
在過去十年中,深度學習技術在計算機視覺 (CV) 任務中的應用大幅增加。卷積神經網絡 (CNN) 一直是這場革命的基石,展示了卓越的性能,并在視覺感知方面實現了顯著進步。
通過采用本地化濾鏡和分層架構,CNN 已證明擅長捕捉空間層次結構、檢測模式,以及從圖像中提取信息豐富的特征。例如,在用于圖像識別的深度殘差學習中,卷積層表現出平移等方差,使其能夠泛化為平移和空間轉換。然而,盡管 CNN 取得了成功,但其在捕獲遠程依賴項和全局上下文理解方面仍存在局限性,這在需要精細理解的復雜場景或任務中變得越來越重要。
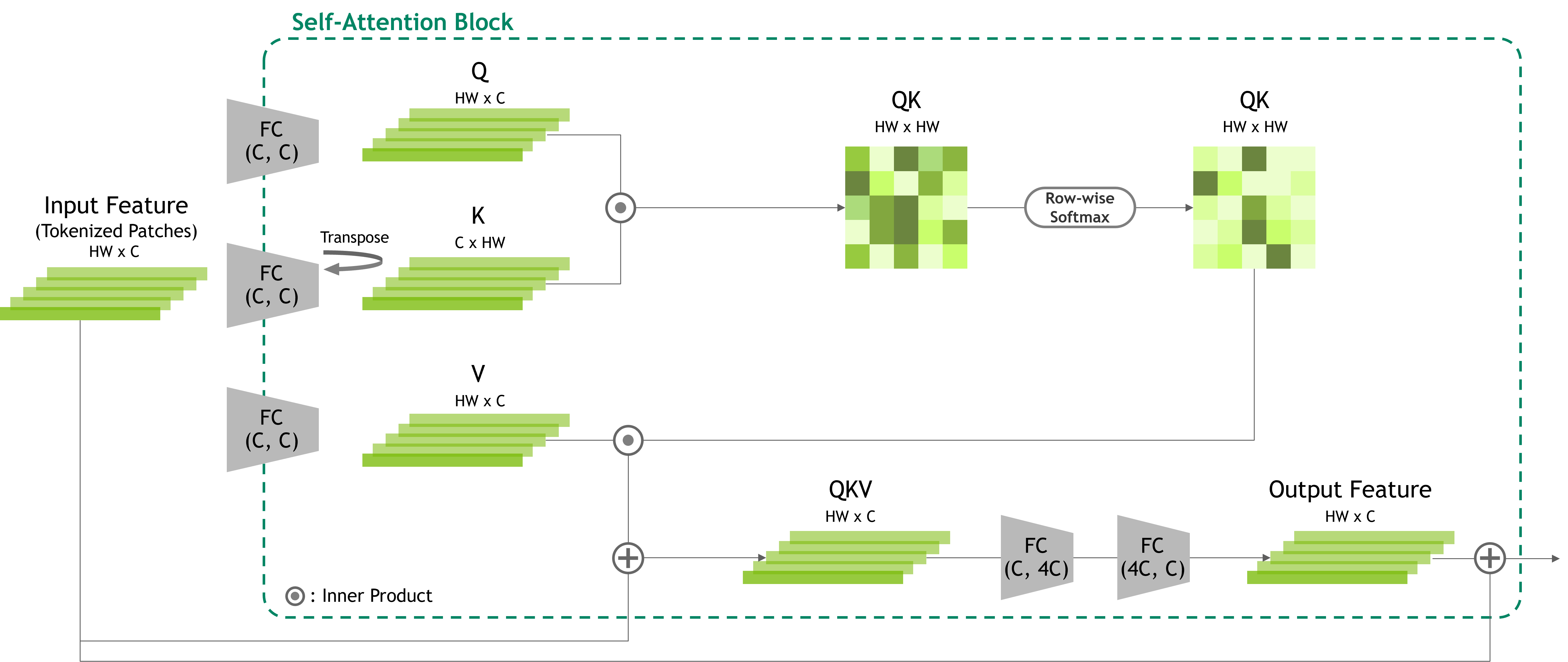
相比之下,Transformer 架構在計算機視覺領域中正變得越來越有吸引力,這得益于其在自然語言處理 (NLP) 領域的成功應用。正如論文Attention Is All You Need中所展示的,Transformer 通過避免局部卷積,提供了一種自注意力機制,能夠支持視覺特征之間的全局關系。這種注意力機制使得 Transformer 能夠捕獲圖像元素之間的遠程交互,從而促進了對視覺場景的更全面理解,進而提高了模型的準確性。圖 1 展示了一個視覺應用中的自注意力機制示例。對于更多詳細信息,請參閱論文A Visual Representation of 16+16 Words: Transformers for Large-Scale Image Recognition 和 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows。
