
在每個行業和每個工作職能部門,生成式 AI 正在激發組織內部的潛力,它將數據轉化為知識,并使員工能夠更高效地工作。
準確的相關信息對于做出數據支持的決策至關重要。因此,企業會繼續投資改進業務數據的存儲、索引和訪問方式。
根據IDC的全球DataSphere Forecast 2023,預計在2024年將創建11ZB的唯一企業數據。到2027年,這一數字預計將增長到20ZB,其中83%為非結構化數據,而音頻和視頻數據將占到一半。2027年創建的非結構化數據量將相當于近800萬個國會圖書館。在企業環境中,必須從分布在不同數據湖中的數據中挖掘這些信息。
用戶可通過多種來源訪問這些信息,包括實時控制面板、包含圖表、圖表和文本混合的手動生成報告、數據庫查詢以及通用搜索工具。
信息的內容和上下文會隨著時間的推移而變化,因此需要反復循環地處理這些來源的信息,并重新評估證據和決策。在回答復雜的業務問題時,此過程可能需要手動處理大量工作,而且非常耗時。這可能會導致信息利用率不足,因為沒有一個簡單的解決方案可以訪問相關數據點。
借助生成式 AI,現在可以構建一個對話式界面,該界面可以使用您的工具并搜索數據來回答問題。換言之,您現在可以與數據進行交流,以做出更快、更明智的決策。 NVIDIA NeMo Retriever 可以在此過程的每個步驟中提供幫助。
什么是 NVIDIA NeMo Retriever?
NVIDIA NeMo 的一部分,NeMo Retriever 是一個用于開發自定義生成式 AI 的端到端平臺,支持對企業數據的語義搜索,從而提供高度準確的檢索增強響應。開發者可以利用各種 GPU 加速微服務,每種服務都針對特定的任務進行了優化,例如:
- 以 PDF 報告、Office 文檔和其他富文本文件的形式提取大量文檔。
- 對上述內容進行編碼和存儲,以進行語義搜索。
- 與現有關系數據庫交互。
- 搜索相關信息以回答業務問題。
這些微服務基于 CUDA 構建,NVIDIA TensorRT, NVIDIA Triton 推理服務器 以及 NVIDIA 軟件套件中的許多其他 SDK,可最大限度地提高易用性、可靠性和性能。
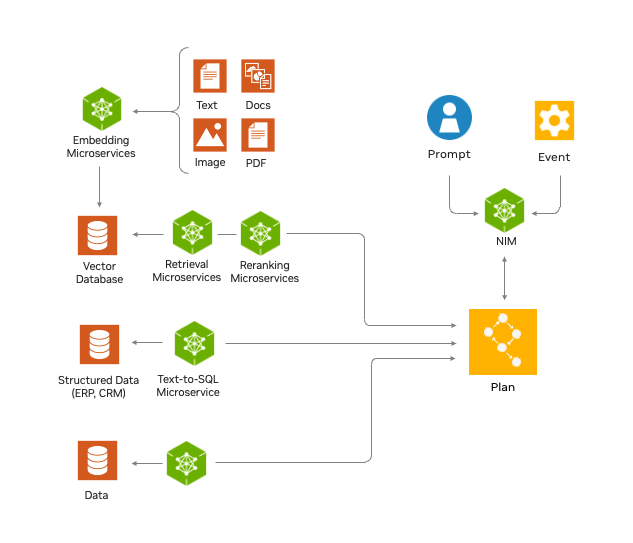
回答復雜的業務問題通常需要有效的規劃和專用工具,并從分布在不同模式下的數據中提取信息(圖 1)。這可以通過構建由 LLM 驅動的 AI 代理來實現。為了提供有關由 NeMo Retriever 提供支持的建筑代理的指南,微服務打包了多個參考代理。
這些微服務和智能體可讓人類專注于“提出和回答正確的問題”,從而加速從大量數據中提取信息的過程,而這些問題通常很復雜,需要掌握相關領域的專業知識,而無需花費時間進行耗時的手動工作,即查找和編譯相關信息以回答這些問題。
