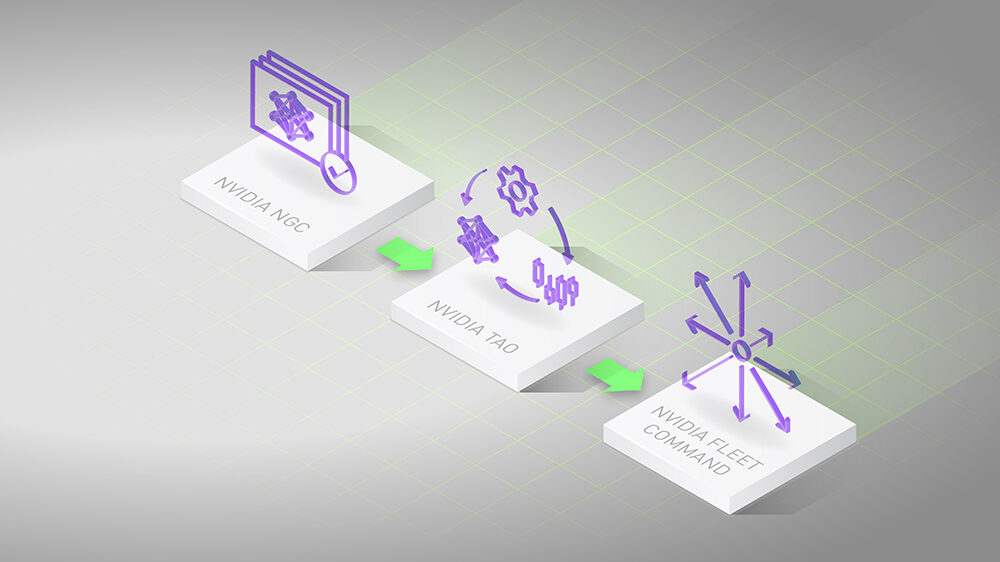
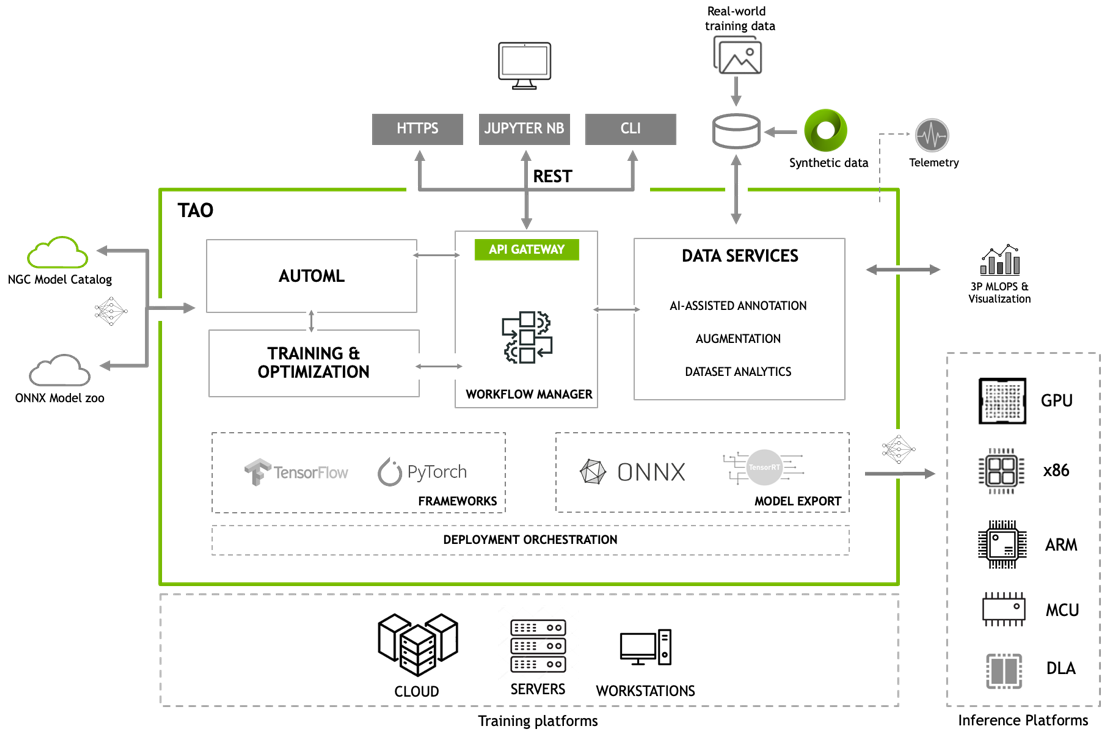
NVIDIA TAO Toolkit 提供了一個低代碼人工智能框架,用于加速視覺人工智能模型開發,適用于從新手到專家數據科學家的所有技能水平。借助 NVIDIA TAO (訓練、適應、優化)工具包,開發人員可以利用遷移學習的力量和效率,通過適應和優化,在創紀錄的時間內實現最先進的精度和生產級吞吐量。
在 NVIDIA GTC 2023 上, NVIDIA 發布了 NVIDIA TAO Toolkit5.0 ,帶來了突破性的功能來增強任何人工智能模型的開發。新功能包括開源架構、基于 transformer 的預訓練模型、人工智能輔助的數據注釋,以及在任何平臺上部署模型的能力。
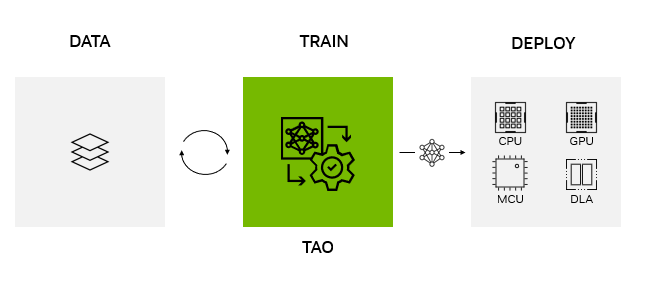
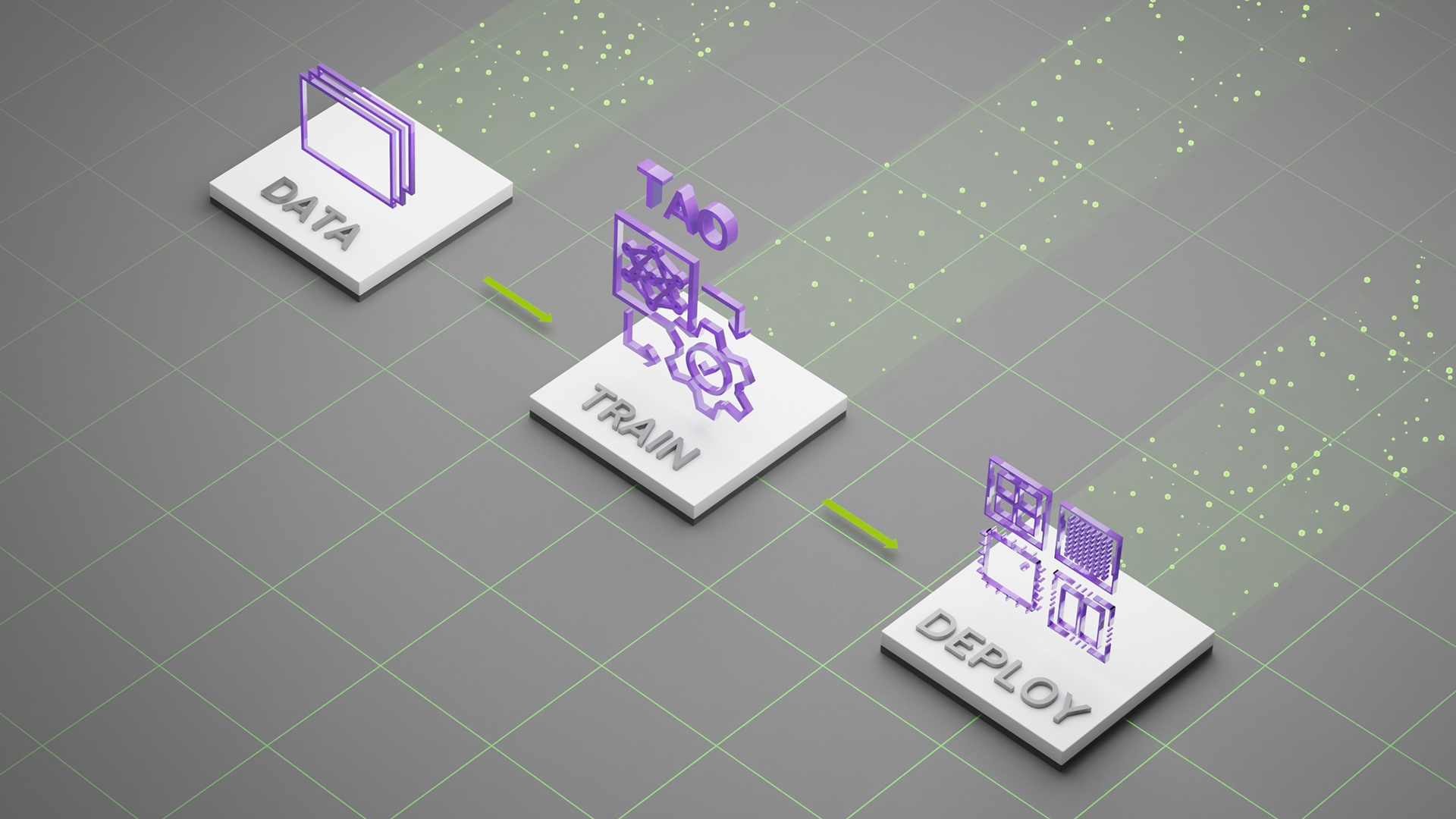
在任何平臺、任何位置部署 NVIDIA TAO 型號
NVIDIA TAO Toolkit 5.0 支持 ONNX 中的模型導出。這使得在邊緣或云中的任何計算平臺 GPU 、 CPU 、 MCU 、 DLA 、 FPGA 上部署使用 NVIDIA TAO Toolkit 訓練的模型成為可能。 NVIDIA TAO 工具包簡化了模型訓練過程,優化了模型的推理吞吐量,為數千億臺設備的人工智能提供了動力。
嵌入式微控制器的全球領導者 STMicroelectronics 將 NVIDIA TAO 工具包集成到其 STM32Cube AI 開發人員工作流程中。這使 STMicroelectronics 的數百萬開發人員掌握了最新的人工智能功能。它首次提供了將復雜的人工智能集成到 STM32Cube 提供的廣泛物聯網和邊緣用例中的能力。
