
目前最令人興奮的計算應用程序依賴于在復雜的人工智能模型上進行訓練和運行推理,通常是在要求苛刻的實時部署場景中。需要高性能、加速的人工智能平臺來滿足這些應用程序的需求,并提供最佳的用戶體驗
新的人工智能模型不斷被發明,以實現新的功能,而人工智能驅動的應用程序往往依賴于許多這樣的模型協同工作。這意味著人工智能平臺必須能夠運行最廣泛的工作負載,并在所有工作負載上提供優異的性能。MLPerf Inference– 現在, v3.0 的第七版是一套值得信賴的、經過同行評審的標準化推理性能測試,代表了許多這樣的人工智能模型。
人工智能應用程序無處不在,從最大的超大規模數據中心到緊湊的邊緣設備。 MLPerf 推理同時代表數據中心和邊緣環境。它還代表了一系列真實世界的場景,如離線(批處理)處理、延遲受限的服務器、單流和多流場景。這種工作負載廣度和深度的平衡確保了 MLPerf 推理對于那些希望選擇人工智能基礎設施以最佳滿足不同部署需求的人來說是一種寶貴的資源。
在 MLPerf 推理 v3.0 回合中,NVIDIA submitted results on several products包括…在內NVIDIA H100 Tensor Core GPUs( SXM 和 PCIe 附加卡的形狀因素)基于NVIDIA Hopper architecture,最近宣布NVIDIA L4 Tensor Core GPU由NVIDIA Ada Lovelace GPU architecture,以及NVIDIA Jetson AGX Orin and NVIDIA Jetson Orin NX用于邊緣人工智能和機器人應用的人工智能計算機
NVIDIA AI 平臺( NVIDIA MLPerf 提交的核心)不斷通過軟件創新進行增強,這些創新提高了性能和功能,并利用了最新 NVIDIA 產品和架構的功能。TensorRT 8.6.0, NVIDIA 高性能深度學習推理 SDK 的最新版本,包含在 NVIDIA GPU 云上。要訪問容器,請訪問NVIDIA MLPerf Inference.
在最新提交的 NVIDIA MLPerf 推理中,添加了許多軟件增強功能,包括支持和優化,以利用 NVIDIA Ada Lovelace 架構為NVIDIA L4 Tensor Core GPU,支持 NVIDIA Jetson Orin NX 、新內核,以及支持 NVIDIA 網絡部門提交的重要工作
NVIDIA 平臺在提交的文件中提供了破紀錄的性能、能效和多功能性。這些成就需要在 NVIDIA 全棧平臺的每一層進行創新,從芯片和系統到網絡和推理軟件。這篇文章詳細介紹了這些結果背后的一些軟件優化
NVIDIA Hopper GPU 實現又一次飛躍