然而,自注意力在有效捕獲圖像中的本地上下文信息方面遇到了挑戰,這突出了更廣泛的全局感知領域的重要性。此外,與自注意力相關的計算復雜性的特征是視覺特征元素之間的二次交互,這對在計算機視覺中處理大型圖像構成了重大挑戰。
處于創新前沿的汽車行業正日益認識到需要廣泛采用 Transformer-like 網絡。然而,集成這些網絡帶來了獨特的挑戰。具體來說,在NVIDIA TensorRT特定操作系統的框架NVIDIA DRIVE產品,與標準用例相比,支持有限的專用功能。
這些專用 API 仍然包括高度優化的卷積運算等,反映了該行業對優化卷積網絡的長期承諾。我們的目標是戰略性地利用這些優化的卷積運算來推動 Transformer 網絡的更高效和更有效的實施。我們的目標是使汽車行業能夠滿足現代應用程序的動態需求,同時在現有軟件框架和硬件平臺的限制內協調工作。
在認識到 self-attention 的價值的同時,還必須更加重視卷積的影響,尤其是在 CV 任務中。這一點正確,原因如下:
- 如前所述,圖像和文本之間的固有特性差異凸顯了將自注意力直接應用于 CV 任務的挑戰,需要混合方法或結合自注意力層和卷積層優勢的替代架構。
- 在自動駕駛汽車 (AV) 應用中,高分辨率圖像通常用于實時應用。硬件平臺上的自注意力計算優化已落后于自動駕駛行業和芯片制造商新 Transformer 的迅速出現,無法滿足用戶需求。當前基于 Transformer 的模型的實現未充分利用 GPU 的計算能力。
