NVIDIA Dynamo
NVIDIA Dynamo is an open-source, low-latency, modular inference framework for serving generative AI models in distributed environments. It enables seamless scaling of inference workloads across large GPU fleets with intelligent resource scheduling and request routing, optimized memory management, and seamless data transfer. NVIDIA Dynamo supports all major AI inference backends and features large language model (LLM)-specific optimizations, such as disaggregated serving.
When serving the open-source DeepSeek-R1 671B reasoning model on NVIDIA GB200 NVL72, NVIDIA Dynamo increased throughput—measured in tokens per second per GPU—by up to 30X. Serving the Llama 70B model on NVIDIA Hopper?, it increased throughput by more than 2X. NVIDIA Dynamo is the ideal solution for developers looking to accelerate and scale generative AI models with the highest efficiency at the lowest cost.
NVIDIA Dynamo builds on the successes of the NVIDIA Triton Inference Server, an open-source software that standardizes AI model deployment and execution across every workload.
See NVIDIA Dynamo in Action
See how to quickly set up and deploy NVIDIA Dynamo
Watch VideoWatch KV Cache-Aware Smart Router with NVIDIA Dynamo
Watch VideoLearn how NVIDIA Dynamo enables disaggregated serving
Watch VideoHow NVIDIA Dynamo Works
Models are becoming larger and more integrated into AI workflows that require interaction with multiple models. Deploying these models at scale involves distributing them across multiple nodes, requiring careful coordination across GPUs. The complexity increases with inference optimization methods, like disaggregated serving, which splits responses across different GPUs, adding challenges in collaboration and data transfer.
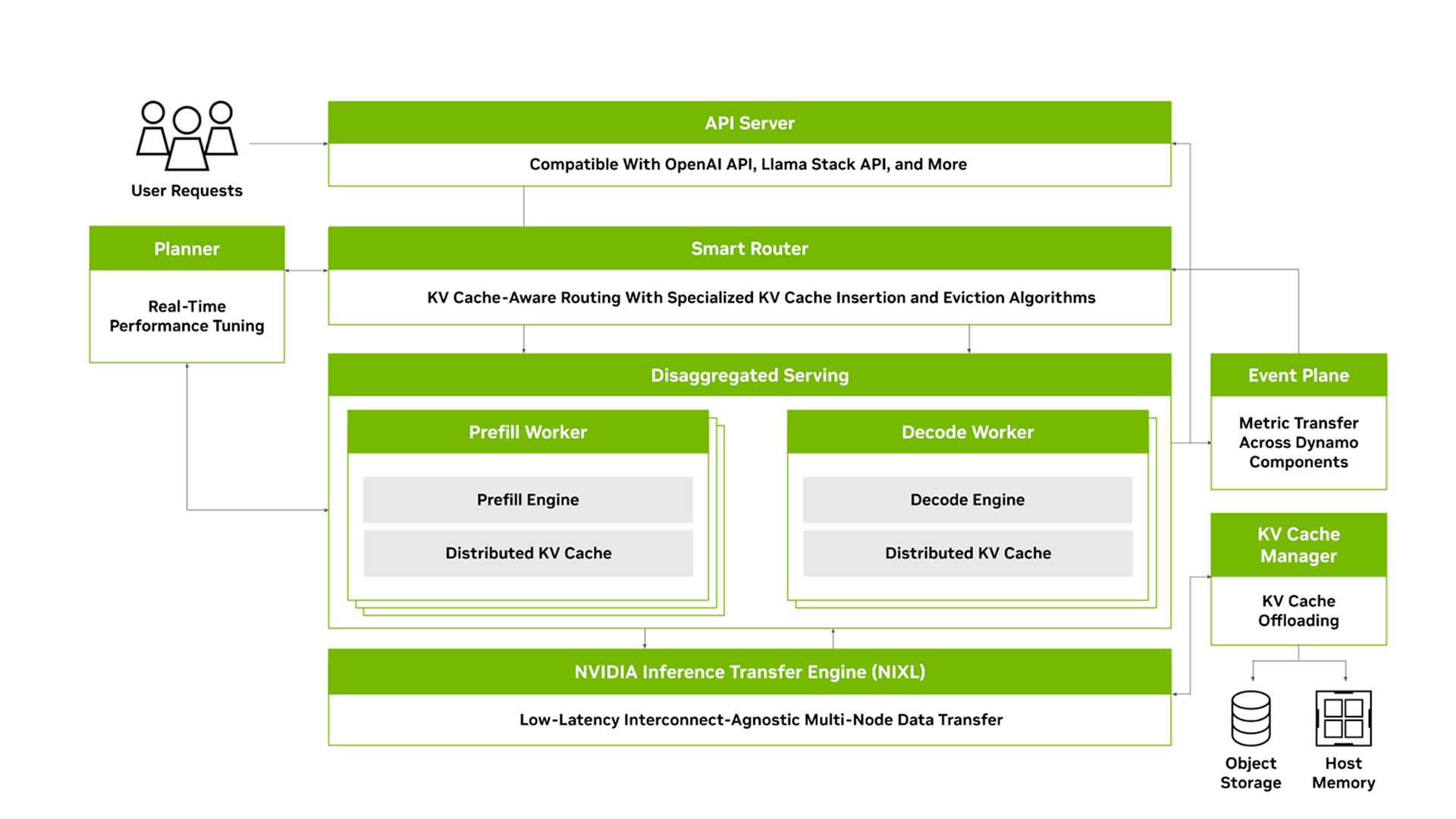
NVIDIA Dynamo addresses the challenges of distributed and disaggregated inference serving. It includes four key components:
GPU Resource Planner: A planning and scheduling engine that monitors capacity and prefill activity in multi-node deployments to adjust GPU resources and allocate them across prefill and decode.
Smart Router: A KV-cache-aware routing engine that efficiently directs incoming traffic across large GPU fleets in multi-node deployments to minimize costly re-computations.
Low Latency Communication Library: State-of-the-art inference data transfer library that accelerates the transfer of KV cache between GPUs and across heterogeneous memory and storage types.
KV Cache Manager: A cost-aware KV cache offloading engine designed to transfer KV cache across various memory hierarchies, freeing up valuable GPU memory while maintaining user experience.
