大型語言模型 (LLM) 可以從大量文本中學習,并為各種任務和領域生成流暢、一致的文本,從而徹底改變自然語言處理 (NLP)。然而,定制 LLM 是一個具有挑戰性的任務,通常需要 訓練過程,這非常耗時且計算成本高昂。此外,訓練 LLM 需要多樣化且具有代表性的數據集,這可能很難獲取和整理。
企業如何在不支付全部訓練成本的情況下利用 LLM 的強大功能?一個很有前景的解決方案是 Low-Rank Adaptation (LoRA),這是一種微調方法,可以顯著減少可訓練參數的數量、內存需求和訓練時間,同時實現與各種 NLP 任務和領域的微調相當甚至更好的性能。
本文介紹了 LoRA 的直覺、實現和一些應用。它還比較了 LoRA 與監督式微調和提示工程,并討論了它們的優缺點。本文概述了訓練和推理 LoRA 調整模型的實用指南。最后,它演示了如何使用 NVIDIA TensorRT-LLM 在 NVIDIA GPU 上優化 LoRA 模型的部署。
教程預備知識
要充分利用本教程,您需要了解 LLM 訓練和推理流程的基本知識,以及:
- 線性代數基礎知識
- Hugging Face 注冊用戶擁有訪問權限以及對 Transformer 庫的一般了解。
- NVIDIA TensorRT-LLM 優化庫
- NVIDIA Triton 推理服務器 與 TensorRT-LLM 后端。
什么是 LoRA?
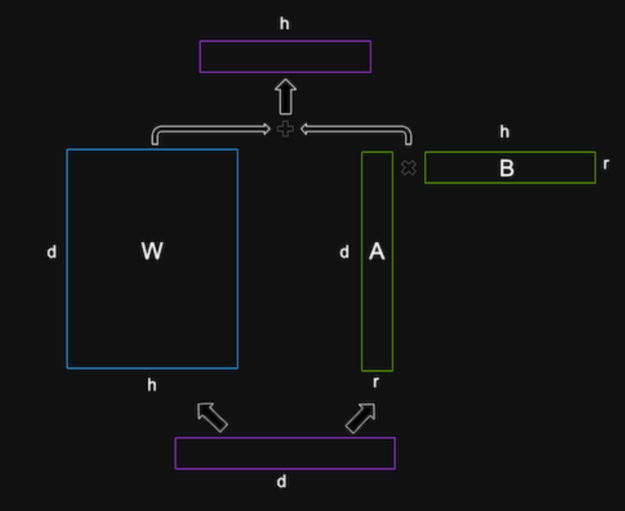
LoRA 是一種微調方法,它在 LLM 架構的每一層中引入低秩矩陣,并僅訓練這些矩陣,同時保持原始 LLM 權重凍結。它是 LLM 架構中支持的 LLM 自定義工具之一,NVIDIA NeMo(圖 1)。
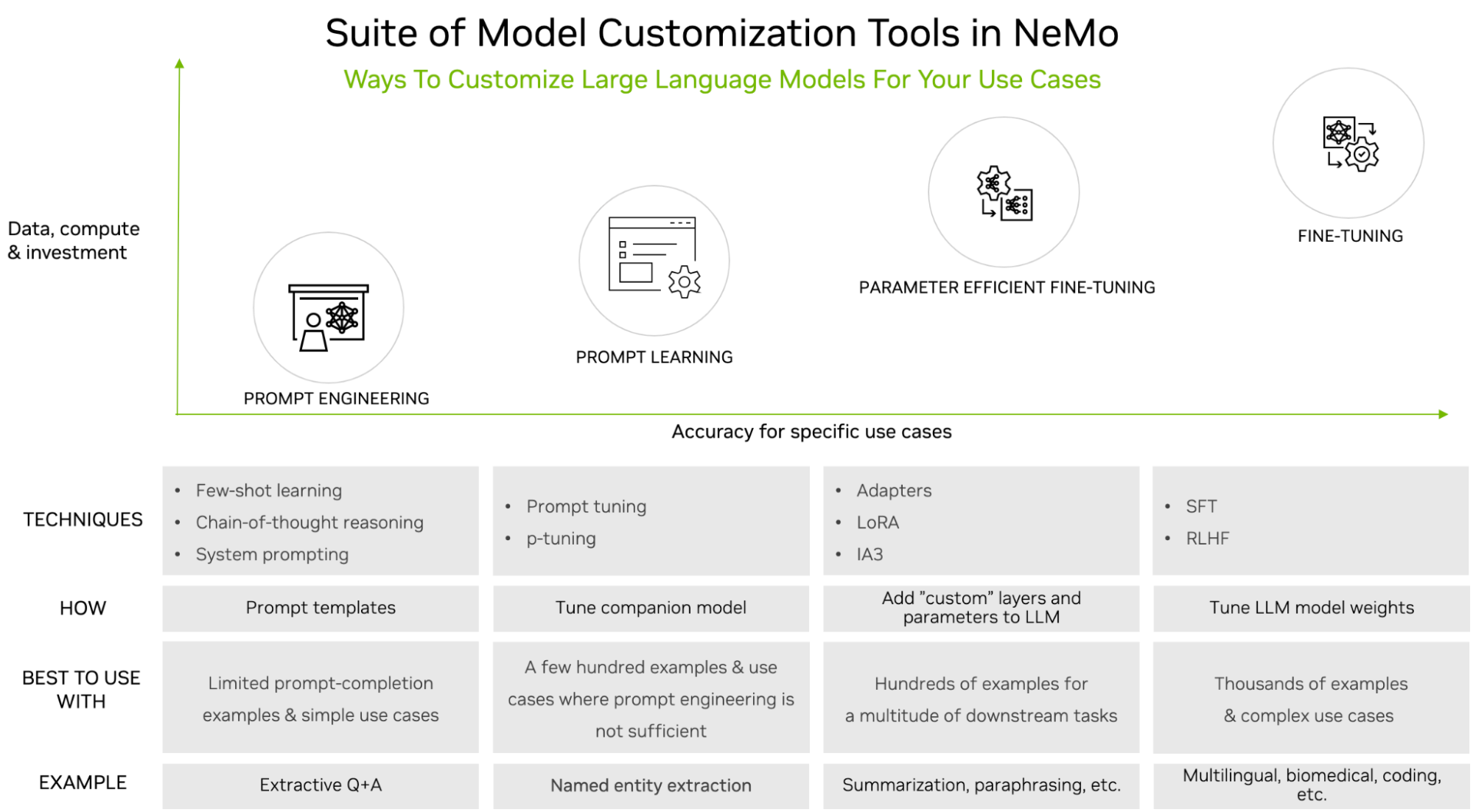
LLM 功能強大,但通常需要自定義,尤其是在用于企業或領域特定的用例時。從簡單的提示工程到監督式微調 (SFT),有許多調整選項。調整選項的選擇通常基于所需數據集的大小 (提示工程為最小值,SFT 為最大值) 和計算可用性。
LoRA 調優是一種名為 Parameter Efficient Fine-Tuning (PEFT) 的調優系列。這些技術是一種中間方法。與提示工程相比,它們需要更多的訓練數據和計算,但也能產生更高的準確性。常見的主題是,它們引入少量參數或層,同時保持原始 LLM 不變。
事實證明,PEFT 在使用更少的數據和計算資源的同時,實現了與 SFT 相當的準確性。與其他調整技術相比,LoRA 有幾個優勢。它降低了計算和內存成本,因為它只添加了幾個新參數,但不添加任何層。它支持多任務學習,通過根據需要部署相關微調的 LoRA 變體,允許單基礎 LLM 用于不同的任務,僅在需要時加載其低秩矩陣。
為了避免災難性的遺忘,LoRA 利用了模型在學習新數據時對先前學習信息的有效利用。與使用提示調整和適配器等替代調整技術模型相比,LoRA 的性能優于這些模型,如 LoRA:大型語言模型的低級別適應。
LoRA 背后的數學運算
LoRA 背后的數學運算基于低秩分解的理念,即通過兩個較小矩陣的乘積求得矩陣的近似值。矩陣的秩是矩陣中線性獨立的行數或列數。低秩矩陣的自由度較低,可以比全秩矩陣更緊湊地表示。
LoRA 對通常非常大且密集的 LLM 權重矩陣應用低秩分解。例如,如果 LLM 的隱藏大小為 1024,詞匯量為 50000,則輸出權重矩陣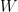
