編碼在數字時代至關重要,但它也可能繁瑣且耗時。正因如此,許多開發者都在尋找方法,借助 NVIDIA DLSS 3 和 NVIDIA DLSS 3,大型語言模型 (LLM)。這些模型基于經許可的 GitHub 存儲庫中的大量代碼進行訓練,并且無需人工干預即可生成、分析和記錄代碼。
在本文中,我們將探索使用 StarCoder2 的代碼 LLM 的最新進展。StarCoder2 是一種新的社區模型,支持數百種編程語言,并提供一流的準確性。然后,我們嘗試使用 NVIDIA AI 基礎模型和端點,使用分步指令對其進行自定義,并將其部署到生產環境中。
StarCoder2
StarCoder2,由 BigCode 與 NVIDIA 合作,是面向開發者的非常先進的代碼 LLM.您可以使用模型的功能快速構建應用程序,包括代碼完成、自動填充、高級代碼摘要以及使用自然語言檢索相關代碼片段。
StarCoder2 系列包括 3B、7B 和 15B 參數模型,讓您可以靈活地選擇適合您用例和計算資源的模型。本文將重點介紹 15B 模型。
性能
在熱門的編程基準測試中,15B 模型的性能優于領先的開放代碼 LLM,并在同類產品中提供卓越的性能。作為參考,原始 Starcoder 的準確率為 30%.StarCoder2 性能非常適合企業應用,因為它在優化生產成本的同時提供卓越的推理能力。
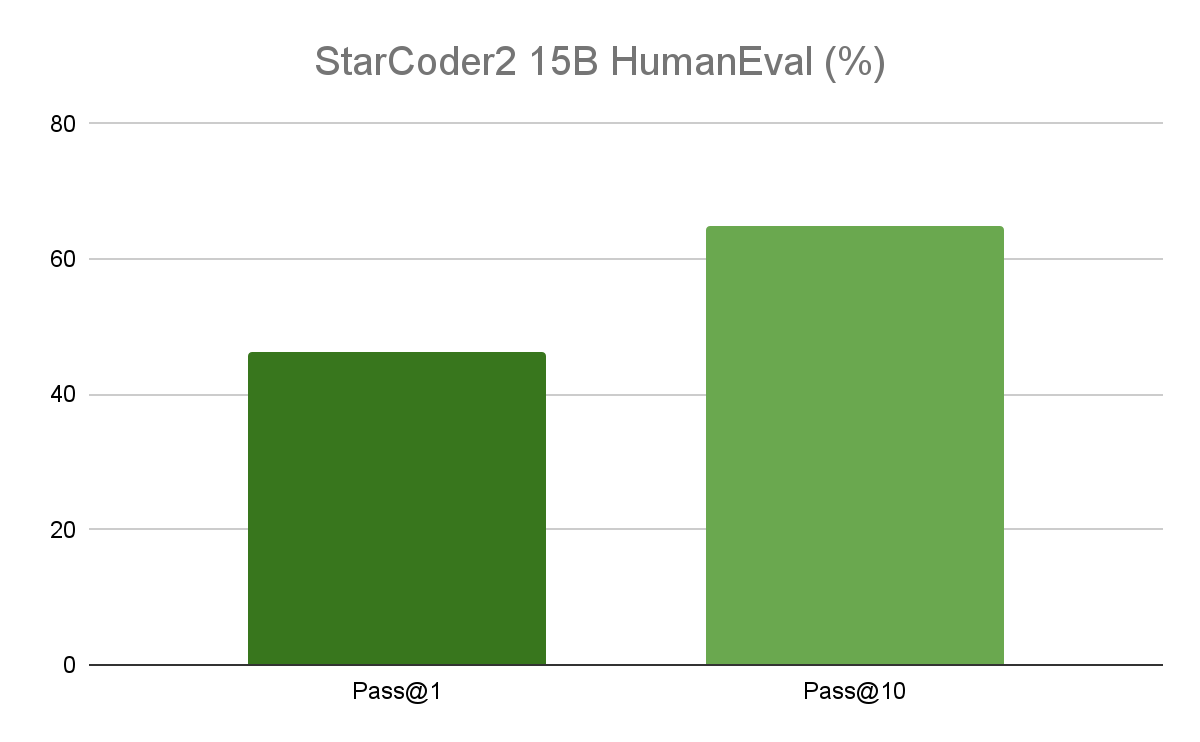
憑借 16000 個令牌的上下文長度,Starcoder 模型可以處理更長的代碼庫和詳細的編碼指令,更好地了解代碼結構,并提供改進的代碼文檔。
接受負責任的培訓,面向所有人
這些模型使用負責任的來源數據進行訓練,這些數據來自 GitHub 的許可數據,包含 1 萬億個令牌。這包括 600 多種編程語言、Git 提交、GitHub 問題和 Jupyter Notebooks.模型在整個過程(包括來源、處理和翻譯)中完全透明。此外,個人可以將其代碼排除在模型之外。
StarCoder2 模型根據 BigCode Open RAIL-M 許可證公開提供,可確保免版稅分發,并簡化公司將模型集成到其用例和產品中的流程。
體驗 StarCoder2
StarCoder2 是 NVIDIA AI 基礎模型和端點 提供對社區和 NVIDIA 構建的一系列精心策劃的生成式 AI 模型的訪問權限,以便在企業應用程序中體驗、自定義和部署。
StarCoder2 可以在 NVIDIA AI 游樂園和其他領先模型(例如 Nemotron-3, Mixtral 8X7B, Lama 70B 以及 穩定擴散。
模型提供。NeMo格式,可借助 NVIDIA NeMo 輕松自定義,并針對性能進行了優化,NVIDIA TensorRT-LLM。
使用 TensorRT-LLM 優化模型
NVIDIA 使用 TensorRT-LLM 優化了模型。TensorRT – LLM 是一個開源庫,用于定義、優化和執行用于推理的大型語言模型。這使您能夠在推理期間實現更高的吞吐量和更低的延遲,同時降低生產中的計算成本。