現在有了 NVIDIA TAO 工具包,即使是最新手的人工智能開發人員也可以在微控制器的計算和內存預算內優化和量化人工智能模型,使其在 STM32 MCU 上運行。開發人員還可以帶來自己的模型,并使用 TAO Toolkit 進行微調。 STMicroelectronics 在下面的演示中捕捉到了有關這項工作的更多信息。
視頻 1 。了解如何在 STM 微控制器上部署使用 TAO Toolkit 優化的模型
雖然 TAO Toolkit 模型可以在任何平臺上運行,但這些模型在使用 TensorRT 進行推理的 NVIDIA GPU 上實現了最高吞吐量。在 CPU 上,這些模型使用 ONNX-RT 進行推理。一旦軟件可用,將提供復制這些數字的腳本和配方。
| ? | NVIDIA Jetson Orin Nano 8 GB | NVIDIA Jetson AGX Orin 64 GB | T4 | A2 | A100 | L4 | H100 |
| PeopleNet | 112 | 679 | 429 | 242 | 3,264 | 797 | 7,062 |
| DINO – FAN-S | 3 | 11.4 | 29.9 | 16.5 | 174 | 52.7 | 292 |
| SegFormer – MiT | 1.3 | 4.7 | 6.2 | 4 | 40.6 | 10.4 | 70 |
| OCRNet | 981 | 3,921 | 3,903 | 2,089 | 27,885 | 7,241 | 53,809 |
| EfficientDet | 61 | 227 | 303 | 184 | 1,521 | 522 | 2,428 |