LoRA 分解此矩陣

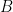
超參數
LoRA 將這些低秩矩陣插入 LLM 的每一層,并將其添加到原始權重矩陣中。原始權重矩陣使用預訓練的 LLM 權重初始化,并且不會在訓練期間更新。低秩矩陣是隨機初始化的,并且是訓練期間更新的唯一參數。LoRA 還對原始矩陣和低秩矩陣的總和應用了層歸一化,以穩定訓練。
多 LoRA 部署
部署 LLM 的一個挑戰是如何高效地為數百或數千個調優模型提供服務。例如,Llama 2 等單個基礎 LLM 在每種語言或區域設置中可能存在許多 LoRA 調優變體。標準系統需要獨立加載所有模型,占用大量內存容量。利用 LoRA 的設計,通過加載單個基礎模型和低秩矩陣,在每個模型中捕獲較小的低秩矩陣中的所有信息(A 和 B 每個經過相應 LoRA 調優的變體)。通過這種方式,可以存儲數千個 LLM,并在最小的 GPU 顯存占用范圍內動態高效地運行它們。
LoRA 調優
LoRA 調整需要以特定格式 (通常使用提示模板) 準備訓練數據集。在形成提示時,您應確定并遵循模式,不同的用例自然會有所不同。下面顯示了一個問答示例。
{????????"taskname": "squad",????????"prompt_template": "<|VIRTUAL_PROMPT_0|> Context: {context}\n\nQuestion: {question}\n\nAnswer:{answer}",????????"total_virtual_tokens": 10,????????"virtual_token_splits": [10],????????"truncate_field": "context",????????"answer_only_loss": True,????????"answer_field": "answer",} |
提示開頭包含所有 10 個虛擬令牌,然后是上下文、問題,最后是答案。訓練數據 JSON 對象中的相應字段將映射到此提示模板,以形成完整的訓練示例。
有多個可用于自定義 LLM 的平臺。您可以使用 NVIDIA NeMo 或工具,例如 HuggingFace PEFT。有關如何使用 NeMo 在 PubMed 數據集上調整 LoRA 的示例,請參閱 NVIDIA NeMo 文檔:使用 Lama 2 的 PEFT 框架。
請注意,本文使用了 Hugging Face 中經過現成調整的 LLM,因此無需進行調整。
LoRA 推理
要使用 TensorRT-LLM 優化 LoRA 調整的 LLM,您必須了解其架構,并確定它最相似的常見基礎架構。本教程使用 Lama 2 13B 和 Lama 2 7B 作為基礎模型,以及 Hugging Face 上提供的幾個 LoRA 調整變體。
第一步是使用此目錄中的轉換器和構建腳本編譯所有模型并為硬件加速做好準備。然后,我將展示使用命令行和 Triton 推理服務器進行部署的示例。
請注意,分詞器并非由 TensorRT-LLM 直接處理。但必須能夠在定義的分詞器系列中對其進行分類,以用于運行時以及在 Triton 中設置預處理和后處理步驟。
設置和構建 TensorRT-LLM
首先,克隆并構建 NVIDIA/TensorRT-LLM 庫。最簡單的方式是使用附帶的 Dockerfile。這些命令將拉取基礎容器并安裝 TensorRT-LLM 所需的所有依賴項。然后,它將在容器中構建并安裝 TensorRT-LLM 本身。
