在生成式人工智能中,機器不僅可以從數據中學習,還可以生成類似人類的文本、圖像、視頻等。檢索增強生成 (RAG) 是一種突破性的方法。
RAG 工作流程基于 大型語言模型(LLM),可以理解查詢并生成響應。但是,LLM 存在局限性,包括訓練復雜性和缺乏當前 (有時是專有) 信息。此外,當未根據特定數據進行訓練以回答提示時,它們往往會產生幻覺并合成事實錯誤的信息。RAG 通過向 LLM 提供企業特定信息來增強查詢,以幫助克服這些限制。
在本文中,我們討論了 RAG 如何助力企業為各種企業用例創建高質量、相關且引人入勝的內容。我們深入探討了擴展 RAG 以處理大量數據和用戶所面臨的技術挑戰,以及如何使用由 NVIDIA GPU 計算、加速以太網網絡、網絡存儲和 AI 軟件提供支持的可擴展架構來應對這些挑戰。
RAG 使企業能夠充分利用數據
典型的 RAG 工作流程使用 向量數據庫,這類數據管理系統專為執行相似性搜索而定制,用于存儲和檢索與查詢相關的企業特定信息。
通過將 RAG 集成到其信息系統中,企業可以利用大量內部和外部數據來生成具有洞察力的最新上下文相關內容。這種融合是一次重大飛躍,使企業能夠利用其數據和領域專業知識,為個性化客戶互動開辟新途徑,簡化內容創建,并提高知識用例的效率。
但是,在企業規模部署 RAG 會面臨一系列挑戰,包括管理數百個數據集和數千名用戶的復雜性。這就需要一個能夠高效處理此類大規模操作的處理和存儲需求的分布式架構。
要擴展此架構,您必須嵌入、向量化數百萬文檔、圖像、音頻文件和視頻并將其編入索引,同時還能適應每天嵌入新創建的內容。
