
GPU 最初專用于在電子游戲中渲染 3D 圖形,主要用于加速線性代數計算。如今,GPU 已成為 AI 革命的關鍵組成部分之一。
現在,我們依靠這些主力來完成深度學習工作負載,處理龐大而復雜的半結構化數據集。
然而,隨著對基于 AI 的解決方案的需求大幅增加,獲取高端 GPU 變得更加困難,更不用說為自己的用例設置和配置高端 GPU 所帶來的投資了。
NVIDIA DGX 云
為滿足 AI 訓練需求,NVIDIA 提供先進的加速計算資源,供用戶訪問,而無需自行尋找、設置和配置基礎設施。對于希望突破深度學習范式所能完成的工作的 AI 團隊來說,NVIDIA DGX Cloud 提供了一場游戲變革。
除了訪問云端的 AI 超級計算之外,您還必須構建代碼并圍繞代碼進行計算,以提高 AI 應用程序的效率和性能。根據我們的經驗,要做到這一點,最好的方法是使用 AI 編排:基礎設施、代碼、數據和模型之間的交集。
在本文中,我很高興介紹 Union 的 NVIDIA DGX Agent,它使您能夠將 Flyte 工作流與 NVIDIA DGX 云集成。這項合作旨在為希望管理 GPU 密集型工作負載的復雜性和成本的團隊普及生產 AI 工作流。
借助 Union 的多云結構和核心開源編排器 Flyte,我將向您展示如何將 AI 工作流容器化、生產化和迭代的頭痛轉變為代碼中的單行配置更改。
工作流程為何重要
Union 旨在簡化和抽象化生產級 AI 編排的低級細節,以便 ML 工程師和數據科學家可以專注于從數據中創造價值。
例如,了解 Repl.it 如何針對其編碼專業模型微調 LLM (圖 1)。
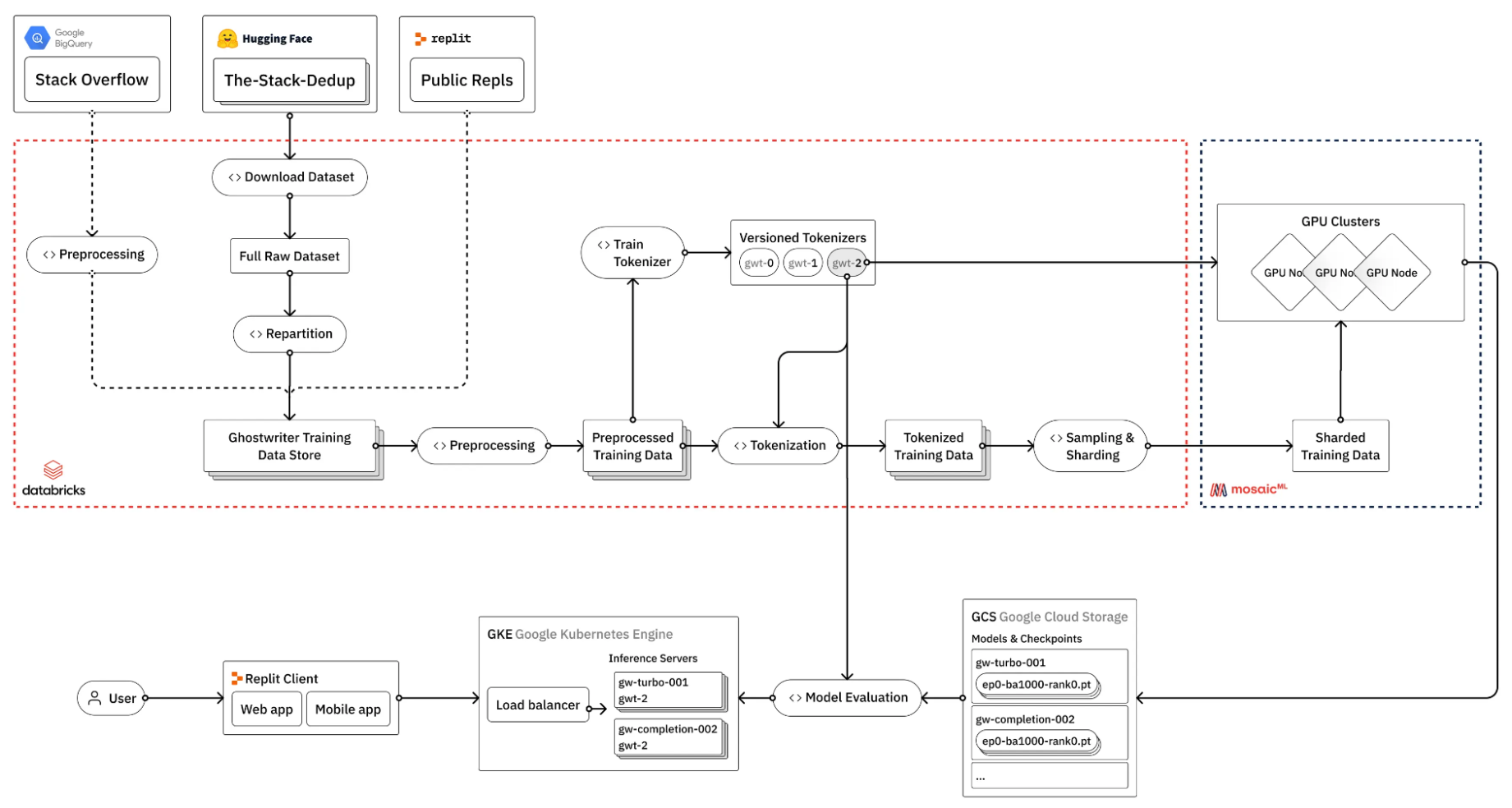
(來源:如何訓練自己的大型語言模型)
圖 1 顯示微調 LLM 的過程涉及許多步驟,其中許多步驟不一定需要 GPU.那么,如何管理此類流程的復雜性呢?
在 AI 模型開發過程中,工作流程實際已成為管理數據復雜性和模型管理的抽象概念。
Flyte 是 Linux 基金會的開源項目,由 Union 聯合創始人在 Lyft 發起,旨在使您的數據和機器學習流程具有可再現性和可擴展性。以下是實現這一點的一些核心功能:
