NVIDIA Holoscan 是 NVIDIA 的多模態實時 AI 傳感器處理平臺,旨在幫助開發者構建端到端傳感器處理流程。該平臺的核心組件是 NVIDIA Holoscan SDK,其功能包括:
- 用于低延遲傳感器和網絡連接的組合硬件系統
- 針對數據處理和 AI 優化的庫
- 靈活部署:邊緣或云
- Python 和 C++等各種編程語言
Holoscan SDK 可用于為多種行業和應用場景構建流式 AI 流程,包括醫療設備、邊緣高性能計算和工業檢測等領域。有關更多信息,請參閱 使用 NVIDIA Holoscan 開發生產就緒型 AI 傳感器處理應用,以獲取詳細信息。
Holoscan SDK 通過充分利用軟件和硬件來加速流式 AI 應用。它可以與 RDMA 技術 結合,通過 GPU 加速進一步提高端到端流程性能。通常,端到端傳感器處理流程包括:
- 傳感器數據輸入
- 加速計算和 AI 推理
- 實時可視化、驅動和數據流輸出
此流程中的所有數據都存儲在 GPU 顯存中,Holoscan 原生運算符可以直接訪問,而無需主機設備內存傳輸。

本文介紹了如何通過集成 Holoscan SDK 和開源庫 OpenCV,在不進行額外顯存傳輸的情況下實現端到端 GPU 加速工作流程。
什么是 OpenCV?
OpenCV(開源計算機視覺庫)是一個功能齊全的開源計算機視覺庫,包含超過 2500 種算法,涵蓋圖像和視頻操作、物體和面部檢測以及 OpenCV 深度學習模塊等方面。
OpenCV 支持 GPU 加速,其中包括一個 CUDA 模塊,該模塊提供了一組類和函數,以便充分利用 CUDA 計算能力。它通過使用 NVIDIA CUDA 運行時 API 實現,并提供實用功能、低級視覺基元和高級算法。
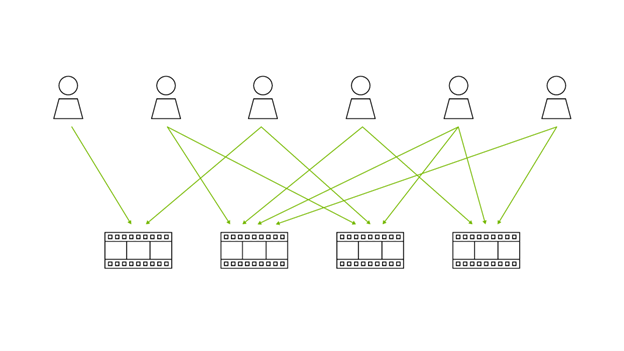
借助 OpenCV 中提供的全面 GPU 加速算法和運算符,開發者可以基于 Holoscan SDK 實施更復雜的流程 (圖 2)。

在 Holoscan SDK 管道中集成 OpenCV 運算符?
要開始在 Holoscan SDK 管道中集成 OpenCV 運算符,您需要以下內容:
- OpenCV > = 4.8.0
- Holoscan SDK > = v0.6
請按照以下指南操作:opencv/opencv_contrib,安裝帶有 CUDA 模塊 OpenCV。如果您想使用 Holoscan SDK 和 OpenCV CUDA 構建鏡像,請參閱 NVIDIA Holoscan/holohub 的 Dockerfile。
作為 Holoscan SDK 中的數據類型,Tensor 被定義為由單一數據類型的元素組成的多維數組。Tensor 類是 Holoscan SDK 中的數據類型的包裝器,DLManagedTensorCtx?保存 DLManagedTensor 對象的結構體。Tensor 類支持 DLPack 和 NumPy 數組接口 (__array_interface__ 和 __cuda_array_interface__),因此它可以與其他 Python 庫一起使用,例如 CuPy、PyTorch、JAX、TensorFlow 以及 Numba。
然而,OpenCV 的數據類型是 GPUMat,它沒有實現 __cuda_array_interface__,因此無法實現端到端 GPU 加速的工作流或應用程序。為此,需要實現兩個函數,將 GpuMat?與?CuPy 數組進行相互轉換,以便直接訪問及使用 Holoscan Tensor。
?
從 GpuMat 到 CuPy 數組的無縫零拷貝?
OpenCV Python 綁定的 GpuMat 對象提供了一個cudaPtr方法,用于訪問 GpuMat 對象的 GPU 顯存地址。此內存指針可以用于直接初始化 CuPy 數組,從而避免主機和設備之間不必要的數據傳輸,實現高效的數據處理。
以下函數用于從 GpuMat 創建 CuPy 數組。該函數的源代碼位于 HoloHub 的內窺鏡深度估算應用程序中。
import cv2 import cupy as cp ??def?gpumat_to_cupy(gpu_mat:?cv2.cuda.GpuMat)?->?cp.ndarray: ????w,?h?=?gpu_mat.size() ????size_in_bytes?=?gpu_mat.step?*?w ????shapes = (h, w, gpu_mat.channels()) ????assert?gpu_mat.channels()?<=3,?"Unsupported?GpuMat?channels"??????dtype?=?None????if?gpu_mat.type()?in?[cv2.CV_8U,cv2.CV_8UC1,cv2.CV_8UC2,cv2.CV_8UC3]: ????????dtype?=?cp.uint8 ????elif?gpu_mat.type()?==?cv2.CV_8S: ????????dtype?=?cp.int8 ????elif?gpu_mat.type()?==?cv2.CV_16U: ????????dtype?=?cp.uint16 ????elif?gpu_mat.type()?==?cv2.CV_16S: ????????dtype?=?cp.int16 ????elif?gpu_mat.type()?==?cv2.CV_32S: ????????dtype?=?cp.int32 ????elif?gpu_mat.type()?==?cv2.CV_32F: ????????dtype?=?cp.float32 ????elif?gpu_mat.type()?==?cv2.CV_64F: ????????dtype?=?cp.float64? ??assert?dtype?is?not?None,?"Unsupported?GpuMat?type"???? ????mem?=?cp.cuda.UnownedMemory(gpu_mat.cudaPtr(),?size_in_bytes,?owner=gpu_mat) ????memptr?=?cp.cuda.MemoryPointer(mem,?offset=0) ????cp_out = cp.ndarray( ????????shapes, ????????dtype=dtype, ????????memptr=memptr, ????????strides=(gpu_mat.step, gpu_mat.elemSize(), gpu_mat.elemSize1()), ????) ????return?cp_out |
請注意,我們在此函數中使用了 非自有內存 創建 CuPy 數組的 API。在某些情況下,OpenCV 運算符將創建需要由 CuPy 處理的新設備內存,其生命周期不限于一個運算符,而是整個工作流。在這種情況下,從 GpuMat 啟動的 CuPy 數組知道所有者并保留對對象的引用。欲了解更多詳細信息,請參閱 CuPy 互操作性文檔。
從 Holoscan Tensor 到 GpuMat 的無縫零拷貝?