解鎖全球企業數據
包括 Adobe、Cloudera、Cohesity、DataStax、NetApp 和 Pure Storage 在內的數據平臺公司正在與 NVIDIA 合作,利用 NeMo Retriever 將其數據轉化為寶貴的商業見解。
- Adobe 的專有 AI 將幫助解鎖全球超過 3 萬億個 PDF 的知識。
- Cloudera 將通過將 NeMo Retriever 與 Cloudera Machine Learning 集成來擴展其生成式 AI 功能,以釋放 25 EB 的企業數據潛力。
- Cohesity 數據平臺客戶可以在數據備份和存檔中添加生成式 AI 智能。
- DataStax Astra DB 利用 NVIDIA NeMo Retriever 和 NVIDIA NIM 推理微服務,提高 RAG 應用程序的性能。使用 NVIDIA H100 GPU,它們實現了 10 毫秒的嵌入和索引延遲。
- NetApp 可解鎖 EB 級數據,使客戶能夠安全地“與其數據對話”,以獲取業務見解。
- Pure Storage 利用 NeMo Retriever 微服務以及 NVIDIA GPU 和 Pure Storage 創建了一個 RAG 工作流,用于全閃存企業存儲。因此,Pure 可以加快企業使用自己的內部數據進行 AI 訓練的速度,確保使用其最新數據,并消除對 LLM 不斷重新訓練的需求。
企業檢索用例
一旦企業能夠輕松訪問其信息,他們可以通過無數種方法更好地利用信息。本節探討了一些用例。在每種情況下,回答商業問題都需要回答一系列有針對性的問答,而這些答案只能通過從不同模式和數據存儲中提取信息來生成。
分析軟件安全漏洞
對軟件容器進行常見漏洞和暴露 (CVE) 分類的過程需要從各種不同的數據源搜索數百條信息,而這一繁瑣的手動過程可能需要幾天時間。事件觸發的 LLM 代理通過執行許多感知 – 推理 – 動作循環來實現此過程的自動化,就像它與自身對話一樣。使用 NVIDIA NIM 推理微服務、NeMo Retriever 和 NVIDIA Morpheus 網絡安全 AI 框架可以將這一過程縮短到幾秒鐘。
解決技術問題
考慮以下場景:網絡解決方案工程師正在診斷數據中心中的問題。該工程師必須檢查機器日志和系統指標,以更好地了解當前的情況。工程師還必須查找單個組件的特定信息片段和行為,以進一步識別受影響的組件。這些信息分布在各種來源中,例如技術文檔、原理圖和供應商 SKU 目錄 (圖 2)。
技術診斷是一個迭代過程。工程師通常需要從問題中反向工作,在多個硬件和軟件層之間瀏覽一系列單獨的組件,以找到根本原因。每個組件都有不同的實用程序,并在更大的系統架構中服務于特定用途。迭代過程包括查找有關這些組件的信息,判斷日志中的行為是否符合預期行為,在發生意外行為時識別替代方案,然后做出決策。
