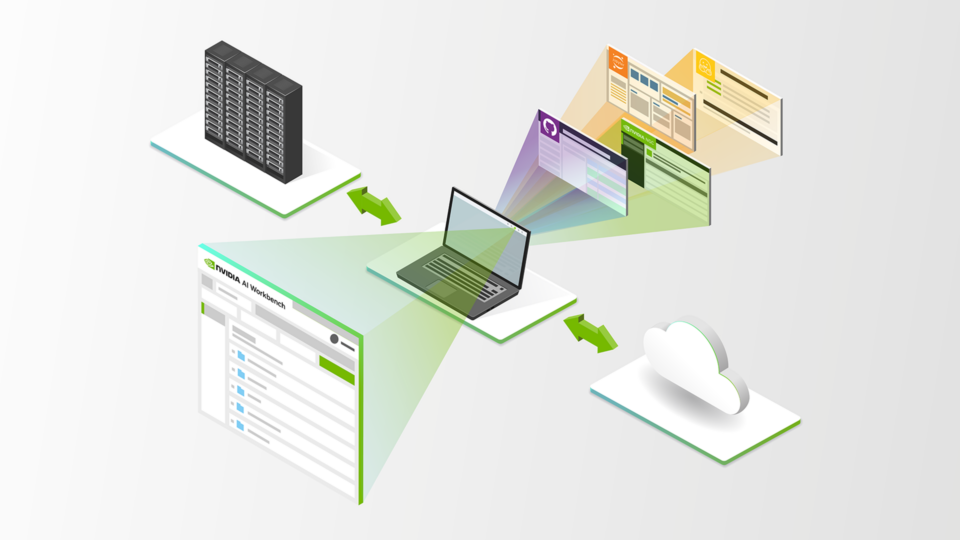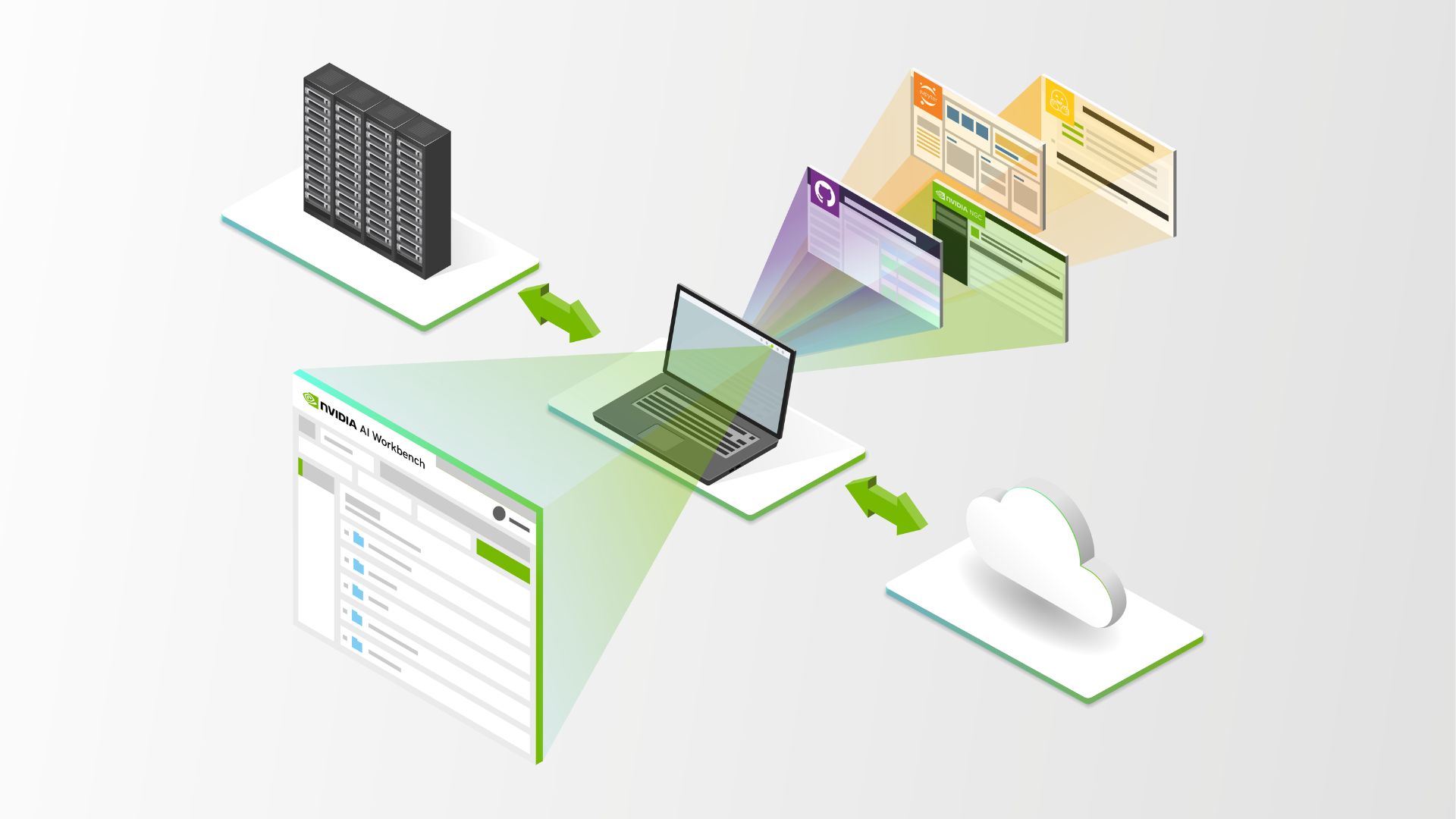
NVIDIA AI Workbench 現已進入測試階段,帶來了豐富的新功能,可簡化企業開發者創建、使用和共享 AI 和機器學習 (ML) 項目的方式。在 SIGGRAPH 2023 上發布的 NVIDIA AI Workbench,使開發者能夠在支持 GPU 的環境中輕松創建、協作和遷移 AI 工作負載。欲了解更多信息,請參閱借助 NVIDIA AI Workbench 無縫開發和部署可擴展的生成式 AI 模型。
本文介紹了 NVIDIA AI Workbench 如何幫助簡化 AI 工作流程,并詳細介紹了測試版的新功能。本文還介紹了編碼副駕駛參考示例,該示例使您能夠使用 AI Workbench 在所選平臺上創建、測試和自定義預訓練的生成式 AI 模型。
什么是 NVIDIA AI Workbench?
借助 AI Workbench,開發者和數據科學家可以在 PC 或工作站上靈活地在本地啟動 AI 或 ML 項目,然后將其遷移到任何地方。項目可以推送到數據中心、公有云或 NVIDIA DGX 云,或者根據項目需求遷移到本地 RTX PC 或工作站進行推理和輕量級定制。
AI Workbench 通過提供處理所選異構計算資源的能力,幫助開發者簡化和縮短 AI 工作流程的設置、開發和遷移。優勢包括:
- 使用直觀的 UX 或 CLI 在所選系統上免費快速安裝,以創建和管理項目。
- 簡化計算資源和運行時配置,為使用不同的 GPU 資源提供再現性和靈活性。
- 簡化容器和 Git 存儲庫的版本控制和管理,以及與 GitHub、GitLab 和 NVIDIA NGC 目錄 的集成。
- 實現自動化和簡化,以處理基于 Git 和容器的開發者環境,使用戶能夠選擇系統、筆記本電腦、工作站、服務器或云。
- 跨用戶和系統的可再現性,可以透明地處理憑據、機密和文件系統更改等特性,而不會產生額外費用。
- 可擴展地創建和分發適用于生成式 AI、支持 GPU 的機器學習和數據科學的復雜工作流程和應用。
測試版新增功能
AI Workbench 測試版包含以下令人興奮的新功能,包括用戶界面更新以及對容器運行時和 Git 服務器的擴展支持。
簡化設置和安裝,支持在 Windows 11、Ubuntu 22.04 和 macOS 11 或更高版本上運行。
- 通過兩種方式快速安裝 AI Workbench:在本地系統上使用桌面應用程序進行單擊安裝,或在遠程系統上進行命令行安裝。
- 支持三大操作系統,隨時隨地開展工作,獲得統一體驗。AI Workbench 可在支持 WSL2、Ubuntu 22。04 和 macOS 版本 11 及更高版本的 Windows 發行版上運行。
借助容器化環境簡化版本控制和開發。
- 使用桌面應用程序和 CLI 訪問簡單且全面的 Git 兼容版本控制。現在包含 Push、Pull 和 Fetch 功能。
