大多數現代數字芯片以存儲塊或模擬塊的形式集成大量宏,如時鐘生成器。這些宏通常比標準單元大得多,標準單元是數字設計的基本組成部分
宏布局對芯片的外觀有著巨大的影響,直接影響到許多設計指標,如面積和功耗。因此,改進這些宏指令的位置對于優化每個芯片的性能和效率至關重要。
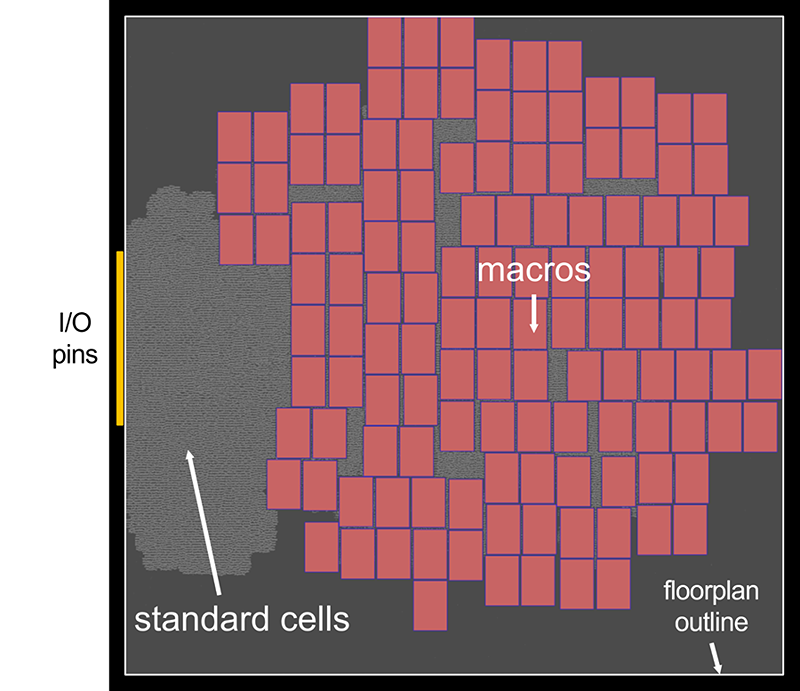
傳統上,設計者會根據歷史悠久的實踐手動放置宏。例如,它們可能出現在樓層平面輪廓的外圍。然而,手動找到最佳宏位置是非常耗時的。考慮到宏布局、標準單元布局以及由此產生的功率、性能和面積( PPA )之間的現代復雜關系,可以改進該過程
最近在改善宏觀布局方面做出的兩項努力是基于強化學習的宏觀布局和宏和標準單元格的并行放置.
強化學習方法
RL 方法將宏放置問題公式化為一個博弈。游戲代理的動作對應于宏的可能位置。通過采樣許多放置示例,代理學習優化其策略(通常由神經網絡表示),以提高宏放置質量。這種質量是基于替代目標來估計的,例如導線長度、擁塞和密度
這些替代目標不是根據實際放置來評估的,而是根據從快速但直接的放置算法獲得的標準細胞簇的近似放置來評估,以保持運行時可管理。 RL 方法需要大量的計算資源。例如, 20 GPU 和 200 CPU 用于訓練和微調代理的神經網絡模型,運行 10 +小時。
并行放置方法
或者,同時放置單元格和宏的方法采用混合大小的放置方法,同時放置宏和標準單元格。最先進的混合尺寸放置工具利用數值算法來有效地優化選定的目標,例如導線長度和密度。這些也可能包括擁堵和timing considerations在目標函數中進行數值優化。這種方法已經在商業 EDA 工具中實現。
盡管并行單元和宏放置方法取得了有希望的結果,但我們相信它可以進一步改進。數值算法有許多算法參數,構成了很大的設計空間。放置的最終質量取決于所選擇的參數配置。通過同時放置單元格和宏來擴展這個設計空間可以進一步增加次優性差距
此外,傳統的布局算法將多個設計目標組合為一個目標進行優化。多目標優化框架可以擴展搜索空間,縮小最優性差距。
這項工作旨在證明,使用基于 ML 的多目標優化和 GPU 加速的數值布局工具,可以有效地搜索巨大的設計空間,以找到更好的宏觀布局解決方案
用于宏放置的 DREAMPlace
這篇文章展示了如何使用最先進的開源分析砂礦DREAMPlace作為并發宏和單元格放置的放置引擎。 DREAMPlace 將放置問題公式化為放置密度約束下的導線長度優化問題,并對其進行數值求解
導線長度目標和密度約束都可以公式化為可微函數。導線長度目標用光滑的對數和 exp 函數近似。密度約束被視為一個靜電系統,通過快速傅立葉變換的泊松方程求解
DREAMPlace 使用 GPU (由 PyTorch 框架啟用的加速算法)以數字方式計算導線長度和密度梯度。僅在全球布局上,它就實現了超過 30 倍的加速。Further work還加速了 GPU 的精確放置,在工業基準上實現了 CPU 實現的 16 倍以上的加速。要了解更多信息,請參閱Place :在多線程 CPU 和 GPU 上加速基于批處理的并行詳細放置.