在這一輪中, NVIDIA 使用 NVIDIA DGX H100 系統提交了可用類別的結果,該系統現已全面生產。 DGX H100 在 NVIDIA H100 Tensor Core GPU 的驅動下,每臺加速器的性能都處于領先地位,與NVIDIA MLPerf Inference v2.1 H100 submission從 6 個月前開始,與 NVIDIA A100 Tensor Core GPU 相比,它已經實現了顯著的性能飛躍。本文后面詳細介紹的改進推動了這些結果。(請注意,每個加速器的性能不是 MLPerf 的主要指標。)
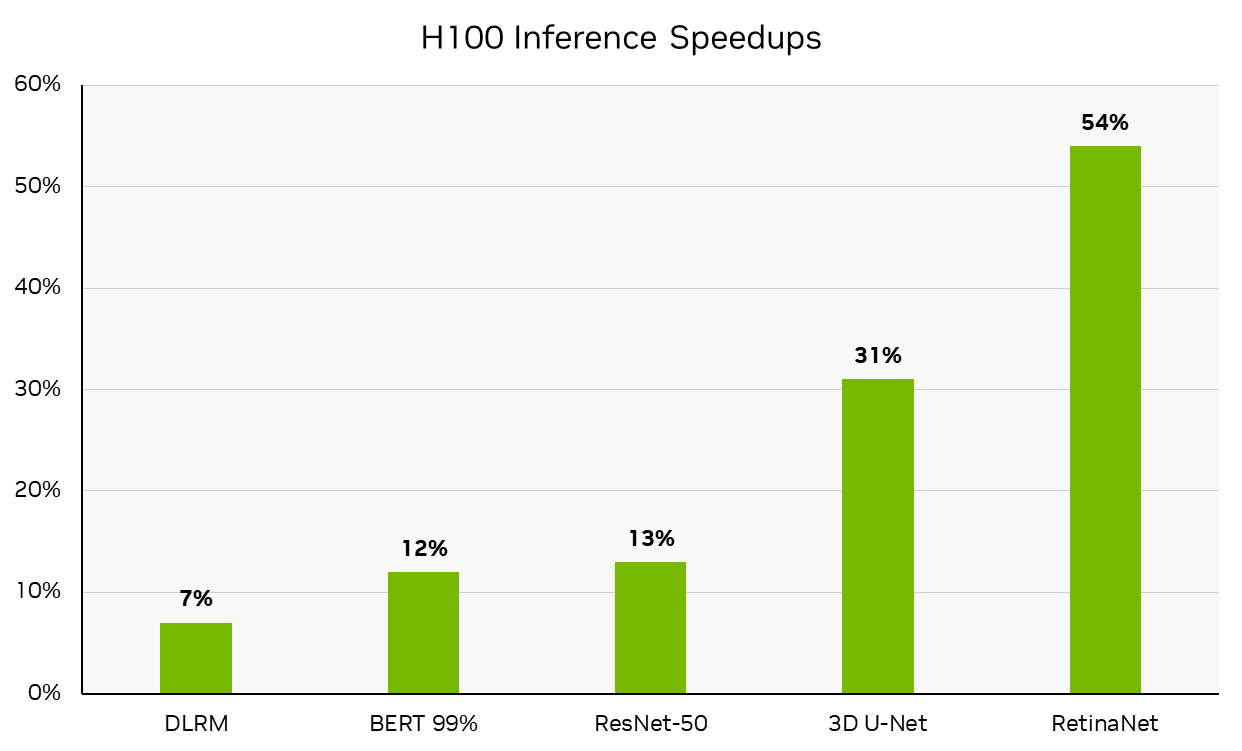
每加速器性能不是 MLPerf 推斷的主要指標。 MLPerf 推理 v3.0 :數據中心,已關閉。通過計算 MLPerf 推理 v3.0 結果 ID 3.0-0070 (可用)中報告的推理吞吐量與 MLPerf 推斷 v2.1 結果 ID 2.1-0121 (預覽)中報告推理吞吐量相比的百分比增長得出的性能增長。 MLPerf 的名稱和標志是 MLCommons 協會在美國和其他國家的商標。保留所有權利。嚴禁未經授權使用。看見網址: www.mlcommons.org了解更多信息
NVIDIA L4 Tensor Core GPU 領先
在 MLPerf 推理 v3.0 中, NVIDIA 首次提交了NVIDIA L4 Tensor Core GPU。 L4 基于新的 NVIDIA Ada Lovelace 架構,是流行的 NVIDIA T4 Tensor Core GPU 的繼任者,在相同的單插槽、低剖面 PCIe 外形中為 AI 、視頻和圖形提供了顯著改進。
NVIDIA Ada Lovelace 架構將第四代 Tensor 核心與 FP8 結合在一起,即使在高精度下也能實現出色的推理性能。在 MLPerf 推理 v3.0 中, L4 的性能比 T4 高出 3 倍, BERT 的參考( FP32 )精度為 99.9% ,這是 MLPerf 推斷 v3.0 中測試的最高 BERT 精度級別
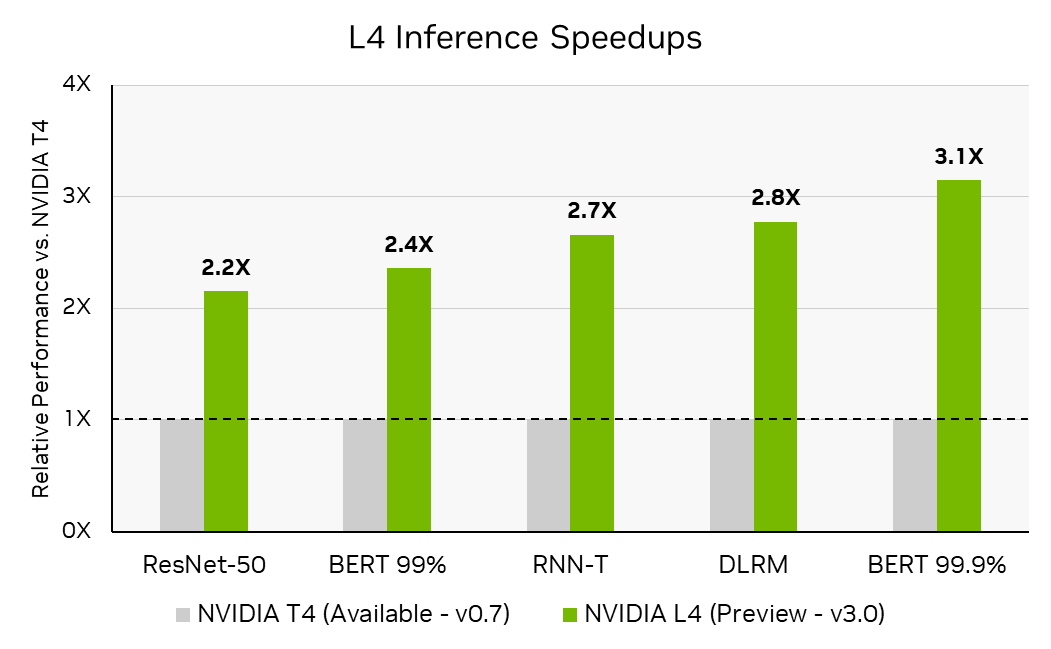
每加速器吞吐量不是 MLPerf 推斷的主要指標。 MLPerf 推理 v3.0 :數據中心關閉。通過將 MLPerf 推理 v0.7 結果 ID 0.7-113 中報告的推理吞吐量除以加速器數量來計算每個加速器吞吐量的 T4 張量核心 GPU ,并計算 3.0-0123 (預覽)中 L4 張量核心 GPU 的推理性能與 T4 的計算的每個加速器吞吐量之比來計算推理加速。 MLPerf 的名稱和標志是 MLCommons 協會在美國和其他國家的商標。保留所有權利。嚴禁未經授權使用。看見網址: www.mlcommons.org了解更多信息
NVIDIA L4 還集成了一個大型 L2 緩存,為提高性能和能源效率提供了額外的機會。在 NVIDIA MLPerf Inference v3.0 提交中,實現了兩個關鍵的軟件優化,以利用更大的二級緩存:緩存駐留和持久緩存管理.
