最新版本的 CUDA 工具包,即 版本 12.4,繼續利用最新的 NVIDIA GPU 來推動加速計算性能。本文將介紹此版本中包含的新功能和增強功能:
- CUDA 驅動程序更新
- 適用于 NVIDIA Grace Hopper 系統的基于訪問計數器的內存遷移
- 機密計算支持
- CUDA 圖形條件語句
- CUB 性能提升
- 編譯器更新
- 增強的監控功能
- 增強 NVIDIA Nsight Compute 和 NVIDIA Nsight Systems 開發者工具。
CUDA 和 CUDA 工具套件軟件為數據科學和分析、機器學習、使用大型語言模型 (LLM) 進行深度學習的所有 NVIDIA GPU 加速計算應用程序提供基礎 .CUDA 軟件堆棧和生態系統提供一個平臺,幫助開發者解決全球極為復雜的計算問題,尤其是在多 GPU 和多節點分布式架構中。
適用于 Linux (R550) 和 Windows (R551) 的 CUDA 驅動
每個 CUDA 工具包版本都需要最低版本的 CUDA 驅動程序。CUDA 驅動程序具有向后兼容性,這意味著使用特定版本的 CUDA 編譯的應用程序將繼續在后續版本的驅動程序中運行。有關兼容性的更多信息,請參閱 CUDA C++最佳實踐指南。
適用于 NVIDIA Grace Hopper 顯存的基于訪問計數器的遷移
此版本引入了一種新的內存遷移算法,適用于 NVIDIA Grace Hopper 系統。它使用硬件訪問計數器來確定內存頁面的訪問模式,并將內存從訪問頻率最高的硬件內存(CPU 或 GPU)遷移到硬件內存。這種遷移可以通過標準調用(如malloc和mmap)實現,并且可以從第三方庫直接在GPU加速核函數中調用。
由于此是首次啟用此功能的版本,因此開發者可能會發現,針對早期內存遷移算法進行優化的應用程序如果針對早期行為進行優化,則可能會出現性能反彈。如果出現這種情況,我們引入了一個受支持但臨時的標志,以退出此行為。您可以通過卸載和重新加載 NVIDIA UVM 驅動程序來控制此功能的啟用情況:
# modprobe -r nvidia_uvm# modprobe nvidia_uvm uvm_perf_access_counter_mimc_migration_enable=0 |
將參數設置為 1 將啟用基于訪問計數器的遷移,將其設置為 0 將禁用它。
NVIDIA 機密計算
NVIDIA 機密計算適用于 NVIDIA Hopper 架構的解決方案現已推出,可供大眾使用。保護您的工作負載免受未經授權的訪問和物理攻擊。有關更多信息,請訪問 NVIDIA 可信計算解決方案.
CUDA Graphs 增強功能
CUDA Graphs API 繼續是啟動復雜設備功能序列重復調用的最高效方式 .CUDA 工具包 12.4 引入了許多 CUDA Graphs 增強功能,包括條件節點、設備端節點參數更新等。
圖形條件節點
在許多應用程序中,對 CUDA 圖形中的工作執行動態控制可顯著提高圖形啟動的靈活性和易用性。例如,您可能有一個算法,涉及多次對一系列操作進行迭代,直到結果收斂在某個閾值以下,這在 AI 中很常見 .CUDA 工具包 12.4 改進了用于實時控制條件圖節點的 API,這是 12.3 版本中引入的功能。
條件節點可以包含由圖形描述的工作,這些工作可以在條件或循環中執行。此外,現在還可以在條件節點體內的內存分配節點中使用新的子圖形類型,以及新的捕捉功能來捕捉這些子圖形。
設備端節點參數更新,用于設備圖形
借助 CUDA 工具包 12.4,現在可以通過設備端 API 動態更新內核節點參數 (網格幾何圖形和其他內核參數)。在創建圖形時,節點可以通過一個新的內核節點屬性“選擇”成為可通過設備更新的節點,該屬性在啟用時將返回設備節點setAttribute呼叫。
設備可更新的內核節點可以從任何其他內核更新,無論是另一個圖形、同一個圖形,甚至是流內核啟動。
一旦節點選擇啟用“device-updatable”(可更新設備),它便無法通過 cudaGraphnodeDestroy 從圖形里去除。如果節點選擇了此功能,則無法再選擇退出具有設備更新功能,也無法在選擇此功能后更新到另一個設備或上下文中的功能。