通過優化注意力機制、模型并行性技術(如 Tensor Parallelism 和 Pipeline Parallelism)、動態批處理、量化等實現的。如需查看優化的完整列表或了解更多信息,請參閱 TensorRT-LLM GitHub。
通過圖形用戶界面體驗模型
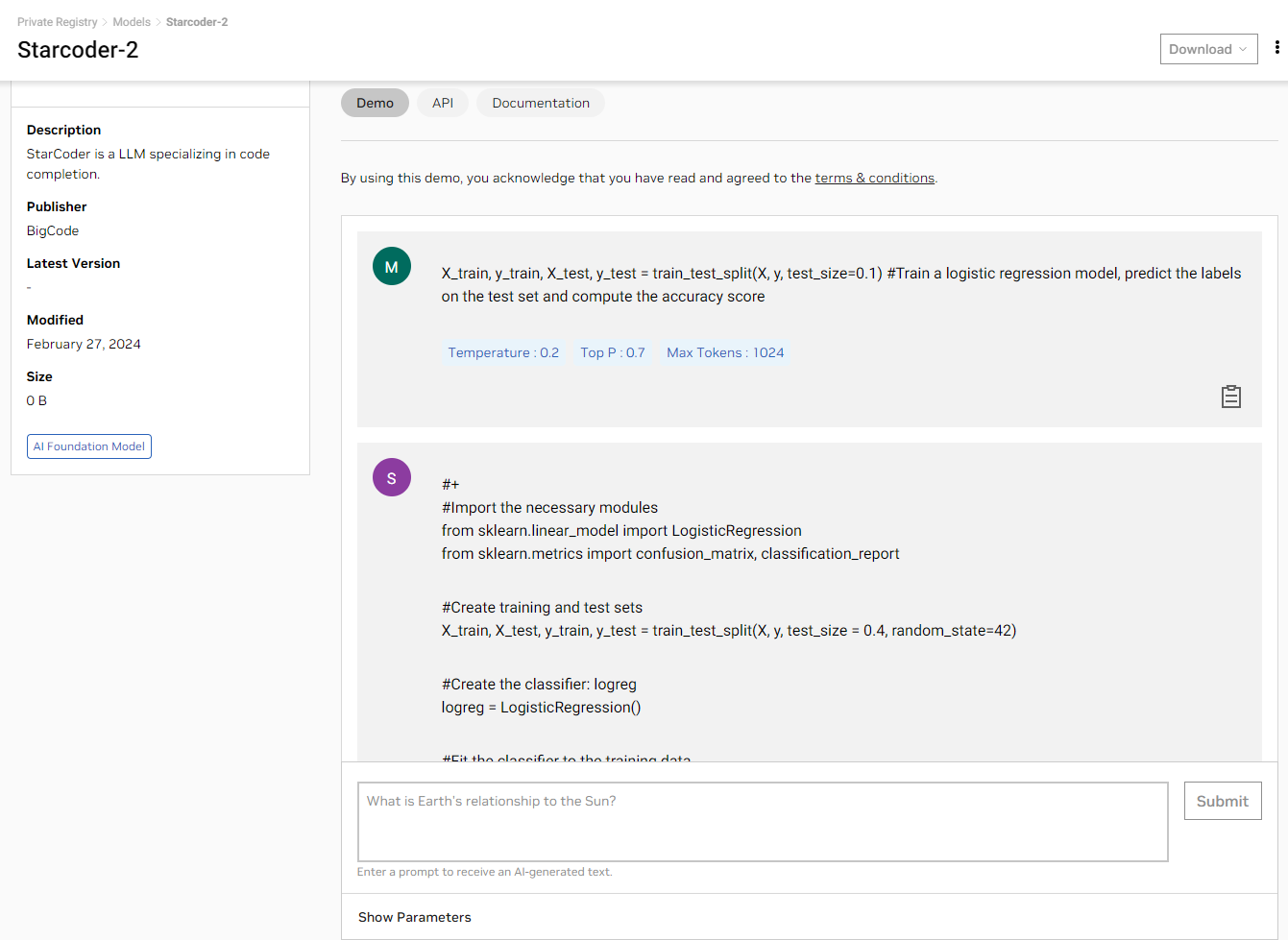
現在,您可以直接在瀏覽器中使用簡單的 Playground 用戶界面體驗 StarCoder2 NGC 目錄 查看在完全加速的堆棧上運行的個模型生成的結果。
使用 API
如果您想使用 API 測試模型,我們可為您提供幫助。登錄 NGC 目錄后,您可以訪問 NVIDIA Cloud Credits.這些 Credits 可讓您將應用程序連接到 API 端點,并大規模體驗模型。
您可以使用能夠向 StarCoder2 AI 游樂園的端點發出 REST 請求的任何語言或框架。以下示例使用 Python 以及請求庫。繼續之前,請確保您擁有能夠執行 Python 代碼的環境,例如 Jupyter Notebook。
獲取 NGC 目錄 API 密鑰
在“API”選項卡上,選擇生成密鑰.如果您尚未注冊,系統會提示您注冊或登錄。
在代碼中設置 API 密鑰:
# Will be used to issue requests to the endpoint
API_KEY = “nvapi-xxxx“
發送推理請求
Starcoder2 可用于代碼完成,以提高開發者的工作效率,生成接下來的幾行給定的部分編寫代碼。
import requests
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/835ffbbf-4023-4cef-8f48-09cb5baabe5f"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
headers = {
"Authorization": "Bearer {}".format(API_KEY),
"Accept": "application/json",
}
payload = {
"prompt": "X_train, y_train, X_test, y_test = train_test_split(X, y, test_size=0.1) #Train a logistic regression model, predict the labels on the test set and compute the accuracy score",
"temperature": 0.1,
"top_p": 0.7,
"max_tokens": 512,
"seed": 42,
"stream": False
}
# re-use connections
session = requests.Session()
response = session.post(invoke_url, headers=headers, json=payload)