| 2D Body Pose | 136 | 557 | 593 | 295 | 4,140 | 1,010 | 7,812 |
| 3D Action Recognition | 52 | 212 | 269 | 148 | 1,658 | 529 | 2,708 |
人工智能輔助的數據注釋和管理
對于所有人工智能項目來說,數據注釋仍然是一個昂貴且耗時的過程。對于像分割這樣需要在對象周圍的像素級生成分割遮罩的 CV 任務來說尤其如此。通常,分割掩模的成本是對象檢測或分類的 10 倍。
使用 TAO Toolkit 5.0 ,使用新的人工智能輔助注釋功能對分割掩碼進行注釋,速度更快,成本更低。現在,您可以使用弱監督分割架構 Mask Auto Labeler ( MAL )來幫助進行分割注釋,以及固定和收緊用于對象檢測的邊界框。地面實況數據中對象周圍的松散邊界框可能會導致次優檢測結果,但通過人工智能輔助注釋,您可以將邊界框收緊到對象上,從而獲得更準確的模型。
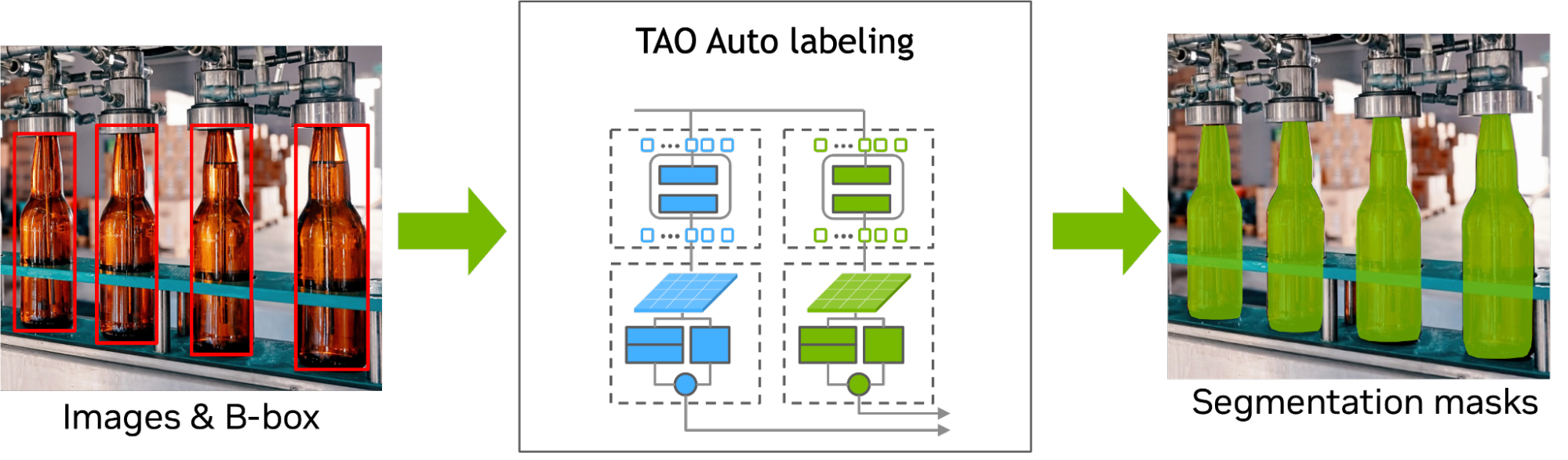
MAL 是一個基于 transformer 的掩碼自動標記框架,用于僅使用方框注釋的實例分割。 MAL 將方框裁剪圖像作為輸入,并有條件地生成掩碼偽標簽。它對輸入和輸出標簽都使用了 COCO 注釋格式。
MAL 顯著減少了自動標注和人工標注之間的差距,以獲得遮罩質量。使用 MAL 生成的掩碼訓練的實例分割模型可以幾乎匹配完全監督的對應模型的性能,保留了高達 97.4% 的完全監督模型的性能。
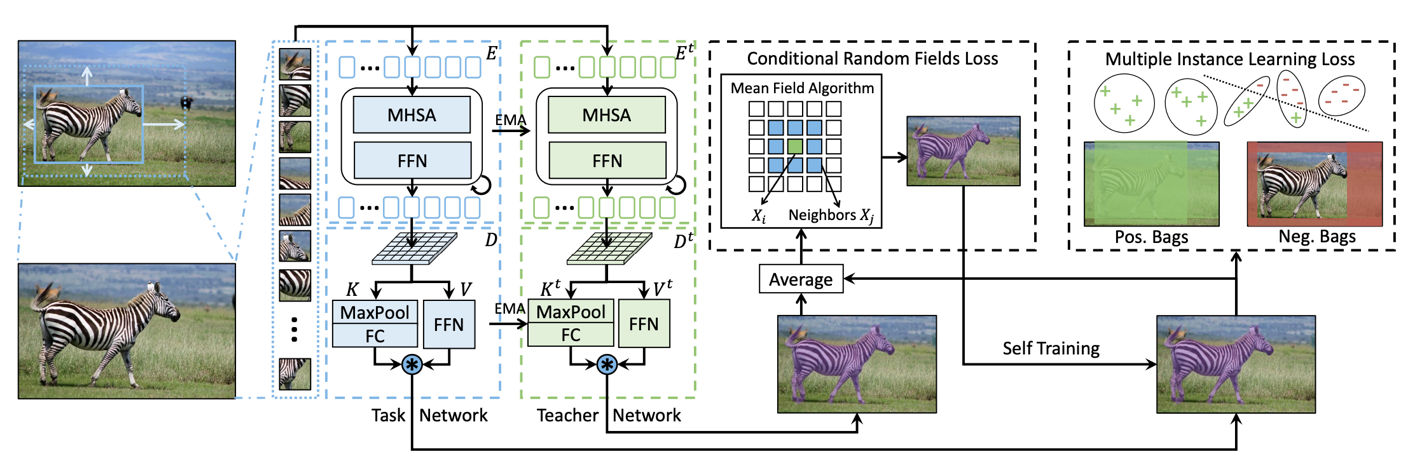