要啟用此功能,請將屬性CU_KERNEL_NODE_ATTRIBUTE_DEVICE_UPDATABLE_KERNEL_NODE創建節點后,可以使用以下 API 調用控制節點參數:
cudaGraphKernelNodeSetGridDimcudaGraphKernelNodeSetEnabledcudaGraphKernelNodeSetParam
無需重新編譯即可更新可更改的圖形節點優先級
在從流中錄制圖形節點時,通常希望在捕獲時記錄并尊重圖形節點的流優先級,而不是使用啟發式算法分配優先級 .CUDA 工具包 11.7 引入了這種功能,允許所有圖形節點以這種方式工作,使用傳入cuGraphInstantiate。但是,要求使用編譯時標志可能會讓用戶無法在不進行全部重新編譯的情況下在使用記錄和啟發式配置文件之間進行切換。
CUDA 工具包 12.4 引入了新的環境變量CUDA_GRAPHS_USE_NODE_PRIORITY以便在運行時控制圖形節點優先級。環境變量按照表 1 中列出的行為運行。
CUDA_GRAPHS_USE_NODE_PRIORITY值 |
UseNodePriority在圖形實例化時的行為 |
| 0 | UseNodePriority在所有圖形實例化過程中 |
| 非零 | UseNodePriority在所有圖形實例化中設置 |
| 未設置 | 通過圖形實例化傳遞的旗幟 (或默認旗幟值) |
CUDA_GRAPHS_USE_NODE_PRIORITY環境變量設置CUB 性能提升
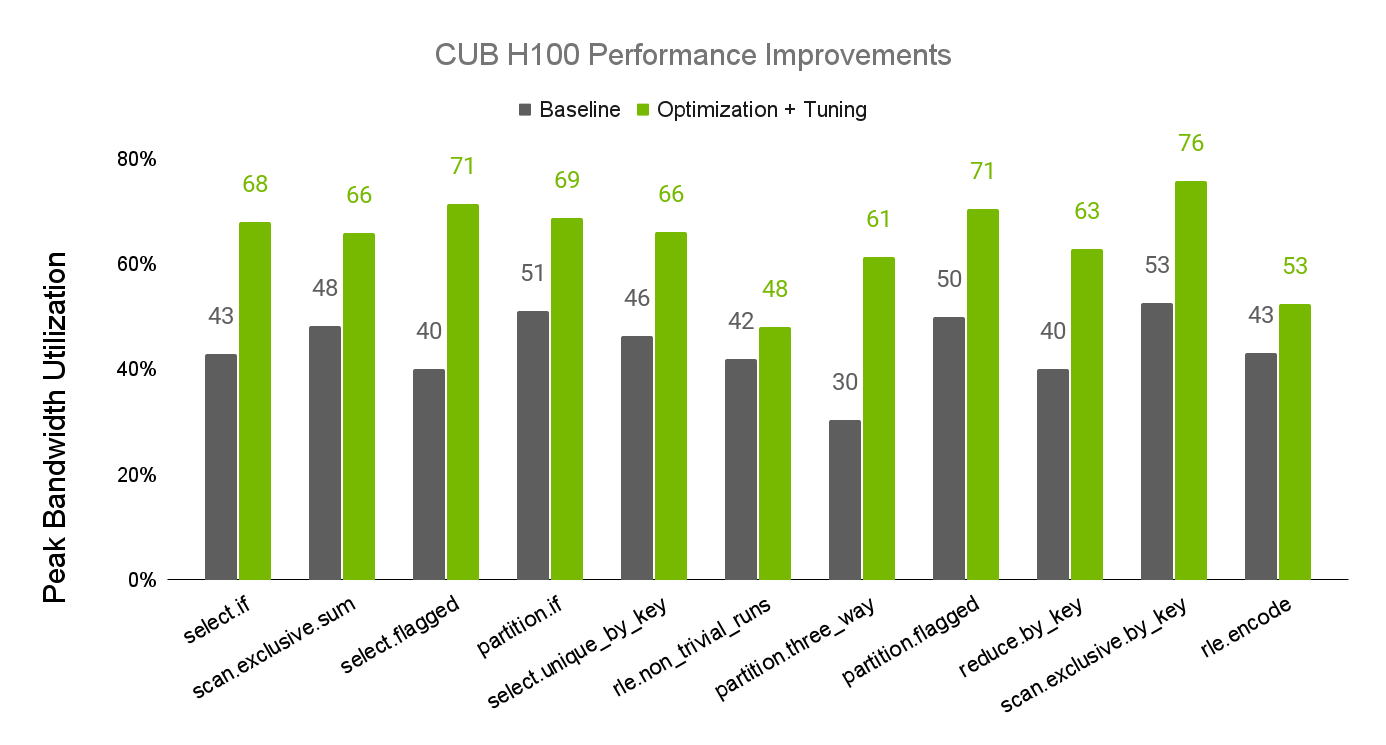
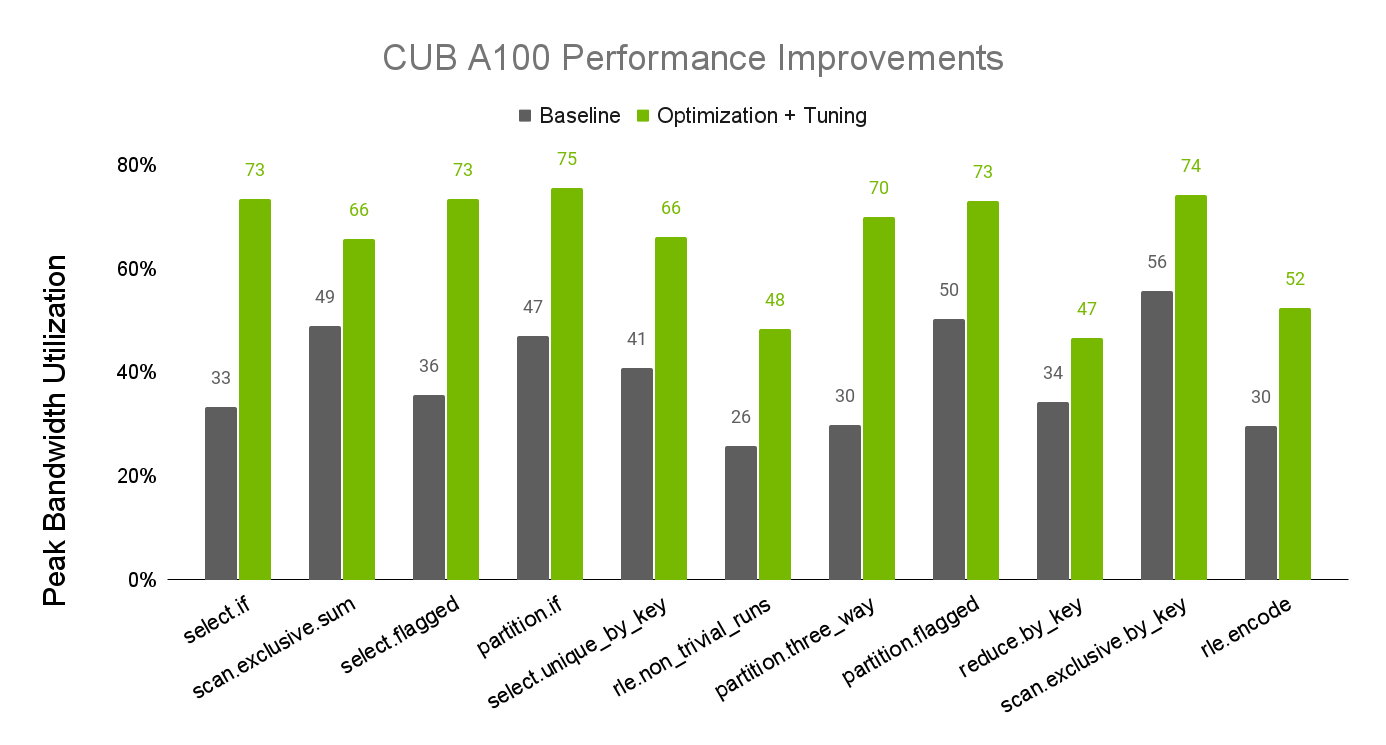
CUB 是 CUDA C++核心庫的一部分,可在 CUDA 工具包和 NVIDIA/cccl的 GitHub 上找到。最近對 CUB 性能的調整更新顯著提高了 CUB 算法在 NVIDIA A100 和 H100 GPU 上的性能。圖 1 和圖 2 顯示了算法性能提升的情況,這是根據可用設備內存帶寬的實現百分比測量得出的。
