視覺語言模型最近有了顯著的發展。然而,現有技術通常僅支持一個圖像。他們無法在多個圖像之間進行推理、支持上下文學習或理解視頻。此外,它們不會優化推理速度。
我們開發了 VILA,一個具有整體預訓練、指令調整和部署管道的可視化語言模型,以幫助我們的 NVIDIA 客戶在其多模式產品中取得成功。VILA 在圖像 QA 基準和視頻 QA 基準上都實現了 state-of-the-art(SOTA)性能,具有強大的多圖像推理能力和上下文學習能力。此外,它還針對速度進行了優化。
與其他 VLM 相比,它使用了 1/4 的令牌,并在不損失精度的情況下使用 4 位 AWQ 進行量化。VILA 有多種尺寸,從支持最高性能的 40B 到可部署在 NVIDIA Jetson Orin 等邊緣設備上的 3.5B 不等。
我們設計了一個高效的訓練管道,僅用兩天時間就在 128 NVIDIA A100 GPU 上訓練了 VILA-13B。除了這個研究原型,我們還證明了 VILA 可以通過更多的數據和 GPU 小時進行擴展。
為了提高推理效率,VILA 與 TRT-LLM 兼容。我們使用 4 位 AWQ 量化了 VILA,該 AWQ 在單個 NVIDIA RTX 4090 GPU 上以 10ms/令牌的速度運行 VILA-14B。
VILA 訓練配方?
像 Llava 這樣的現有方法使用視覺指令調整來擴展具有視覺輸入的 LLM,但缺乏對視覺語言預訓練過程的深入研究,在該過程中,模型學習在兩種模態上進行聯合建模。
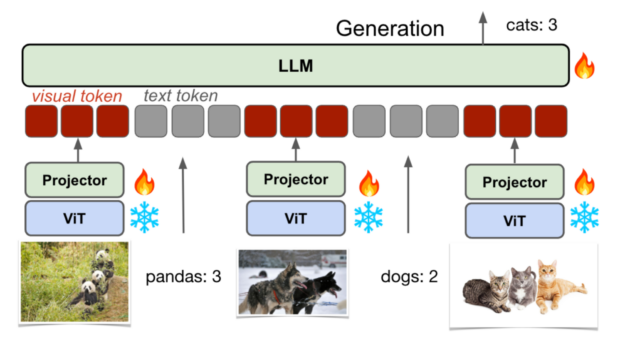
模型架構?
多模式 LLM 可以分為基于交叉注意力和基于自回歸的設置。
后一個標記器將圖像轉換為視覺標記,與文本標記連接,并作為 LLM 的輸入(即,將視覺輸入視為外語)。它是純文本 LLM 的自然擴展,通過與 RAG 類似的視覺嵌入來增強輸入,并且可以處理任意數量的交錯圖像文本輸入。
因此,由于其靈活性和易于量化/部署,我們將重點放在了自回歸架構上。
圖 1 顯示自回歸 VLM 模型由三個主要組件組成:a視覺編碼器、LLM 和 投影儀,它們橋接來自兩種模態的嵌入。該模型可以接受視覺和文本輸入,并生成文本輸出。
解凍 LLM 至關重要?
有兩種流行的方法可以用視覺輸入來增強預訓練的純文本 LLM:在視覺輸入標記上微調 LLM,或者凍結 LLM 并僅訓練視覺輸入投影儀作為提示調整。
后者很有吸引力,因為凍結 LLM 可以防止預訓練的純文本 LLM 的退化。盡管如此,更新基本 LLM 對于繼承一些有吸引力的 LLM 屬性(如上下文學習)至關重要。
我們觀察到以下情況:
- 盡管使用了高容量設計,但在 SFT 期間僅訓練投影儀會導致性能不佳。在 SFT 期間對 LLM 進行微調會更有收獲。
- 有趣的是,在預訓練過程中凍結 LLM 不會影響零樣本性能,但會降低上下文學習能力。
- 當使用小容量投影儀(線性層而不是變壓器塊)時,精度略高(比較 c 和 d)。我們假設,一個更簡單的投影儀迫使 LLM 在處理視覺輸入時學習更多,從而獲得更好的泛化能力。
鑒于這些觀察結果,我們在后續研究的預訓練和教學調整過程中使用了一個簡單的線性投影層來微調 LLM。
交錯的圖像文本數據至關重要?