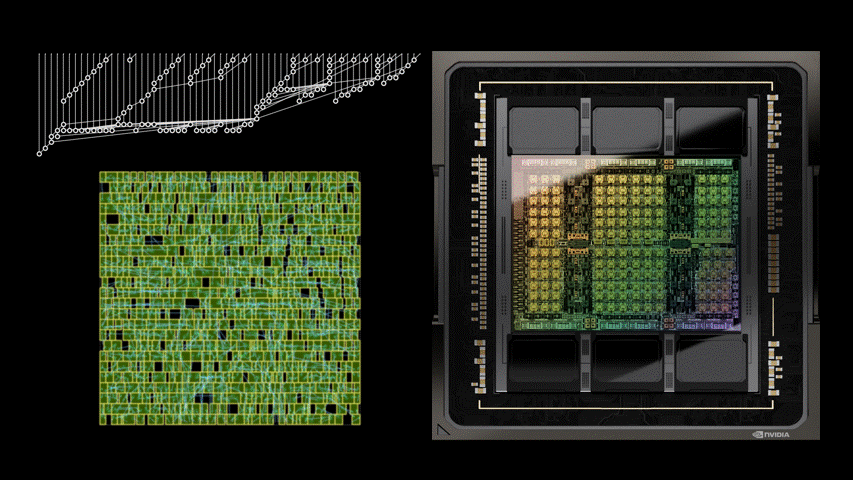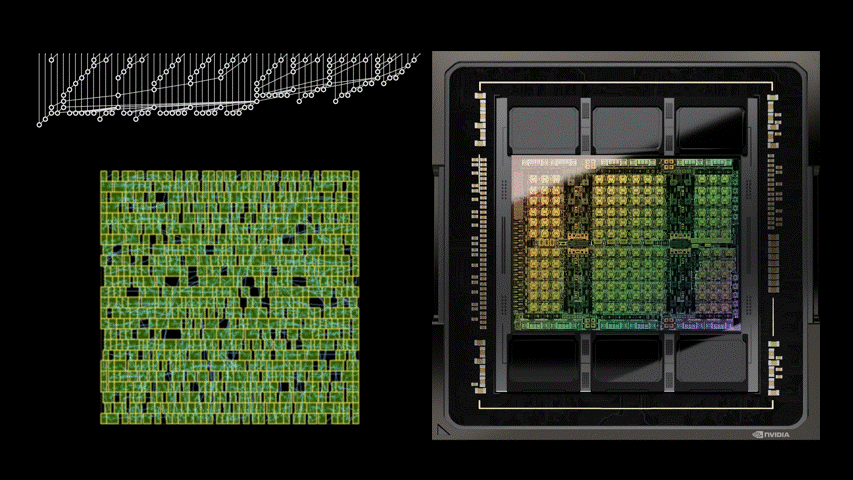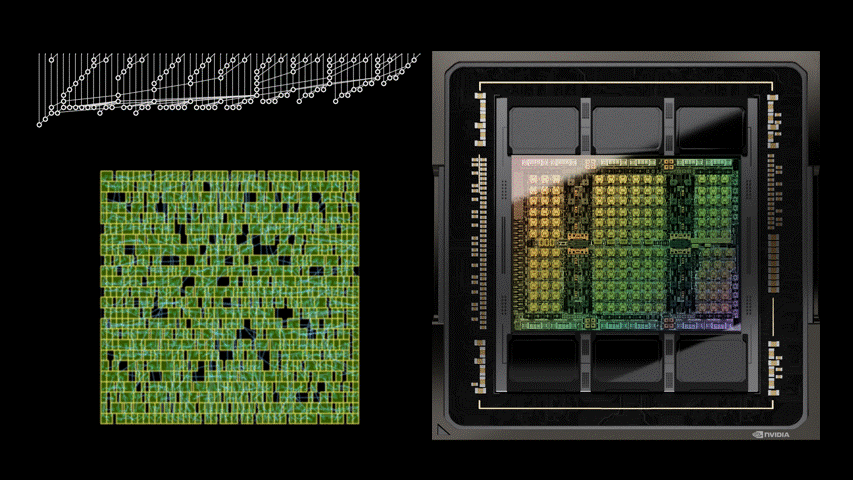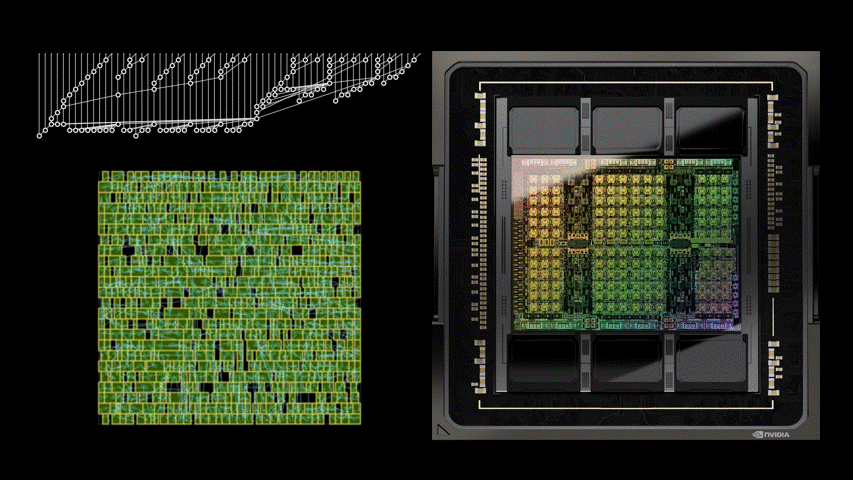
DREAMPlace 支持混合大小的放置,可以同時放置宏和標準單元格。例如,圖 2 顯示了一個開源設計 MemPool 的放置過程。

放置參數
我們在 DREAMPlace 中選擇了一組 16 個參數來定義設計空間。這些參數是基于觀察到它們顯著影響放置質量而確定的。