有關 CUB 性能調整的更多信息,請參閱 CUB 調整基礎架構文檔。
編譯器更新
CUDA 工具包 12.4 版增加了對 GCC 13 作為主機端編譯器的支持,并提高了編譯時間性能。此外,還提供了一個新庫,nvFatbin,以便對多 GPU 架構支持的二進制對象進行運行時操作。此庫能夠以編程方式創建較大的二進制文件,從而更輕松地處理運行時編譯。
增強的監控功能
此版本為 NVIDIA 管理庫 (NVML) 和 NVIDIA 系統管理接口 ( nvidia-smi ) 提供了許多新的指標,從而大幅提升了對整體 GPU 利用率的可見性:
- NVJPG 和 NVOFA 利用率百分比
- PCIe 類別和分類報告
dmon報告現已以 CSV 格式提供- NVML 返回更具說明性的錯誤代碼
dmon現在報告 MIG 的 gpm 指標 (即nvidia-smi dmon --gpm-metrics在 MIG 模式下運行)- 使用舊版驅動程序運行的 NVML 將報告
FUNCTION_NOT_FOUND。某些情況下,如果 NVML 比驅動程序更新則會優雅的失效 - NVML API,用于查詢適用于 Hopper 機密計算的保護內存信息
有關更多信息,請參閱 NVML 文檔 和 NVIDIA 系統管理接口文檔。
NVIDIA Nsight 開發者工具
最新版本的 NVIDIA Nsight 開發者工具 已包含在 CUDA 工具包 12.4 版中,可幫助您在 Grace Hopper 平臺上優化和調試 CUDA 應用程序。
NVIDIA Nsight Compute
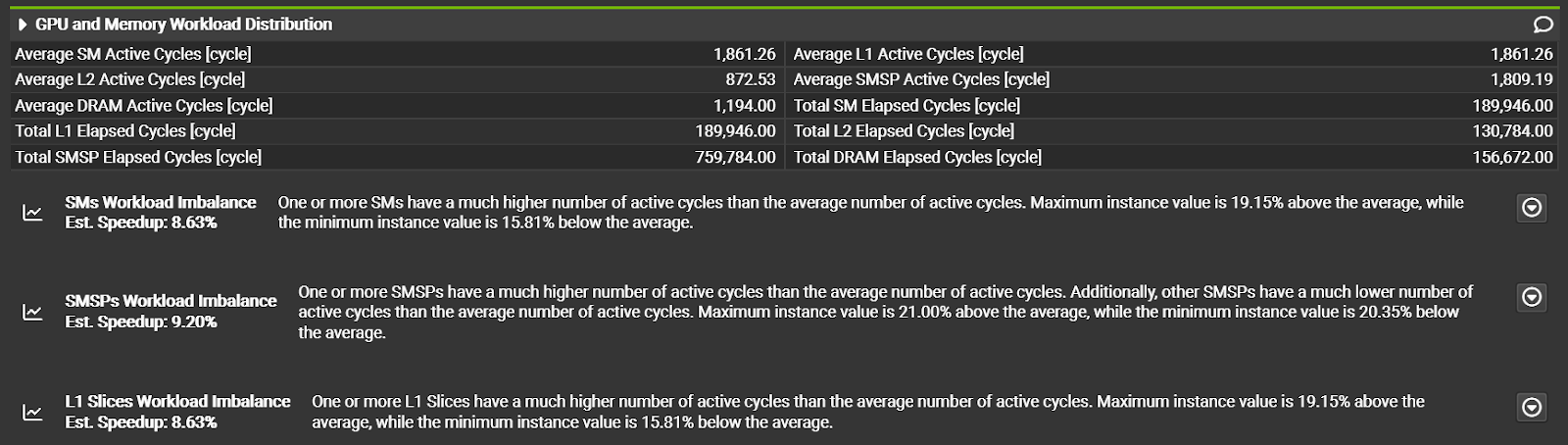