在訓練 MAL 網絡時,任務網絡和教師網絡(共享相同的 transformer 結構)一起工作,以實現類不可知的自我訓練。這使得能夠細化具有條件隨機場( CRF )損失和多實例學習( MIL )損失的預測掩碼。
TAO Toolkit 在自動標記管道和數據擴充管道中都使用了 MAL 。具體而言,用戶可以在空間增強的圖像上生成偽掩模(例如,剪切或旋轉),并使用生成的掩模細化和收緊相應的邊界框。
最先進的愿景 transformer
transformer 已經成為 NLP 中的標準架構,這主要是因為自我關注。它們還因一系列視覺人工智能任務而廣受歡迎。一般來說,基于 transformer 的模型可以優于傳統的基于 CNN 的模型,因為它們具有魯棒性、可推廣性和對大規模輸入執行并行處理的能力。所有這些都提高了訓練效率,對圖像損壞和噪聲提供了更好的魯棒性,并在看不見的對象上更好地泛化。
TAO Toolkit 5.0 為流行的 CV 任務提供了幾種最先進的( SOTA )愿景 transformer ,具體如下。
全注意力網絡
全注意力網絡( FAN )是 NVIDIA Research 的一個基于 transformer 的主干家族,它在抵御各種破壞方面實現了 SOTA 的魯棒性。這類主干可以很容易地推廣到新的領域,并且對噪聲、模糊等更具魯棒性。
FAN 塊背后的一個關鍵設計是注意力通道處理模塊,它可以實現穩健的表征學習。 FAN 可以用于圖像分類任務以及諸如對象檢測和分割之類的下游任務。

FAN 系列支持四個主干,如表 2 所示。
| Model | # of parameters/FLOPs | Accuracy |
| FAN-Tiny | 7 M/3.5 G | 71.7 |
| FAN-Small | 26 M/6.7 | 77.5 |
| FAN-Base | 50 M/11.3 G | 79.1 |