我們的目標是增強 LLM 以支持視覺輸入,而不是訓練一個只對視覺語言輸入有效的模型。保留 LLM 的純文本功能是至關重要的。
數據管理和混合是預訓練和教學調整的關鍵因素。有兩種數據格式:
- 圖像文本對(即圖像及其標題):<im1><txt1>、<im2><txt2>
- 交錯的圖像文本數據:<txt1><im1><txt2><txt3><im2><txt4>
圖像文本對
像在 COYO 數據集中那樣使用圖像-文本對進行預訓練可能會導致災難性的遺忘。純文本準確性(MMLU)降低了 17.2%。
值得注意的是,4 次拍攝的準確度甚至比零樣本更差,這表明該模型無法正確地對視覺語言輸入進行上下文學習(可能是因為它在預訓練過程中從未看到過一張以上的圖像)。
我們認為,災難性的遺忘是由于基于文本的字幕的分布,這些字幕通常簡短明了。
交錯的圖像文本
另一方面,與純文本語料庫相比,使用像 MMC4 這樣的交錯圖像-文本數據集具有更接近的分布。當使用交織數據進行預訓練時,MMLU 的退化僅為~5%。
通過適當的指令調整,可以完全恢復這種降級。它還實現了視覺上下文學習,與零樣本相比,具有更高的 4 拍攝精度,這是 VILA 的一大亮點。
數據混合
數據混合改進了預訓練,將兩者的優點結合起來。混合交錯語料庫和圖像文本對可以在語料庫中引入更多的多樣性,同時防止嚴重退化。
MMC4+COYO 的訓練進一步提高了視覺語言基準測試的準確性。
通過聯合 SFT 恢復 LLM 退化?
盡管交錯數據有助于保持純文本功能,但仍有 5%的準確性下降。
保持純文本能力的一種潛在方法是添加純文本語料庫(LLM 預訓練中使用的語料庫)。然而,這樣的文本語料庫通常是專有的,即使對于開源模型也是如此。目前還不清楚如何對數據進行子采樣,以匹配視覺語言語料庫的規模。
幸運的是,我們發現純文本功能只是暫時隱藏的,不會被遺忘。盡管使用的規模比文本預訓練語料庫(通常為萬億規模)小得多,但在 SFT 期間添加純文本數據可以幫助彌補退化。
我們觀察到,在純文本的 SFT 數據中混合可以彌補純文本能力的退化,并提高視覺語言能力。我們推測,純文本指令數據提高了模型的指令跟隨能力,這對視覺語言任務也很重要。
有趣的是,在聯合 SFT 中,混合 COYO 數據的好處更為顯著。我們相信,通過聯合 SFT,當使用短字幕進行預訓練時,模型不再遭受純文本的退化,從而釋放出更好的視覺多樣性的全部好處。
圖像分辨率很重要,而不是代幣的數量?
將分辨率從 224 提高到 336 可以將 TextVQA 的準確率從 41.6%提高到 49.8%。
然而,更高的分辨率導致每幅圖像有更多的令牌(336×336 對應于 576 個令牌/幅圖像)和更高的計算成本,在有限的上下文長度下,這對視頻理解來說甚至更糟。我們有一種 LongLoRA 技術來擴展上下文長度,我們計劃將其結合起來。它還限制了上下文學習的演示次數。
幸運的是,原始分辨率比視覺標記/圖像的數量更重要。我們可以使用不同的投影儀設計來壓縮視覺標記。我們嘗試了一種下采樣投影儀,它只需將每 2×2 個標記連接成一個標記,并使用線性層來融合信息。在 336 分辨率下,它將#令牌減少到 144 個,甚至小于 224+線性設置。
盡管如此,TextVQA 的準確性更高(46%對 41.6%),盡管與 336+線性設置相比仍差 3%,顯示出圖像標記中的巨大冗余。其他數據集(如 OKVQA 和 COCO)上的差距較小,因為它們通常需要更高級別的語義。
在我們最初的出版物中,我們沒有在主要結果中應用任何令牌壓縮。然而,在本版本中,我們為各種尺寸的模型提供了這種令牌壓縮技術。
數據質量比數據量更重要?
我們的實驗表明,將預訓練數據從 25M 擴展到 50M 并沒有帶來多大好處。然而,添加約 1M 的高質量數據可以提高基準測試結果。因此,數據質量比數據量重要得多。
為了用高性能但有限的計算資源訓練 VILA,我們更多地關注數據質量而不是數據量。例如,根據 CLIP 評分,我們只選擇了 COYO-700M 數據集的前 5%作為文本圖像對。我們還為視頻字幕數據集過濾了高質量的數據,并將其添加到我們的數據集混合物中。
VILA 部署?
VILA 易于量化并部署在 GPU 上。它用可視化標記增強了 LLM,但沒有改變 LLM 體系結構,后者保持了代碼庫的模塊化。
我們使用 4 位 AWQ 量化了 VILA,并將其部署在 NVIDIA RTX 4090 和 Jetson Orin 上。欲了解更多信息,請參閱 視覺語言智能與 Edge AI 2.0 博客。
AWQ 量化算法適用于多模式應用,因為 AWQ 不需要反向傳播或重建,而 GPTQ 需要。因此,它對新的模態具有更好的泛化能力,并且不會過度擬合到特定的校準集。我們只量化了模型的語言部分,因為它決定了模型的大小和推理延遲。視覺部分占用的延遲不到 4%。
AWQ 在零樣本和各種少熱點設置下優于現有方法(RTN、GPTQ),證明了不同模式和上下文學習工作負載的通用性。
性能?