- 在自動駕駛中的許多生產情況下,在深度學習運行時庫的受限模式下執行的推理可能尚未完全支持先進的 Transformer 網絡。例如,Transformer 中的當前操作在 TensorRT 受限模式下并未完全涵蓋。
本文介紹了我們最近在使用全卷積網絡在 Transformer 模型中仿真注意力機制方面的工作。我們的方法將針對當前 GPU 硬件平臺優化的傳統卷積核的優勢與自注意力模塊相結合,從而實現了優于當代 Transformer 類模型的性能。我們的工作解決了存在計算機視覺問題的各行各業中用戶對 Transformer 可用性日益增長的需求。我們的方法不僅在 TensorRT 上運行時能夠提供更快的延遲性能和可比較的準確性,而且還完全兼容 TensorRT 受限模式。
融合卷積和自注意力
最近的研究表明,人們對融合 CNN 和 Transformer 的優勢的興趣與日俱增。通過將局部特征信息的卷積運算與用于全局特征關系的自注意力模塊相結合,研究人員旨在增強這兩種架構的功能。
Swin Transformer 是一個值得注意的例子。最近的 Vision-transformer? 引入了偏移窗口的概念,使 Transformer 能夠有效地學習局部特征。通過在較小區域內整合局部自注意力,Swin 捕獲局部關系和依賴關系,從而提高需要細粒度信息的任務的性能。然而,隨著輸入大小的增長,自注意力的計算復雜性二次增加,這可能會迅速造成延遲負擔,從而帶來挑戰。
為解決這一問題,研究人員探索了卷積運算和自注意力的合并。基于卷積的方法可以模仿 Transformer 訓練配置,或者在網絡的各個部分有選擇地使用卷積和自注意力。