| FAN-Large | 77 M/16.9 G | 81.0 |
全球環境愿景 transformer
全局上下文視覺 transformer ( GC ViT )是 NVIDIA Research 的一種新架構,可實現非常高的準確性和計算效率。 GC ViT 解決了視覺中缺乏誘導性偏倚的問題 transformer 。通過使用局部自注意,它在 ImageNet 上使用較少的參數獲得了更好的結果。
局部自我注意與全局上下文自我注意相結合,可以有效地模擬長距離和短距離的空間交互。圖 6 顯示了 GC ViT 模型體系結構。有關更多詳細信息,請參見 Global Context Vision Transformers 。

如表 3 所示, GC ViT 家族包含六個主干,從 GC ViT xxTiny (計算效率高)到 GC ViT Large (非常準確)。 GC ViT 大型模型在 ImageNet-1K 數據集上可以實現 85.6 的 Top-1 精度,用于圖像分類任務。該體系結構還可以用作其他 CV 任務的主干,如對象檢測、語義和實例分割。
| Model | # of parameters/FLOPs | Accuracy |
| GC-ViT-xxTiny | 12 M/2.1 G | 79.6 |
| GC-ViT-xTiny | 20 M/2.6 G | 81.9 |
| GC-ViT-Tiny | 28 M/4.7 G | 83.2 |
| GC-ViT-Small | 51 M/8.5 G | 83.9 |
| GC-ViT-Base | 90 M/14.8 G | 84.4 |
| GC-ViT-Large | 201 M/32.6 G | 85.6 |
DINO?