L4 上更大的 L2 緩存使 MLPerf 工作負載完全在緩存中。二級緩存以比 GDDR 內存更低的功率提供更高的帶寬,因此 GDDR 訪問的顯著減少有助于提高性能和減少能源使用
與將批處理大小設置為最大容量時的性能相比,當優化批處理大小以使工作負載完全適應二級緩存時,觀察到的性能高出 1.4 倍
另一個優化使用L2 cache persistence在中首次引入的功能NVIDIA Ampere architecture這使開發人員能夠通過對 TensorRT 的單個調用來標記二級緩存的子集,從而可以對其進行優先保留(即,計劃最后驅逐)。當在駐留機制下工作時,此功能對于推理特別有用,因為開發人員可以將內存重新用于整個模型執行的層激活,從而顯著減少 GDDR 寫入帶寬的使用
使用 NVIDIA DGX A100 和 NVIDIA 網絡提交網絡劃分
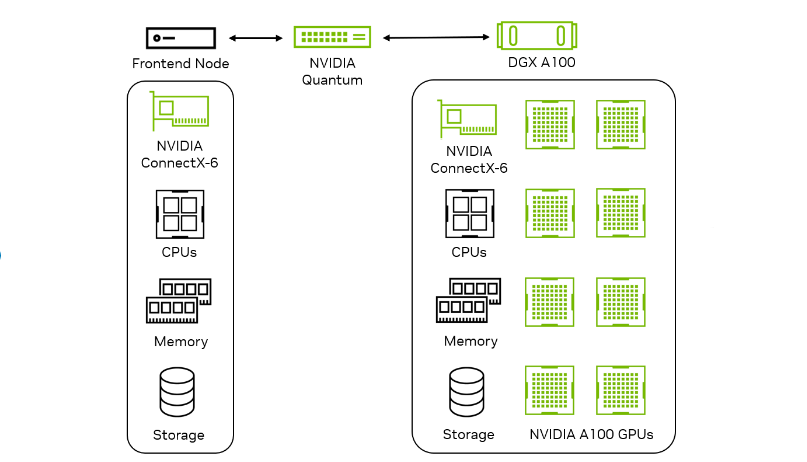
在 MLPerf 推理 v3.0 中, NVIDIA 首次在網絡部門提交,旨在衡量網絡對真實數據中心設置中推理性能的影響。網絡結構,如以太網或NVIDIA InfiniBand將推理加速器節點連接到查詢生成前端節點。目標是衡量 Accelerator 節點的性能,以及 NIC 、交換機和結構等網絡組件的影響
| 基準 | NVIDIA DGX A100 x8 | 網絡事業部業績 與封閉式部門相比 |
| RN50 低精度 | 脫機 | 100% |
| RN50 低精度 | 服務器 | 100% |
| BERT 低精度 | 脫機 | 94% |
| BERT 低精度 | 服務器 | 96% |
| BERT 高精度 | 脫機 | 90% |
| BERT 高精度 | 服務器 | 96% |
網絡部門提交的性能相對于相應的封閉部門提交的百分比不是 MLPerf 推理 v3.0 的主要指標。通過將 MLPerf 推理 v3.0 結果 ID 3.0-0136 中 ResNet-50 和 BERT 上報告的吞吐量除以 3.0-0068 中報告的吞吐量計算的百分比。 MLPerf 的名稱和標志是 MLCommons 協會在美國和其他國家的商標。保留所有權利。嚴禁未經授權使用。看見網址: www.mlcommons.org了解更多信息。