NVIDIA Nsight Compute 提供了對 CUDA 內核的詳細分析和性能分析。在 2024.1 版本中,首次引入了 CUDA 工具包 12.4 的支持。此版本的 Nsight Compute 新增了 GPU 和顯存工作負載分布的分析部分,幫助用戶了解不同 SM 之間的任務負載平衡,以及顯存系統的使用情況。內置的規則可以識別不平衡的負載分布,這可能對性能產生影響。利用這些新功能和規則來檢測并優化潛在的不平衡工作負載分布,以最大程度地提高性能。
此外,新的“PM Sampling Warp State”(PM 采樣扭曲狀態) 部分提供更詳細的時間相關性性能信息,并對最近添加的“Source Comparison”(來源比較) 頁面進行了幾項改進。
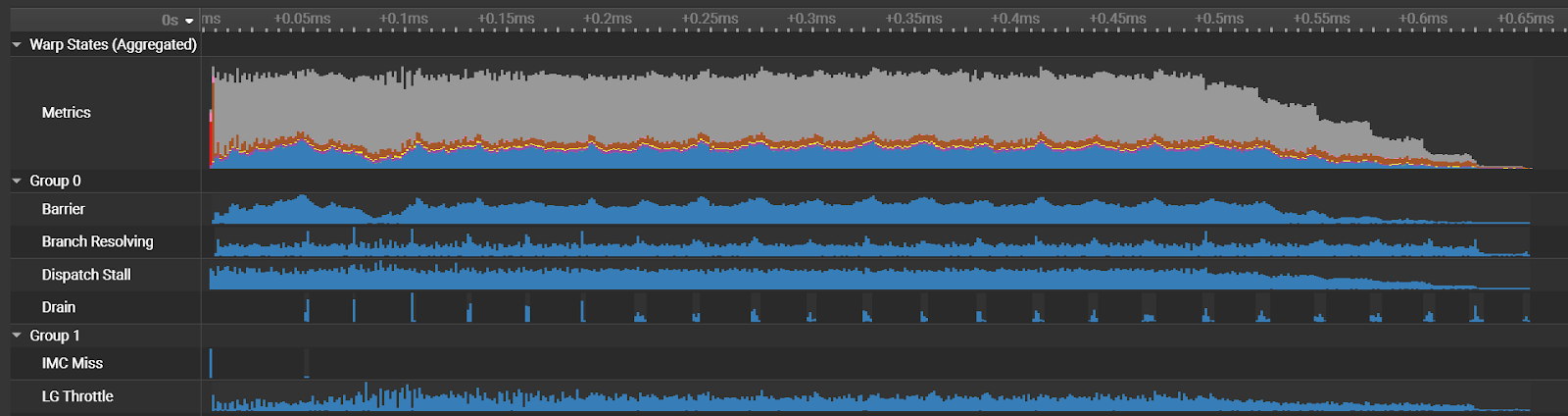
如需詳細了解 Nsight Compute 2024.1 功能,請參閱 Nsight Compute 入門。
NVIDIA Nsight Systems
CUDA 工具包 12.4 還包括 NVIDIA Nsight Systems,這是一款性能調整工具,可以在統一的時間軸上分析硬件指標以及 CUDA 應用程序、API 和庫。
Nsight Systems 提供了多節點分析腳本,即 recipe。這些腳本可以自動分析跨數據中心捕獲的指標,幫助您診斷性能限制因素。新的 recipe 提供了關于 NVIDIA 集合通信庫 (NCCL) 的執行時間信息。此外,對多節點分析的支持已擴展至 Mac、Windows x64 和 Linux Arm 服務器。
如需詳細了解 Nsight Systems 中的新功能,請參閱 Nsight Systems 入門。如需深入了解 Nsight Systems 如何支持數據中心規模的開發,請參閱 借助 NVIDIA Nsight Systems 加速數據中心和 HPC 性能分析。
總結
CUDA 工具套件 12.4 版增強了基礎 NVIDIA 驅動和運行時軟件,為加速計算提供支持,同時繼續為最新的 NVIDIA GPU、加速庫、編譯器和開發者工具提供增強支持。
想要了解更多信息?請查看 CUDA 文檔,瀏覽最新的 NVIDIA 深度學習學院 產品,并訪問 NGC 目錄。提出問題并加入討論,CUDA 開發者論壇。
?