我們包括了與優化相關的參數(如基于梯度的數值優化器及其學習率)和物理參數(如密度評估的倉數和密度目標)
除了原始的 DREAMPlace 參數外,我們還添加了下面列出的參數,以進一步擴展宏放置的設計空間。
初始位置:DREAMPlace 最初將單元和宏的所有初始位置設置在樓層平面的中心。如圖 3 所示,調整這些初始位置可以顯著影響最終的放置質量。
宏觀光暈:為了簡化宏合法化,添加了兩個參數來強制宏之間的最小垂直/水平間距。間距約束轉換為在宏周圍添加的填充。

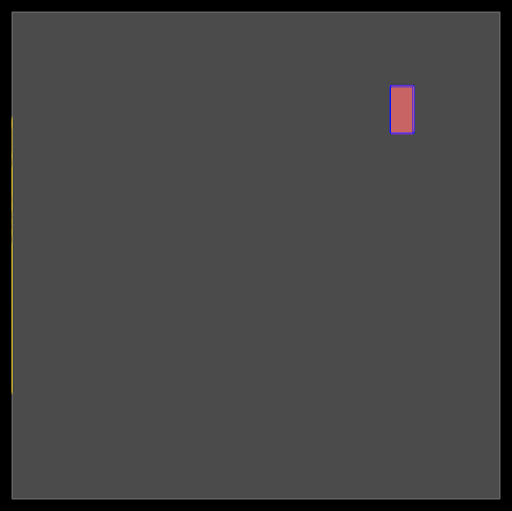