在探索了擴散模型采樣、參數化和訓練的基礎知識之后,我們的團隊開始研究這些網絡架構的內部結構。請參考 生成式 AI 研究聚焦:揭開基于擴散的模型的神秘面紗?了解更多詳情。
結果證明這是一項令人沮喪的練習。任何直接改進這些模型的嘗試都會使結果更加糟糕。它們似乎處于微妙、微調、高性能的狀態,任何更改都會破壞平衡。雖然通過徹底重新調整超參數可以實現好處,但下一組改進將需要重新經歷整個過程。
如果您熟悉這種繁瑣的開發循環,但您不直接使用擴散,請繼續閱讀。我們的研究結果針對大多數神經網絡及其訓練背后的普遍問題和組件。
我們決定打破這個循環,回顧一下基礎知識。為什么架構如此易碎?網絡中是否存在破壞訓練進程的未知現象?我們如何使其更加穩健?歸根結底:由于這些問題,我們目前還剩下多少性能?
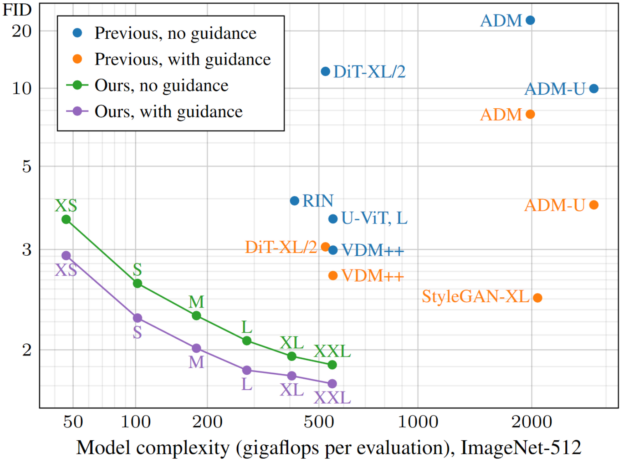
我們最近的論文 分析和改進擴散模型的訓練動力學 中報告了我們的研究結果和細節。我們仔細分析和重新思考訓練動態,這是許多旗艦級圖像生成器模型的基礎。我們報告了在訓練速度和生成質量方面的出色性能,以實現降噪擴散。圖 1 顯示,我們的模型的質量與先前的工作相當,只是模型復雜性和訓練時間的一小部分,并且在使用更大的模型時明顯優于先前的工作。
我們得出了簡化的網絡架構和訓練方法,我們稱之為 EDM2,這是一種可靠、清晰的方法,可隔離 ADM 的強大核心,同時擺脫歷史包和束縛。