- 創建具有隔離和可再現性的容器化 JupyterLab 環境,而無需處理細節。
- 從兩個容器運行時選項中進行選擇:Docker 或 Podman。
擴展了用戶界面和 CLI 之間的功能一致性。
- 直接在桌面應用程序中查看提交歷史記錄和摘要。
- 在桌面應用程序中查看改進的容器狀態和應用程序狀態通知。
擴展了默認基礎圖像。
- 訪問三個新的基礎圖像以創建項目,此外,NGC 目錄中已有的 Python 基礎版 和 PyTorch 基礎版。適用于 CUDA 11.0、CUDA 12.0 和 CUDA 12.2 的新基礎圖像為進一步定制提供了基礎。
三個新的示例項目供參考。
- Mistral:使用 QLoRA PEFT 在自定義代碼指令數據集上微調 Mistral 7B 大型語言模型 (LLM)。
- RAG:使用用戶友好型本地開發者工作流程與數據進行對話,實現檢索增強生成(RAG)。
- NeMotron-3 中文關鍵詞:在自定義 QA 數據集上微調 NVIDIA NeMo 的 Nemotron-3 8B LLM。
創建您自己的編碼副駕駛
本節介紹了 AI Workbench 如何顯著簡化在用戶選擇的 GPU 系統上使用和微調生成式 AI 模型的過程。
關鍵概念
本示例中使用的幾個關鍵概念概述如下。
AI 工作臺項目
AI Workbench 項目是一個 Git 存儲庫,其中包含一組可由 AI Workbench 讀取的配置文件,以自動創建和管理容器化開發環境。項目引用了已配置的容器化開發環境所需的一切,包括:
- 代碼、數據和模型
- 驅動 AI Workbench 自動化的簡單配置文件,用于容器自定義和軟件包安裝
- 項目規格元數據文件,以與 AI Workbench 兼容的方式包裝資源庫
訪問 GitHub 上的 NVIDIA 項目,這些項目為調整自己的數據和用例提供了起點。此外,AI Workbench 搶先體驗成員可以貢獻和使用第三方社區項目示例。
我們的 Mistral 7B 微調參考項目 詳細介紹了如何在您的系統中利用 AI Workbench 的強大功能,構建一個基本的編碼副駕駛。
微調
雖然 Mistral 7B 是多個下游任務的堅實基礎,但它可能缺乏基于專有或其他敏感信息的特定領域知識。在這些情況下,微調用于改善模型的響應。
微調有兩個版本。第一個版本是完全微調,使用新數據更新所有模型權重。這可以改善特定領域的結果,但通常需要更多的時間、更大、更昂貴的 GPU。其次,參數高效微調 (PEFT)是一系列用于更新模型權重子集的技術。PEFT 通常優于完全微調,因為它可以在更短的時間內生成類似的結果,并且使用更小、更便宜的 GPU。
此示例主要關注 PEFT 的量化低排名適應 (QLoRA) 方法。低排名適應 (LoRA) 是一種 PEFT 方法,在重新訓練中使用較小的權重矩陣作為近似值,而不是更新全權重矩陣。這種排名分解優化技術可以提高內存效率,并減少成功微調所需的 GPU 大小。