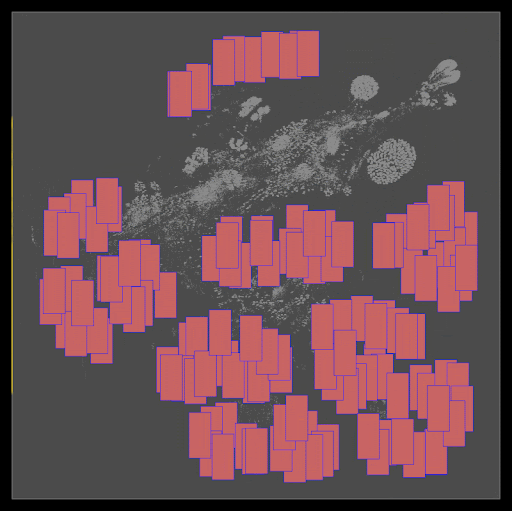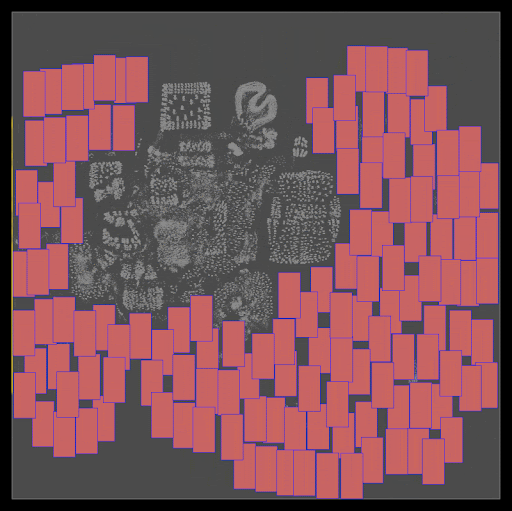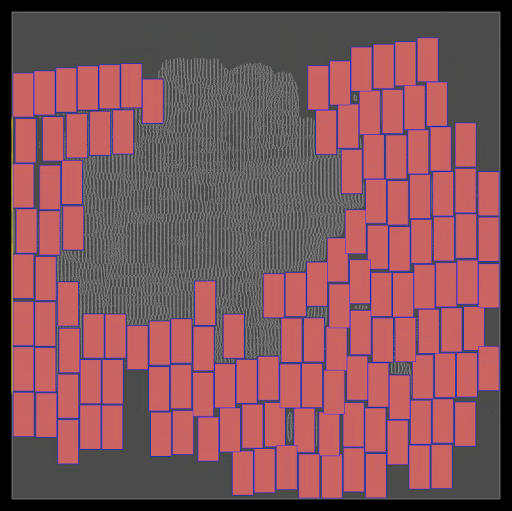
圖 3 。從中心到右上角修改單元格的初始位置會導致兩種截然不同的最終放置景觀
多目標優化
我們建議在參數空間中使用多目標優化,而不是單目標優化。目標是導線長度、密度和擁塞。這三個目標都是從夢想之地的詳細布局中進行評估的。導線長度近似為直線 Steiner 最小樹( RSMT )長度。密度是 DREAMPlace 中使用的目標細胞密度。最后,使用RUDY algorithm.