git lfs installgit clone https://github.com/NVIDIA/TensorRT-LLM.gitcd TensorRT-LLMgit submodule update --init --recursivemake -C docker release_build |
檢索模型權重
從 Hugging Face 下載基礎模型和 LoRA 模型:
git-lfs clone https://huggingface.co/meta-llama/Llama-2-13b-hfgit-lfs clone https://huggingface.co/hfl/chinese-llama-2-lora-13b |
編譯模型
構建引擎時,設置 --use_lora_plugin 和 --hf_lora_dir 參數。如果 LoRA 有一個單獨的 `lm_head` 和嵌入,它們將取代 `lm_head` 和基礎模型的嵌入。
python convert_checkpoint.py --model_dir /tmp/llama-v2-13b-hf \?????????????????????????--output_dir ./tllm_checkpoint_2gpu_lora \?????????????????????????--dtype float16 \?????????????????????????--tp_size 2 \?????????????????????????--hf_lora_dir /tmp/chinese-llama-2-lora-13b??????????????????????????trtllm-build --checkpoint_dir ./tllm_checkpoint_2gpu_lora \????????????--output_dir /tmp/new_lora_13b/trt_engines/fp16/2-gpu/ \????????????--gpt_attention_plugin float16 \????????????--gemm_plugin float16 \????????????--lora_plugin float16 \????????????--max_batch_size 1 \????????????--max_input_len 512 \????????????--max_output_len 50 \????????????--use_fused_mlp |
運行模型
在推理期間運行模型時,請設置 lora_dir 命令行參數。請記住使用 LoRA 分詞器,因為 LoRA 調整模型的詞匯量更大。
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \??????????????--max_output_len 50 \??????????????--tokenizer_dir "chinese-llama-2-lora-13b/" \??????????????--input_text "今天天氣很好,我到公園的時后," \??????????????--lora_dir "chinese-llama-2-lora-13b/" \??????????????--lora_task_uids 0 \??????????????--no_add_special_tokens \??????????????--use_py_session?