此外,我們還介紹了一個理解不足但至關重要的網絡權重指數移動平均值程序,并大大簡化了此超參數的調優。
這篇文章介紹這項研究的主要發現。要查看參考實現代碼,請訪問在 GitHub 上發布的?NVlabs/edm2。
訓練動態是什么?為何如此重要?
假設基準 ADM 架構如圖 2 所示。
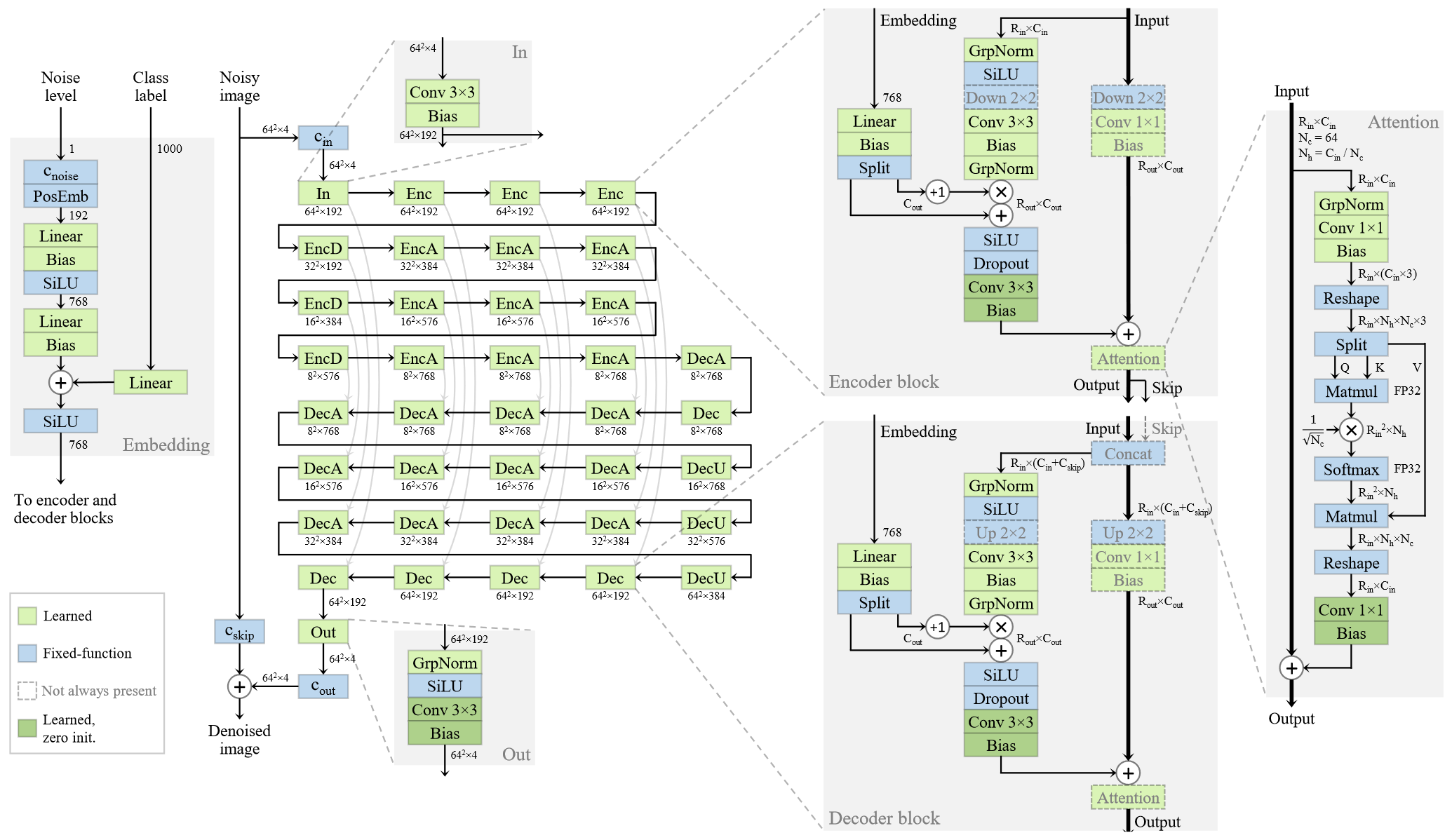
我們可以通過從輸出端發送的梯度反饋信號來成功訓練如此深度和復雜的網絡,這真是一個奇跡。我們如何確保它以健康和平衡的方式真正到達網絡的所有部分,并訓練每個層充分發揮其潛力?
從歷史上看,這一點很不明確,并且由于梯度爆炸和消失等問題,網絡將受到性能不佳的影響。在 2010 年代早期引入現代優化器以及歸一化和初始化程序后,情況迅速改善。訓練動態已經解鎖,到目前為止,我們還沒有看到模型復雜性和數據的擴展。
隨意散布批量或組歸一化層等組件通常可以解決最明顯的問題,而這只能解決。但是,現代網絡是真正運行良好的學習機器,還是它們在日益復雜的架構和訓練任務中作響?擴散損失非常雜亂和復雜,通過仔細檢查,訓練幾乎無法將所有內容保持在一起。
控制重量和激活量
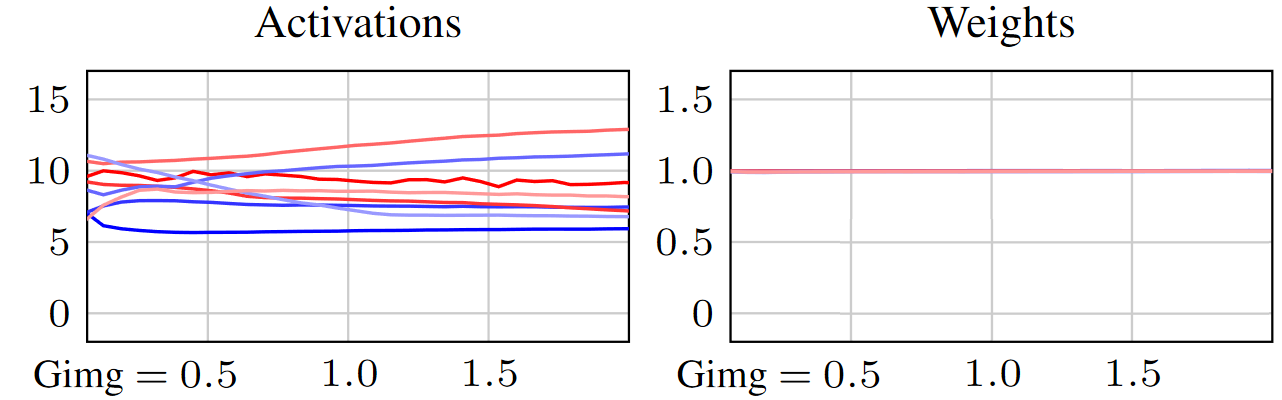
