VISTA-2D 是 NVIDIA 的新基礎模型,可以快速準確地執行細胞分割,這項基本任務在細胞成像和空間組學工作流程中至關重要,對所有下游任務的準確性至關重要。
VISTA-2D 模型使用圖像編碼器創建圖像嵌入,然后將其轉換為分割蒙版(圖 1)。這些嵌入必須包含每個細胞的形態信息。

如果可以為每個細胞分割生成嵌入,則可以在所有嵌入上運行聚類,以自動將具有類似形態的細胞分組。
在本文中,我將帶您深入了解隨附的 Jupyter Notebook,以展示如何使用這些工具首先分割細胞并使用 VISTA-2D 提取其空間特征,然后使用 RAPIDS。這將創建一個自動化流程來快速分類細胞類型。
預備知識
要學習本教程,您需要以下資源:
- 基本熟悉 Python、Jupyter 和 Docker
- Docker 版本 19.03 及更高版本
啟動 notebook
此 Jupyter Notebook 的代碼位于 /clara-parabricks-workflows/vista2d_rapids_clustering GitHub 庫中,并在 NVIDIA 的 PyTorch Docker 容器 內運行。此 Notebook 使用該容器的 24:03-py3 標簽構建。使用以下命令運行容器:
docker run --rm -it \ -v /path/to/this/repo/:/workspace \ -p 8888:8888 \ --gpus all \ nvcr.io/nvidia/pytorch:24.03-py3 \ /bin/bash |
此命令會啟動以下操作:
- 啟動 Docker 容器。
- 將資源庫的文件夾安裝到容器中。
- 將主機上的端口 8888 映射到 Docker 中的端口 8888。
- 將所有可用的 GPU 分配給容器。
- 啟動 PyTorch 容器。
- 返回終端。
接下來,您需要一些其他的 Python 包,這些包可以在 requirements.txt 中找到。
fastremaptifffile monaiplotly |
這些包主要用于輔助函數和繪圖,這在本文稍后部分將更加明顯。目前,它們可以在 Docker 容器之上安裝。
pip install -r requirements.txt |
接下來,啟動 notebook:
jupyter notebook |
現在,notebook 服務器正在運行,并且可以使用 web 瀏覽器在運行服務器的同一臺機器上或在單獨的機器上訪問 notebook。
在瀏覽器中,輸入服務器所在計算機的 IP 地址,然后輸入端口 8888:
<ip-address>/8888 |
現在 Notebook 已經準備就緒,可以運行了。有關更多信息,請參閱 GitHub 資源庫。
使用 VISTA-2D 進行細胞分割和特征提取
本 Notebook 的上半部分結合使用 Live Cell 數據與 VISTA-2D 分割圖像中的細胞,并使用 VISTA-2D 模型本身的編碼層提取特征。
首先,加載 VISTA-2D 模型檢查點,因為本筆記本不專注于訓練模型,而是將其用于特征提取的目的。
model_ckpt = "cell_vista_segmentation/results/model.pt" |
接下來,加載輔助函數,以避免主筆記本變得太冗長。
from segmentation import segment_cells, plot_segmentation, feature_extract |
下幾節將詳細介紹這些輔助函數的作用。它們均可在segmentation.py中找到。
segment_cells
此函數獲取細胞圖像,并從頭到尾通過 VISTA-2D 運行。這會生成另外兩張圖像,一張用于完整分割,另一張用于標記圖像中發現的細胞數(在 Notebook 中稱為pred_mask),從 1 到細胞數之間的每個細胞。這使得細胞能夠單獨索引,以便向下行提取特征。
img_path="example_livecell_image.tif"patch, segmentation, pred_mask = segment_cells(img_path, model_ckpt) |
plot_segmentation
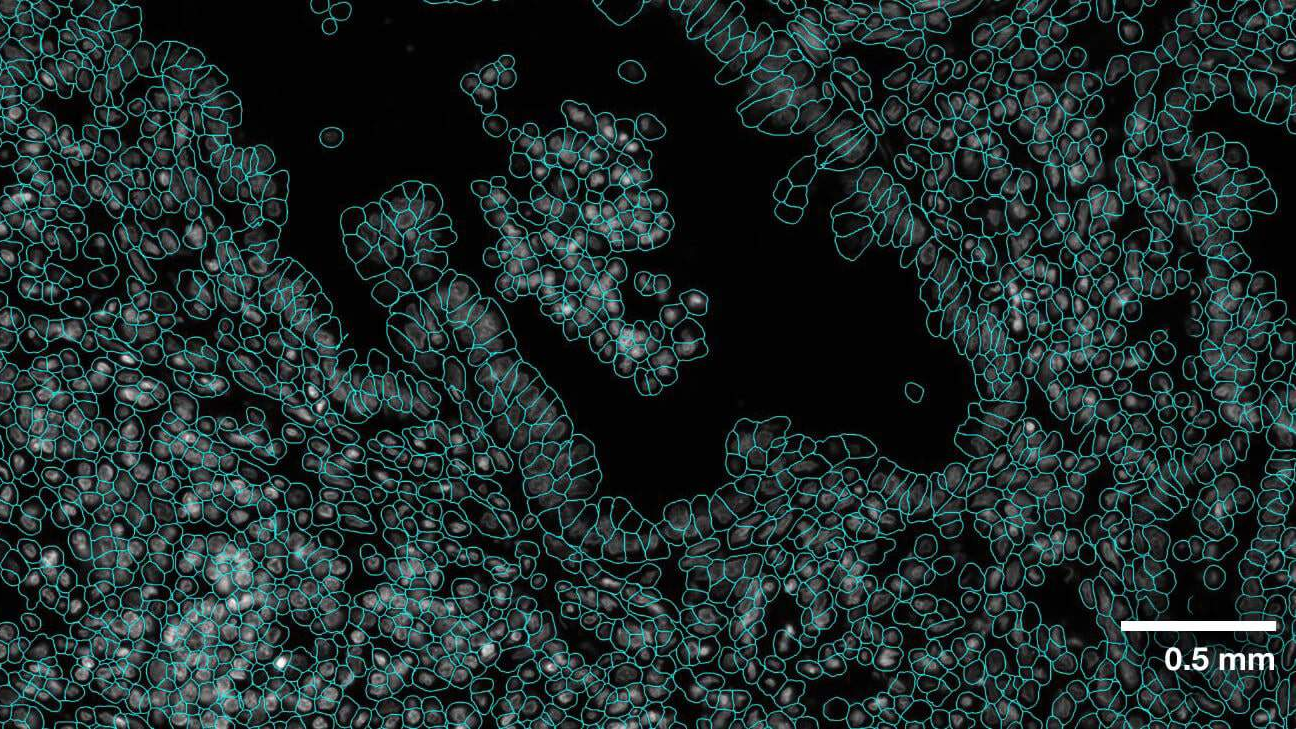
此函數接收segment_cells的輸出并顯示圖像,以便在分割和預測蒙版中直觀地驗證其準確性。圖 2 展示了使用 notebook 中提供的單元圖像輸出的示例。
plot_segmentation(patch, segmentation, pred_mask) |