Watch the recording to learn about NVIDIA Dynamo’s key components and architecture and how they enable seamless scaling and optimized inference in distributed environments.
Quick-Start Guide
Learn the basics for getting started with NVIDIA Dynamo, including how to deploy a model in a disaggregated server setup and how to launch the smart router.
Introductory Blog
Read about how NVIDIA Dynamo helps simplify AI inference in production, the tools that help with deployments, and ecosystem integrations.
Deploy LLM Inference With NVIDIA Dynamo and vLLM
NVIDIA Dynamo supports all major backends, including vLLM. Check out the tutorial to learn how to deploy with vLLM.
Get Started With NVIDIA Dynamo
Find the right license to deploy, run, and scale AI inference for any application on any platform.
Download Code for Development
NVIDIA Dynamo is available as open-source software on GitHub with end-to-end examples.
NVIDIA Dynamo is the successor to NVIDIA Triton Inference Server?. The link to the earlier Triton Inference Server Github is here.
Purchase NVIDIA AI Enterprise
NVIDIA AI Enterprise will include NVIDIA Dynamo for production inference. Get a free license to try NVIDIA AI Enterprise in production for 90 days using your existing infrastructure.
Starter Kits
Access technical content on inference topics like prefill optimizations, decode optimizations, and multi-GPU inference.
Multi-GPU Inference
Models have grown in size and can no longer fit on a single GPU. Deploying these models involves distributing them across multiple GPUs and nodes. This kit shares key optimization techniques for multi-GPU inference.
Prefill Optimizations
When a user submits a request to a large language model, it generates a KV cache to compute a contextual understanding of the request. This process is computationally intensive and requires specialized optimizations. This kit presents essential KV cache optimization techniques for inference.
Decode Optimizations
Once the LLM generates the KV cache and the first token, it moves into the decode phase, where it autoregressively generates the remaining output tokens. This kit highlights key optimization techniques for the decoding process.
More Resources


Ethical AI
NVIDIA believes trustworthy AI is a shared responsibility, and we have established policies and practices to support the development of AI across a wide array of applications. When downloading or using this model in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI concerns here.