另一個挑戰是確保交互式多模態應用程序的低延遲響應。由于需要集成數據企業應用程序以及結構化和非結構化數據存儲,因此需要實時處理和響應,而大規模實現這一目標可能具有挑戰性。
生成式 AI 的數據索引和存儲也構成了挑戰。
傳統企業應用可以壓縮數據并將其存儲以進行高效檢索,以支持索引和語義搜索,而基于 RAG 的數據庫可以擴展到比原始文本文件及其相關元數據大 10 倍以上。這將導致數據增長和存儲方面的重大挑戰。
為了獲得最佳結果,企業必須投資加速計算、網絡和存儲基礎設施,這對于處理訓練和部署 RAG 模型所需的大量數據至關重要。
如何實現可擴展且高效的 RAG 推理
在 GTC 2024 上,NVIDIA 推出了 生成式 AI 微服務目錄,為開發者提供用于創建和部署自定義 AI 應用的企業級基礎模組。
企業可以將這些微服務用作創建 RAG 驅動的應用的基礎。通過將其與 NVIDIA RAG 工作流程示例相結合,您可以加快生成式 AI 應用的構建和產品化過程。
在本文中,我們使用多節點 GPU 計算推理、加速以太網網絡和網絡連接存儲對這些 RAG 工作流程示例進行基準測試。我們的測試結果表明,高性能網絡和網絡連接存儲可實現高效且可擴展的生成式 AI 推理,使企業能夠開發由 RAG 驅動的應用,在促進持續數據處理的同時,還可擴展到數千名用戶。
圖 1 顯示了包含兩個階段和數據管線的 RAG 工作流程。
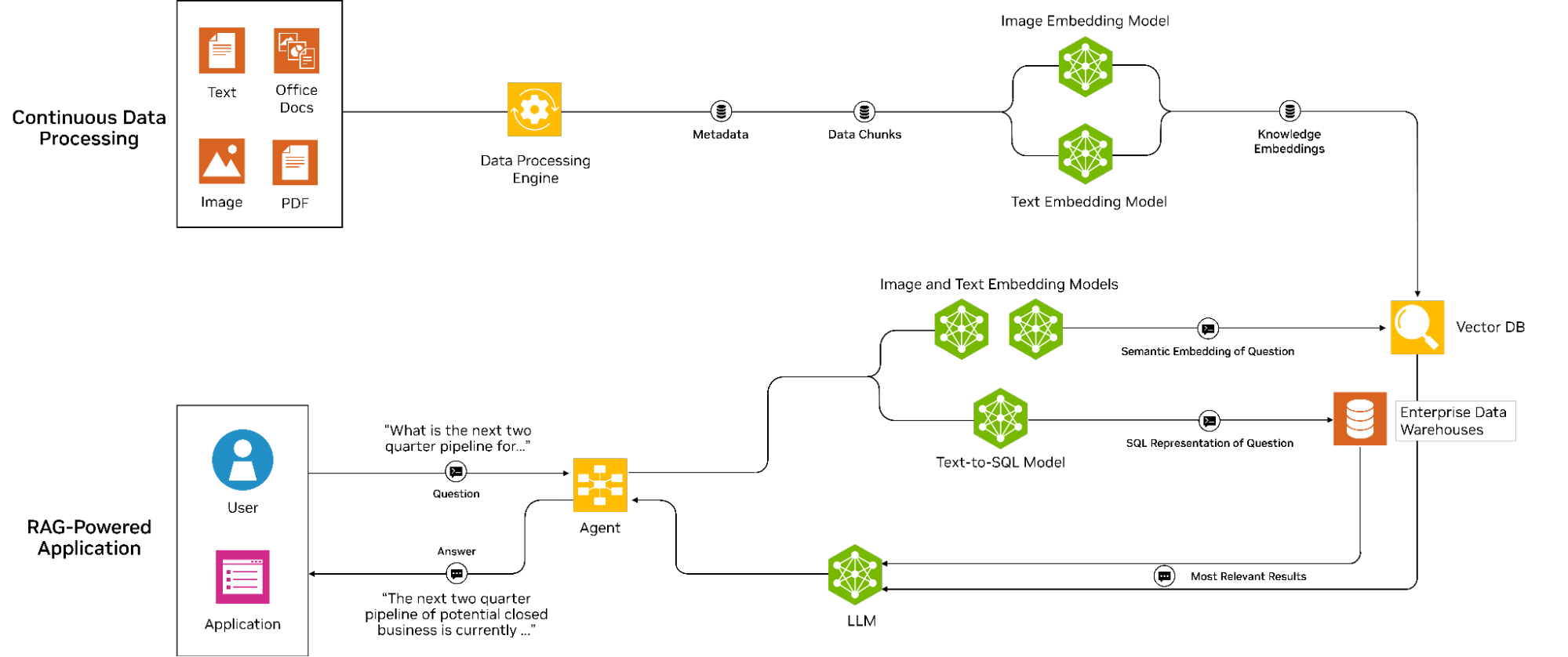
在第一階段,數據提取將文檔和其他數據模式轉換為數字嵌入,然后在向量數據庫中對其進行索引。此過程支持基于相似度分數高效檢索相關文檔。
