Note: This blog post was originally published on Oct. 28, 2024, but has been edited to reflect new updates.
Fraud in financial services is a massive problem. Financial losses from worldwide credit card transaction fraud are expected to total $403.88 billion over the next 10 years, according to research firm the Nilson Report. While other types of fraud—such as identity theft, account takeover, and money laundering—are also significant concerns, credit card fraud poses a unique challenge due to its high transaction volume and broad attack surface, making it a key target for fraudsters.
Traditional fraud detection methods, which rely on rules-based systems or statistical methods, are reactive and increasingly ineffective in identifying sophisticated fraudulent activities. As data volumes grow and fraud tactics evolve, financial institutions need more proactive, intelligent approaches to detect and prevent fraudulent transactions.
AI offers essential tools for analyzing vast amounts of transactional data, identifying abnormal behaviors, and recognizing patterns that indicate fraud. While steps have been taken to improve detection, even more advanced techniques are needed to improve accuracy, reduce false positives, and enhance operational efficiency in fraud detection.
The NVIDIA AI Blueprint for financial fraud detection uses graph neural networks (GNNs) to detect and prevent sophisticated fraudulent activities for financial services with high accuracy and reduced false positives.
Graph neural networks for fraud detection
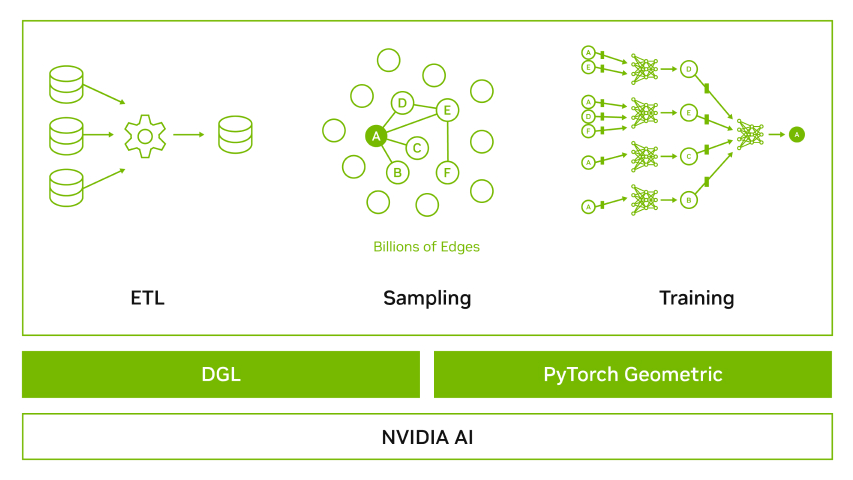
Traditional machine learning (ML) models like XGBoost are effective at identifying anomalous behavior in individual transactions, but fraud rarely occurs in isolation. Fraudsters operate within complex networks, often using connections between accounts and transactions to hide their activities. This is where GNNs come in.
GNNs are designed to work with graph-structured data, making them ideal at detecting financial fraud. Instead of analyzing only individual transactions, GNNs consider accounts, transactions, and devices as interconnected nodes—uncovering suspicious patterns across the entire network.
For example, even if an account appears normal, GNNs can flag it if it’s linked to known fraudsters or resembles high-risk entities—surfacing threats traditional models might miss.
Combining GNNs with XGBoost offers the best of both worlds:
- Higher accuracy: GNNs look at how transactions are connected, rather than examining each transaction on its own. This allows the system to detect fraud patterns that otherwise might go undetected.
- Fewer false positives: With more context, GNNs see the big picture in a transaction and therefore are less likely to flag a normal transaction as suspicious.
- Better scalability: GNNs are built to handle massive networks of data efficiently so pairing them with XGBoost allows for real-time fraud detection (inference) at large scale.
- Explainability: Combining GNNs with XGBoost provides the power of deep learning with the explainability of decision trees.
