NVIDIA cuTENSOR 是一個 CUDA 數學庫,提供經過優化的張量運算。張量是一種密集的多維數組或數組片段。cuTENSOR 2.0 的發布代表著功能和性能方面的重大更新,這一版本重構了其 API,使其更富有表現力,包括在 NVIDIA Ampere 和 NVIDIA Hopper GPU 架構上實現的出色性能。
雖然張量運算看起來很陌生,但它們描述了許多自然發生的算法。尤其是,這些運算在機器學習和量子化學中十分常見。
如果您已經使用 NVIDIA cuBLAS 或 BLAS,cuTENSOR 提供的三個例程可能會讓您感到眼前一亮:
- 元素式 API 對應于 1 級 BLAS (向量向量運算)
- 歸約 API 對應于二級 BLAS (矩陣向量運算)
- 收縮 API 對應于 3 級 BLAS (矩陣-矩陣運算)
主要區別在于,cuTENSOR 可將這些運算擴展到多維度 .cuTENSOR 使您無需擔心這些運算的性能優化,而是可以依靠現成的加速例程。
cuTENSOR 的優勢和進步不僅可以通過您的 CUDA 代碼使用,而且還可以通過其他許多工具使用,這些工具目前均已提供對 cuTENSOR 的支持。
- Fortran 開發者可以從 NVIDIA HPC SDK 中提供的 cuTENSOR Fortran API 綁定中受益,NVFORTRAN.
- Python 開發者可以通過CuPy訪問 cuTENSOR 中提供的 NVIDIA GPU 加速的張量收縮、歸約和元素計算。
- cuTENSOR 也可用于 Julia 開發者使用的 Julia Lang。
借助 cuTENSOR 加速的程序數量不斷增加。我們還提供使用 TensorFlow 和 PyTorch 在 C++和 Python 中入門的示例代碼。
在本文中,我們討論了 cuTENSOR 支持的各種操作,以及如何作為 CUDA 編程人員利用這些操作。我們還分享了性能注意事項和其他有用的提示和技巧。最后,我們分享了我們使用的示例代碼,這些代碼也可以在 /NVIDIA/CUDALibrarySamples GitHub 資源庫中找到。
cuTENSOR 2.0
cuTENSOR 2.0 在性能、特征支持和易用性方面實現了重大進步,我們重構了元素運算、歸約和張量收縮的 API,使其保持一致,以便所有運算遵循相同的多階 API 設計 (圖 1)。
cuTENSOR 首次引入對張量收縮的即時編譯支持,使您能夠編譯針對特定張量收縮定制的專用核函數。這一功能對于高維張量收縮尤為有價值,因為它們經常在量子電路模擬中出現。
Tensor permutations 現在還支持填充,使得輸出張量可以按照任意維度進行填充,以滿足任何對齊要求或避免后續核函數的預測。
從 cuTENSOR 2.0 開始,計劃緩存是默認啟用的。換句話說,它的默認設置從 opt-in 更改為 opt-out,這有助于以用戶友好的方式減少規劃開銷。