在 v3.0 網絡部門, NVIDIA 提交了關于 ResNet-50 和 BERT 數據中心工作負載的報告。通過利用高帶寬和低延遲,它們在 ResNet-50 上實現了 100% 的單節點性能GPUDirect RDMA上的技術NVIDIA ConnectX-6 InfiniBand smart adapters由于主機上的批處理開銷,. BERT 對性能的影響最小。
幾種 NVIDIA 技術結合在一起,實現了這些高性能結果:
- 來自 TensorRT 的優化推理引擎
- InfiniBand 遠程直接內存訪問( RDMA )網絡傳輸,用于低延遲、高通量張量通信,基于IBV verbs在里面Mellanox OFED軟件堆棧
- 用于配置交換、運行狀態同步和心跳監測的以太網 TCP 套接字
- 利用 CPU / GPU / NIC 資源實現 NUMA 感知實現,以獲得最佳性能
NVIDIA Jetson Orin NX 顯著提升性能
NVIDIA Jetson Orin NX 16 GB該模塊是最先進的人工智能計算機,適用于更小、更低功率的自主機器。在其首次提交的 MLPerf 推理中,與前代 NVIDIA Jetson Xavier NX 相比,它的性能提高了 3.2 倍。 NVIDIA 與Connect Tech關于 Jetson Orin NX MLPerf 推理 v3.0 提交,該提交托管在Boson NGX007 carrier boardConnect Tech Boson 支持 Jetson Orin NX 系列和 Jetson Orin Nano 系列,具有可用于開發和生產的緊湊型載板;將 Orin 的強大功能與商用現貨的便利性相結合。