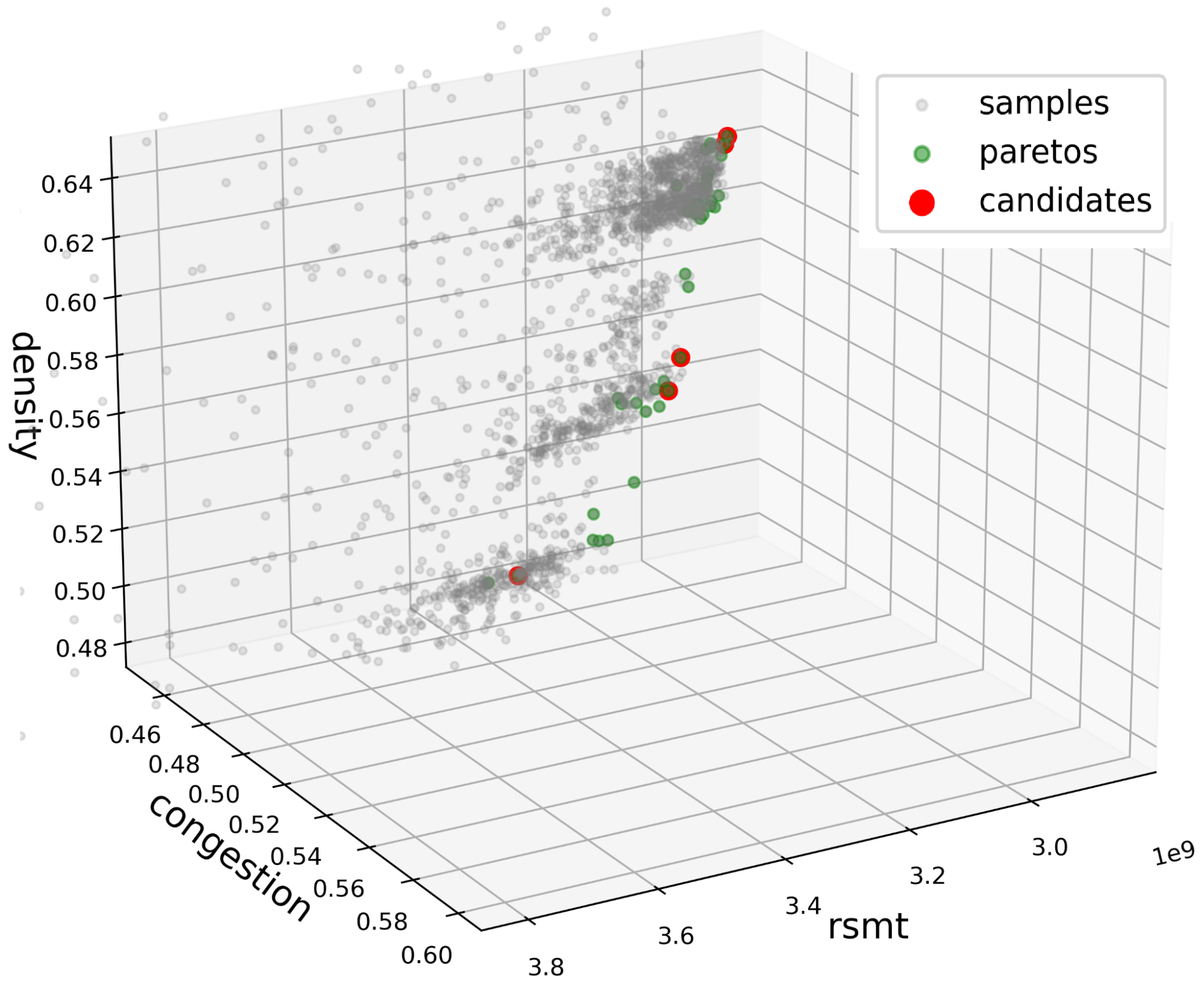
多目標優化試圖找到帕累托前沿,如圖 4 所示。這是一組非支配目標空間點,其中沒有一個目標可以在不降低至少一個其他目標的情況下得到改進。
使用多目標樹結構 Parzen 估計器它基于貝葉斯優化算法,這是一種學習內部模型作為指導的智能搜索技術
該模型從先前采樣的數據中近似參數配置和目標之間的關系,這有助于為未來的樣本找到更好的搜索配置。 MOTPE 的特殊性是通過基于目標值劃分參數空間,對給定目標的參數的條件分布進行建模
優化過程如圖 5 所示。在左邊( a ),區域由在 2D 目標空間中具有三個采樣點的假想 Pareto 前沿( Y *)定義。綠色區域比帕累托前沿更差,藍色區域包括與當前帕累托前線不相上下或更好的點。在右邊( b ),兩個概率密度函數l和g分別針對在藍色區域和綠色區域內采樣的數據學習。將繪制參數的新樣本,以便它們可能處于分布狀態l而不是g.

