語音 AI 應用,從呼叫中心到虛擬助理,嚴重依賴 自動語音識別?( ASR )和文本轉語音( TTS )。 ASR 可以處理音頻信號并將音頻轉錄為文本。語音合成或 TTS 可以實時從文本中生成高質量、自然的聲音。語音 AI 的挑戰是實現高精度并滿足實時交互的延遲要求。
NVIDIA Riva 是一個 GPU 加速 SDK ,用于構建語音 AI 應用程序,使用最先進的模型實現高精度,同時提供高吞吐量。 Riva 提供世界級的語音識別和文本到語音技能,以與人類進行多種語言的交互。 Riva 可以部署在內部 、云中、邊緣或嵌入式平臺上,您可以擴展 Riva 服務器,以低延遲處理數百或數千個實時流。這篇文章一步一步地指導您如何使用 Kubernetes 進行自動縮放和 Traefik 進行負載平衡來大規模部署 Riva 服務器。
Riva 可以針對不同應用程序(如聊天機器人、虛擬助手和轉錄服務)的數據集進行定制。預訓練的模型可以通過 NVIDIA TAO Toolkit 使用遷移學習進行微調,使您的開發比從頭開始預訓練模型更快。 NVIDIA GPU Cloud 中提供了語音識別和語音合成的預訓練模型。
非英語(西班牙語、德語和俄語) ASR 模型在多種開源數據集(如 Mozilla Common Voice )以及私有數據集上進行訓練。 Riva 開發了自動語音識別模型,以提供開箱即用的準確度,并作為適應行業、行話、方言甚至嘈雜環境的良好起點。
為了讓用戶享受逼真的對話,語音應用程序必須提供類似人類的表情。使用 FastPitch 模型, Riva 幫助開發人員定制文本到語音的管道,并創建富有表現力的類人聲音。例如,在推斷期間,開發人員可以使用 SSML tags 改變語音音調和速度。最新的最先進的模型,如 Riva 中的 Fastpitch ,可以幫助文本到語音管道的運行速度比市場上其他競爭選項快幾倍。
硬件和軟件先決條件
要擴展 Riva 部署以以低延遲處理數百到數千個實時流,可以使用 Kubernetes 。為 Riva 部署準備 Kubernetes 集群需要滿足幾個先決條件。
首先,確保 Kubernetes 節點有 GPU 可用。在 GPU 上運行 Riva 的深度神經網絡對于確保實時流的低延遲和高帶寬要求至關重要。 NVIDIA Volta 或更高版本 GPU 支持 Riva ,建議每個 GPU 至少具有 16 GB 的 VRAM 。 Riva 也可以部署在具有適當 GPU 資源的公共云計算實例上,例如 AWS EC2 實例。
接下來,允許從 Kubernetes 集群中運行的工作負載訪問 GPU 。最簡單的方法是使用 NVIDIA GPU Operator ,它將自動設置和管理工作節點上的 NVIDIA 軟件組件。
如果您愿意,也可以自己安裝和管理 GPU 軟件組件。在這種情況下,您需要在每個節點上安裝 NVIDIA GPU Driver 和 NVIDIA Container Toolkit ,以及 Kubernetes 的 NVIDIA 設備插件。這使 Kubernetes 能夠發現哪些節點具有 GPU ,并使其可用于在這些節點上運行的容器。您還可以選擇安裝 GPU Feature Discovery plugin ,它將為每個節點生成描述可用 GPU 功能的標簽。
NVIDIA GPU Operator 的公開版本是免費的,僅包括社區支持。 NVIDIA AI Enterprise 推薦用于企業客戶。對于活動訂閱,您可以使用經過充分驗證且企業支持的 GPU Operator 版本。有關更多信息,請參閱 NVIDIA AI Enterprise 文檔。
為了支持自動縮放, Prometheus 必須安裝在 Kubernetes 集群中,以收集度量并將其報告給控制平面。還要確保在 Kubernetes 集群中啟用 Kubernetes API Aggregation Layer ,這允許自動縮放器訪問 Prometheus 等外部 API 。
要在下一節中使用 Helm 圖表,請使用以下腳本安裝 Helm :
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
$ chmod 700 get_helm.sh
$ ./get_helm.sh
然后使用 kube 普羅米修斯堆棧 Helm chart 安裝普羅米修斯監視堆棧:
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
$ helm install <name> --set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
prometheus-community/kube-prometheus-stack
Autoscale Riva deployment
使用自動縮放和負載平衡為語音 AI 推理部署 Riva 的四個主要步驟是:
- 為 Riva 服務器創建 Kubernetes deployment
- 創建 Kubernetes 服務以將 Riva 服務器公開為網絡服務
- 自動縮放 Riva 部署:
- 使用 kube Prometheus 和 ServiceMonitor 向 Prometheus 公開 NVIDIA Triton 指標
- 為自定義度量部署 Prometheus 適配器
- 創建水平吊艙自動縮放器( HPA )
- 使用 Traefik 在所有 Pod 之間分發客戶端請求
Riva 部署的舵圖
您可以使用 Helm 圖表進行此部署,因為它很容易在不同環境中進行修改和部署。圖表被組織為riva目錄中的文件集合,如下所示。在riva目錄中, Helm 需要一個與以下文件匹配的結構:
chart.yaml:這里是您打包的圖表的所有信息。例如,您的版本號和依賴項。