為主題專家提供特定案例信息的對話式訪問權限可以節省時間和精力,使他們能夠專注于應用其技術專業知識。這意味著減少停機時間和提高效率會節省成本。無論是在生產車間中斷的工廠,還是遇到網絡問題的 IT 設施,這種情況都很常見。
用于金融分析的 Copilot
財務分析師投入大量時間整理報告、會計核算表、市場數據、宏觀經濟趨勢等,以評估企業的前景。具體來說,可以考慮由 NVIDIA 負責評估最新收益結果的分析師。該分析師可能會審查 文稿和新聞稿、CFO 評論、10-K 和 10-Q 報告,以及季度演講,同時還會分析存儲在結構化數據庫中的專有模型結果。
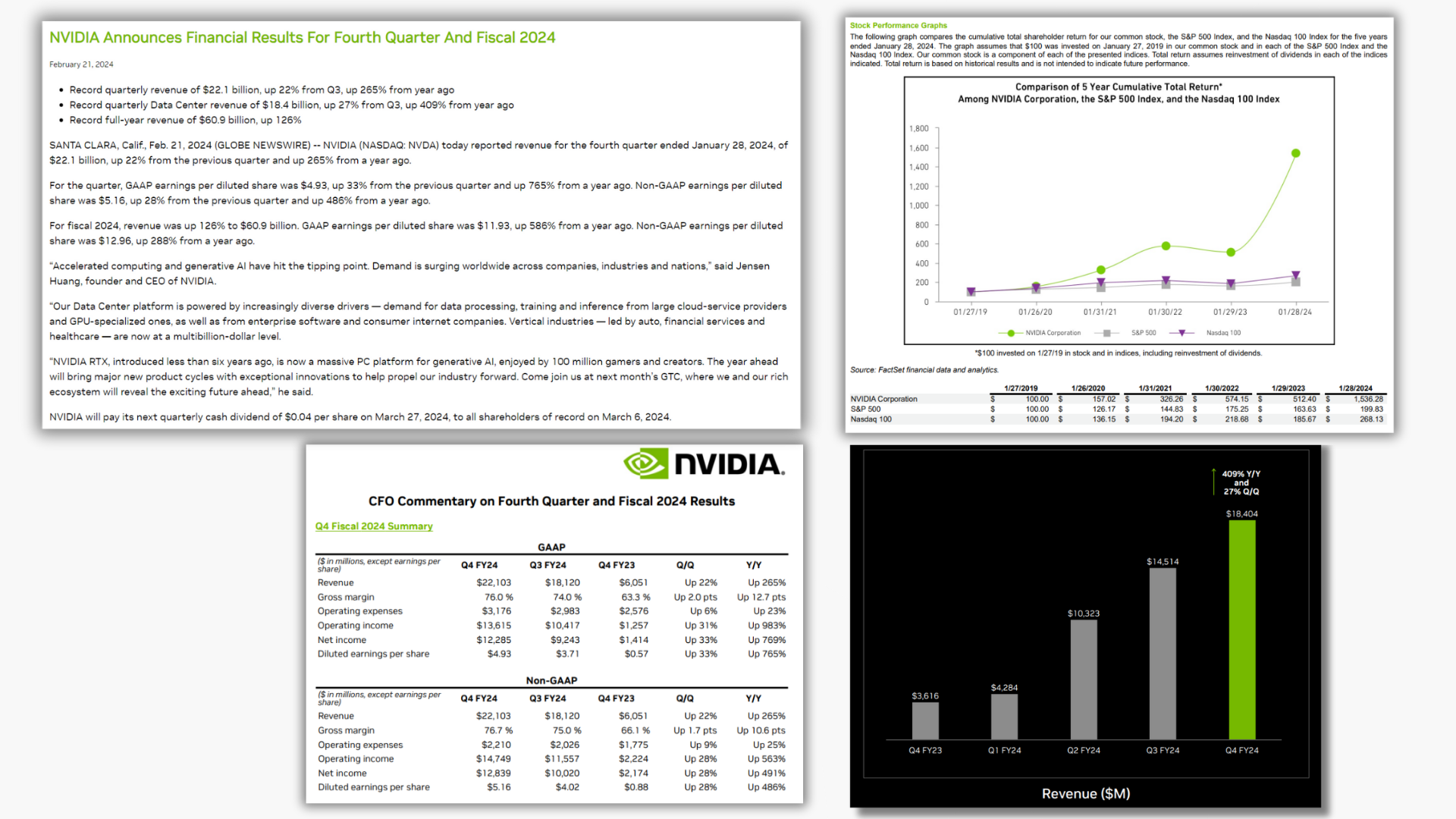
財務分析師可能會提出以下問題:
- “ NVIDIA 最近一個季度的要點是什么?”
- “在過去九個月中, NVIDIA 的自由現金流量發生了多少變化?”
- “與標準普爾 500 指數相比,NVDA 的表現如何?”
這些是分析師可能會花費大量時間研究的基本必備背景問題。回答這些問題所需的數據通常通過引用不同季度的多個報告,從不同的現金流量表中提取信息來找到。通過簡化跨多個來源提取數據的過程,分析師可以專注于其關鍵的創收任務:編寫包含公司業績審查的報告。
企業運營
銷售和運營團隊需要訪問有關客戶關系、金融交易和產品庫存的數據。他們還需要利用有關市場趨勢、競爭格局和財務分析的大量報告,這些報告經過編譯后可用于制定業務決策。
此外,在深入研究細節時,通常需要使用 SKU 目錄、供應商信息、主題專家評論和其他項目作為參考。這些數據通常包含在組織孤島、控制面板或單個員工中。因此,由于跨來源的碎片化,這些數據可能未得到充分利用。
收入是銷售團隊的一項關鍵績效指標。要找到正確的信息,需要瀏覽多個數據源。無論團隊是計劃下季度、教育客戶并為客戶提供支持,還是完成交易,用于訪問相關信息的統一對話界面都有助于簡化流程,并使賣家能夠將其專業知識專注于創收任務。
總結
與許多用例一樣,本文中介紹的用例需要訪問分布在各種模式和數據存儲中的信息,以打造一個可以簡化回答復雜業務問題的系統。NeMo Retriever 可更大限度地提高必要基礎設施的易用性、可靠性和性能,使用戶能夠“與其數據通信”。
要開始構建使用檢索增強生成的應用程序,您可以探索 NVIDIA API 目錄,并參考 NVIDIA 生成式 AI 示例。此外,要了解如何將 RAG 應用從試點階段遷移到生產階段,請參閱 如何通過四個步驟將 RAG 應用程序從試點階段轉變為生產階段。
1資料來源:IDC,Global DataSphere Forecast,2023 年
?