最后,我們在元素運算、歸約和張量歸約之間的 API 設計保持一致,即所有運算都遵循張量歸約的相同多階 API 設計,這樣您就可以重復使用元素運算和歸約運算的計劃。
本文僅介紹最新的 2.0 API。有關如何從 1.x 過渡到 2.0,請參閱 從 cuTENSOR 1.x 過渡到 cuTENSOR 2.x。
API 介紹
本節介紹了 cuTENSOR API 背后的關鍵概念,以及如何在代碼中調用它們。有關更多信息和全面示例,請參閱 /NVIDIA/CUDALibrarySamples GitHub 資源庫和 入門指南 cuTENSOR 文檔。
第一步是初始化 cuTENSOR 庫句柄 (每個線程一個),以便庫做好準備并僅執行一次昂貴的設置工作。
cutensorStatus_t status;cutensorHandle_t handle;status = cutensorCreate(handle);// [...] check status |
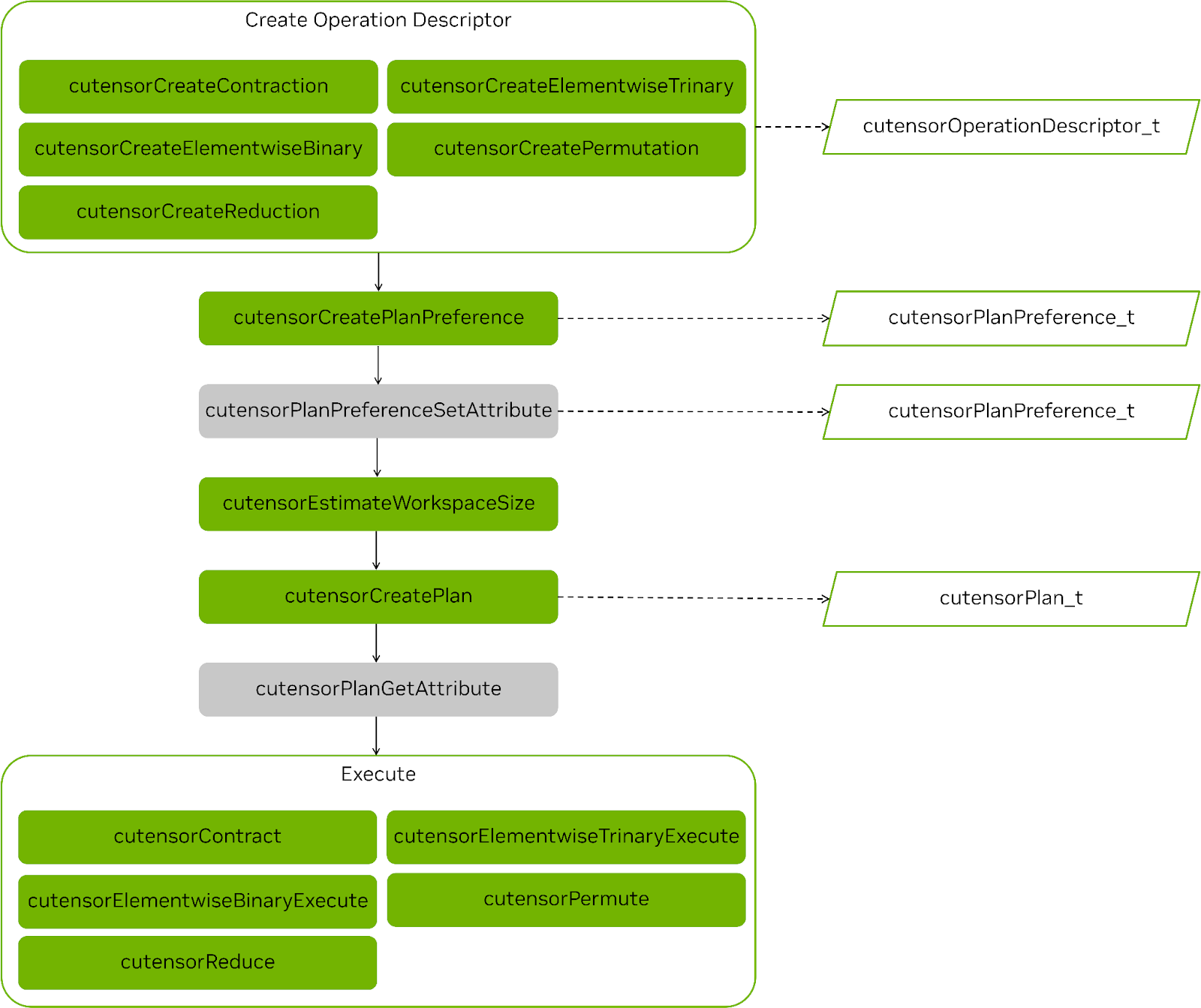
創建把握后,它可以重復用于任何后續 API 調用。從 cuTENSOR 2.0 開始,所有操作都遵循相同的工作流程:
- 創建操作描述符:
cutensorTensorDescriptor_t來捕捉張量的物理布局。cutensorOperationDescriptor_t來編碼操作本身。cutensorPlanPreference_t限制可用核函數的空間。
- (可選) 設置計劃首選項的屬性。
- 估算工作空間需求。
- 創作
cutensorPlan_t選擇用于執行操作的內核。- 調用 cuTENSOR 性能模型。
- 若啟用 JIT,則可能會導致編譯步驟。
- (可選) 查詢計劃實際使用的工作空間。
- 執行實際操作。
圖 1 顯示了任何操作的步驟,并突出顯示了常見步驟。
Tensor 描述符是 cuTENSOR API 的重要組成部分。它可以編碼以下內容:
- 密集張量的物理布局:
- 張量元件的數據類型
- 維度 (秩) 數
- 每個維度的范圍
- 相同維度的兩個相鄰元件之間的步長 (線性內存)
- 相應數據指針的對齊要求 (通常為 256 字節,匹配 CUDA 默認對齊)
cudaMalloc).
在本文中,我們使用維度和模式互換使用。
這可能很抽象,因此請考慮圖 2.這是一個三維張量,其元素按照它們在內存中的排列順序編號。這個張量在每個維度中具有三個元素的范圍。其第一個維度的步長為 1,第二個維度的步長為 3,最后一個維度的步長為 9.這對應于維度中兩個元素之間的位置差異。
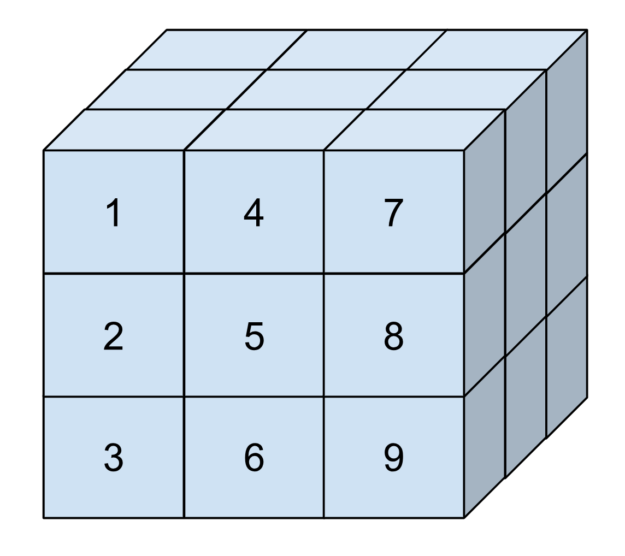
步長允許您表示子張量(由更大的張量切片構成的張量)。在 cuTENSOR 中,步長始終以元件為單位提供,就像極限一樣。
例如,如要表示圖中的張量,您可以調用以下代碼:
int64_t extents[] = {3, 3, 3};int64_t strides[] = {1, 3, 9};uint32_t alignment = 256; // bytes (default of cudaMalloc)cutensorTensorDescriptor_t tensor_desc;status = cutensorCreateTensorDescriptor(handle, tensor_desc, 3 /*num_modes*/, extents, strides, CUTENSOR_R_32F, alignment); |
您還可以傳遞 NULL 指針,而不是步長。在這種情況下,cuTENSOR 會自動從極限范圍中推理步長,假設是通用列式內存布局。即,步長從左到右增加,最左側模式的步長為 1.任何其他布局,包括通用行式布局,均可通過提供適當的步長實現。
步長還可用于訪問子張量。例如,以下代碼示例用于編碼前一張量的二維非連續水平面:
int64_t extents_slice[] = {3, 3};int64_t strides_slice[] = {3, 9};status = cutensorCreateTensorDescriptor(handle, tensor_desc, 2 /*num_modes*/, extents_slice, strides, CUTENSOR_R_32F, alignment); |
Einsum 符號
cuTENSOR 的元素化、歸約和收縮 API 遵循 Einsum 符號,每個維度都有一個獨特的標簽。通過重排或省略模式,可以以用戶友好的方式表示張量運算,如轉置和收縮。未在輸出中出現的模式會被收縮。有關更多信息,請參閱 PyTorch 文檔中的 torch.einsum 。
例如,對于存儲在 GPU 上的四維張量,?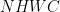

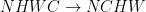
前面的字母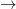
同樣,矩陣-矩陣乘法可以表示為?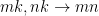

收縮
張量收縮可以看作是矩陣-矩陣乘法的更高維度版本。唯一的區別是操作數是多維矩陣,而不僅僅是二維矩陣。有關詳細方程式,請參閱 cuTENSOR 函數。
在本文中,我們使用張量收縮示例展示了 cuTENSOR API 的使用方法 操作。但其他 API 的行為類似。從開始到結束,執行此操作需要執行以下步驟:
- 創建操作描述符。
- 創建計劃首選項。
- 查詢工作空間大小。
- 制定計劃。
- (可選) 查詢精確的工作空間大小使用情況。
- 執行收縮。
創建操作描述符
如前所述,您首先要創建張量描述符。完成此步驟后,繼續對實際收縮執行編碼:
cutensorComputeDescriptor_t descCompute = CUTENSOR_COMPUTE_DESC_32F;cutensorOperationDescriptor_t desc;cutensorCreateContraction(handle, &desc, descA, {‘a’,’b’,’k’}, /* unary op A*/ CUTENSOR_OP_IDENTITY, descB, {‘m’,’k’,’n’}, /* unary op B*/ CUTENSOR_OP_IDENTITY, descC, {‘m’,’a’,’n’,’b’}, /* unary op C*/ CUTENSOR_OP_IDENTITY, descC, {‘m’,’a’,’n’,’b’}, descCompute) |
代碼示例會對兩個三維輸入進行張量收縮,以創建四維輸出;。API 與相應的 einsum 符號類似:
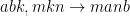
性能準則
本節假設是一種通用的列式數據布局,其中最左側模式的步長最小。
雖然 cuTENSOR 可以使用任何順序提供的模式,但順序可能會影響性能。我們通常推薦以下性能準則:
- 嘗試在所有張量中以類似的方式排列模式 (即增加步長)。例如,?
而不是
.。
- 盡量將批處理模式保留為最慢變化模式 (即最大步長)。例如,
而不是
。
- 盡可能保持最快變化模式的范圍 (s試用一次模式) 盡可能大。
創建計劃首選項
下一步是通過創建cutensorPlanPreferrence_t例如,您可以使用 plan_preference 修復cutensorAlgo_t指定具體核函數,如果您希望實現自動調整或啟用即時編譯,
cutensorAlgo_t algo = CUTENSOR_ALGO_DEFAULT;cutensorJitMode_t jitMode = CUTENSOR_JIT_MODE_NONE;cutensorPlanPreference_t planPref;cutensorCreatePlanPreference(handle, &planPref, algo, jitMode); |
使用此計劃首選項創建的任何計劃都依賴于 cuTENSOR 性能模型來選擇最適合的預編譯內核:CUTENSOR_ALGO_DEFAULT.在本例中,您已禁用 JIT 編譯。
正如之前所述,JIT 編譯可以在運行時為特定操作生成專用內核,從而顯著提高性能。要利用 cuTENSOR JIT 功能,請設置 jitMode = CUTENSOR_JIT_MODE_DEFAULT。有關更多信息,請參閱JIT 編譯和性能詳細介紹。
查詢工作空間大小
現在,您已初始化收縮描述符并創建計劃優先級,您可以使用cutensorEstimateWorkspaceSize.