第一個提示是:ADM 訓練并非一切都正確。跟蹤網絡中傳播的激活函數中看到的值的大小以及存儲在層中的學習權重張量,可以顯示整個訓練過程中的穩步增加 (線對應于選擇的不同層)。
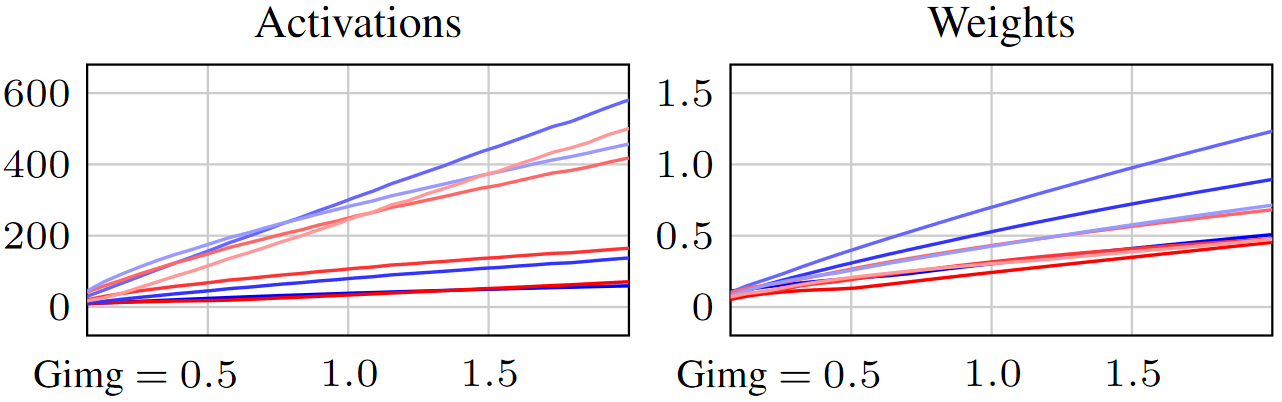
這種行為很常見 (不僅僅是在擴散中),通常會被忽略為另一種奇怪的好奇心,因為它似乎并不阻止網絡學習。但是,我們發現這是一種不健康的現象,會嚴重影響訓練的速度、可靠性和可預見性,并影響最終結果的質量。
為什么會出現這個問題?是什么導致了重量和活化增長,以及它們有哪些有害影響?這些問題帶來了許多問題,每個問題都在復雜的交互網絡中相互交織。
首先,我們發現 **權重** 只是一個數值偽影,而不是訓練“有意”為了達到某些有益的目的而尋求的東西。這種現象是由梯度更新中存在的噪聲和數值近似值錯誤所引起的統計趨勢。盡管存在這種附帶性質,但由于兩個不同的原因,它存在問題:…
- 訓練會隨著時間的推移而飽和,因為當現有權重已經很大時,權重的更新會產生較小的相對影響。這就像將一成分投入罐子里一樣。過了一段時間,再添加一不會有太大的變化。訓練速度會降低到爬行 (每層的速度不同),即使有更多的東西需要學習。換言之,訓練會受到每層學習率下降的控制。
- 權重乘法作用于 **激活** 通過卷積和矩陣乘積。當權重增加時,該層的激活也會增加。因此,權重增長會導致激活增長。
那么,激活增長又如何呢?為什么會出現問題呢?