values.yaml:您可以在這里定義要注入到模板目錄中的所有值。
charts:這是存儲 Riva 圖表所依賴的其他圖表的目錄。 Riva 分別依賴于 Traefik 和 Prometheus 適配器圖表進行入口和自動縮放。
templates:這是放置與圖表一起部署的實際清單的目錄。
對于 Riva 服務器,您需要deployment.yaml , service.yaml , [EZX205] , 和ingressroute.yaml,它們都在templates目錄中。這些都將從values.yaml中獲得某些配置值。按照慣例, Helm 圖表還包括部分文件(通常稱為_helpers.tpl . )中的助手模板
您可以通過修改文件templates/*.yaml中的字段values.yaml來更改部署的配置。
riva/
chart.yaml
values.yaml
charts/
templates/
deployment.yaml
service.yaml
hpa.yaml
ingressroute.yaml
_helpers.tpl
下面的chart.yaml文件需要指定圖表的所有信息,例如 Riva 版本以及 Traefik Helm chart 和 Prometheus Community Kubernetes Helm Charts 的存儲庫。
apiVersion: v1
appVersion: 1.9.0-beta
description: Riva Speech Services
name: riva
version: 1.9.0-beta
dependencies:
- name: traefik
version: "~10.6.2"
repository: "https://helm.traefik.io/traefik"
tags:
- loadBalancing
- name: prometheus-adapter
version: "~3.0.0"
repository: "https://prometheus-community.github.io/helm-charts"
tags:
- autoscaling
為 Riva 服務器創建 Kubernetes 部署
Kubernetes deployment 為 Pods 和 ReplicaSets 提供聲明性更新。下面的deployment.yaml 為 GPU 服務器創建了一組復制的 Kubernetes Pod 。您可以指定開始部署時要使用多少 Kubernetes Pod ,如.spec.replicas字段所示。.spec.containers字段告訴每個 Kubernetes Pod 在 Riva 設備上運行一個 Riva 服務器 docker 容器。
.spec.selector字段定義了部署如何找到要管理的 Pod 。端口號50001是為 Riva 服務器指定的,以接收 GRPC 從客戶端發出的推斷請求,而端口8002是為 NVIDIA Triton 指標指定的。deployment.yaml 中的字段可以根據您的部署在values.yaml 中進行修改。
kind: Deployment
metadata:
[…]
spec:
replicas: {{ .Values.autoscaling.minReplicas }}
selector:
[…]
template:
metadata:
labels:
app: {{ template "riva-server.name" . }}
spec:
volumes:
[…]
containers:
- name: riva-speech-api
image: {{ $server_image }}
imagePullPolicy: {{ .Values.riva.pullPolicy }}
resources:
limits:
nvidia.com/gpu: {{ .Values.riva.numGpus }}
command: ["/opt/riva/bin/start-riva"]
args:
{{- range $service, $enabled := .Values.riva.speechServices }}
- "--{{$service}}_service={{$enabled}}"
{{- end }}
env:
- name: TRTIS_MODEL_STORE
value: "/data/models“
ports:
- containerPort: 50051
name: speech-grpc
- containerPort: 8000
name: http-triton
- containerPort: 8001
name: grpc-triton
- containerPort: 8002
name: metrics-triton
volumeMounts:
- mountPath: /data/
name: workdir
……
為 Riva 服務器創建 Kubernetes 服務
Kubernetes service 是將在 Pods 集合上運行的應用程序公開為網絡服務的抽象方法。下面提供的service.yaml將 Riva 服務器公開為網絡服務,因此 Riva 服務器已準備好接收來自客戶端的推斷請求。由于 NVIDIA Triton Inference Server 是 Riva 服務器的固有組件,因此 NVIDIA Triton metrics 可以從端口號8002收集,方法與您使用 NVIDIA Triton 推理服務器相同。service.yaml中的字段可以根據您的部署在values.yaml中進行修改。