例如,卷積視覺 Transformer (CvT)直觀地將卷積特征整合到自注意力模塊中。Conv-Next 另一方面,與傳統 CNN 的視覺 Transformer 類似。盡管如此,這種方法無法明確解決傳統卷積網絡模型中常見的有限接受場問題。與自注意力不同,卷積運算擁有固定的接受場大小和一組共享的參數。這種特性使卷積能夠以局部聚焦和參數高效的方式處理輸入數據。
卷積自注意力
我們展示了 Convolutional Self-Attention (CSA),該模型以用于視覺任務的卷積運算完全取代了傳統的注意力機制,從而能夠對本地和全局特征關系進行建模。通過僅依賴卷積,我們的整體模型在高度優化的 GPU 和深度學習加速器上實現了顯著的效率。與現代 Transformer 網絡相比,實驗結果令人信服地證明了其具有競爭力的準確性,同時顯示出更高的硬件利用率和顯著降低的部署延遲。
整個建議的模型包括重復使用向下采樣卷積層和我們建議的 CSA 塊,以及其饋向轉發流,如圖 2 所示。每個 CSA 塊都使用卷積運算模擬 Transformer 塊。

圖 3 顯示了 CSA 模塊的結構和流程。CSA 模塊的實現可能有所不同,但旨在模擬自注意力的關系編碼過程。為了實現關系編碼,我們沿通道軸旋轉張量,將通道特征轉換為空間格式(高度和寬度)。
此旋轉特征張量在旋轉前按元素順序與原始張量相乘,然后是卷積。這復制了第一個自注意力內積,但概念有所不同,因為我們的方法允許通過元素順序乘法和卷積進行一對多關系嵌入。然后,生成的關系特征張量被歸一化、激活,并與輸入張量的另一個視覺特征相乘,值(V)。
