
NVIDIA NeMo 是一種端到端平臺,用于開發和部署多模態 生成式 AI 模型。它可以隨時隨地進行大規模模型部署。
NeMo 團隊最近發布了 Canary,這是一款多語言模型,可轉錄英語、西班牙語、德語和法語的語音,并添加標點符號和大寫。Canary 還提供英語和其他三種受支持語言之間的雙向翻譯。
本文詳細介紹了 Canary 模型及其使用方法。
Canary 概述?
Canary 模型在 HuggingFace 開放 ASR 排行榜 中平均詞錯誤率 (WER) 為 6.67%,其性能遠遠優于所有其他開源模型。
Canary 結合使用公共和內部數據進行訓練。它使用 85000 小時的轉錄語音來學習語音識別。為了教授 Canary 翻譯,我們使用 NVIDIA NeMo 文本翻譯模型生成所有支持語言的原始轉錄的翻譯。
盡管數據量比類似規模的模型少一個數量級,但 Canary 的性能優于 Whisper-large-v3 和 SeamlessM4T-Medium-v1 模型在 MCV 16.1 英語、西班牙語、法語和德語測試集上的 WER 分別為 5.77 (圖 1)。
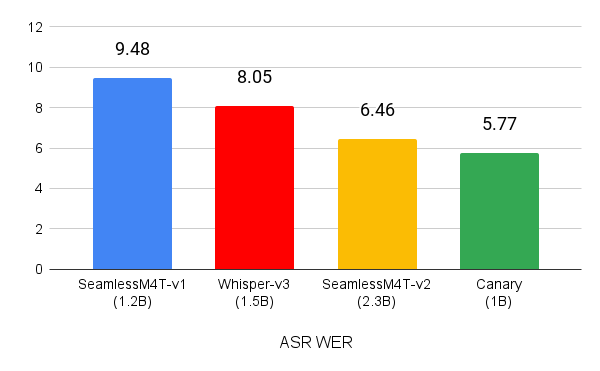
(越低越好)
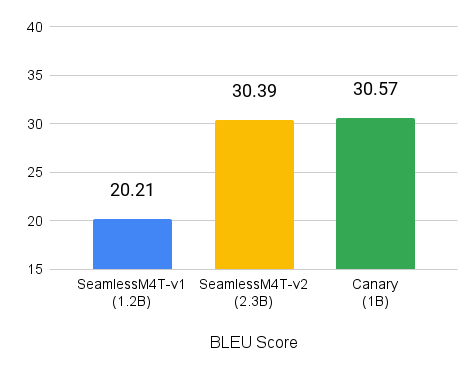
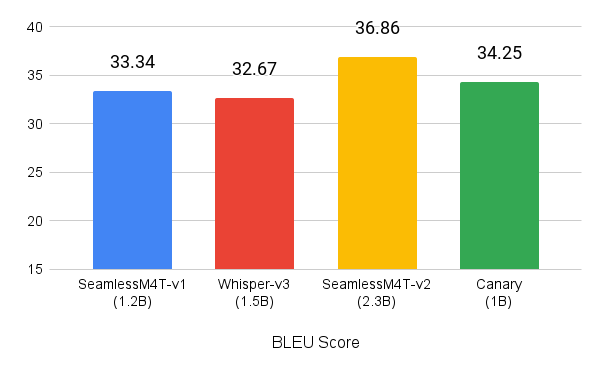
您可以嘗試 canary-1b 模型的 Gradio 演示。有關如何在本地訪問 Canary 并進行構建的更多信息,請參閱 NVIDIA/NeMo GitHub 庫。
Canary 架構?
Canary 是一種基于 NVIDIA 創新技術構建的編碼器 – 解碼器模型。
編碼器 Fast-Conformer 是一種高效的 Conformer 架構,經過優化,可節省大約 3 倍的計算和大約 4 倍的內存。編碼器以對數 – 梅爾頻譜圖特征的形式處理音頻,Transformer 解碼器以自動回歸的方式生成輸出文本標記。系統會提示解碼器使用特殊標記來控制 Canary 執行轉錄還是翻譯。
Canary 還集成了 連接的分詞器,以提供對輸出令牌空間的顯式控制。
模型權重以研究友好型非營利 CC BY-NC 4.0 許可證分發,而用于訓練此模型的代碼可通過 Apache 2.0 許可證獲得。許可證信息可參考 NeMo。
如何使用 Canary 轉錄?
要使用 Canary,請將 NeMo 安裝為 pip 包。在安裝 NeMo 之前,請先安裝 Cython 和 PyTorch (2.0 及更高版本)。
pip install nemo_toolkit['asr'] |
安裝 NeMo 后,使用 Canary 轉錄或翻譯音頻文件:
# Load Canary modelfrom nemo.collections.asr.models import EncDecMultiTaskModelcanary_model = EncDecMultiTaskModel.from_pretrained('nvidia/canary-1b')??# Transcribetranscript = canary_model.transcribe(audio=["path_to_audio_file.wav"])# By default, Canary assumes that input audio is in English and transcribes it.?
# To transcribe in a different language, such as Spanishtranscript = canary_model.transcribe(?????audio=["path_to_spanish_audio_file.wav"],?????batch_size=1,?????task='asr',?????source_lang='es',? # es: Spanish, fr: French, de: German?????target_lang='es',? # should be same as "source_lang" for 'asr'?????pnc=True )?
# To translate using Canary. For example, from English audio to French texttranscript = canary_model.transcribe(?????audio=["path_to_english_audio_file.wav"],?????batch_size=1,?????task='ast',?????source_lang='en',?????target_lang='fr',? ?????pnc=True ) |
結束語?
我們所開發的 Canary 多語言模型已成為新標準,在英語、西班牙語、德語和法語的語音識別和翻譯方面表現出色,準確度極高。
有關 Canary 架構的更多信息,請參閱以下資源:
要深入了解 canary-1b,您可以:
– 探索 Gradio 演示。
– 通過 NVIDIA/NeMo GitHub 庫。
Parakeet-CTC 已經發布,其他模型將在 NVIDIA Riva 推出時發布。
通過 NVIDIA API 目錄,您可以在本地使用 NVIDIA NIM。更多信息請參閱 NVIDIA LaunchPad,它提供了專用托管基礎設施上的硬件和軟件堆棧。
致謝:
感謝所有為本文做出貢獻的模型作者:Krishna Puvvada、Piotr Zelasko、He Huang、(Steve) Oleksii Hrinchuk、Nithin Koluguri、Somshubra Majumdar、Elena Rastorgueva、Kunal Dhawan、Zhehuai Chen、Vitaly Lavrukhin、Jagadeesh Balam、Boris Ginsburg
?