NVIDIA AI Blueprint for financial fraud detection using GNNs
NVIDIA has built a reference example that combines traditional ML with the power of GNNs. This process builds on a standard XGBoost approach but augments it with GNN embeddings to significantly boost accuracy. While specific metrics vary, even a small improvement—such as 1%—could translate into millions of dollars in savings, making GNNs a critical part of fraud detection systems.
This reference architecture includes two main parts: the model building process and the inference process, as shown in Figure 1.
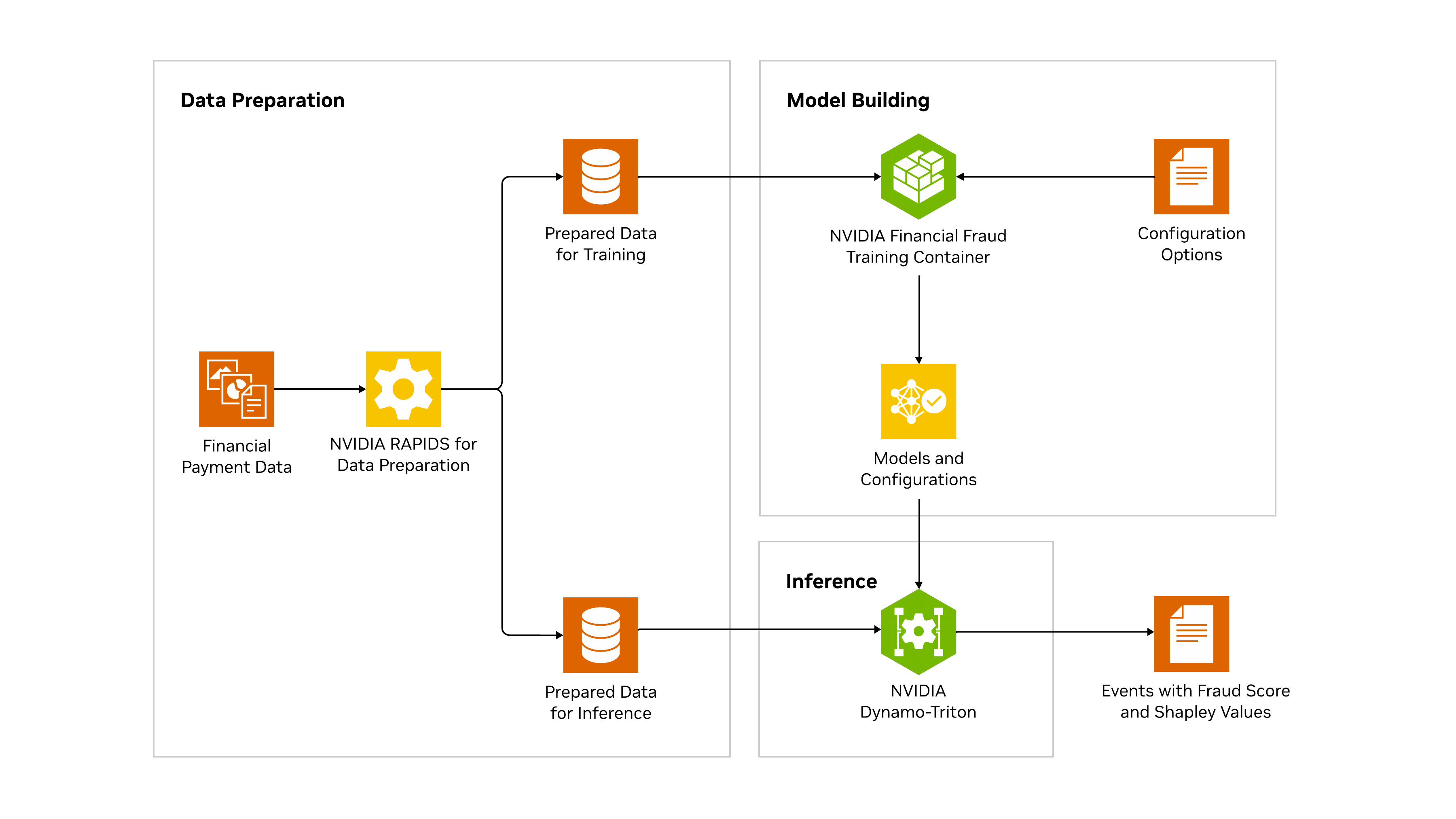
Model building with GNNs and XGBoost
Fraud is detected in the inference phase, but before that, a model needs to be created. The model building process is inside the NVIDIA Financial Fraud Training Container (referred as financial-fraud-training container) and produces an XGBoost model that’s created from GNN embeddings. The container hides the complexity of needing to create both a Feature Store (tabular data) and a Graph Store (structural data). A key benefit of using the container is that it’s optimized for the GNN framework that produces the best performance and accuracy.