| 模型 | VQA-V2 | GQA | VQA–T | 科學 QA–I | MME | 種子-I | MMMU 值 | MMMU 測試 |
| LLaVA-NeXT-34B | 83.7 | 67.1 | 69.5 | 81.8 | 1631 | 75.9 | 51.1 | 44.7 |
| 維拉 1.5-40B | 84.3 | 64.6 | 73.5 | 87.4 | 1727 | 75.7 | 51.9 | 46.9 |
| 模型 | 精確 | VQA-V2 | GQA | VQA–T | 科學 QA–I | MME | 種子-I | MMMU 值 | MMMU 測試 |
| 維拉 1.5-13B | fp16 | 82.8 | 64.3 | 65 | 80.1 | 1570 | 72.6 | 37.9 | 33.6 |
| 維拉 1.5-13B | int4 | 82.7 | 64.5 | 64.7 | 79.7 | 1531 | 72.6 | 37.8 | 34 |
| Llama-3-別墅 15-8B | fp16 | 80.9 | 61.9 | 66.3 | 79.9 | 1577 | 71.4 | 36.9 | 36 |
| Llama-3-別墅 15-8B | int4 | 80.3 | 61.7 | 65.4 | 79 | 1594 | 71.1 | 36 | 36.1 |
| 模型 | 精確 | NVIDIA A100 GPU | NVIDIA RTX 4090 | NVIDIA Jetson Orin |
| 維拉 1.5-13B | fp16 | 51 | OOM | 6 |
| 維拉 1.5-13B | int4 | 116 | 106 | 21 |
| Llama-3-別墅 15-8B | fp16 | 75 | 57 | 10 |
| Llama-3-別墅 15-8B | int4 | 169 | 150 | 29 |
視頻字幕性能?
VILA 具有上下文學習能力:在沒有明確描述任務(描述公司、分類和計數以及世界知識)的情況下,使用少量鏡頭示例進行提示,VILA 可以自動識別任務并做出正確的預測。

VILA 具有良好的泛化和推理能力。它可以理解模因,通過多個圖像或視頻幀推理,并處理駕駛場景中的角落案例。

VILA 在 NVIDIA GTC 2024
在 NVIDIA GTC 2024 上,我們宣布了 VILA,以實現從邊緣到云的高效多模式 NVIDIA AI 解決方案。
在邊緣,使用 AWQ 將 VILA 有效地量化為四個比特,這對于 下載,能夠在 NVIDIA Jetson Orin Nano 和 Jetson AGX Orin 平臺上進行實時推理。這大大解決了邊緣機器人和自動駕駛汽車應用所面臨的能源和延遲預算有限的挑戰。有關全面的教程,請參見 視覺語言智能與 Edge AI 2.0 博客。
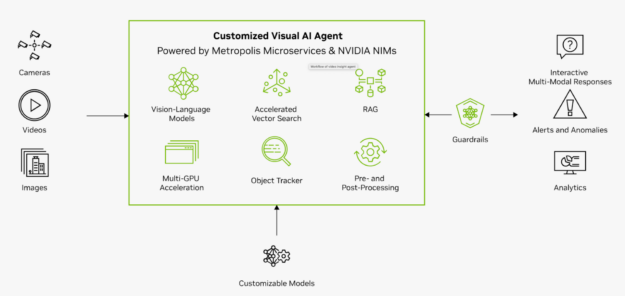
VILA 和 NVIDIA Visual Insight Agent
VILA 在云中增強了 NVIDIA Visual Insight Agent(VIA)框架,使您能夠創建 AI 代理。這些代理人通過回答諸如“工廠第三通道發生了什么?”之類的詢問來協助運營團隊例如,生成型人工智能代理可以立即提供見解,解釋道:“下午 3:30,盒子從貨架上掉下來,擋住了過道。”
使用 VIA 框架,您可以制作人工智能代理,通過視覺語言模型處理大量實時或存檔的視頻和圖像數據。無論是在邊緣還是在云中實現,這一先進一代的視覺人工智能代理都將改變幾乎每個行業。它們使您能夠使用自然語言從視頻內容中總結、搜索和獲得可操作的見解。
欲了解更多信息,請參閱 保持同步:NVIDIA 將數字孿生與實時人工智能相結合,實現工業自動化。
結論?
VILA 提供了一種有效的設計方法,可以將 LLM 擴展到視覺任務,從訓練到推理。充分利用 LLM 的解凍、交錯的圖像-文本數據管理和仔細的文本數據重新混合,VILA 在保持純文本功能的同時,已經超越了最先進的視覺任務方法。
VILA 在多圖像分析、上下文學習和零/少鏡頭任務方面表現出強大的推理能力。我們希望 VILA 能夠幫助 NVIDIA 在 NVIDIA Metropolis、視聽、機器人、生成人工智能等領域建立更好的多模態基礎模型。
有關更多信息,請參閱 VILA:關于視覺語言模型的預訓練 論文和在 GitHub 上的 /Efficient-Large-Model/VILA 庫。
?