使用 Connect Tech 的 Boson NGX007 L4T 圖像和由 cuDNN 、 TensorRT 和 CUDA 組成的 Jetson AGX Orin 軟件堆棧,在 Jetson Orin NX 上開箱即用。 Jetson AGX Orin 和 Jetson Orin NX 共享相同的提交代碼,展示了 NVIDIA 軟件堆棧在新的 Jetson 產品、第三方承載板和主機系統上運行的多功能性
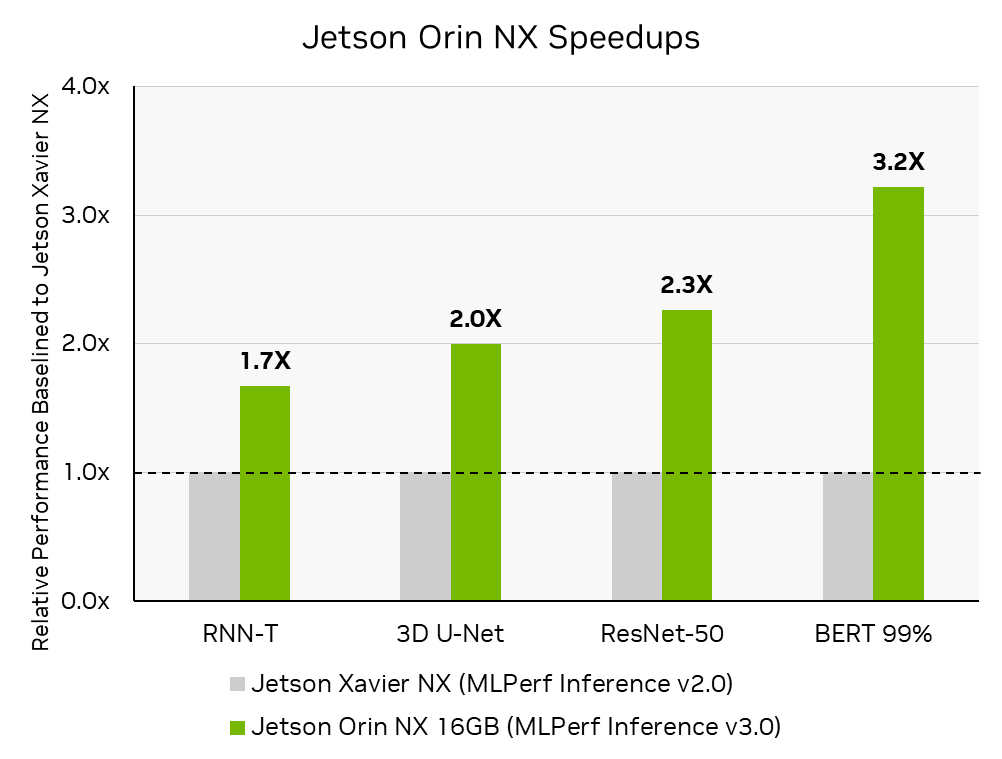
MLPerf 推理 v3.0 :邊緣,關閉。通過計算 MLPerf 推理 v3.0:Edge , Closed MLPerf ID 3.0-0079 中報告的推理吞吐量的增加,與 MLPerf 推斷 v2.0:Edge , Closeed MLPerf ID2.0-113 中報告的相比,獲得性能提高。 MLPerf 的名稱和標志是 MLCommons 協會在美國和其他國家的商標。保留所有權利。嚴禁未經授權使用。看見網址: www.mlcommons.org了解更多信息。
RetinaNet 優化
在 MLPerf 推理 v3.0 中, NVIDIA 通過全棧內核改進和優化的非最大值抑制( NMS ),將所有提交產品的 RetinaNet 吞吐量提高了 20-60% 。
RetinaNet NMS 預處理階段具有顯著的計算吞吐量和內存帶寬,這是由于將 10 個卷積層輸出重塑、轉置和級聯為兩個張量。序列化和篩選還導致計算資源利用不足。
為了解決這些問題, NVIDIA 開發了一個優化的內核,該內核可以并行轉換卷積層的輸出。此外,標簽得分過濾與轉置融合,從而隱藏了內存負載開銷,并加快了后續的分段排序。通過這些優化, NMS 現在比 2.1 中的速度快了 50% 。
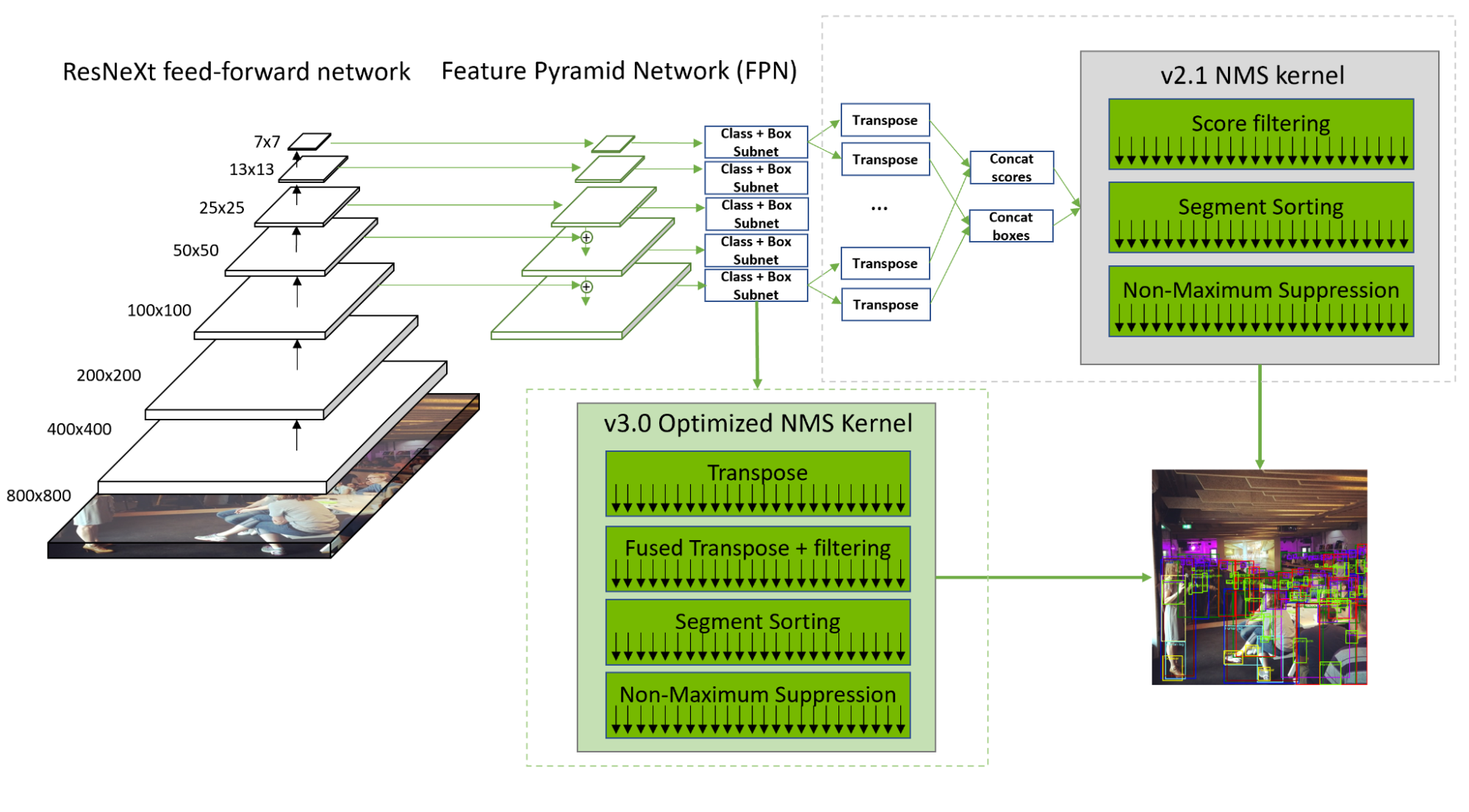
NVIDIA 還增加了對在Deep Learning Accelerator( DLA )內核。現在在 DLA 3.12.1 和 TensorRT 8.5.2 中提供,該支持使 RetinaNet 的非 NMS 部分能夠完全在 DLA 上運行,而不是在 GPU 和 DLA 之間轉換工作負載。整個非 NMS 部分可以編譯為單個可加載的 DLA ,并卸載到運行時,使 RetinaNet 能夠在 GPU 和 DLA 上同時運行。