DINO ( d 檢測 transformer ,帶有 i 改進的 n oising anch o r )是最新一代 de 檢測 tr 編碼器( DETR )。它實現了比前代更快的訓練收斂時間。可變形 DETR ( D-DETR )至少需要 50 個歷元才能收斂,而 DINO 可以在 COCO dataset 上收斂 12 個歷元。與 D-DETR 相比,它還實現了更高的精度。
DINO 通過在訓練過程中使用去噪來實現更快的收斂,這有助于在提案生成階段進行二分匹配過程。由于二分匹配的不穩定性,類 DETR 模型的訓練收斂較慢。二部分匹配消除了手工制作和計算量大的 NMS 操作的需要。然而,它通常需要更多的訓練,因為在二分匹配過程中,不正確的基本事實與預測相匹配。
為了解決這個問題, DINO 引入了有噪聲的正地面實況盒和負地面實況盒來處理“無對象”場景。因此, DINO 的訓練收斂得非常快。有關更多信息,請參閱 DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection 。
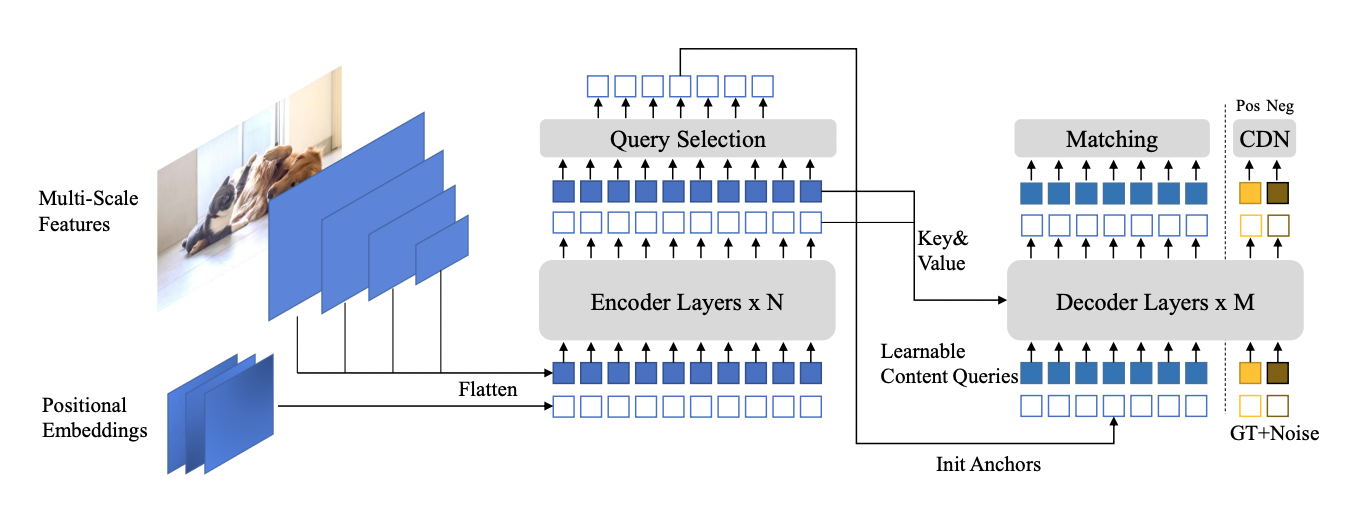
TAO Toolkit 中的 DINO 是靈活的,可以與傳統細胞神經網絡的各種骨干(如 ResNets )和基于 transformer 的骨干(如 FAN 和 GC ViT )相結合。表 4 顯示了流行 YOLOv7 的各種版本的 DINO 上的 COCO 數據集的準確性。有關更多詳細信息,請參見 YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors 。
| Model | Backbone | AP | AP50 | AP75 | APS | APM | APL | Param |
| YOLOv7 | N/A | 51.2 | 69.7 | 55.5 | 35.2 | 56.0 | 66.7 | 36.9M |
| DINO | ResNet50 | 48.8 | 66.9 | 53.4 | 31.8 | 51.8 | 63.4 | 46.7M |
| ? | FAN-Small | 53.1 | 71.6 | 57.8 | 35.2 | 56.4 | 68.9 | 48.3M |
| ? | GCViT-Tiny | 50.7 | 68.9 | 55.3 | 33.2 | 54.1 | 65.8 | 46.9M |
分段窗體
SegFormer 是一種基于 transformer 的輕量級語義分割。解碼器由輕量級 MLP 層制成。它避免了使用位置編碼(主要由 transformer s 使用),這使得推理在不同分辨率下高效。
將 FAN 骨干網添加到 SegFormer MLP 解碼器中會產生一個高度魯棒和高效的語義分割模型。 FAN-based hybrid + SegFormer 是 Robust Vision Challenge 2022 語義分割的獲勝架構。