通過網絡中間某個地方的單個層的眼睛查看世界,在任何訓練迭代中,它收到的輸入激活量的增長略大于過去看到的增長。雖然其權重已適應以前較小的輸入,因此已經過時,但它使用這些權重。后來,它收到一個梯度信號,告訴它如何解決這一差異。但是反饋來得太遲,計算已經有點錯誤。在下一次迭代中,輸入激活量再次增加,并且重復相同的過程。
通過誘導,在不斷增長的激活下,所有層在網絡輸出始終存在略有錯誤。無論訓練持續多久,優化永遠無法完全達到。這在擴散降噪等高精度任務中非常重要。
補救辦法
認識到問題后,如何解決這些問題?為了簡化任務,我們首先嚴格檢查了網絡中的每個移動部件,并消除了不必要的松。例如,我們刪除了所有可學習的偏差 (令人驚訝的是,沒有任何不良反應),這使我們更容易推理大小,因為它為我們留下了更少的可學習參數類型。論文詳細介紹了許多其他改進,這些改進共同使網絡的行為更加可預測和穩定。
清晰明了之后,我們針對之前詳述的問題進行了核心改進。以下各節詳細介紹了關鍵步驟:
- 為所有應用統一的大小保存原則。層
- 控制有效學習率
- 刪除現已被取代 (且存在問題的) 組歸一化層
消除激活和重量增長
我們采用一個簡單的總體原則:每個層都必須根據統計預期保留其輸入激活的大小。由于沒有層主動改變激活大小,它們會隨著時間的推移和網絡各部分之間保持大致不變。
我們首先用“非學習”層 (例如非線性 (我們認為這些層與學習層分開)、連接和加法來說明這一想法。例如,SiLU 非線性會降低其輸入激活的大小,將負值拉向零。使用大量隨機數據饋送此層,平均而言,其大小將變化 0.596 倍。保持大小的 SiLU 版本將輸出激活除以這個統計預期常量,近似于取消大小的變化。
如何將此原則應用于包含可學習權重的卷積和全連接層?激活大小的預期變化與權重大小成正比。為了消除這一點,我們重新調整了權重,使其始終保持在單位大小 (帶有一些細微之處 – 請參閱論文附錄或代碼版本以了解詳情)。
至關重要的是,這可以消除權重增長會導致激活次數增加的直接因果關系,并消除永遠過時的層的問題。激活數量的標準化還使網絡更具可預見性。例如,當組合來自兩個不同分支的激活時,我們可以根據選擇的比例混合它們的貢獻,而不會因為不受控制的數量而意外超過一個分支。
請注意,這如何讓兩鳥獲得一塊石頭:激活過程保持穩定,并且明確禁止權重增長 (圖 4)。
控制學習率衰減
消除權重增長還可以消除不受控制的學習率的下降。這是一個很好的基準情況,因為現在每次 Adam 優化器權重更新都會對每個權重產生大致一致的影響,而不管訓練進展有多遠或位于網絡中的位置。
相比之下,原始網絡層根據其不受控制的數量具有“有效學習率”:一些層學習速度太慢,另一些則速度太快,不穩定;一些在完成之前就停止了學習,而另一些則從未安頓下來。
但是,學習率衰減是必要的,因為它允許網絡在學習時逐漸專注于數據的更精細的細節。我們希望根據我們的條件來執行此操作,并且在歸一化權重下,我們可以相信所有層都遵循指定的速率。在實踐中,簡單的受控衰減調度在此設置中效果很好。
刪除組歸一化層
此時,ADM 網絡中的眾多組歸一化層已成為冗余,因為幅度保存方案已經控制了激活幅度。有趣的是,刪除這些層可以進一步改善結果。這表明直接應用激活統計信息可能會產生不利的副作用。
這激發了我們對原始 StyleGAN 架構中所發現的幾個有趣的發現的回憶,詳情如下:適用于生成式對抗網絡的基于風格的生成器架構。事實證明,生成器網絡已經學會了通過在其內部激活貼圖中增加一個大規模的本地化 Blob(在輸出圖像中留下一個難看的標記)來“欺詐”。這將通過破壞其計算的平均值來繞過激活量級歸一化。由于網絡為了逃脫而跳的圓圈,嚴格的歸一化肯定會嚴重限制網絡的期望。
我們認為,除以給定激活張量中的平均大小會在所有像素和特征之間引入意外的遠程依賴關系和復雜的平衡要求。權重歸一化在這方面較為柔和。一個角出現的明亮像素不會使圖像的其余部分變暗。
指數移動平均線
模型平均是深度學習中廣泛使用的一種實踐。我們的想法是在訓練期間跟蹤“最近”權重的運行指數移動平均 (EMA).這些權重不在訓練期間使用,而是在推理時使用。我們的想法是,原始訓練權重很雜,對最近顯示的訓練樣本影響太大。
擴散模型訓練的一個令人費解的方面 (通常隱藏在研究論文附錄中的不透明超參數表或代碼庫中的默認參數中) 是需要應用很長的平均值來獲得良好結果,通常是整個訓練長度的幾個百分比。使用最新的訓練權重 (無 EMA) 會產生災難性的糟糕結果。另一方面,過多的平均值會過度強調早期階段的權重,包括隨機初始化。這并不方便,因為對于平均速率的邏輯似乎并不多,并且需要在訓練之前確定數量。還是這樣?