與其他單目標優化算法相比, MOTPE 很好地支持離散搜索空間。此外,每個參數都有其條件密度,這往往會發現良好的設置較少依賴于參數交互
搜索后可能發現了許多 Pareto 最優點,這是一個積極的事實,表明了布局解決方案的多樣性。然而,由于反饋延遲要求和共享資源限制(服務器、工具許可證等),在商業電子設計自動化( EDA )工具中評估所有這些點是不切實際的
相反,對 3D 點進行聚類,以將 Pareto 點減少到更小的候選集合。假設是,在客觀空間中彼此靠近的點對應于看起來相似的位置。圖 4 顯示了這種方法,其中紅點對應于 EDA 工具中使用的位置。
兩級 PPA 評估
我們提出了一種兩步 PPA 評估方法,以減少布局質量估計量和流末 PPA 結果之間的相關性差距(圖 6 )。
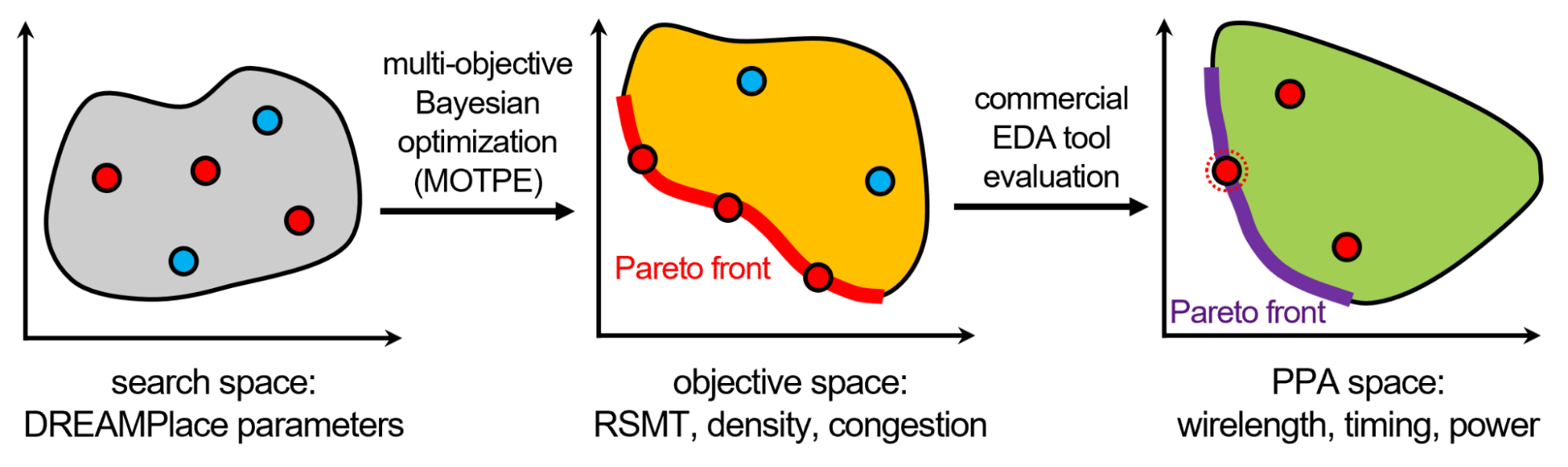
首先, AutoDMP 多目標參數優化找到一組布局,其估計的導線長度、擁塞和密度位于 Pareto 前沿。該步驟本質上將 AutoDMP 參數的設計空間映射到目標代理空間。
然后,將目標空間 Pareto 前沿上的宏位置映射到 EDA 工具的真實 PPA 空間。這兩個 Pareto 前沿可能不匹配,因為 EDA 工具對布局進行了大量優化,其中許多是啟發式驅動的,因此很難預測
因此,在目標代理空間的 Pareto 前沿的所有宏位置上運行 EDA 工具,并評估真實的 PPA 度量,例如從 EDA 工具流執行中獲得的布線長度、時序和功率。為了減少對計算資源的不必要使用,請停止流,盡早評估 PPA (例如,在位置選擇階段),并放棄沒有希望的宏位置。
后果
AutoDMP 是根據由TILOS AI-Institute該基準包括一組 CPU 和 AI 加速器設計,這些設計具有大量宏。最初建議公平評估谷歌電路訓練方法.