?Input: "今天天氣很好,我到公園的時后,"Output: "發現公園里人很多,有的在打羽毛球,有的在打乒乓球,有的在跳繩,還有的在跑步。我和媽媽來到一個空地上,我和媽媽一起跳繩,我跳了1" |
您可以運行燒蝕測試來了解 LoRa 調優模型的貢獻。要輕松比較使用和不使用 LoRa 的結果,只需在命令中添加 `–lora_task_uids -1` 參數。在這種情況下,模型將忽略 LoRa 模塊,結果將僅基于基礎模型。
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \??????????????--max_output_len 50 \??????????????--tokenizer_dir "chinese-llama-2-lora-13b/" \??????????????--input_text "今天天氣很好,我到公園的時后," \??????????????--lora_dir "chinese-llama-2-lora-13b/" \??????????????--lora_task_uids -1 \??????????????--no_add_special_tokens \??????????????--use_py_session?
?Input: "今天天氣很好,我到公園的時后,"Output: "我看見一個人坐在那邊邊看書書,我看起來還挺像你,可是我走過過去問了一下他說你是你嗎,他說沒有,然后我就說你看我看看你像你,他說說你看我像你,我說你是你,他說你是你," |
使用多個 LoRA 調優模型運行基礎模型
TensorRT-LLM 支持同時運行具有多個 LoRA 調整模塊的單個基礎模型。在這里,我們使用兩個 LoRA 檢查點作為示例。作為 rank 8 的兩個 Checkpoint,您可以將其設置為 --max_lora_rank 8,以減少 LoRA 插件的內存需求。
此示例使用基于中文數據集 luotuo-lora-7b-0.1 微調的 LoRA 檢查點,以及基于 Japanese-Alpaka-LoRA-7b-v0 微調的 LoRA 檢查點。要加載多個檢查點,請使用 `–lora_dir “luotuo-lora-7b-0.1/” “Japanese-Alpaca-LoRA-7b-v0/”` 參數。TensorRT-LLM 將分配 `lora_task_uids` 這些檢查點。`lora_task_uids -1` 是一個預定義值,代表基礎模型。例如,通過 `lora_task_uids 0 1`,將在第一句中使用第一個 LoRA 檢查點,并在第二句中使用第二個 LoRA 檢查點。
要驗證正確性,請將相同的中文輸入美國的首都在哪里? \n答案: 三次,以及相同的日語輸入 アメリカ合衆國の首都はどこですか? \n答え 三次。(在英語中,這兩種輸入的意思是“美國的首都在哪里? nAnswer”)。然后分別在基本模型 luotuo-lora-7b-0.1 和 Japanese-Alpaka-LoRA-7b-v0 上運行:
git-lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1BASE_LLAMA_MODEL=llama-7b-hf/?