后期重建
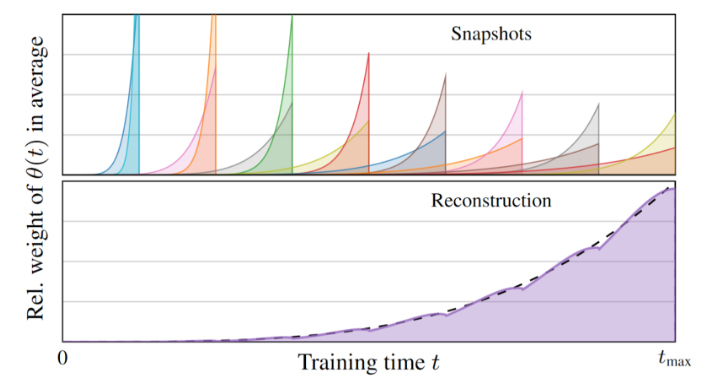
在?分析和改進擴散模型的訓練動力學?中,我們改變了 EMA 配置文件曲線的形狀,使其隨著訓練長度“舒展”,并提出了一種在訓練后重建具有不同 EMA 長度的網絡的后期方法。我們的想法是存儲具有固定較短 EMA 長度的中間訓練狀態的定期快照,然后我們可以通過合適的線性混合從中重建各種更長的 EMA 配置文件。與重新運行整個訓練相比,組合幾十個快照的效率要高出幾個數量級;確定最佳 EMA 長度是一個簡單的機械過程。
圖 5 展示了如何在權重歷史中將單個快照合并為更長的平均值的示例。著色區域表示每個快照在不同時間收集的權重。
此方法支持將性能指標繪制為 EMA 長度的函數,使我們能夠對其行為進行前所未有的深入了解。密集測量作為 EMA 長度函數的生成圖像的質量 (FID 分數越低越好) (占完整訓練運行長度的百分比),會得出如圖 6 所示的圖形。它比較不同網絡配置的性能,這些配置用字母表示。
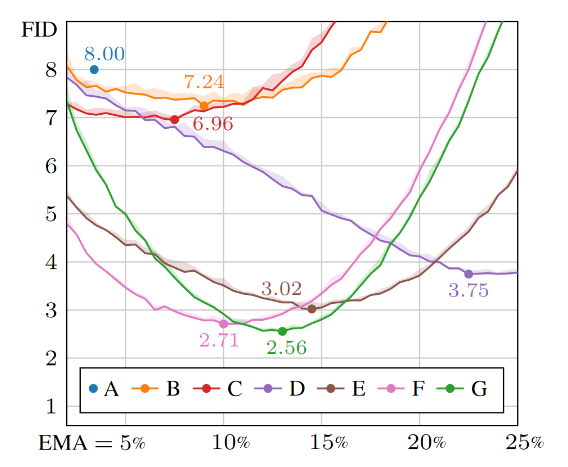
最佳值非常銳利,當偏離最佳值時,質量會迅速下降。如果選擇錯誤的 EMA,一個好的模型可能會表現出任意較差的性能。盲目使用次優 EMA (例如,8%或 18%) 會錯誤地表明獲勝的配置 G 低于其他一些競爭對手。
使用此新工具可以發現一些令人驚訝的現象。例如,最佳 EMA 長度對使用無分類器指導非常敏感 (圖 7)。
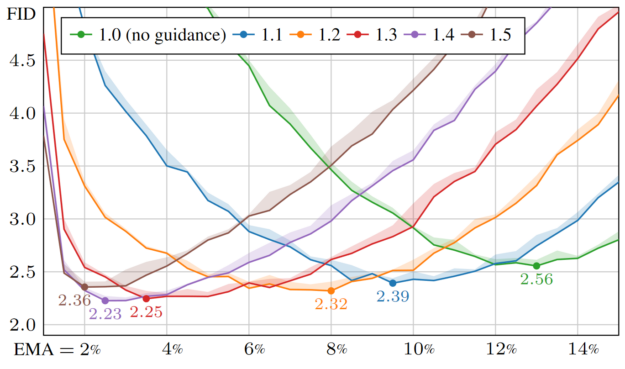
基于這些知識,掃描 EMA 值是未來模型調整和評估的重要組成部分。
結果和結論
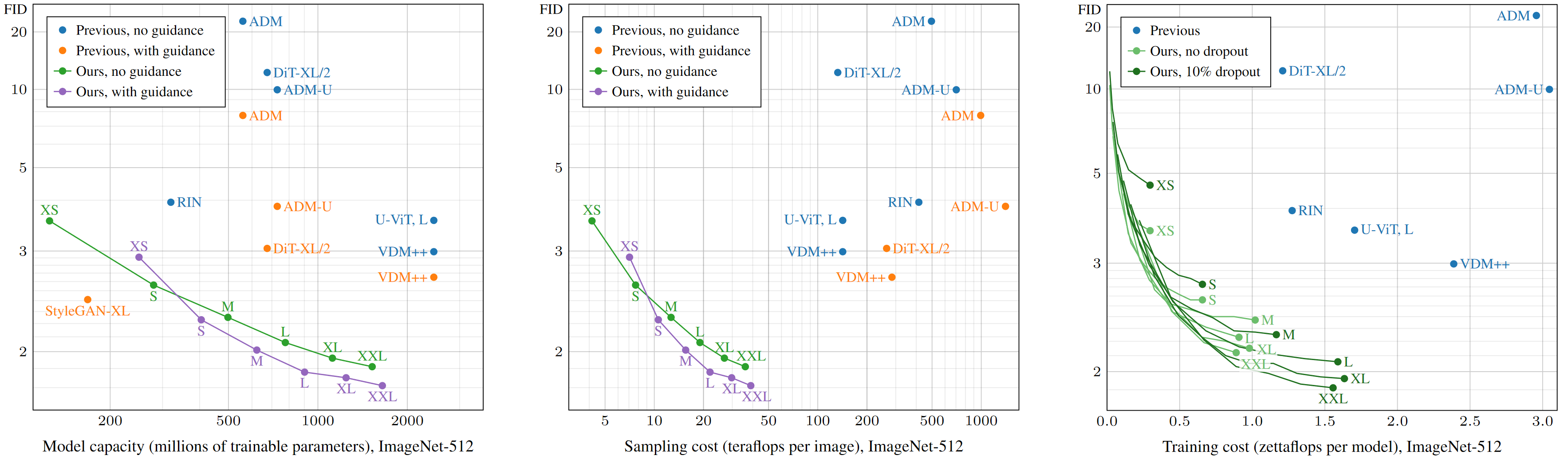