為了進行評估, AutoDMP 與一個商業 EDA 工具集成在一起,如圖 7 所示。首先,在NVIDIA DGX系統該系統有四個 A100 GPU ,每個都配備了 80GB 的 HBM 存儲器。產生了 16 個并行進程來對參數進行采樣,并在優化過程中運行 DREAMPlace 。然后,從 Pareto 前沿選擇的宏布局被饋送到 TILOS 提供的 EDA 流,該 EDA 流在 CPU 服務器上運行
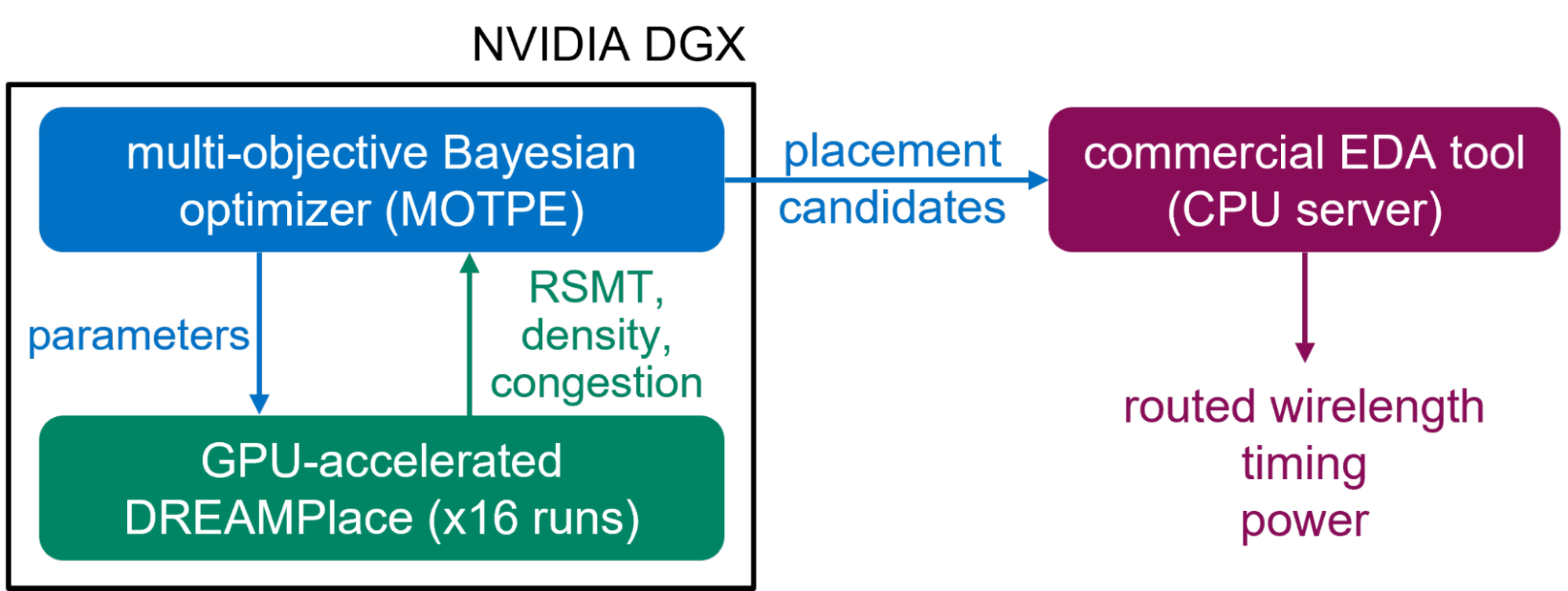
TILOS 基準測試包括幾種設計,其中一些設計只在時間和密度目標上有所不同。多目標優化為每個設計采樣 1000 個設計點。在單個 DGX 系統上運行搜索只需要幾個小時
從 Pareto 前沿中選擇五個宏布局以由 EDA 流處理。 PPA 指標在流程結束時收集(路由后)。圖 8 報告了每種設計的五個宏位置中的最佳 PPA 。所有指標都使用默認的商業宏布局流結果進行標準化
在大多數設計中, AutoDMP 導線長度、功率、最差負松弛( WNS )和總負松弛( TNS )的 PPA 指標結果等于或優于商業流量