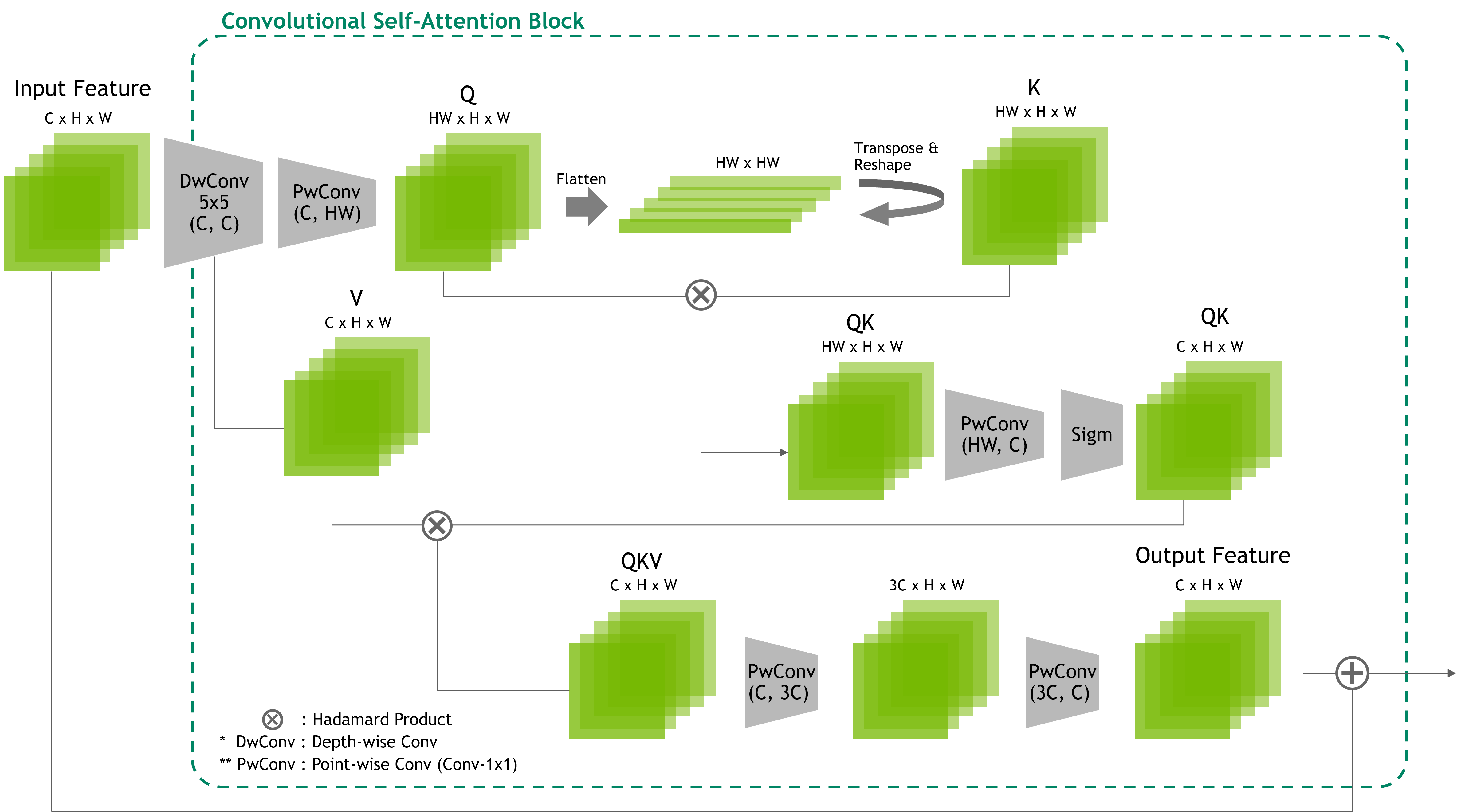
我們的方法通過策略性地重新排列特征張量并利用本地卷積核窗口來實現全局感知場。這種顯式關系編碼可將每個特征像素投影到所有其他特征像素,從而實現全面的像素間交互。這是因為我們方法中張量的結構重新排列使卷積窗口能夠捕獲視覺特征之間的全局關系,利用卷積運算的優勢進行一對一多視覺特征關系推理。
相比之下,CSA 模塊通過內部產品運算對所有特征像素之間的關系進行編碼,這可能會給硬件帶來巨大的計算負擔。通過實現一對一關系編碼,我們的方法可以減少計算負載,同時保留在整個特征圖中捕獲遠程依賴項和結構信息的能力。
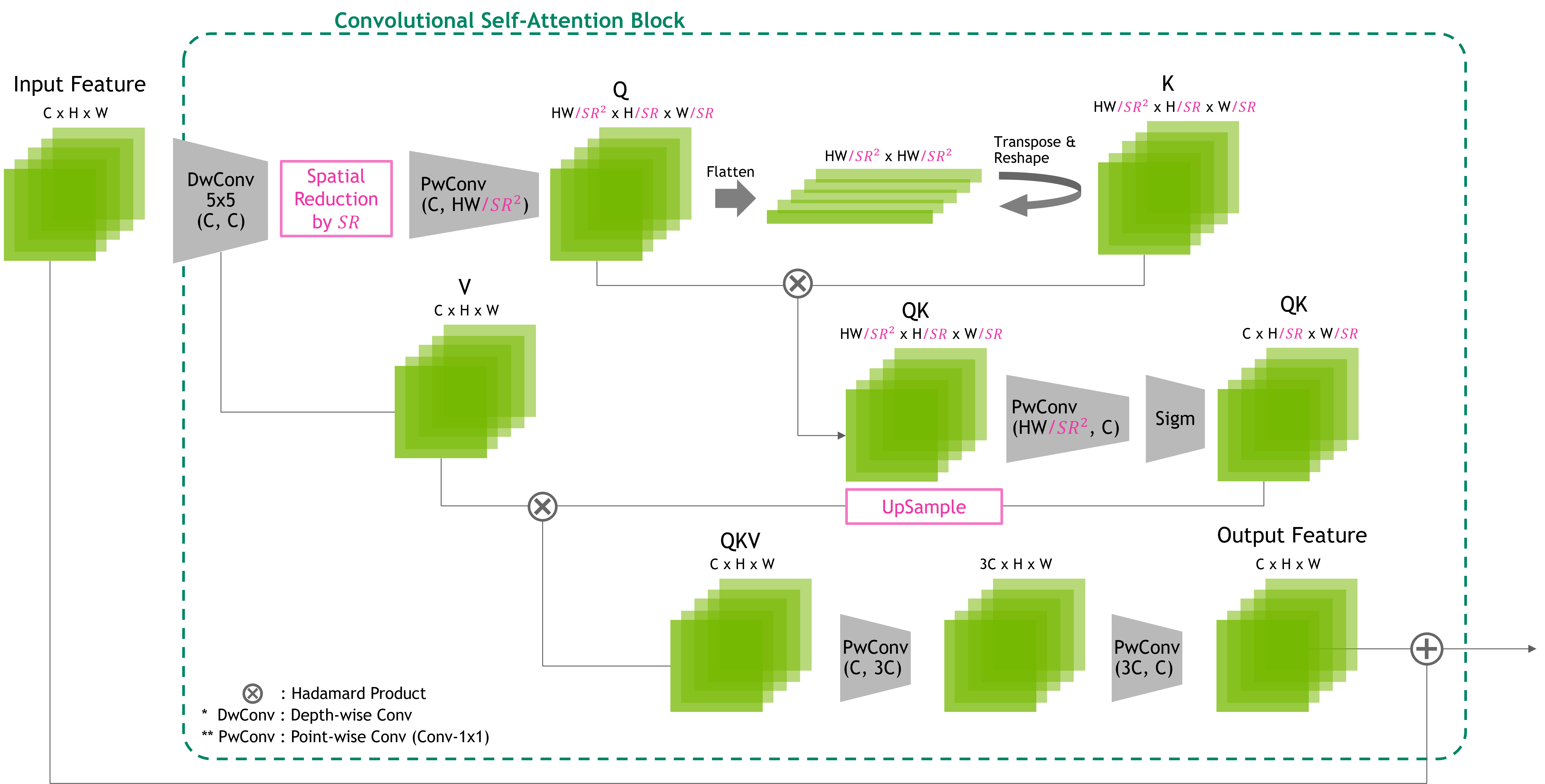
為了管理因輸入大小增加而產生的二次計算增量,我們的設計可以加入空間歸約層以減小張量大小,如圖 4 所示。這不僅有助于減少計算開銷,而且還使網絡能夠專注于視覺特征之間的區域關系,而視覺特征帶有更多語義,而不是像素級關系。
準確性和延遲方面的性能
將 CSA 模塊與使用 ImageNet-1K 數據集的相關當代 CV 分類模型進行比較,在準確性和使用 TensorRT-8.6.11。4 測量的驗證數據和延遲方面進行比較。我們的目標是在受限模式下應用 CSA 的自動駕駛汽車,因此在 NVIDIA DRIVE Orin 平臺上對這些模型進行比較。 NVIDIA DRIVE Orin 是一種高性能、高能效的片上系統 (SoC),是用于自動駕駛汽車的 NVIDIA DRIVE 平臺的一部分。
基準測試條目