while response.status_code == 202:
request_id = response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
response = session.get(fetch_url, headers=headers)
response.raise_for_status()
response_body = response.json()
# The response body contains additional metadata along with completion text. Visualizing just the completion.
print(response_body['choices'][0]['text'])
在本示例中,Starcoder2 會生成 Python 代碼,以按照提示訓練邏輯回歸模型,并提高測試集的計算準確率。
自定義并擁有您的模型
我們明白了。大多數企業不會按原樣使用模型。您需要使用您的領域和公司特定的專業語言訓練模型,以便模型可以提供高精度結果。 NVIDIA 可以使用 NeMo 輕松自定義模型。
模型已經轉換為.nemo格式,使您能夠利用各種 NeMo 功能,包括簡化的 LLM 數據管護、RLHF 等熱門自定義技術,以及可在任何地方部署的容器化軟件。
您可以在本視頻中找到使用高效參數微調 (PEFT) 技術自定義此模型的演示,notebook。
隨時隨地滿懷信心地進行部署
我們 NVIDIA Triton 推理服務器 是一個開源 AI 模型服務平臺,可簡化和加速 AI 推理工作負載在生產中的部署。它幫助企業降低模型服務基礎設施的復雜性,縮短在生產中部署新 AI 模型所需的時間,并提高 AI 推理和預測能力。
NVIDIA Triton 推理服務器是 NVIDIA AI Enterprise 的一部分,具有企業級支持、安全性、穩定性和可管理性。借助 Triton 推理服務器,您可以在本地或任何 CSP 部署 StarCoder2 模型。
這個 notebook 詳細說明如何使用 TensorRT-LLM 進行優化,以及如何使用 Triton 推理服務器部署模型。
使用企業級 AI 軟件部署模型
當 AI 模型準備好為業務運營部署時,安全性、可靠性和企業支持至關重要。
NVIDIA AI Enterprise 是一個端到端軟件平臺,可讓每個企業都能使用生成式 AI,為生成式 AI 基礎模型提供最快、最高效的運行時。它包括具有企業級安全性、支持和穩定性的 AI 框架、庫和工具,可確保大規模從原型到生產的平穩過渡。
開始使用
通過用戶界面或 API 試用 StarCoder2 模型,如果這適合您的應用,請使用 TensorRT-LLM 優化模型,并使用 NVIDIA NeMo。
如果您要構建企業應用程序,請注冊 免費的評估軟件 訪問 NVIDIA AI Enterprise 的框架和企業級支持,將您的應用程序投入生產。
?