Alt:三張圖像顯示 VISTA-2D 分割的結果:原始細胞圖像,從背景中分割出所有細胞,以及每個細胞的單個蒙版。
feature_extract
此函數獲取每個單獨的單元分割,并生成特征向量。每個單元都包含在一個裁剪的方形遮罩中,以適應該單元和周圍的任何背景。它使用 VISTA-2D 模型的前半部分作為編碼器來生成這些特征向量。
我們的想法是,生成的向量包含細胞分割所需的所有信息,因此還必須包含有關每個細胞形態的信息。這些信息作為向量,可以輕松插入聚類算法中。形態相似的細胞應具有類似的特征向量,并被分配給類似的集群。
cell_features = feature_extract(pred_mask, patch, model_ckpt) |
這將生成一個包含 num_cells 行和 1024 列的矩陣,該矩陣的列數是每個單元的編碼向量的長度。
現在您已經擁有每個單元的特征向量,是時候使用 RAPIDS 通過聚類算法運行它們了。
使用 RAPIDS 進行聚類
RAPIDS 是一個 GPU 加速的機器學習庫,具有適用于常用 Python 數據科學庫(例如 pandas 和 scikit-learn)的匹配 API。在此 Notebook 中,您僅使用 RAPIDS 的特征降維和聚類部分,但還有更多可用產品。
from cuml import TruncatedSVD, DBSCAN |
TruncatedSVD
您從 VISTA-2D 獲得的特征向量長度為 1024。然而,考慮到圖像中只有大約 80 個單元,因此使用如此多特征來制作集群是不合理的。
您可以使用降維算法來減少這些嵌入的長度,同時最大限度地減少丟失的信息。在此筆記本中,使用TruncatedSVD算法將維度從1024縮減到3。這還可以更輕松地繪制集群,因為您可以在 3D 空間中可視化集群。
dim_red_model = TruncatedSVD(n_components=3)X = dim_red_model.fit_transform(cell_features) |
這將生成新的特征向量矩陣 X,現在其大小為[num_cells, 3],而不是 cell_features 中大小為[num_cells, 1024]的原始向量。
DBSCAN
RAPIDS 中提供了許多集群算法。對于此 Notebook,我選擇了 DBSCAN。在這里,您將 eps(兩個點之間的最大距離)設置為 0.003,并將允許構成集群的最小樣本數設置為 2。
model = DBSCAN(eps=0.003, min_samples=2)labels = model.fit_predict(X) |
現在,運行 fit_predict 會為圖像中的每個單元生成集群標簽。如果將標簽列表轉換為標簽字典,則更容易看到哪些單元已被分配給哪些集群。
# Background is 0, so cell IDs start at 1labels_dict = {x:np.add(np.where(labels==x),1) for x in np.unique(labels)}# Label -1 means "data was too noisy" so we remove itlabels_dict.pop(-1)labels_dict |
最后,您可以使用 Plotly 配置 3D 交互式圖形,以顯示每個單元的聚類位置。
import plotlydata = []for l in labels_dict.keys(): cluster_indices = labels_dict[l][0]-1 # Configure the trace trace = go.Scatter3d( x=X[cluster_indices,0], y=X[cluster_indices,1], z=X[cluster_indices,2], name="Cluster "+str(l), mode='markers', marker={ 'size': 10, 'opacity': 0.8, } ) data.append(trace)# Configure the layoutlayout = go.Layout( margin={'l': 0, 'r': 0, 'b': 0, 't': 0})plot_figure = go.Figure(data=data, layout=layout)# Render the plotplotly.offline.iplot(plot_figure) |

結束語
在本文中,我向您展示了如何使用 VISTA-2D 模型分割圖像中的細胞,并從每個分割細胞中提取特征向量。我還展示了如何使用 RAPIDS 對這些向量運行聚類。
有關更多信息,請參閱以下資源:
- GitHub 上的 vista2d_rapids_clustering Jupyter notebook
- 借助 NVIDIA AI 基礎模型 VISTA-2D 推進細胞分割和形態分析
- RAPIDS 文檔中的 API 參考,獲取關于降維和聚類的信息。
?