創建服務時,您可以通過設置clusterIP: None . (如果您想指定給定的 IP 地址,請參閱 Kubernetes service documentation )自動創建外部負載平衡器。這使 Kubernetes 能夠自動分配一個外部可訪問的 IP 地址以將流量發送到 Kubernete 集群節點上的正確端口。
apiVersion: v1
kind: Service
metadata:
name: {{ template "riva-server.fullname" . }}
labels:
app: {{ template "riva-server.name" . }}
spec:
selector:
app: {{ template "riva-server.name" . }}
clusterIP: None
ports:
- port: 50051
targetPort: speech-grpc
name: riva-speech
- port: 8000
targetPort: http
name: triton-http
- port: 8001
targetPort: grpc
name: triton-grpc
- port: 8002
targetPort: metrics
name: metrics
自動縮放 Riva 部署
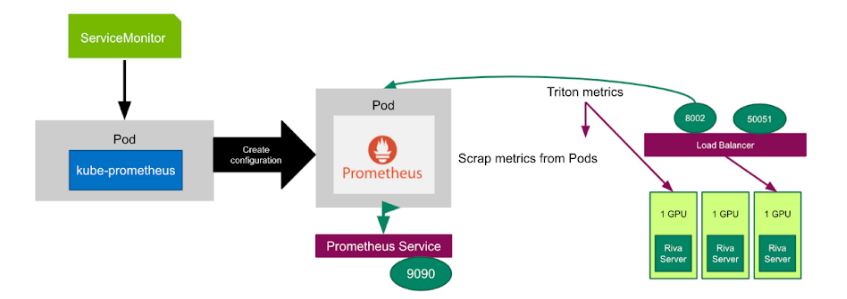
為了自動更改 Kubernetes Pods 上 Riva 服務器的數量,您需要一個 ServiceMonitor 來監視 Prometheus 發現 Riva Service 的目標。您還需要 kube Prometheus 來部署 Prometheu 斯并將 Prometheus 鏈接到度量端點。在下面的yaml文件中, ServiceMonitor 設置為每 15 秒監視一次 Riva 服務。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: {{ template "riva-server-metrics-monitor.fullname" . }}
namespace: {{ .Release.Namespace }}
labels:
app: {{ template "riva-server-metrics-monitor.name" . }}
chart: {{ template "riva-server.chart" . }}
release: {{ .Release.Name }}
spec:
selector:
matchLabels:
app: {{ template "riva-server.name" . }}
endpoints:
- port: metrics
interval: 15s您可以使用 Prometheus 從端口號8002處的所有 Kubernetes Pod 中抓取 NVIDIA Triton 度量,然后使用 PromQL ( PrometheusQuery 語言)基于 NVIDIA Triton 度量定義一個新的自定義度量,告訴 Prometheu 適配器如何收集此自定義度量,如下所示:
prometheus-adapter:
prometheus:
url: http://example-metrics-kube-prome-prometheus.default.svc.cluster.local
port: 9090
rules:
custom:
- seriesQuery: 'nv_inference_queue_duration_us{namespace="default",pod!=""}'
resources:
overrides:
namespace:
resource: "namespace"
pod:
resource: "pod"
name:
matches: "nv_inference_queue_duration_us"
as: "avg_time_queue_ms"
metricsQuery: 'avg(delta(nv_inference_queue_duration_us{<<.LabelMatchers>>}[30s])/(1+delta(nv_inference_request_success{<<.LabelMatchers>>}[30s]))/1000) by (<<.GroupBy>>)’
您可以使用兩個 NVIDIA Triton 度量來定義自定義度量avg_time_queue_ms,這意味著在過去 30 秒內每個推斷請求的平均隊列時間, HPA 根據它決定是否更改副本編號。
nv_inference_request_success[30]是過去 30 秒內成功的推理請求數。nv_inference_queue_duration_us是以微秒為單位的累積推斷排隊持續時間。
現在您有了一個正在運行的 Prometheus 副本來監控您的應用程序,您需要部署 Prometheu 適配器,它知道如何與 Kubernetes 和 Prometheus 通信,充當兩者之間的轉換器。如果在chart.yaml中包含prometheus-adapter部分, Prometheus 適配器將自動部署。
普羅米修斯適配器幫助您利用普羅米修斯收集的指標,并使用它們做出縮放決策。這些度量由 API 服務公開, HPA 可以輕松使用。 HPA 可以使用自定義度量,根據推斷請求的數量自動縮放(上下) Kubernetes Pod 的副本數量。如果自定義度量的值高于所需的值, HPA 可以增加副本的數量以減少隊列時間。
在hpa.yaml和value.yaml中,您需要指定用于部署的副本的最大和最小數量。在value.yaml中,您可以將pods用于metrics.type,以獲取自動縮放目標控制的所有 Pod 中給定度量的平均值。可以根據您對響應時間的要求將目標或期望的度量值設置為任意數字。