DLA 3.12.1 優化通過提高 SRAM 的利用率,以及一種新的搜索算法來確定 SRAM 中激活數據和權重數據之間的最佳分割比,從而最大限度地減少了延遲和 DRAM 帶寬。參觀NVIDIA/Deep-Learning-Accelerator-SW有關詳細信息,請訪問 GitHub 。
這減少了 20% 的延遲和 50% 的 DRAM 消耗。這些 DLA 優化也有利于其他 CNN 工作負載。此外, DLA 軟件還優化了 ResNeXt 分組卷積模式,使 DRAM 流量增加 1.8 倍,減少 1.8 倍。
Orin DLA 功能的這種有效利用對于將 RetinaNet 的性能和能效提高 50% 以上(在同一硬件上不到一年的時間)至關重要,從而實現 NVIDIA 不斷提高 Jetson AGX Orin 軟件性能的承諾。看見Delivering Server-Class Performance at the Edge with NVIDIA Jetson Orin了解更多信息。
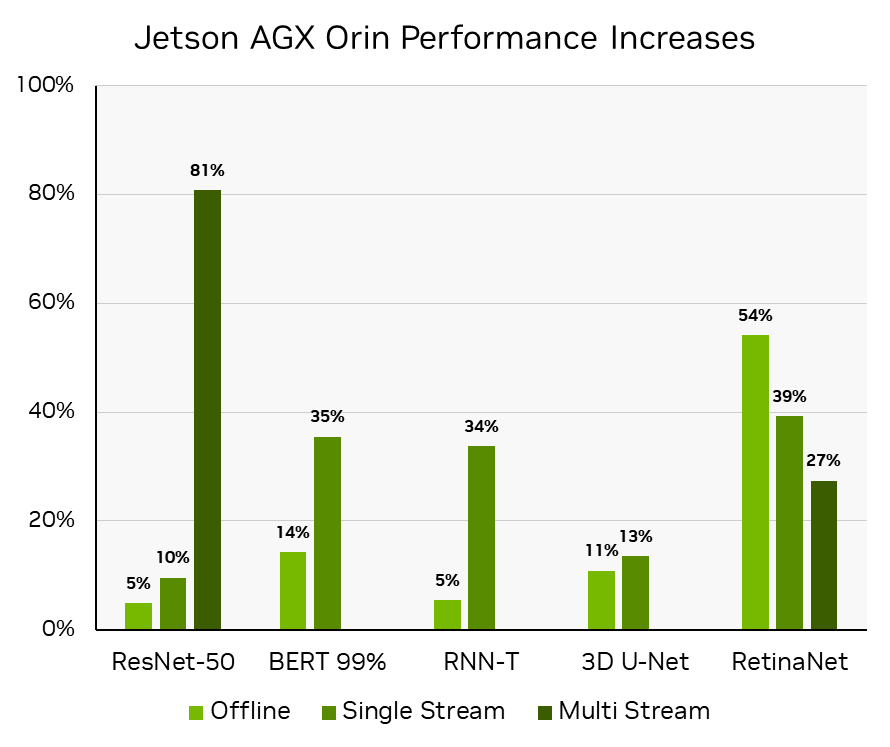
通過計算 MLPerf 推理 v3.0:Edge , Closed 中報告的推理吞吐量的百分比來獲得性能提高。 MLPerf ID 3.0-0080 與 MLPerf 推理 v2.0:Edge 中報告的那些相比, ResNet-50 、 BERT 和 RNN-T 工作負載的 MLPerf IDs 為 2.0-140 關閉,與 MLPerf 推理 v2.1:Edge 中報告, RetinaNet 為 2.1-0095 關閉,因為 RetinaNet 是在 v2.1 中首次添加的。 MLPerf 的名稱和標志是 MLCommons 協會在美國和其他國家的商標。保留所有權利。嚴禁未經授權使用。看見網址: www.mlcommons.org了解更多信息。