我們的團隊使用隱擴散徹底評估了常見 ImageNet-512 設置的改進,并在此廣泛使用的基準測試中達到創紀錄的 1.81 FID.但是,僅僅查看行數可能會產生誤解。重要的是隨大小進行縮放。
為此,我們訓練了六個規模越來越大的模型,分別為 EDM2-XS、S、M、L、XL 和 XXL.圖 1 顯示了每個模型的 FID 分數 (質量) 作為模型復雜性 (每個網絡評估的千兆浮點運算) 的函數,以及最近的先進競爭對手,如擴散 Transformer 和 VDM++.對于每個模型,我們還繪制了在采樣期間啟用無分類器指導的變體,因為這是改進當前模型擴散結果的關鍵工具。
因此,我們的模型在給定的預算范圍內一致地達到了最好的降價效果,并達到了與之前最先進的模型相似的質量,模型縮小了 5 倍。在參數計數、推理時間采樣費用和訓練成本方面進行的比較也說明了類似的情況 (圖 8)。
當然,生成的圖像也可以而且應該被查看 (圖 9)。但該領域嚴重依賴指標是有原因的,因為很難直觀判斷來自少量圖像的訓練數據的保真度。

我們還評估了使用 FD 的性能DINOv2指標,該指標最近被提出來改進 FID 的一些盲點。我們看到我們的方法也有類似的優勢。
除了更大限度地提高性能外,一個關鍵目標是簡化架構,使其更易于調整和探索。根據我們的實踐經驗,最終架構的行為似乎更可預測,我們發現它在變化方面更加可靠。
您可能已經注意到,大多數研究結果都是通用的,與 ADM 架構無關,對此,甚至沒有與擴散有關。這確實是未來研究的一個有趣的途徑。這些原則也可以直接應用于,例如,擴散 Transformer 訓練。例如,在先前的研究中,圖像分類器已從歸一化方案的相關重新設計中受益。強制權重歸一化和大小保留層等關鍵組件是自包含的,可以輕松應用到其他網絡。
?