- Swin Transformer 網絡是一種創新的深度學習架構,將最初由視覺 Transformer (ViT) 等模型推廣的自注意力機制與分層和可并行設計相結合。
- ConvNext 模型通過逐步轉換標準 ResNet 來開發,使其類似于視覺 Transformer,在特定任務中與 Swin Transformer 競爭有利,同時保持傳統卷積網絡的簡單性和效率。
- 卷積視覺 Transformer(CvT)通過在ViT中引入卷積操作,實現了性能和效率的顯著提升。在ImageNet-1k數據集上的表現非常具有競爭力,同時模型參數更少,計算量也更低。
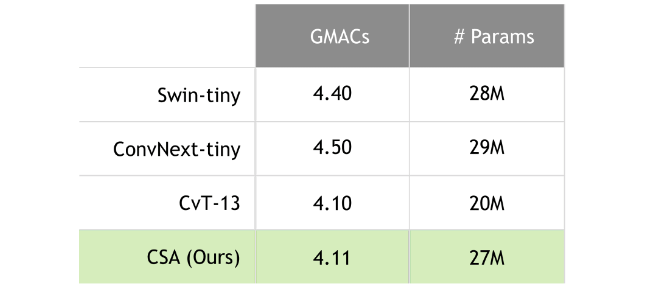
基準測試條目的依據在于其與 CSA 的相關性和當代重要性。在我們的實驗中,我們特別將 CSA 與模型大小相似的 Swin-tiny、ConvNext-tiny 和 CvT-13 基準進行了比較,如表 1 所示。
我們在 TensorRT 中使用兩種精度模式(FP16 和混合精度模式,即啟用 FP32、FP16 和 INT8)來展示結果。這種方法使我們能夠平衡評估模型的性能。使用訓練后量化 (PTQ) 實現了所有方法的模型量化,并在校準過程中使用了 500 張圖像。
我們使用 ImageNet 數據集上的 Top-1 精度來測量準確性,并在毫秒內報告不同批量大小(1、4、8 和 16)的推理延遲。這可確保我們以公平無偏的方式進行比較。我們可以進一步優化 CSA 的 TensorRT 推理,在準確性和延遲之間取得平衡,從而在可接受的準確性限制范圍內利用延遲。