python convert_checkpoint.py --model_dir ${BASE_LLAMA_MODEL} \????????????????????????????--output_dir ./tllm_checkpoint_1gpu_lora_rank \????????????????????????????--dtype float16 \????????????????????????????--hf_lora_dir /tmp/Japanese-Alpaca-LoRA-7b-v0 \????????????????????????????--max_lora_rank 8 \????????????????????????????--lora_target_modules "attn_q" "attn_k" "attn_v"?
trtllm-build --checkpoint_dir ./tllm_checkpoint_1gpu_lora_rank \????????????--output_dir /tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/ \????????????--gpt_attention_plugin float16 \????????????--gemm_plugin float16 \????????????--lora_plugin float16 \????????????--max_batch_size 1 \????????????--max_input_len 512 \????????????--max_output_len 50?
python ../run.py --engine_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \??????????????--max_output_len 10 \??????????????--tokenizer_dir ${BASE_LLAMA_MODEL} \??????????????--input_text "美國的首都在哪里? \n答案:" "美國的首都在哪里? \n答案:" "美國的首都在哪里? \n答案:" "アメリカ合衆國の首都はどこですか? \n答え:" "アメリカ合衆國の首都はどこですか? \n答え:" "アメリカ合衆國の首都はどこですか? \n答え:" \??????????????--lora_dir? "luotuo-lora-7b-0.1/" "Japanese-Alpaca-LoRA-7b-v0/" \??????????????--lora_task_uids -1 0 1 -1 0 1 \??????????????--use_py_session --top_p 0.5 --top_k 0 |
結果如下所示:
Input [Text 0]: "<s> 美國的首都在哪里? \n答案:"Output [Text 0 Beam 0]: "Washington, D.C.What is the"?
Input [Text 1]: "<s> 美國的首都在哪里? \n答案:"Output [Text 1 Beam 0]: "華盛頓。"?
Input [Text 2]: "<s> 美國的首都在哪里? \n答案:"Output [Text 2 Beam 0]: "Washington D.C.'''''"?
Input [Text 3]: "<s> アメリカ合衆國の首都はどこですか? \n答え:"Output [Text 3 Beam 0]: "Washington, D.C.Which of"?
Input [Text 4]: "<s> アメリカ合衆國の首都はどこですか? \n答え:"Output [Text 4 Beam 0]: "華盛頓。"?
Input [Text 5]: "<s> アメリカ合衆國の首都はどこですか? \n答え:"Output [Text 5 Beam 0]: "ワシントン D.C."</s></s></s></s></s></s> |
請注意,luotuo-lora-7b-0.1 在第一句和第五句 (中文) 上生成正確答案。日語 – Alpaka-LoRA-7b-v0 在第六句 (日語) 上生成正確答案。
**重要提示:**如果任何 LoRA 模塊包含經過微調的嵌入表或 Logit GEMM,則用戶必須確保所有模型實例都使用相同的經過微調的嵌入表或 Logit GEMM。
使用 Triton 和機上批處理部署經過 LoRA 調整的模型
本節展示了如何使用 Triton 推理服務器,通過 LoRA 調優的模型進行機上批處理部署。有關設置和啟動 Triton 推理服務器的具體說明,請參閱 NVIDIA TensorRT-LLM 和 NVIDIA Triton:部署 AI 編碼助手。
與之前一樣,首先編譯啟用 LoRA 的模型,這次使用基礎模型 Lama 2 7B。
BASE_MODEL=llama-7b-hf?
python3 tensorrt_llm/examples/llama/build.py --model_dir ${BASE_MODEL} \????????????????--dtype float16 \????????????????--remove_input_padding \????????????????--use_gpt_attention_plugin float16 \????????????????--enable_context_fmha \????????????????--use_gemm_plugin float16 \????????????????--output_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \????????????????--max_batch_size 128 \????????????????--max_input_len 512 \????????????????--max_output_len 50 \????????????????--use_lora_plugin float16 \????????????????--lora_target_modules "attn_q" "attn_k" "attn_v" \????????????????--use_inflight_batching \????????????????--paged_kv_cache \????????????????--max_lora_rank 8 \????????????????--world_size 1 --tp_size 1 |
接下來,生成 LoRA 張量,這些張量將隨每個請求傳入 Triton。
git-lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1?