查詢階段從用戶輸入問題時開始,該問題也會被轉換為嵌入并用于在向量數據庫中搜索相關內容。檢索相關內容后,系統會將其傳遞給 LLM 進行進一步處理。原始輸入問題以及增強上下文會提供給 LLM,LLM 會針對用戶的查詢生成更精確的答案。
此工作流支持有效檢索和生成信息,使其成為適用于各種企業應用程序的強大工具。
加速的以太網網絡、網絡連接的存儲擅長數據提取
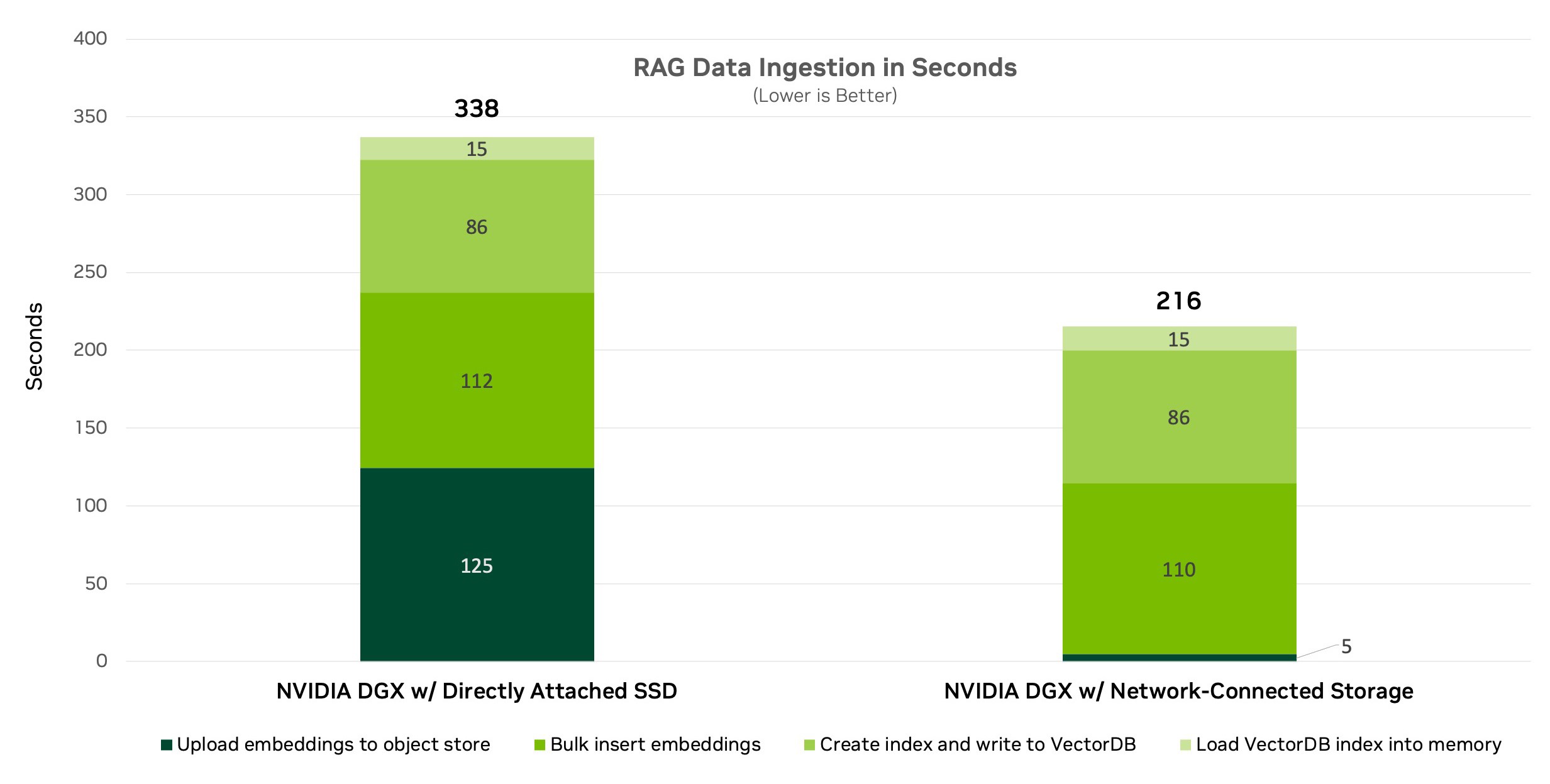
我們最初基于單個 GPU 節點測試了數據提取流程。圖 2 顯示了使用一個配備 8 塊 A100 GPU 的 DGX 系統和一個專為對象存儲工作負載設計的網絡連接全閃存存儲平臺進行的測試設置。
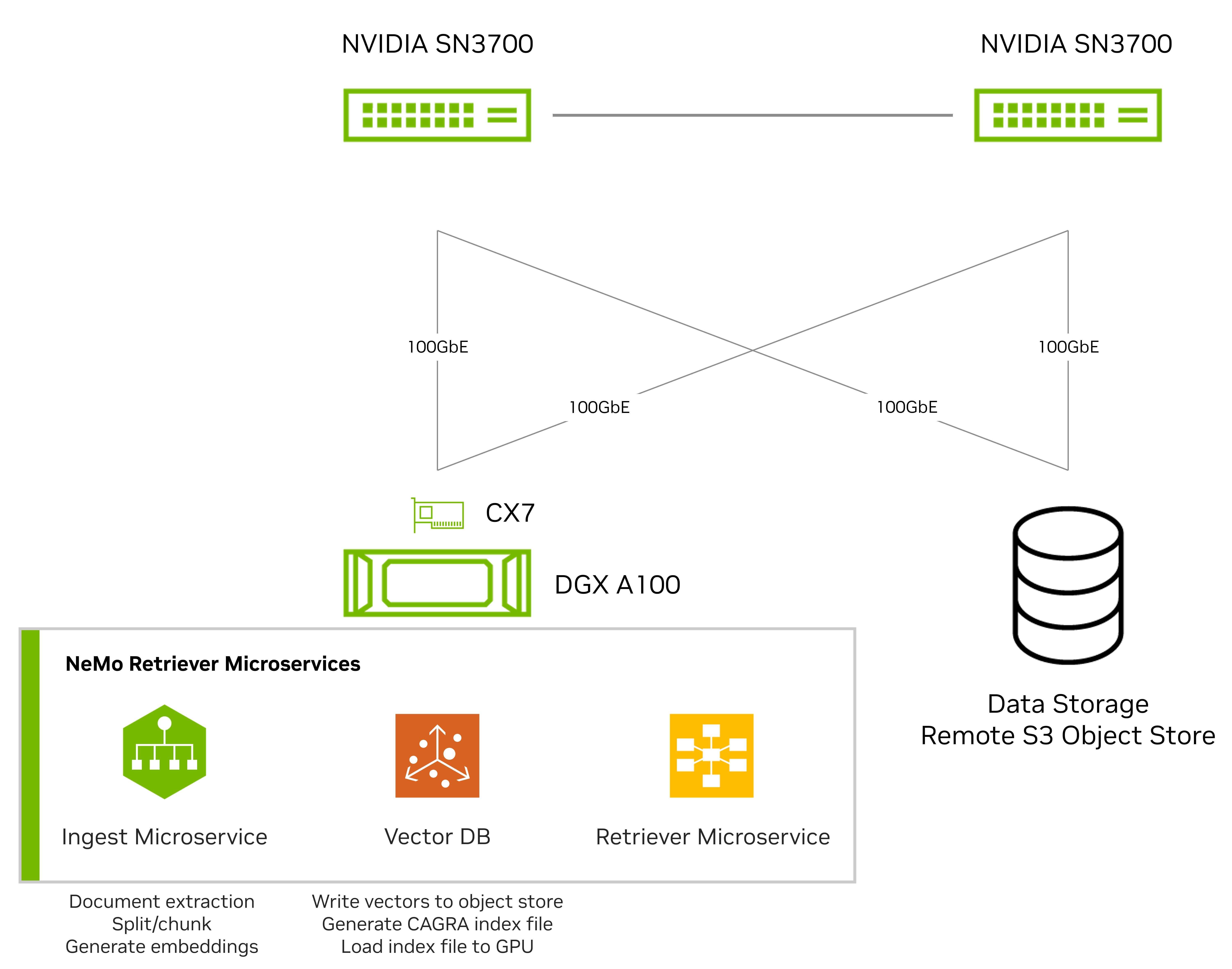
DGX 系統通過 NVIDIA ConnectX-7 網卡 使用加速的 NVMe-over-Fabrics (NVMe – oF) 和 Amazon S3 對象存儲協議,并由兩臺 NVIDIA Spectrum SN3700 交換機連接。
我們使用 NeMo Retriever 微服務 對PDF文檔(包括文本和圖像)的嵌入和索引性能進行了比較。此次比較涉及DGX系統和網絡連接存儲中的直連存儲(DAS)。
圖 3 顯示了單節點數據提取基準測試的結果。它顯示,與使用 DAS 相比,使用 Amazon S3 的網絡連接存儲將數據提取速度提高了 36%,將處理時間縮短了 122 秒。這表明網絡連接存儲是更好的數據提取選擇,同時還依賴于網絡速度和延遲。
加速以太網網絡對于提供穩健、高性能和安全的連接至關重要。除了增強文檔嵌入外,網絡連接存儲還提供各種企業級數據管理功能。