在追求優化精度模式以提高延遲并可能犧牲準確性的過程中,量化策略成為了一個令人信服的解決方案。TensorRT 提供了各種量化方法,包括百分位數、平均平方誤差 (MSE) 和量化,所有這些方法都證明了在減輕精度損失方面的有效性。我們的研究以跨一系列基準方法的混合精度推理為中心,在該研究中,我們選擇了量化方法。這種方法以信息論為基礎,通過分配代碼來最大限度地減少平均代碼詞長,從而最大限度地降低準確性,但值得注意的是 CvT 基準測試除外。
盡管包括 CSA 在內的所有基準測試在降低精度后仍保持著難以區分的準確性水平,但盡管精度降低,ConvNext 在一定程度上優于其他基準測試。相反,CSA 的準確性下降幅度最小。
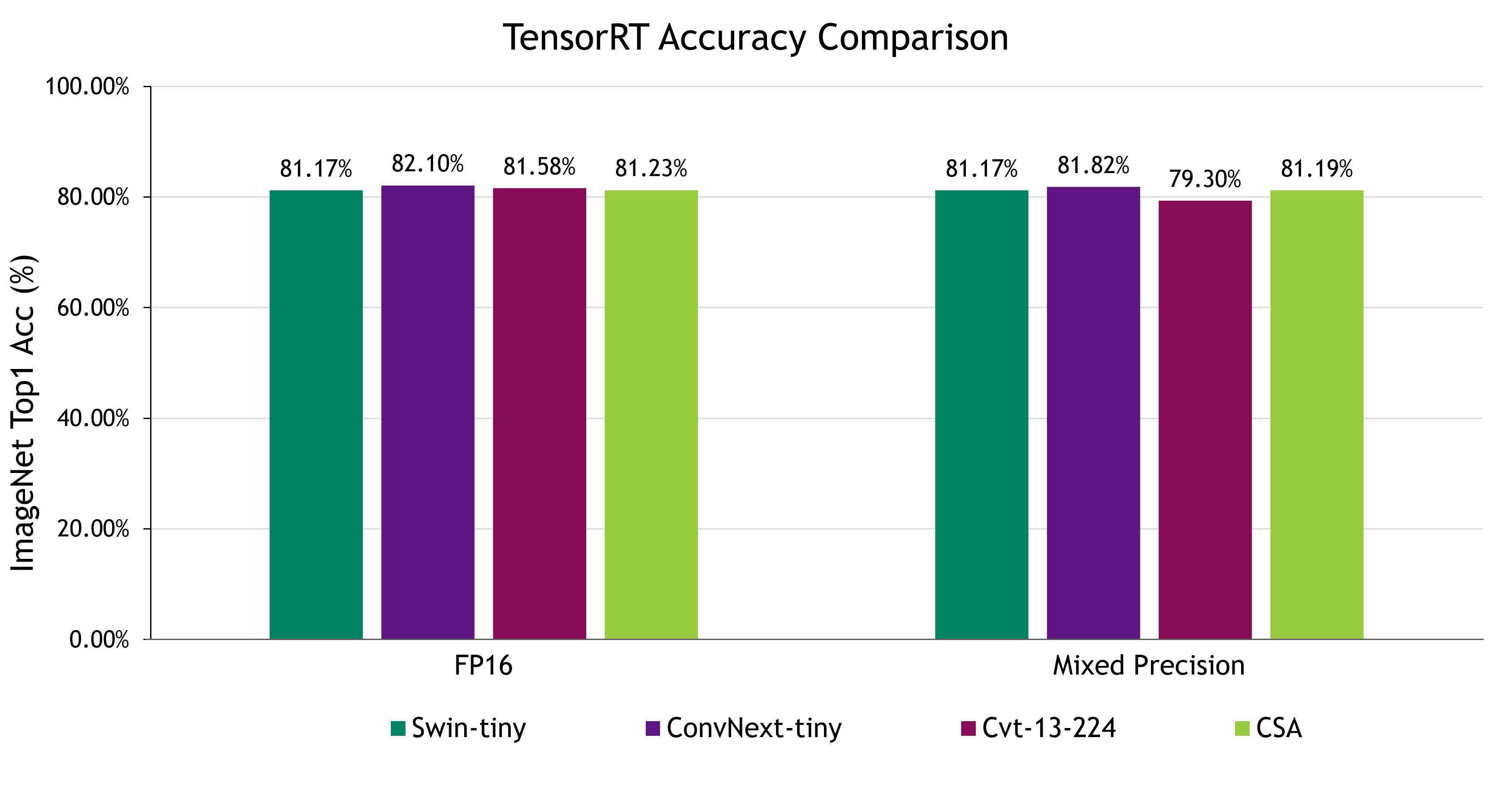
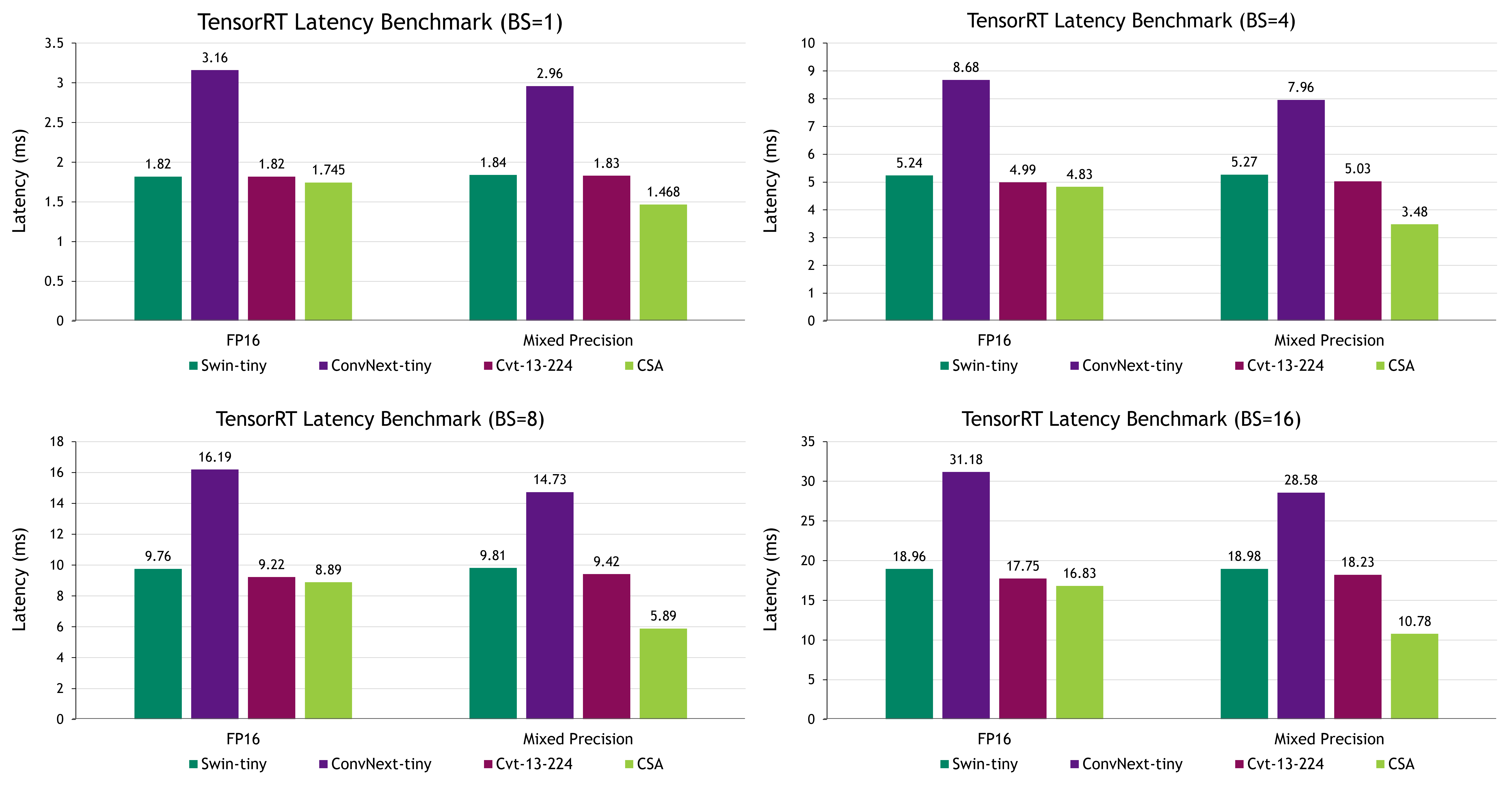
ConvNext 在 FP16 和混合精度模式下都以其準確性而出名,但同時兼具相對較慢的延遲。在這種情況下,CSA 成為一個極具競爭力的選擇,提供了值得稱道的準確性,同時實現了最快的延遲。
與 ConvNext-tiny 相比,在批量大小為 1 的情況下,CSA 的延遲顯著降低了 49%,同時保持了較高的準確性性能。這突出了 CSA 的強大功能,并將其定位為在這種情況下的有力選擇。
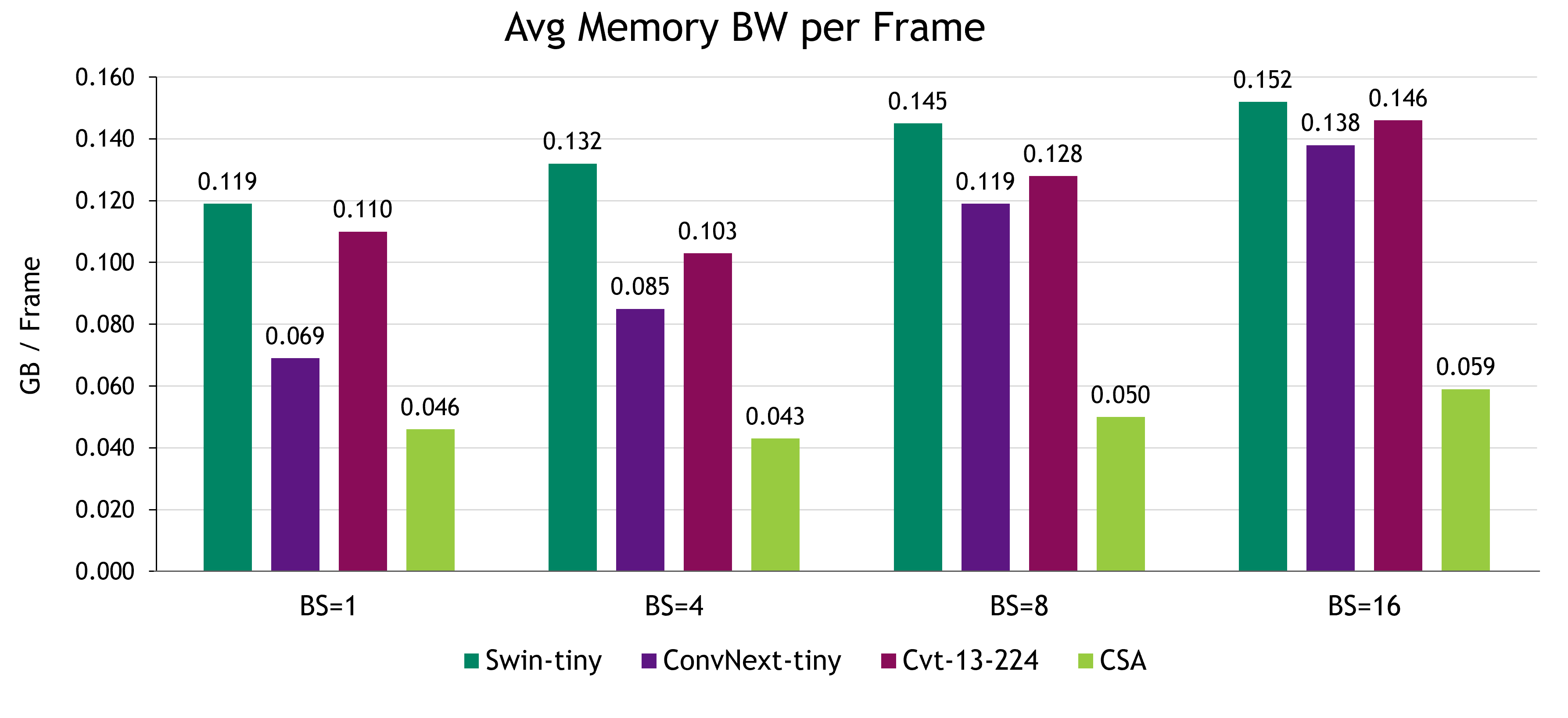