| Model | Dataset | Mean IOU (%) | Retention rate (robustness) (%) |
| PSPNet | Cityscapes Validation | 78.8 | 43.8 |
| SegFormer – FAN-S-Hybrid | Cityscapes validation | 81.5 | 81.5 |
目標檢測和分割之外的 CV 任務
NVIDIA TAO 工具包加速了傳統對象檢測和分割之外的各種 CV 任務。 TAO Toolkit 5.0 中新的字符檢測和識別模型使開發人員能夠從圖像和文檔中提取文本。這自動化了文檔轉換,并加速了保險和金融等行業的用例。
當被分類的對象變化很大時,檢測圖像中的異常是有用的,這樣就不可能用所有的變化進行訓練。例如,在工業檢測中,缺陷可以是任何形式的。如果訓練數據之前沒有發現缺陷,那么使用簡單的分類器可能會導致許多遺漏的缺陷。
對于這樣的用例,將測試對象直接與黃金參考進行比較將獲得更好的準確性。 TAO Toolkit 5.0 的特點是暹羅神經網絡,在該網絡中,模型計算被測對象和黃金參考之間的差異,以便在對象有缺陷時進行分類。
使用 AutoML 實現超參數優化的自動化培訓
自動機器學習( autoML )自動化了在給定數據集上為所需 KPI 尋找最佳模型和超參數的手動任務。它可以通過算法推導出最佳模型,并抽象掉人工智能模型創建和優化的大部分復雜性。
TAO Toolkit 中的 AutoML 可完全配置,用于自動優化模型的超參數。它既適合人工智能專家,也適合非專家。對于非專家來說,引導 Jupyter notebook 提供了一種簡單有效的方法來創建準確的人工智能模型。
對于專家來說, TAO Toolkit 可以讓您完全控制要調整的超參數和要用于掃描的算法。 TAO Toolkit 目前支持兩種優化算法:貝葉斯優化和雙曲線優化。這些算法可以掃描一系列超參數,以找到給定數據集的最佳組合。
AutoML 支持多種 CV 任務,包括一些新的視覺 transformer ,如 DINO 、 D-DETR 、 SegFormer 等。表 6 顯示了受支持網絡的完整列表(粗體項目是 TAO Toolkit 5.0 的新增項目)。
| Image classification | Object detection | Segmentation | Other |
| FAN | DINO | SegFormer | LPRNet |
| GC-ViT | D-DETR | UNET | ? |
| ResNet | YoloV3/V4/V4-Tiny | MaskRCNN | ? |
| EfficientNet | EfficientDet | ? | ? |
| DarkNet | RetinaNet | ? | ? |
| MobileNet | FasterRCNN | ? | ? |
| ? | DetectNet_v2 | ? | ? |
| ? | SSD/DSSD | ? | ? |