The model building workflow is depicted below (Figure 2) and consists of three main steps: data preparation, creating the configuration file, and running the container.

Step 1: Data preparation
Incoming transaction data is cleaned and prepared using tools like RAPIDS, part of NVIDIA CUDA-X libraries, for efficiency. Data preparation and feature engineering have a significant impact on the performance of model building. This step requires a detailed understanding of the data and could take multiple tries to get the best results. The financial-fraud-training container documentation contains a section that offers advice on how to prepare data and what the data requirement needs to be.
Once a script for data preparation has been created, it can be automated in the workflow. The data preparation process should be updated as new data is added or periodically as data grows. The next iteration of this workflow will leverage NVIDIA RAPIDS Accelerator for Apache Spark to accelerate the data processing piece of this workflow.
Step 2: Creating the configuration file
The financial-fraud-training container requires that a configuration file be created, in JSON format, that specifies how the model should be trained and created. The data in that configuration file contains two portions: (A) “paths,” a section defining directory paths for reading data and saving the model; and (B) ”models,” a section that defines the parameters used in training and creating the model.
The paths section defines two parameters:
data_dir:path within the container where the training data is mounted.output_dir:path within the container where the models will be saved after training.
The model section defines how the model will be trained and can be viewed in two parts: the Kind section and the Model Configuration Schema.
The Kind section defines two arguments:
kind: which can beGraphSAGE_XGBoost or XGBoostgpu: which is currently limited to just “single”
The container supports the option to train an XGBoost model directly from the input feature and not generate any GNN embeddings. For some datasets, the pure XGBoost approach could yield better results, but that isn’t true for most datasets. For this blog, the focus is on using GNNs. If you are interested in XGBoost only, please see the documentation for how to create the JSON configuration file for that approach.
The Model Configuration Schema section defines the hyperparameters for both the GNN portion and the XGBoost portion.
Here is an example of a full training configuration file for training an XGBoost model on the embeddings produced by a GNN model.
{ "paths": { // Directory paths within the container "data_dir": "/data" // where training data is mounted. "output_dir": "/trained_models" // where trained models will be saved. }, "models": [ { "kind": "GraphSAGE_XGBoost", // GNN model that prduces the embeddings "gpu": "single", // use single-gpu or multi-gpu "hyperparameters": { "gnn": { // GraphSAGE Hyper-parameters that produces embeddings "hidden_channels": 16, // Number of hidden channels in the GraphSAGE model "n_hops": 1, // Number of hops/layers "dropout_prob": 0.1, // Dropout probability for regularization "batch_size": 1024, // Batch size for training the model "fan_out": 16, // Number of neighbors to sample per node "num_epochs": 16 // Number of training epochs }, "xgb": { // XGBoost Hyper-parameters predicts fraud score "max_depth": 6, // Maximum depth of the tree "learning_rate": 0.2, // Learning rate for boosting "num_parallel_tree": 3, // Number of trees built in parallel "num_boost_round": 512, // Number of boosting rounds "gamma": 0.0 // Minimum loss reduction to make a further partition } } } ]} |
Step 3: Running the container
Now that the data has been prepared and the configuration file created, the last step is to run the financial-fraud-training container to create the model. During the data preparation step, two directories should have been created. Within this example, variables are used for those two directories. Those directories will be mounted to the docker container. The directories are:
host_path_data_root_dir:the directory on the host where the prepared data can be found. As mentioned, that data needs to conform to the required subfolder formats (see documentation).host_path_trained_models:the directory on host where the produced model and required NVIDIA Dynamo scripts will be saved.