QLoRA 是一種進一步的優化,它降低了模型權重的精度,從而在內存和空間效率方面取得了更大的進步。在 LoRA 微調工作流程中,最常見的量化是 4 位量化,它在模型性能和微調可行性之間提供了適當的平衡。
NVIDIA AI Workbench 中的 Mistral 7B 微調項目演練
此演示包含高級代碼和詳細信息。欲了解更多信息,請參閱完整的Mistral 7B 微調參考項目,該項目基于 Mistral 7B 基礎模型。此外,TokenBender 代碼說明數據集提供了 12.2 萬個 Alpaca 風格的代碼指令和相應的代碼解決方案。

首先,下載數據并將其分為 80%的訓練數據集、10%的驗證數據集和 10%的測試數據集。數據集中的一個指令條目如下所示:
Below is an instruction that describes a task. Write a response that appropriately completes the request.### Instruction: Output the maximum element in an array. ### Input: [1, 5, 10, 8, 15] ### Output: 15 |
接下來,下載 Mistral 7B 模型權重至此項目:
model_id = "mistralai/Mistral-7B-v0.1"bb_config = BitsAndBytesConfig(????load_in_4bit=True,????bnb_4bit_use_double_quant=True,????bnb_4bit_quant_type="nf4",)?
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bb_config) |
請注意,已為基礎模型指定 4 位量化配置。
接下來,根據特定的示例編程問題評估基礎模型的性能。這將為基礎模型和最終微調模型之間的比較建立基準。
base_prompt = """Write a function to output the prime factorization of 2023 in python, C, and C++"""?
base_tokenizer = AutoTokenizer.from_pretrained(????model_id,????add_bos_token=True,)?
model_input = base_tokenizer(base_prompt, return_tensors="pt").to("cuda")?
model.eval()with torch.no_grad():????print(base_tokenizer.decode(model.generate(**model_input, max_new_tokens=256)[0], skip_special_tokens=True))?