- 任務:將任務視為數據或機器學習流程中的單個步驟,每個步驟都有自己的輸入和輸出。例如包括訓練、數據轉換、預測等。
- 工作流程:當您將這些步驟串聯起來時,便形成一個工作流程。它就像一個食譜,其中每個任務在正確的時間點被添加。
- 聲明性資源管理:與以前不同,技術水平有了提高。每個任務都有自己的資源需求,這意味著它可以明確告訴 Flyte 需要多少計算能力來完成特定工作。
- 智能體:代理作為中介,將 Flyte 連接到 DGX 云等外部服務,以簡化對 Flyte 核心能力之外的服務的調用。
以下代碼示例展示了這些元素如何在高層次上交互:
from collections import NamedTuple import pandas as pd import torch.nn as nn from flytekit import task, workflow, Resources from flytekit.extras.accelerators import T4 from flytekitplugins.spark import Databricks @task(task_config=Databricks(...)) def create_data() -> pd.DataFrame: ... @task(requests=Resources(gpu="4"), accelerator=T4) def train_model(data: pd.DataFrame) -> nn.Module: ...@workflowdef model_training_pipeline() -> nn.Module: train_data, test_data = get_data() model = train_model(data=train_data) return model |
此示例使用 Databricks 任務配置來執行 `create_data` 任務,它利用四個 NVIDIA T4 Tensor Core GPU,并使用 Flyte 的原生加速器聲明語法來創建訓練數據。
在 Flyte 中,Repl.it 微調流程如下所示:
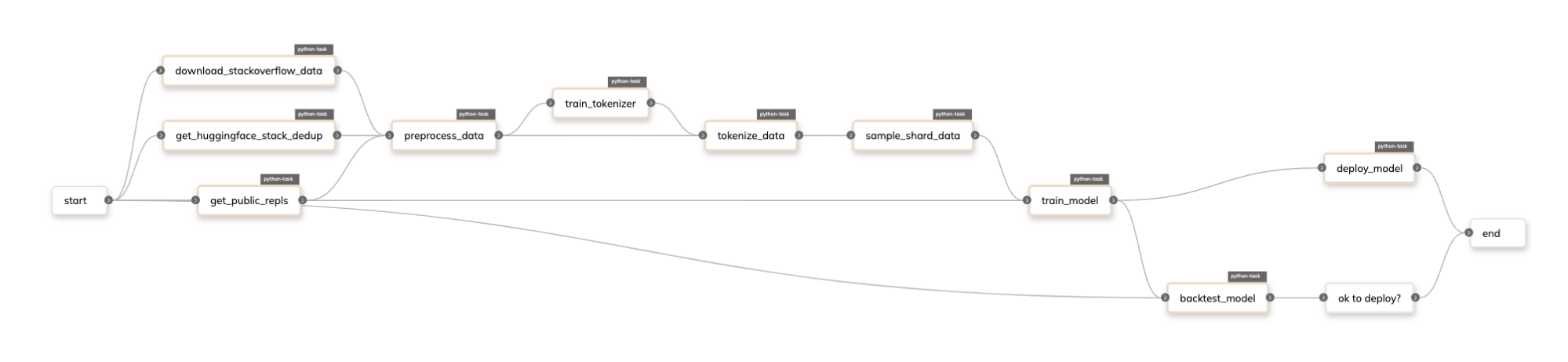
隆重推出 Union 的 NVIDIA DGX 智能體?