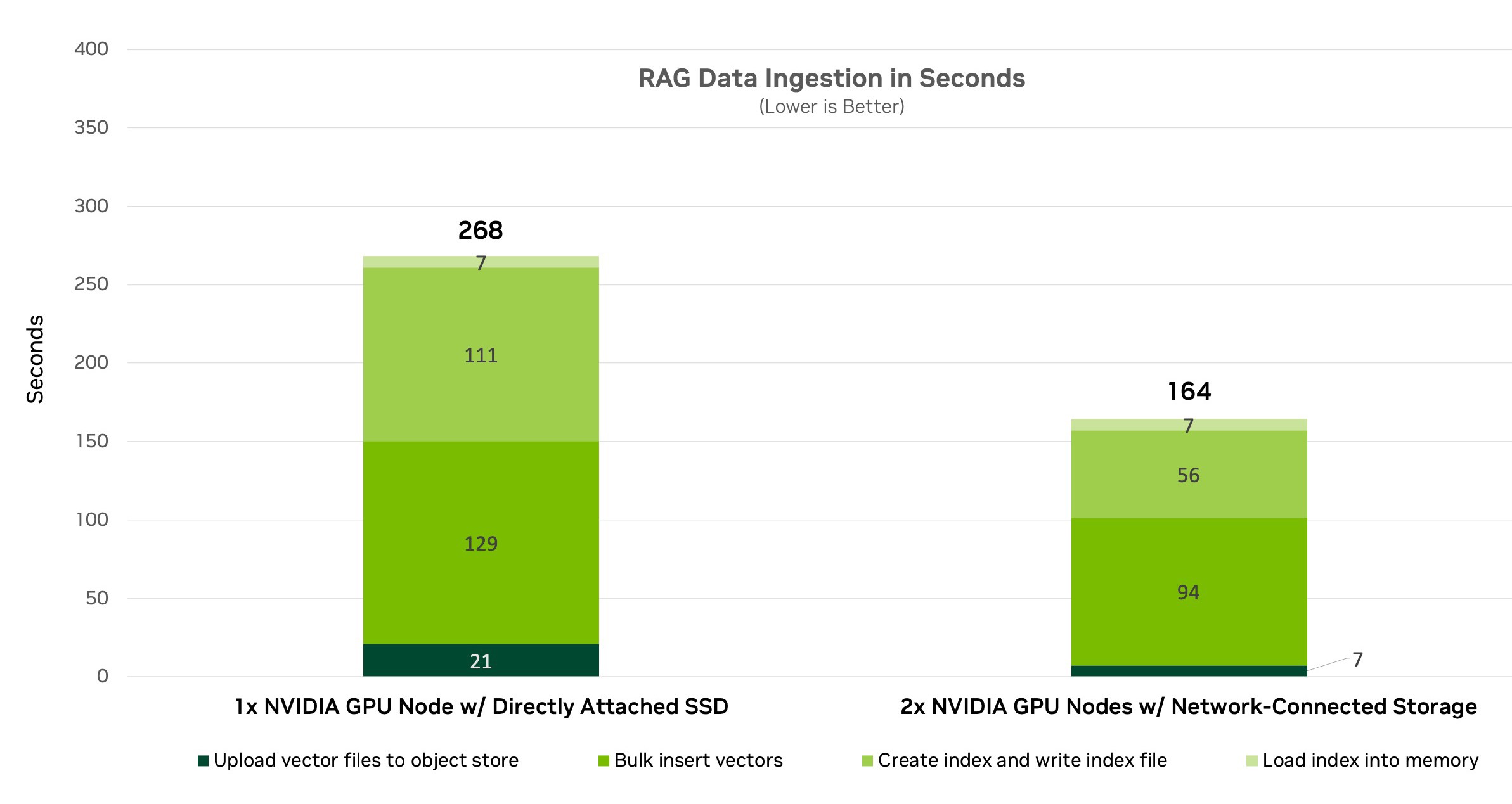
然后,我們使用多節點 RAG 設置進行測試,該設置使用通過 NVIDIA BlueField-3 DPU 連接的分布式微服務架構 (圖 4)。隨著多個節點并行運行,以上傳嵌入、計算索引并插入向量數據庫,性能也隨之提升。
我們比較了在每臺服務器中使用直接連接 SSD 與網絡連接存儲的性能。對于服務器內的 SSD,MinIO 充當對象存儲層。對于網絡連接存儲,我們繞過 MinIO,測試了存儲系統自己的原生 Amazon S3 對象接口。
結果表明,多節點提供的性能比使用單節點更快,處理時間縮短了近 102 秒。這些結果證明了多節點 GPU 加速與企業級網絡連接存儲相結合的性能優勢。
適用于 RAG 驅動型應用程序的網絡連接存儲的優勢
聯網存儲支持通過網絡訪問塊、文件和對象,而無需直接將存儲介質連接到服務器。
聯網存儲不僅為基于 RAG 的應用程序提供了明顯的性能優勢,而且還提供了額外的企業優勢,使其成為增強自然語言處理的最佳數據平臺。
適用于 RAG 工作流程的網絡連接存儲具有以下優勢:
- 實時流數據提取:網絡連接存儲支持從各種來源(例如社交媒體、網絡、傳感器或物聯網設備)提取實時流數據。RAG 應用程序可以使用這些數據生成相關的最新內容。DAS 可能無法處理大量且快速的流數據,或者可能需要額外的處理或緩沖來存儲數據。
- 可擴展性:在不影響性能或數據可用性的情況下,通過添加更多磁盤或設備來擴展存儲容量更容易。相比之下,DAS 的可擴展性有限,可能需要停機或重新配置以進行存儲升級。