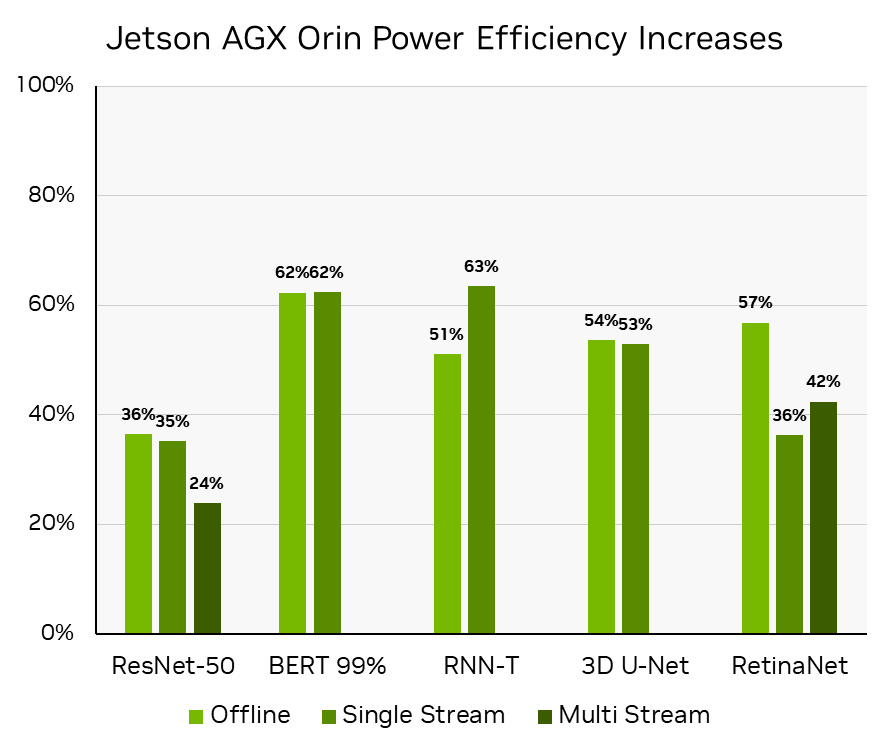
MLPerf 推理 v3.0 :邊緣,閉合,電源。功率效率是通過計算 MLPerf 推理 v3.0 MLPerf ID 3.0-0081 中離線場景的吞吐量/瓦和單流和多流場景的焦耳/流的增加來推導的,相比之下, ResNet-50 、 BERT 和 RNN-T 工作負載的 MLPerf 推斷 v2.0 MLPerf ID2.1-141 和 RetinaNet 的 MLPerf 推理 v2.1 MLPerf ID:2.1-0096 ,因為 RetinaNet 是在 MLPerf 推理 v2.1 中首次添加的。
3D U-Net 分批次滑動窗口
3D U-Net 對 KiTS19 輸入數據使用滑動窗口推理。每個輸入圖像被劃分為具有 50% 重疊的 ROI 子體積,并用于子體積分割。對結果進行聚合和歸一化,以獲得輸入圖像的分割。看見Getting the Best Performance on MLPerf Inference 2.0了解更多信息。
對于 MLPerf 推理 v3.0 ,引入了滑動窗口批處理來進行子卷的批處理。由于批處理僅在給定圖像的子卷上進行,而不是在不同圖像之間進行,因此這也有利于單流場景。(參見MLPerf Inference: NVIDIA Innovations Bring Leading Performance了解更多詳細信息。)這提高了 GPU 的利用率,尤其是使用 NVIDIA A100和H100[Z1K1’時,性能提高了30%。
挑戰在于確保在重疊元素的最終輸出張量聚合中引入的競爭條件期間的函數正確性。為了解決這個問題,CUDA Cooperative Groups在聚合和規范化內核中使用。盡管這增加了同步開銷,但由于將相鄰子卷批處理在一起會帶來好處,因此可以獲得更好的性能。子卷有 50% 的數據重疊,這提高了緩存并減少了內存流量。
ResNet-50 優化