借助 API,您可以通過cutensorWorksizePreference_t. CUTENSOR_WORKSPACE_DEFAULT是一個很好的默認值,因為它旨在實現高性能,同時減少工作空間要求。如果內存占用空間不是問題,則CUTENSOR_WORKSPACE_MAX可能是更好的選擇。
uint64_t workspaceSizeEstimate = 0;cutensorWorksizePreference_t workspacePref = CUTENSOR_WORKSPACE_DEFAULT;cutensorEstimateWorkspaceSize(handle, desc, planPref, workspacePref, &workspaceSizeEstimate); |
制定計劃
下一步是創建實際計劃,它編碼了操作的執行,并選擇核函數。這一步涉及查詢 cuTENSOR 性能模型,通常是設置階段的最耗時步驟。因此,自 cuTENSOR 2.0.0 開始,它將在用戶控制的緩存中自動緩存。有關更多信息,請參閱計劃緩存和增量自動調整詳細介紹。
創建計劃也是如果啟用的話,會導致內核即時編譯的步驟。
cutensorPlan_t plan;cutensorCreatePlan(handle, &plan, desc, planPref, workspaceSizeEstimate); |
cutensorCreatePlan接受工作空間大小限制作為輸入 (在本例中,workspaceSizeEstimate) 并確保創建的計劃不超過此限制。
(可選) 查詢精確的工作空間大小使用情況
從 cuTENSOR 2.0.0 開始,您可以查詢創建的計劃,以了解其實際使用的工作空間大小。雖然這一步可選,但我們建議您執行此步驟,以減少所需的工作空間大小。
uint64_t actualWorkspaceSize = 0;cutensorPlanGetAttribute(handle, plan, CUTENSOR_PLAN_REQUIRED_WORKSPACE, &actualWorkspaceSize, sizeof(actualWorkspaceSize)); |
執行收縮
剩下的工作是執行收縮運算,并提供 GPU 需要訪問的數據指針。關于數據如何在主機上保留的更多信息,請參閱 使用 NVIDIA cuTENSORMg 擴展塊周期張量以支持多 GPU。
cutensorContract(handle, plan, (void*) α, A_d, B_d, (void*) β, C_d, C_d, work, actualWorkspaceSize, stream); |
元素化運算
元素級別 操作是 cuTENSOR 中最簡單的操作。元素級別其中參與者張量的大小不會降低任何方式。換句話說,您可以按元素級別執行操作。常見的元素級別操作包括復制張量、重排序張量、加法張量或元素級別乘法張量 (也稱為哈達姆德乘法)。
根據輸入張量的數量,cuTENSOR 提供三個元素級 API:
- cutensorCreatePermute 創建一個輸入張量
- cutensorCreateElementwiseBinary 創建兩個輸入張量的元素級二元運算。
- cutensorCreateElementwiseTrinary 創建一個三元運算操作,該操作作用于三個輸入張量。
例如,考慮一個 permutation。在這種情況下,張量 A (源) 和張量 B (目標) 是 rank-4 張量,您可以將其模式從NHWC擴展至NCHW.操作描述符的創建可以通過以下方式實現,與上一節中的步驟 1 和 6 相比較。
float alpha = 1.0f;cutensorOperator_t op = CUTENSOR_OP_IDENTITY;cutensorComputeDescriptor_t descCompute = CUTENSOR_COMPUTE_DESC_32F;cutensorOperationDescriptor_t permuteDesc;status = cutensorCreatePermutation(handle, &permuteDesc, α, descA, {‘N’, ‘H’, ‘W’, ‘C’}, op, descB, {‘N’, ‘C’, ‘H’, ‘W’}, descCompute, stream);// next stages (such as plan creation) omitted …cutensorPermute(handle, plan, α, A_d, C_d, nullptr /* stream */)); |
此代碼示例僅突出了與前一個收縮示例的不同之處。除了創建操作描述符和實際執行之外,所有階段均與收縮相同。唯一的例外是元素式運算不需要任何工作空間。
cuTENSOR 2.0 還提供了對張量重排序輸出張量進行填充的支持。如果需要滿足對齊要求,例如啟用向量化加載,這可能非常有用。