- 元數據標注:網絡連接存儲支持使用元數據(例如標簽、類別、關鍵字或摘要)進行數據標注。RAG 應用可使用此元數據根據查詢或上下文檢索數據源并對其進行排名。DAS 可能不支持數據標注,也可能需要單獨的數據庫或索引來存儲元數據。
- 利用率:網絡連接存儲(Network Attached Storage, NAS)可讓多個用戶和應用程序同時訪問相同的數據,從而優化存儲資源的利用率,而不會產生重復數據或沖突。相比之下,直接連接存儲(Direct Attached Storage, DAS)可能會導致存儲未充分利用或過度使用,具體取決于需求和特定服務器內的數據分配。
- 可靠性:網絡連接存儲通過使用高級獨立磁盤冗余陣列 (RAID) 功能或其他方法來保護數據免受磁盤故障、網絡故障或斷電的影響,提高了可靠性和數據可用性。相比之下,直接連接存儲在磁盤或服務器發生故障時,可能會丟失數據或損壞,因為 DAS 無法利用 RAID 或其他冗余技術。
- 刪除重復內容:網絡存儲通過消除跨文件或設備的重復或冗余數據來減少存儲空間和網絡帶寬。DAS 可能會存儲相同數據的多個副本,從而浪費存儲空間和網絡資源。
- 數據來源引文:網絡連接存儲(Network Attached Storage, NAS)可以提供數據的來源引用,例如 URL、作者、日期或許可證。RAG 應用程序(基于規則和知識的應用程序)可以使用這些信息來對數據源進行屬性識別和驗證,并確保所生成內容的質量和可靠性。DAS(直接連接存儲)可能不提供數據來源引用,也可能需要手動或外部方法來跟蹤數據來源。