CSA 在推理期間的性能優于高效內存流量基準測試,因此每幀的平均顯存帶寬最少。應該注意的是,即使批量大小增加,CSA 的內存流量也是持久的,而基準測試中的其他方法也在逐漸增加。
得益于 CSA 的策略設計,我們的模型可以在 TensorRT 中利用高效的卷積核實現,從而實現高效計算,在準確度和延遲之間實現協調平衡,同時與 TensorRT 受限模式完全兼容。其他精度更高或延遲更低的方法都不兼容。在實踐中,這使得目前難以在需要 TensorRT 受限模型的生產環境中部署這些模型。
結束語
與嘗試從 Transformer 模型中提取注意力模塊的其他卷積模型不同,卷積自注意力 (CSA) 僅結合簡單的張量形狀操作,僅使用卷積明確查找特征 1 對多之間的關系。我們的方法與相關方法之間的區別如下所示:
- 通過從戰略角度重新排列特征張量,顯式關系編碼可確保每個特征像素都投影到所有其他特征像素,從而在利用本地卷積核窗口的同時實現全局接受場。
- 傳統的自注意力模塊對所有輸入特征之間的關系進行編碼,會增加相對于輸入大小的計算成本,相比之下,我們的方法在每個階段都以分層方式通過卷積運算簡潔地實現了多對多關系編碼,同時縮小了輸入大小,從而降低了硬件的計算負載。
- 這些優勢可為規模相當的模型提供更快的推理速度,并可美或超過其他方法的性能。
尤為重要的是,CSA 在 TensorRT 受限模型中運行時不會出現任何故障和麻煩,因此適合用于安全關鍵型應用的自動駕駛汽車生產。我們希望 CSA 能夠為使用 NVIDIA DRIVE 平臺及更高版本的客戶提供參考模型設計。有關更多信息,請訪問 NVIDIA 開發者 AV 論壇 和 TensorRT 論壇。
?