***** Output ***** ?
## Prime Factorization of 2023?
The prime factorization of 2023 is 13 x 157.?
## Prime Factorization of 2023 in Python?
The prime factorization of 2023 in python is given below.?
def prime_factorization(n):????factors = []????for i in range(2, n + 1):????????if n % i == 0:????????????factors.append(i)????return factors?
print(prime_factorization(2023))?
... |
請注意,基礎模型開箱即用的表現不佳。首先,基礎模型似乎認為 2023 的 Prime factorization 是 13 x 157.這相當于 2041。實際答案是 7 x 17 x 17、
其次,模型輸出的 Python 函數也不正確。運行建議的代碼會給出[7、17、119、289、2023]的答案,而實際上 119、289 和 2023 不是主要因素。
為了提高模型性能,必須進行微調。首先,通過重新格式化數據集條目以更好地適應用于微調的指令提示[INST],對數據集進行預處理。然后對每個提示進行標記化。
接下來,配置 QLoRA 微調的參數,并開始微調過程。默認情況下,微調包括 1000 次迭代,每 50 步進行一次檢查點和評估。這些超參數可以根據硬件資源進行調整。在配備 NVIDIA A100 80 GB GPU 的系統中,此配置大約需要 6.5 小時。
config = LoraConfig(????r=8,????lora_alpha=16,????target_modules=[????????"q_proj",????????"k_proj",????????"v_proj",????????"o_proj",????????"gate_proj",????????"up_proj",????????"down_proj",????????"lm_head",????],????bias="none",????lora_dropout=0.05,????task_type="CAUSAL_LM",)?
model = get_peft_model(model, config)?
# Training configstrainer = transformers.Trainer(????model=model,????train_dataset=tokenized_train_ds,????eval_dataset=tokenized_val_ds,????args=transformers.TrainingArguments(????????output_dir="./mistral-code-instruct",????????warmup_steps=5,????????per_device_train_batch_size=2,????????gradient_checkpointing=True,????????gradient_accumulation_steps=4,????????max_steps=1000,????????learning_rate=2.5e-5,????????logging_steps=50,????????bf16=True,????????optim="paged_adamw_8bit",????????logging_dir="./logs",????????save_strategy="steps",????????save_steps=50,????????evaluation_strategy="steps", ????????eval_steps=50,????????report_to="none",????????do_eval=True,????),????data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),)?
# Train! trainer.train() |
使用最終微調檢查點,定義更新的 Mistral 7B 模型:
ft_model = PeftModel.from_pretrained(base_model, "mistral-code-instruct/checkpoint-1000") |
要評估微調模型的性能,請提出與初始問題類似的編碼問題,并請求生成代碼片段:
eval_prompt = f"""For a given integer n, print out all its prime factors one on each line. n = 30"""?
input_ids = tokenizer(eval_prompt, return_tensors="pt", truncation=True).input_ids.cuda()outputs = ft_model.generate(input_ids=input_ids, max_new_tokens=256, do_sample=True, top_p=0.9,temperature=0.5)?
***** Output ***** ?
Generated response:235 ?
#include ?
int main() {????int n = 30;????int i;????for (i = 2; i <= n; i++) {????????while (n % i == 0) {????????????printf("%d\n", i);????????????n /= i;????????}????}????return 0;}?
... |
經過微調的模型生成的代碼片段響應效果會更好。使用沙盒環境親自試用代碼。
這就是微調 Mistral 7B LLM 的全部內容。此項目為您的開發需求提供了參考工作流。您可以隨時選擇自定義項目,以更好地適應您的企業數據或用例。將數據集切換為您自己的數據集,或將模型微調為另一個用例,例如文本摘要或問答。
開始使用 AI 工作臺
NVIDIA AI Workbench 可以幫助您在支持 GPU 的不同環境之間創建、共享和擴展企業 AI 和 ML 工作流程。注冊以獲取 NVIDIA AI Workbench 的測試版訪問權限。如需詳細了解 AI Workbench,請查看以下資源:
- 觀看視頻演示,了解如何使用 Stable Diffusion XL 完成自定義圖像生成示例項目。
- 已讀借助 NVIDIA AI Workbench 無縫開發和部署可擴展的生成式 AI 模型,搶先了解更多示例項目。
- 參考 NVIDIA AI Workbench 用戶指南,借助 NVIDIA AI Workbench 啟動并運行您的 AI 和 ML 項目。
?