- 備份:連接網絡的存儲通過使用快照、復制或其他方法在不同位置或設備上創建數據副本來促進數據備份和恢復。DAS 可能需要手動或復雜的備份程序,這可能很耗時或容易出錯。
- 數據保護和保留:網絡連接存儲通過使用加密、壓縮或其他技術來保護數據免遭未經授權的訪問或修改,從而確保數據保護和保留。它還使用策略、規則或法規來管理數據生命周期,例如數據的創建、刪除或存檔。相比之下,直接連接存儲可能不提供數據保護和保留功能,或者可能需要額外的軟件或硬件來實現數據安全和治理。
結束語
檢索增強型生成通過利用生成式 AI 的強大功能 (通過企業特定的環境和信息增強),為企業利用數據提供了巨大的潛力。
但是,大規模部署 RAG 會帶來諸多挑戰,例如管理大型數據集、確保交互式應用程序的低延遲以及滿足生成式 AI 的存儲需求。
為了克服這些挑戰,企業必須擴展其基于 RAG 的生成式 AI 基礎架構。為了高效運行,此基礎架構必須在整個數據中心堆棧 (加速計算、快速網絡、網絡連接存儲和企業 AI 軟件) 中進行適當的規模和架構設計。
生成式 AI 是一個快速增長的新領域。隨著 RAG 的擴展以支持視頻等新模式,數據處理需求繼續快速增長。 NVIDIA 生成式 AI 微服務與多節點 NVIDIA GPU 計算推理、加速以太網網絡和網絡連接存儲相結合,展示了企業級 RAG 推理的效率。
如需詳細了解如何擴展基于 RAG 的生成式 AI 應用,請不要錯過 NVIDIA GTC 2024:
- 通過優化的以太網 AI 網絡實現企業生成式 AI – NVIDIA GTC 會議
- 所有 檢索增強生成 GTC 會議
您可以通過注冊 NVIDIA GTC或按需訪問會話。
?