用于工作流集成的 REST API
TAO Toolkit 是模塊化的、云原生的,這意味著它可以作為容器使用,并且可以使用 Kubernetes 進行部署和管理。 TAO Toolkit 可以作為自管理服務部署在任何公共或私有云、 DGX 或工作站上。 TAO Toolkit 提供了定義良好的 RESTAPI ,使其易于集成到您的開發工作流程中。開發人員可以為所有的訓練和優化任務調用 API 端點。這些 API 端點可以從任何應用程序或用戶界面調用,這可以遠程觸發培訓作業。
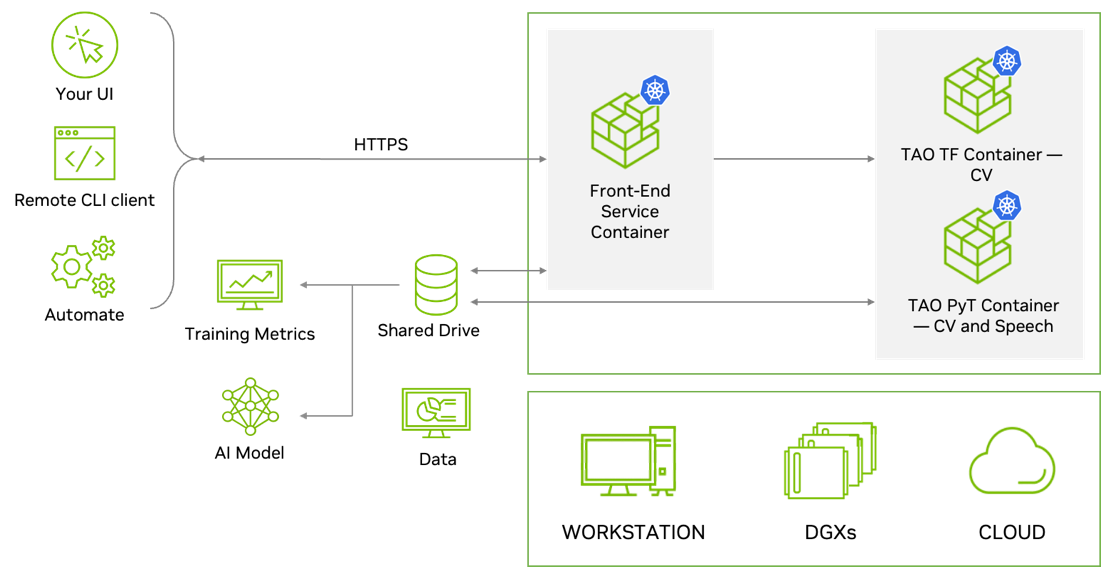
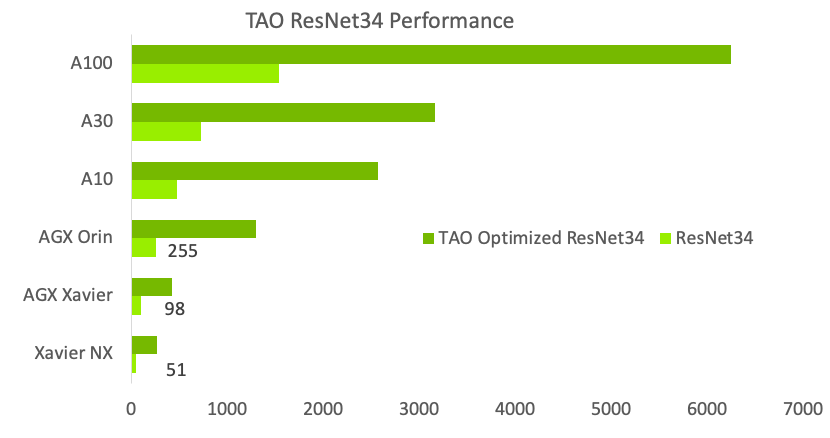
Better inference optimization
為了簡化產品化并提高推理吞吐量, TAO Toolkit 提供了幾種交鑰匙性能優化技術。其中包括模型修剪、較低精度量化和 TensorRT 優化,與公共模型動物園的可比模型相比,這些技術可以將性能提高 4 到 8 倍。
開放靈活,具有更好的支撐
人工智能模型基于復雜的算法預測輸出。這可能會使人們很難理解系統是如何做出決定的,并且很難調試、診斷和修復錯誤。可解釋人工智能( XAI )旨在通過深入了解人工智能模型如何做出決策來應對這些挑戰。這有助于人類理解人工智能輸出背后的推理,并使診斷和修復錯誤變得更容易。這種透明度有助于建立對人工智能系統的信任。
為了提高透明度和可解釋性, TAO Toolkit 現在將以開源形式提供。開發人員將能夠從內部層查看特征圖,并繪制激活熱圖,以更好地理解人工智能預測背后的推理。此外,訪問源代碼將使開發人員能夠靈活地創建定制的人工智能,提高調試能力,并增加對其模型的信任。
NVIDIA TAO 工具包已準備就緒,可通過 NVIDIA AI Enterprise ( NVAIE )獲得。 NVAIE 為公司提供關鍵業務支持、訪問 NVIDIA 人工智能專家以及優先級安全修復。 Join NVAIE 獲得人工智能專家的支持。
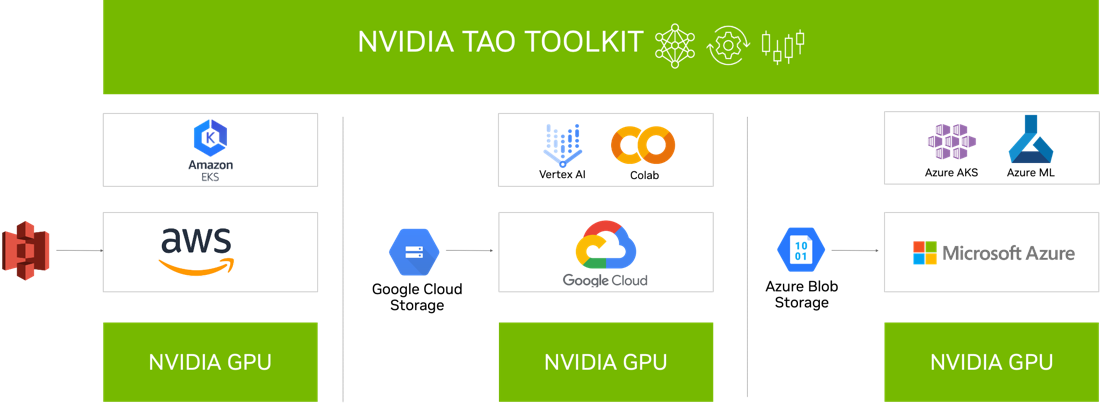
與云服務集成
NVIDIA TAO Toolkit 5.0 集成到您可能已經使用的各種 AI 服務中,如 Google Vertex AI 、 AzureML 、 Azure Kubernetes 服務和 Amazon EKS 。
總結
TAO Toolkit 為任何開發人員、任何服務和任何設備提供了一個平臺,可以輕松地轉移學習他們的自定義模型,執行量化和修剪,管理復雜的訓練工作流程,并執行人工智能輔助注釋,而無需編碼。在 GTC 2023 上, NVIDIA 宣布了 TAO Toolkit 5.0 . Sign up to be notified 關于 TAO Toolkit 的最新更新。
Download NVIDIA TAO Toolkit 并開始創建自定義人工智能模型。您也可以在 LaunchPad 上體驗 NVIDIA TAO 工具包。
?
?