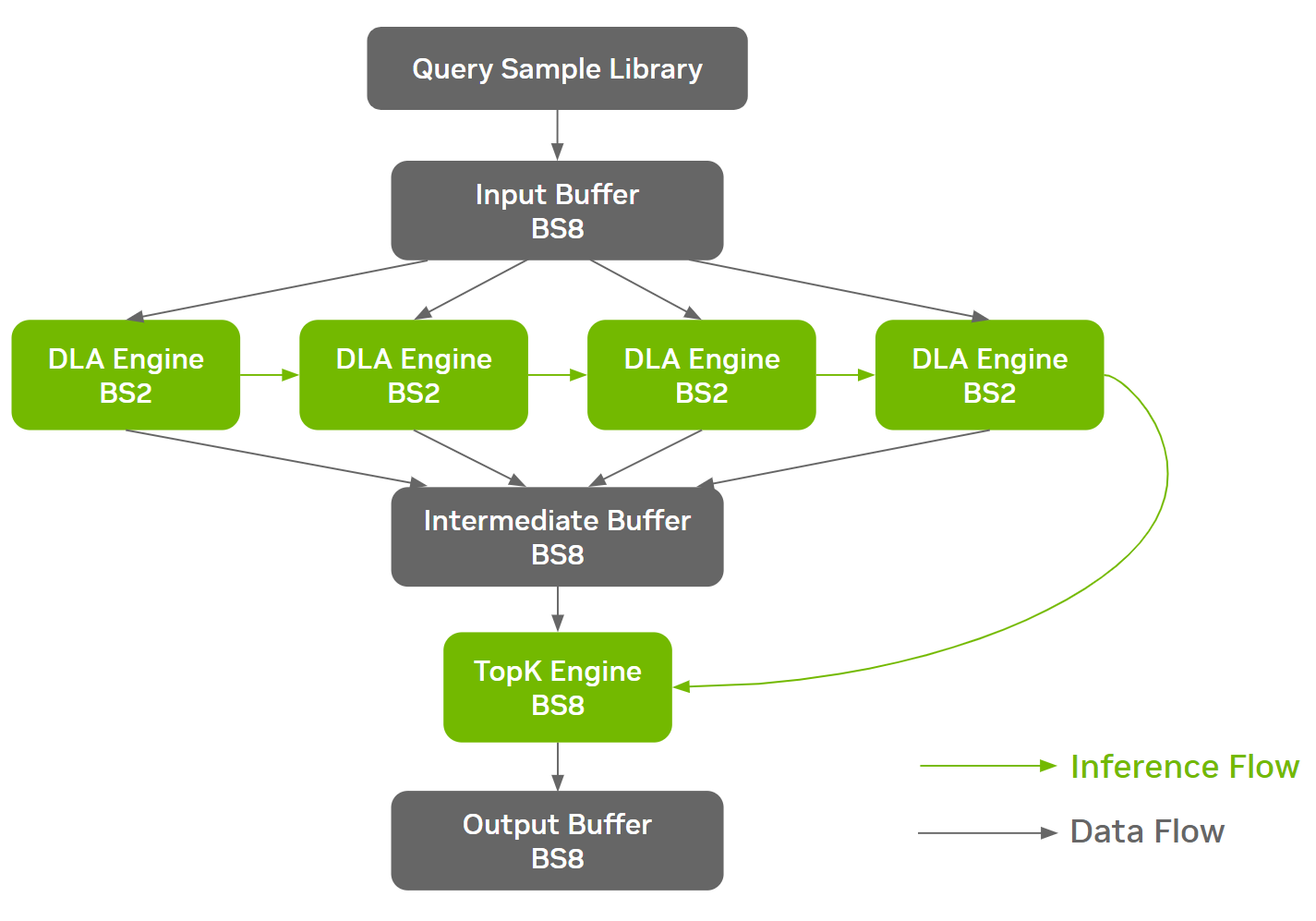
ResNet-50 等工作負載在網絡架構的不同階段具有不同的內存特性,為面向 DRAM 的優化創造了機會。在 NVIDIA MLPerf 推理 v3.0 ResNet-50 提交中采用的一種這樣的優化是批處理拆分
這使得不同的批量大小能夠在網絡的不同階段運行,從而在效率和 DRAM 帶寬利用率之間找到最佳折衷。 NVIDIA 提交采用在內存密集的部分之前將較大的批次拆分為較小的批次,依次對其進行推理,然后將其收集回較大的批次
在構建階段期間,ONNX GraphSurgeon自動識別定義的切割點,并將單個 ONNX 模型拆分為多個克隆的子圖。 TensorRT 為每個唯一的 ONNX 分區生成一個獨立的引擎。該線束負責協調引擎的執行和通信緩沖器的管理,從而不引入額外的設備到設備( D2D )拷貝。
通過批處理拆分方法, Orin 系統上的 ResNet-50 Offline 實現了約 3% 的端到端性能改進。下圖以線束中的數據流和推理流為例進行了說明。
NVIDIA AI 推理從云端到邊緣的領先地位
NVIDIA 平臺通過廣泛的全棧工程不斷提高人工智能推理性能。通過軟件,NVIDIA H100 Tensor Core GPU在一輪中,推理性能提高了 54% 。深度軟硬件協同優化使NVIDIA L4 Tensor Core GPU與 NVIDIA T4 GPU 相比,可提供高達 3 倍的性能
對于自動駕駛機器和機器人, NVIDIA Jetson AGX Orin 的性能和每瓦性能提高了 50% 以上。 NVIDIA Jetson Orin NX 的性能是前代產品的 3.2 倍
NVIDIA 平臺還繼續展示領先的多功能性,在所有 MLPerf 推理工作負載中提供卓越的性能。隨著人工智能不斷改變計算,在一組多樣化且不斷增長的工作負載和一組不斷增長的部署選項中提供出色性能的需求只會增加。 NVIDIA 平臺正在迅速發展,以滿足人工智能應用程序的當前需求,同時準備加速未來的需求
?