The container interacts via some defined ports, and noted below:
NIM_HTTP_PORT = 8002NIM_GRPC_PORT = 50051CONTAINER_NAME = "financial-fraud-training" |
It’s now time to start the container using standard Docker commands.
docker run -d -it --rm --name={CONTAINER_NAME} --gpus "device=0" \-p {NIM_HTTP_PORT}:{NIM_HTTP_PORT} \-e NIM_HTTP_API_PORT={NIM_HTTP_PORT} \-p {NIM_GRPC_PORT}:{NIM_GRPC_PORT} \-e NIM_DISABLE_MODEL_DOWNLOAD=True \-e NIM_GRPC_API_PORT={NIM_GRPC_PORT} \-v {host_path_data_root_dir}:/data \-v {host_path_trained_models}:/trained_models \nvcr.io/nvidia/cugraph/financial-fraud-training:1.0.0 \-e NGC_API_KEY={API_KEY} |
Once the container is running, the last step is to pass in the configuration information and start the training process.
-H "Content-Type: application/json" \-d @{training_config_file_name} |
Inference for real-time fraud detection
Once the model is trained, it can be served for real-time fraud detection using NVIDIA Dynamo-Triton (formerly known as Triton Inference Server), an open source AI model-serving platform that streamlines and accelerates the deployment of AI inference workloads in production. NVIDIA Dynamo-Triton helps enterprises reduce the complexity of model-serving infrastructure, shorten the time needed to deploy new AI models in production, and increase AI inferencing and prediction capacity.
As shown in Figure 3, the inference process involves:
- Transforming the raw input data through the same process used during model building (that is, training).
- Feeding the data to models deployed using the Dynamo-Triton to predict if the transactions are fraudulent. Internally, the data is first fed to a GNN model to convert the transaction data into embeddings, which are then fed to an XGBoost model to predict fraud score.

By incorporating both GNNs and XGBoost, this workflow offers a flexible, high-performance solution for fraud detection. Enterprises can customize the configuration of GNNs and adjust model-building processes based on their unique needs, ensuring the system stays optimized over time.
Ecosystem using the blueprint to enhance fraud detection
Amazon Web Services is among the first partners to integrate NVIDIA AI Blueprint for financial fraud detection with its highly secure accelerated computing capabilities. With this integration, developers who build fraud detection models can use NVIDIA RAPIDS within Amazon EMR for data processing, and leverage the financial-fraud-training Container within Amazon SageMaker for efficient model training. Once models are trained, they are deployed using the NVIDIA Dynamo-Triton on the Amazon SageMaker or Amazon Elastic Kubernetes Service endpoint. The endpoints support serving models from various ML frameworks and offer features such as dynamic batching and concurrent execution.
As these efforts continue to develop, this blueprint will be available across the NVIDIA partner ecosystem for enterprises and developers to prototype it and take it to production through NVIDIA AI Enterprise. Among other early adoption partners are Cloudera, Dell Technologies, EXL, Hewlett Packard Enterprise, Infosys, and SHI International. They’re integrating this blueprint into their labs and offerings for enterprise developers to test out these capabilities.
Get started
As fraud tactics evolve, traditional detection methods fall short. Combining XGBoost with GNNs offers a powerful solution—boosting accuracy, reducing false positives, and improving real-time detection. The NVIDIA AI Blueprint for financial fraud detection is designed to help developers stay ahead of sophisticated fraud attempts and adapt quickly to new threats.
Visit build.nvidia.com to deploy the notebook in an GPU-accelerated environment via NVIDIA Launchable or your own environment via GitHub repository.