隨著 OpenCV 4.8 的發布,OpenCV 的 Python 綁定現在支持直接從 GPU 顯存指針初始化 GpuMat 對象。此功能通過實現與 GPU 駐留數據的直接交互來提高數據處理和處理效率,從而無需在主機和設備顯存之間傳輸數據。
在基于 Holoscan SDK 的工作流應用程序中,GPU 顯存指針可以通過由 CuPy 數組提供的?_cuda_array_interface_ 獲得。以下列出了用于利用 CuPy 數組創建 GpuMat 對象的函數。有關詳細實現,請參閱提供的源代碼 HoloHub 內窺鏡深度估計應用程序。
import?cv2 import?cupy?as?cp ??def?gpumat_from_cp_array(arr:?cp.ndarray)?->?cv2.cuda.GpuMat: ????assert?len(arr.shape)?in?(2,?3),?"CuPy?array?must?have?2?or?3?dimensions?to?be?a?valid?GpuMat"????type_map?=?{ ????????cp.dtype('uint8'):?cv2.CV_8U, ????????cp.dtype('int8'):?cv2.CV_8S, ????????cp.dtype('uint16'):?cv2.CV_16U, ????????cp.dtype('int16'):?cv2.CV_16S, ????????cp.dtype('int32'):?cv2.CV_32S, ????????cp.dtype('float32'):?cv2.CV_32F, ????????cp.dtype('float64'):?cv2.CV_64F ????} ????depth?=?type_map.get(arr.dtype) ????assert?depth?is?not?None,?"Unsupported?CuPy?array?dtype"????channels?=?1?if?len(arr.shape)?==?2?else?arr.shape[2] ????mat_type?=?depth?+?((channels?-?1)?<<?3) ???? ????mat?=?cv2.cuda.createGpuMatFromCudaMemory( ????arr.__cuda_array_interface__['shape'][1::-1],? ????mat_type,? ????arr.__cuda_array_interface__['data'][0] ??) ????return?mat |
集成 OpenCV 運算符?
借助前面的兩個函數,您可以在基于 Holoscan SDK 的工作流中使用 OpenCV-CUDA 操作,從而避免內存傳輸。以下是實現步驟:
- 創建調用 OpenCV Operator 的自定義操作符。有關詳細信息,請參閱 Holoscan SDK 用戶指南文檔。
- 在 Operator 中的計算函數中:
- 從前一個運算符接收消息,并從 Holoscan Tensor 創建 CuPy 數組。
- 使用
gpumat_from_cp_array函數創建 GpuMat。 - 使用自定義的 OpenCV Operator 進行處理。
- 使用
gpumat_to_cupy函數從 GpuMat 創建 CuPy 數組。
請參閱下方的演示代碼。有關完整的源代碼,請參閱 HoloHub 內窺鏡深度估計應用程序的源代碼。
def compute(self, op_input, op_output, context): ????????stream = cv2.cuda_Stream() ????????message = op_input.receive("in") ??????????cp_frame = cp.asarray(message.get(""))? # CuPy array ????????cv_frame = gpumat_from_cp_array(cp_frame)? # GPU OpenCV mat ??????????## Call OpenCV Operator? ????????cv_frame = cv2.cuda.XXX(hsv_merge, cv2.COLOR_HSV2RGB) ??????????cp_frame = gpumat_to_cupy(cv_frame) ????????cp_frame = cp.ascontiguousarray(cp_frame) ??????????out_message = Entity(context) ????????out_message.add(hs.as_tensor(cp_frame), "") ????????op_output.emit(out_message, "out") |
總結?
將 OpenCV CUDA 操作符集成到基于 Holoscan SDK 構建的應用程序中,只需實現兩個函數,實現 OpenCV 的 GpuMat 和 CuPy 數組的轉換。
這些功能允許在自定義運算符中直接訪問 Holoscan Tensors.通過調用這些功能,您可以無縫創建端到端 GPU 加速應用程序,而無需內存傳輸,從而提高性能。
首先,下載 Holoscan SDK 2.0 并查看 版本說明。如果您有任何問題或想分享信息,請訪問 NVIDIA 開發者論壇。
欲了解如何將其他外部庫集成到 NVIDIA Holoscan SDK 管線中,請參閱 HoloHub 教程。您還可以從示例代碼和應用入手,nvidia-holoscan/holohub 是 NVIDIA Holoscan AI 傳感器處理社區的中央存儲庫,提供了豐富的資源和示例代碼。
?