HPA 使用的相關度量標準的選擇取決于您組織中的服務級別要求,例如,您可能還希望犧牲響應時間以支持整體設備利用率,以最小化應用程序部署的成本。在本示例中,選擇對推斷請求的響應時間 作為 HPA 的主要度量。
hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: riva-hpa
namespace: {{ .Release.Namespace }}
labels:
app: {{ template "riva-server.name" . }}
chart: {{ template "riva-server.chart" . }}
……
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ template "riva-server.fullname" . }}
minReplicas: {{ .Values.autoscaling.minReplicas }}
maxReplicas: {{ .Values.autoscaling.maxReplicas }}
metrics: {{ toYaml .Values.autoscaling.metrics | nindent 2}}
values.yaml
autoscaling:
minReplicas: 1
maxReplicas: 3
metrics:
- type: Pods
pods:
metric:
name: avg_time_queue_ms
target:
type: AverageValue
averageValue: 500m
使用 Traefik 實現 Riva 部署的負載平衡
您還需要一個負載平衡器,以幫助根據負載壓力在所有 Riva 服務器之間均勻分布推斷請求。一般來說,有兩種類型的負載平衡器:第 4 層和第 7 層。Layer4負載平衡器位于網絡的Transport層,不知道實際服務(例如 gRPC 中的 HTTP )。Layer7負載平衡器位于Application層,通常將特定service的請求代理到端點。
本示例使用 Traefik 入口控制器和負載平衡器(即第 7 層)來接收推斷請求,然后將其分發到所有 Riva 服務器。在 Kubernetes 集群中注冊IngressRoute類型,并在 Traefik 中為 GRPC 使用h2c協議,如下面的ingressroute.yaml所示。
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: {{ template "riva-server-ingressroute.name" . }}
namespace: {{ .Release.Namespace }}
labels:
app: {{ template "riva-server.name" . }}
chart: {{ template "riva-server.chart" . }}
release: {{ .Release.Name }}
heritage: {{ .Release.Service }}
spec:
entryPoints:
- riva-grpc
routes:
- match: PathPrefix(`/`)
kind: Rule
services:
- name: {{ template "riva-server.fullname" . }}
port: 50051
scheme: h2c嘗試 Riva 部署
最后,您可以將所有內容放在一起,使 Riva 客戶端能夠向 Riva 服務器發送推理請求。對于 Riva 服務器,可以使用 Helm 圖表安裝所有內容:
$ helm install <name> .
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
riva-traefik LoadBalancer X.X.X.X <pending> 50051:32067/TCP,80:30082/TCP 69s
您可以通過運行 NGC Riva Client image 中提供的 Riva 流式 ASR 客戶端來測試 Riva client 。要求 Riva 客戶端向 Riva 服務器發送流式推理請求,使 HPA 能夠自動縮放(增加或減少) Kubernetes Pod 的數量。
$ riva_streaming_asr_client --riva_uri=<IP address of load balancer>:50051 --audio_file /work/wav/en-US_sample.wav --num_parallel_requests=32 --num_iterations=1024您還可以從 Prometheus 查詢 NVIDIA Triton 指標,并通過導航到其指標端點 localhost:9090/metrics 以時間序列顯示結果。
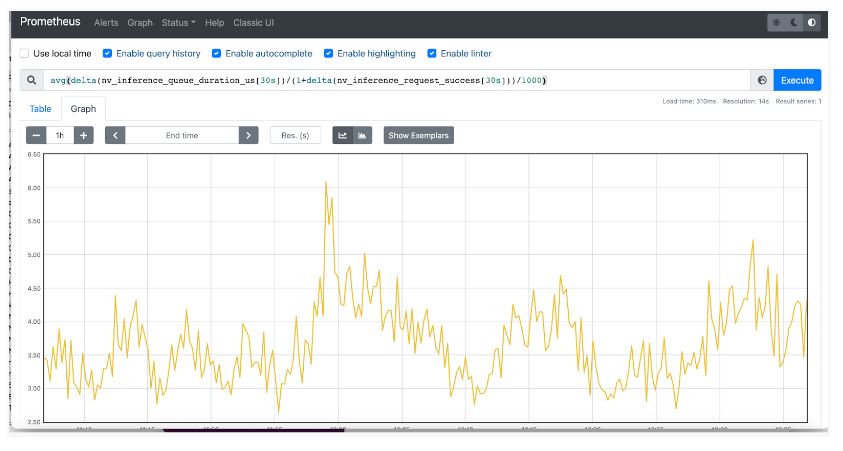
結論
本文提供了在 Kubernetes 環境中自動縮放 NVIDIA Riva 部署的分步說明和代碼。它還向您展示了如何使用 Traefik 平衡工作負載。查看所有步驟和結果.
要了解更多信息,請觀看 Autoscaling Riva Deployment with Kubernetes for Conversational AI in Production GTC 2022 課程。有關使用 Kubernetes 和 NGINX Plus (作為另一個負載平衡器選項)大規模部署 AI 推理工作負載的更多信息,請參閱 Deploying NVIDIA Triton at Scale with MIG and Kubernetes 。
?