假設您正在微調 Mixtral 8x7b 模型。盡管 Flyte 可以為您的工作負載配置 GPU,但您仍然可能會受到傳統云提供商 (例如 Amazon Web Service、Google Cloud Platform 和 Microsoft Azure) 無法提供某些類型 GPU 的限制。
要利用 DGX 云繞過此限制,您必須執行以下操作:
- 在本地或基于云的 IDE 上開發模型訓練工作流。
- 容器化您的代碼和依賴項。
- 將鏡像推送到 NVIDIA 容器注冊表。
- 在云端出現問題時調試代碼。
- 返回到步驟 2,沖洗,然后重復。
借助 Union,這項艱巨的任務將變得更加順暢。我們為您提供工具,讓您可以通過代碼中的單行配置輕松利用 DGX 云的功能,將原本復雜的操作轉變為簡單的過程。
假設您有一個名為 Flyte 的任務,fine_tune 對 Mixtral 8x7B 模型進行微調:
from datasets import load_dataset from transformers import ( AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments, ) from trl import SFTTrainer @taskdef fine_tune(dataset_name: str, output_dir: str): # load model, tokenizer, and dataset model = AutoModelForCausalLM.from_pretrained( "mistralai/Mixtral-8x7B-v0.1", quantization_config=BitsAndBytesConfig(load_in_4bit=True), device_map="auto", torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained( "mistralai/Mixtral-8x7B-v0.1", use_fast=True) dataset = load_dataset(dataset_name, split="train") # configer training arguments and trainer training_args = TrainingArguments(...) trainer = SFTTrainer(...) # train and save the model trainer.train() trainer.save_model(output_dir) |
要使用 Flyte 和 Union 的 NVIDIA DGX 智能體,請在任務配置中添加 `DGXConfig` 任務和所需的依賴項,以及附帶的文件:`dgx_image_spec` 代理插件。
from flytekitpligins.dgx import DGXConfig, dgx_image_spec fine_tuning_image_spec = dgx_image_spec.with_packages([ "accelerate", "datasets", "torch", "transformers", "trl",]) @task( task_config=DGXConfig(instance="dgxa100.80g.8.norm"), container_image=fine_tuning_image_spec, ) def fine_tune(dataset_name: str, output_dir: str): ... |
代碼示例使用 `dgxa100.80g.8.norm` 實例,這是一個包含 8 個 NVIDIA A100 Tensor Core GPU 的單節點。您可以將其用于訓練。對于多節點訓練,代理插件還提供一個 `DGXTorchElastic` 配置類,可讓您進一步擴展工作負載。
NVIDIA DGX 智能體提供實用程序,以將您的數據安全地遷移到云原生 Blob 存儲 (Amazon S3、GCS、Azure Blob Storage) 到 DGX 云的 Blob 存儲系統。結合 Flyte 的緩存功能,您可以管理數據出口成本,以進一步控制成本。有關更多信息,請參閱 聯盟 AI 平臺上的文檔。
立即體驗先進的加速計算!
如果您正在深入研究 AI 開發,卻發現自己在與 GPU 短缺或設置問題作斗爭,那么值得仔細了解一下 Union 的多云結構。它旨在簡化您的收購流程,讓您更專注于開發,而不是管理和維護硬件或云服務的物流。
準備好簡化您的 AI 項目了嗎?聯系聯盟團隊,深入了解代碼,看看您的生活會變得更加輕松。使用合適的工具,正面應對這些 AI 挑戰。
?