以下代碼示例詳細介紹了如何使用零填充輸出張量。具體來說,第四個模式的左側和右側各添加一個填充元,其余模式均未填充。
cutensorOperationDescriptorSetAttribute(handle, permuteDesc, CUTENSOR_OPERATION_DESCRIPTOR_PADDING_RIGHT, {0,0,0,1}, sizeof(int) * 4));cutensorOperationDescriptorSetAttribute(handle, permuteDesc, CUTENSOR_OPERATION_DESCRIPTOR_PADDING_LEFT, {0,0,0,1}, sizeof(int) * 4));float paddingValue = 0.f;cutensorOperationDescriptorSetAttribute(handle, permuteDesc, CUTENSOR_OPERATION_DESCRIPTOR_PADDING_VALUE, &paddingValue, sizeof(paddingValue)); |
有關更多信息以及完全功能的填充示例,請參閱 /NVIDIA/CUDALibrarySamples GitHub 資源庫。
歸約
cuTENSOR張量歸約操作 接受單個張量作為輸入,并使用歸約運算(如求和、乘法、最大值或最小值)來減少張量的維度。有關更多信息,請參閱 cutensorOperator-t.
與收縮和元素化運算類似,張量歸約也使用相同的多階段 API。此 API 示例僅限于不同之處。
cutensorOperationDescriptor_t desc;cutensorOperator_t opReduce = CUTENSOR_OP_ADD;cutensorCreateReduction(handle, &desc, descA, {‘a’, ‘b’, ‘c’}, CUTENSOR_OP_IDENTITY, descC, {‘b’, ‘a’,}, CUTENSOR_OP_IDENTITY, descC, {‘b’, ‘a’,}, opReduce, descCompute);// next stages (such as plan creation) omitted …cutensorReduce(handle, plan, (const void*)α, A_d, (const void*)β, C_d, C_d, work, actualWorkspaceSize, stream); |
輸入張量不一定要完全歸約為一個標量,但某些模式仍然可以保留。此外,模式的確切順序沒有任何限制,這有效地將轉換和歸約融合到一個內核中。例如,張量歸約不僅縮短了
也會改變剩余模式的順序。
即時編譯
正如我們在優化cuTENSOR 2.0 中所介紹的,我們引入了對張量收縮的即時編譯支持,以便在運行時為特定的張量收縮提供專用的核函數。這對于處理高維張量收縮等具有挑戰性的任務特別有價值,因為預構建的核函數可能不夠豐富。
啟用即時編譯可通過傳遞CUTENSOR_JIT_MODE_DEFAULT擴展至cutensorCreatePlanPreference 相應的張量收縮運算。
cutensorAlgo_t algo = CUTENSOR_ALGO_DEFAULT;cutensorJitMode_t jitMode = CUTENSOR_JIT_MODE_DEFAULT;cutensorPlanPreference_t planPref;cutensorCreatePlanPreference(handle, &planPref, algo, jitMode); |
然后使用 NVIDIA nvrtc 編譯器進行 CUDA C++編譯,并在第一次調用 cutensorCreatePlan 時運行時編譯內核。成功編譯的內核會被自動添加到內部內核緩存中,這樣任何后續調用相同的操作描述符和計劃優先級只會導致緩存查詢,而不是重新編譯。
為了進一步減少即時編譯的開銷,cuTENSOR 提供了 cutensorReadKernelCacheFromFile 和 cutensorWriteKernelCacheToFile,允許您讀取和寫入內部內核緩存到文件,以便在多個程序執行中重復使用。
cutensorReadKernelCacheFromFile(handle, "kernelCache.bin");// execution (possibly with JIT-compilation enabled) omitted…cutensorWriteKernelCacheToFile(handle, "kernelCache.bin"); |
For more information, please see the Just-In-Time Compilation section.