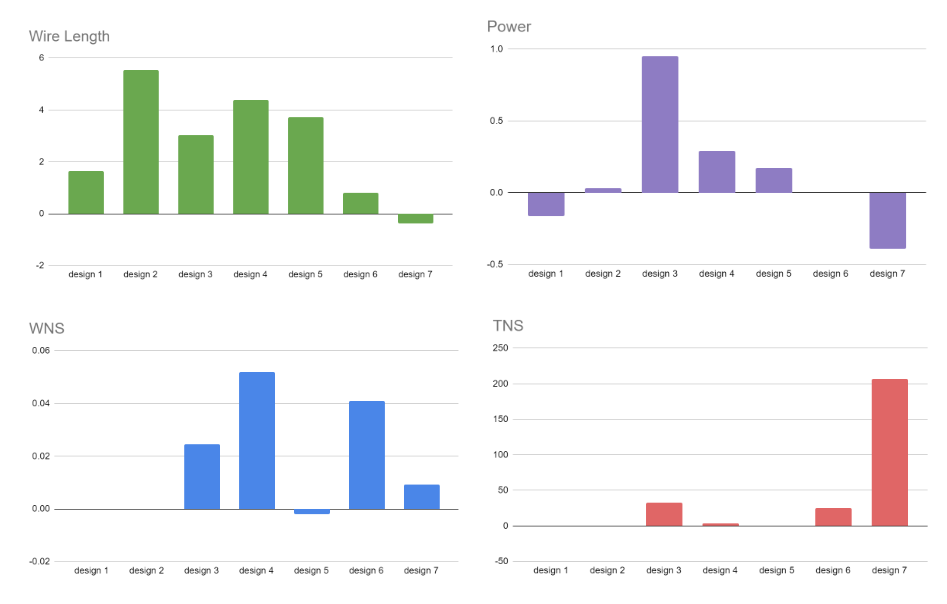
我們還觀察到, AutoDMP 在一個技術節點(如 NanGate45 )的設計上實現的最佳參數可以應用于另一個技術結點,如 ASAP7 。這表明, AutoDMP 發現的最佳參數可能會在微小的設計變化中轉移
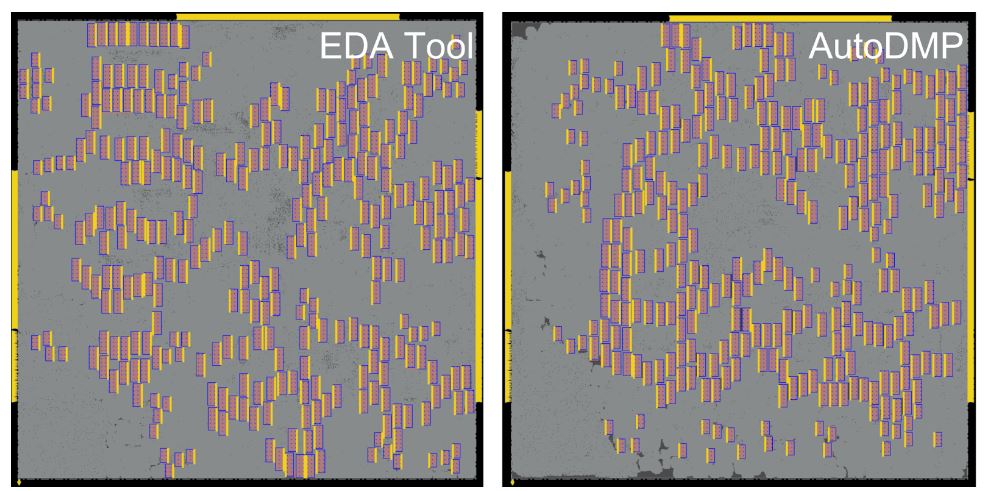
圖 9 顯示了基準測試中最大的設計 MemPool 的位置,它集成了 256 個 RISC-V 內核,占 270 萬個標準單元和 320 個內存宏。經過 3.5 小時的搜索, AutoDMP 生成一組候選宏位置
結論
這項工作證明了將 GPU 加速砂礦與 AI / ML 多目標參數優化相結合的有效性。此外,鑒于可擴展性在現代芯片設計流程中的重要性,我們希望這種方法能夠開啟新的前瞻性設計空間探索技術。
有關更多信息和實驗結果,請參閱AutoDMP :基于 DREAMPlace 的自動宏放置。本文將在ISPD 2023 會議,以及其他 NVIDIA 研究工作,包括:
?