python3 tensorrt_llm/examples/hf_lora_convert.py -i Japanese-Alpaca-LoRA-7b-v0 -o Japanese-Alpaca-LoRA-7b-v0-weights --storage-type float16python3 tensorrt_llm/examples/hf_lora_convert.py -i luotuo-lora-7b-0.1 -o luotuo-lora-7b-0.1-weights --storage-type float16 |
然后,如前所述,創建 Triton 模型庫并啟動 Triton 服務器。
最后,通過從客戶端發出多個并發請求來運行 multi-LoRA 示例。機上批處理程序將在同一批量中執行具有多個 LoRA 的混合批量。
INPUT_TEXT=("美國的首都在哪里? \n答案:" "美國的首都在哪里? \n答案:" "美國的首都在哪里? \n答案:" "アメリカ合衆國の首都はどこですか? \n答え:" "アメリカ合衆國の首都はどこですか? \n答え:" "アメリカ合衆國の首都はどこですか? \n答え:")LORA_PATHS=("" "luotuo-lora-7b-0.1-weights" "Japanese-Alpaca-LoRA-7b-v0-weights" "" "luotuo-lora-7b-0.1-weights" "Japanese-Alpaca-LoRA-7b-v0-weights")?
for index in ${!INPUT_TEXT[@]}; do????text=${INPUT_TEXT[$index]}????lora_path=${LORA_PATHS[$index]}????lora_arg=""????if [ "${lora_path}" != "" ]; then????????lora_arg="--lora-path ${lora_path}"????fi?
????python3 inflight_batcher_llm/client/inflight_batcher_llm_client.py \????????--top-k 0 \????????--top-p 0.5 \????????--request-output-len 10 \????????--text "${text}" \????????--tokenizer-dir /home/scratch.trt_llm_data/llm-models/llama-models/llama-7b-hf \????????${lora_arg} &done?
wait |
輸出示例如下所示:
Input sequence:? [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]Input sequence:? [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]Input sequence:? [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]Input sequence:? [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]Input sequence:? [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]Input sequence:? [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]Got completed requestInput: アメリカ合衆國の首都はどこですか? \n答え:Output beam 0: ワシントン D.C.Output sequence:? [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 29871, 31028, 30373, 30203, 30279, 30203, 360, 29889, 29907, 29889]Got completed requestInput: 美國的首都在哪里? \n答案:Output beam 0: Washington, D.C.What is theOutput sequence:? [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 5618, 338, 278]Got completed requestInput: 美國的首都在哪里? \n答案:Output beam 0: Washington D.C.Washington D.Output sequence:? [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 360, 29889, 29907, 29889, 13, 29956, 7321, 360, 29889]Got completed requestInput: アメリカ合衆國の首都はどこですか? \n答え:Output beam 0: Washington, D.C.Which ofOutput sequence:? [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 8809, 436, 310]Got completed requestInput: アメリカ合衆國の首都はどこですか? \n答え:Output beam 0: Washington D.C.1. アOutput sequence:? [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 360, 29889, 29907, 29889, 13, 29896, 29889, 29871, 30310]Got completed requestInput: 美國的首都在哪里? \n答案:Output beam 0: 華盛頓WOutput sequence:? [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 1 |
結束語
TensorRT-LLM 對許多熱門的 LLM 架構提供基準支持,可讓用戶輕松地使用各種代碼 LLM 進行部署、實驗和優化。 NVIDIA TensorRT – LLM 和 NVIDIA Triton 推理服務器攜手合作,為高效優化、部署和運行 LLM 提供了不可或缺的工具包。TensorRT – LLM 支持 LoRA 調優模型,支持高效部署自定義 LLM,顯著降低內存和計算成本。
要開始使用,請下載并設置 NVIDIA/TensorRT-LLM 開源庫,并嘗試使用不同的 LLM 示例。您可以使用 NVIDIA NeMo 參考 使用 Llama 2 的 NeMo 框架 PEFT 或 NeMo 框架推理容器。
?