計劃緩存和增量自動調整
規劃是最耗時的設置階段,因為它會調用 cuTENSOR 性能模型。建議您存儲規劃并使用不同的數據指針多次重復使用。
然而,由于這種重復使用可能并不總是可行,或者在用戶端實施時可能需要花費大量時間,因此 cuTENSOR 2.0 采用了默認激活的軟件管理計劃緩存。您仍然可以在 CUTENSOR_CACHE_MODE_NONE 操作級別上進行調整。
計劃緩存可縮短cutensorCreatePlan速度提升了約 10 倍。
計劃緩存采用最近使用 (LRU) 驅逐策略,其默認容量為 64 條記錄。理想情況下,您希望緩存的容量與獨特張量收縮的數量相同或更高 .cuTENSOR 提供以下選項來更改緩存容量:
int32_t numEntries = 128;cutensorHandleResizePlanCachelines(&handle, numEntries); |
與內核緩存類似,計劃緩存也可以通過磁盤進行序列化,從而在不同的程序執行中重復使用:
uint32_t numCachelines = 0;cutensorHandleReadPlanCacheFromFile(handle, "./planCache.bin", &numCachelines);// execution (possibly with JIT-compilation enabled) omitted…cutensorHandleWritePlanCacheToFile(handle, "./planCache.bin"); |
增量自動調整是計劃緩存的選擇性功能。它允許不同候選或核函數執行連續的相同操作,具有可能不同的數據指針。在探索用戶定義的數量候選時,系統會存儲速度最快的候選,以供特定操作使用。
與其他自動調整方法相比,使用計劃緩存的增量自動調整具有以下優勢:
- 從用戶角度來看,它不需要對現有代碼進行其他修改,除了啟用該功能之外。此外,它還盡可能減少了測量開銷,因為它不使用計時循環或同步。
- 候選內容在硬件緩存狀態與生產環境相匹配的時刻進行評估。換句話說,硬件緩存狀態反映了現實情況。
在計劃首選項創建期間,可以啟用增量自動調整,如下所示:
const cutensorAutotuneMode_t autotuneMode = CUTENSOR_AUTOTUNE_MODE_INCREMENTAL;cutensorPlanPreferenceSetAttribute( &handle, &find, CUTENSOR_PLAN_PREFERENCE_AUTOTUNE_MODE_MODE, &autotuneMode , sizeof(cutensorAutotuneMode_t));// Optionally, also set the maximum number of candidates to exploreconst uint32_t incCount = 4;cutensorPlanPreferenceSetAttribute( &handle, &find, CUTENSOR_PLAN_PREFERENCE_INCREMENTAL_COUNT, &incCount, sizeof(uint32_t)); |
有關 cuTENSOR 的計劃緩存和增量自動調整功能的更多信息,請參閱 計劃緩存文檔。
多 GPU 支持
有關更多信息,請參閱 利用 NVIDIA cuTENSORMg 擴展塊周期張量,實現多 GPU 支持。
總結
在處理密集張量時,cuTENSOR 提供了一個全面的例程集合,使您作為 CUDA 開發者的生活更加輕松,并且不必擔心低級別性能優化。許多您想要應用到張量的算法都可以使用現有的 cuTENSOR 例程來表達。
作為 CUDA 庫用戶,您還可以從任何未來的 NVIDIA 架構和其他性能改進中受益,因為我們不斷優化 cuTENSOR 庫。
有關更多信息,請參閱 cuTENSOR 2.0:應用程序和性能。
開始使用 cuTENSOR 2.0
開始使用 cuTENSOR 2.0。
深入了解 cuTENSOR 2.0,并在開發者論壇中討論。
?