
CUDA Quantum 是一種用于構建量子經典應用的開源編程模型。有用的量子計算工作負載將在異構計算架構上運行,例如量子處理器(QPU)、GPU 和 CPU,它們協同工作以解決現實世界的問題。CUDA Quantum 通過提供對這些計算架構進行協調編程的工具來加速此類應用程序。
針對多個 QPU 和 GPU 的能力對于擴展量子應用至關重要。當這些工作負載可以并行化時,將工作負載分配到多個計算端點可以實現顯著加速。新的 CUDA Quantum 功能支持多 QPU 平臺以及多個 GPU 無縫編程。
CUDA Quantum 中的大部分加速都是通過消息傳遞接口 (MPI) 完成的,MPI 是一種用于并行編程的通信協議。它對于解決天氣預報以及流體和分子動力學模擬等需要大量計算的問題特別有用。現在,CUDA Quantum 可以使用 MPI 插件與任何 MPI 實現集成,因此客戶可以輕松地將 CUDA Quantum 與現有的 MPI 設置一起使用。
使用多 GPU 擴展電路模擬
電路仿真依賴于量子比特 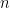
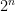
此外,nvidia-mgpu 目標可聚合節點中多個 GPU 的內存和集群中多個節點的內存,以實現擴展并消除單個 GPU 顯存瓶頸。CUDA Quantum 中的這款開箱即用型軟件工具適用于單個節點,與適用于數十甚至數千個節點一樣。量子位數量僅受可用 GPU 資源的限制。
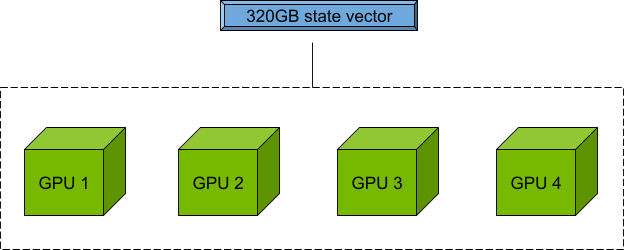
對于具有四個 GPU 且每個 GPU 均具有 80 GB 顯存的節點,您可以使用 80 x 4=320 GB 顯存來存儲和操作量子態向量,以進行電路模擬。
使用多 QPU 實現并行化
借助多 QPU 模式,您可以對未來的工作流程進行編程,在這種工作流程中,并行化可將運行時間縮短至可用計算資源的 1 倍。
想象一下,在電路切割協議中,一次切割需要運行多個子電路,其結果在后處理中被重新拼接在一起。在傳統軟件中,這些子電路將按順序執行。但是,使用 nvidia-mqpu CUDA Quantum 中的目標,這些子電路將并行執行,大幅減少運行時間。
目前,nvidia-mqpu目標是 GPU。隨著量子硬件的發展速度,QPU 數據中心正在迅速逼近。
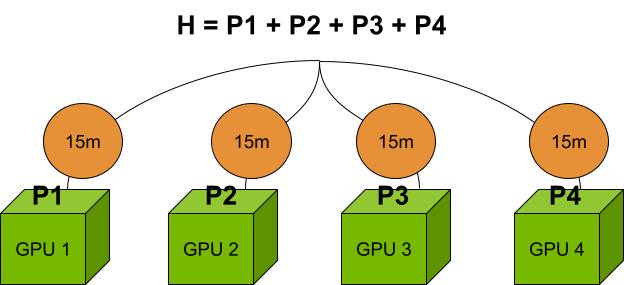
另一種常見的“令人難為情的并行”工作流程是計算具有許多項的哈密頓量的期望值。在多 QPU 模式下,您可以定義多個端點,其中每個端點都可以模擬問題的獨立部分。使用 nvidia-mqpu 例如,您可以異步并行運行哈密頓量的多個項。有關詳細信息,請參閱 對量子經典超級計算機進行編程。
對于前面提到的由四個 GPU 組成的集群,與在單個 GPU 上計算哈密頓量項相比,并行計算速度提高了 4 倍。如果具有多個端點的順序計算需要 1 小時,則只需 15 分鐘。但是,每個 GPU 上的問題大小仍限制在 80 GB 以內。
結合使用多 QPU 和多 GPU 工作負載
如前所述,使用 NVIDIA DLSS 3 和 NVIDIA DLSS 技術nvidia-gpu目標和并行化nvidia-mqpu借助 CUDA Quantum 0。6,您現在可以將兩者結合起來,從而實現大規模模擬的并行運行。
在上一個示例中,如果連續計算需要1小時,并且包含兩個端點,那么每個端點只需要30分鐘,因為兩個端點可以由兩個 NVIDIA A100 GPU支持,并且擁有160 GB的狀態向量。
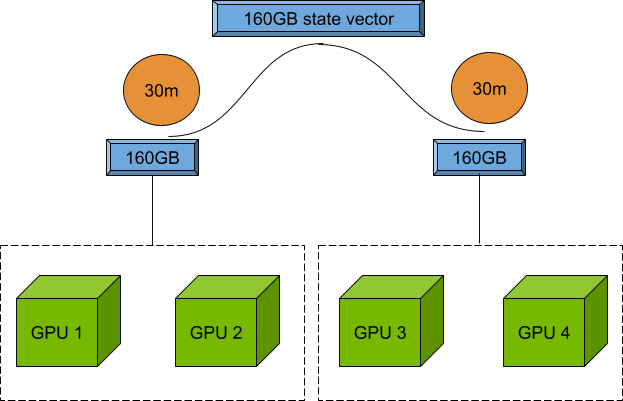
作為開發者,您現在可以嘗試在問題規模和并行端點數量之間找到最佳平衡點,以最大限度地利用您的 GPU。請參閱 CUDA Quantum 文檔,詳細了解remote-mqpu目標。
MPI 插件
MPI 是一種用于對并行計算機進行編程的通信協議。
CUDA Quantum 利用 MPI 并使用開放 MPI 構建,開放 MPI 是 MPI 協議的開源實現。此外,還有其他流行的 MPI 實現,如 MPICH 和 MVAPICH2,以及許多高性能計算(HPC) 中心或數據中心已經建立了特定的實現。
現在,通過 MPI 插件接口將 CUDA Quantum 與任何 MPI 實現集成比以往更容易。需要一次性激活腳本來為實現創建動態庫。CUDA Quantum 0。6 包含與 Open MPI 和 MPICH 兼容的插件實現。歡迎為其他 MPI 實現貢獻內容,并且應易于添加。
如需詳細了解如何使用 MPI 插件,請訪問 使用 MPI 的分布式計算 CUDA Quantum 文檔部分。
詳細了解 CUDA Quantum
訪問 NVIDIA/cuda-quantum 查看完整的 CUDA Quantum 0.6 版本日志。CUDA Quantum 入門指南將為您介紹 Python 和 C++ 示例。有關量子經典應用的高級用例,請參閱 CUDA 量子教程。最后,在 Omniverse 中探索代碼、報告問題并提出功能建議,使用 CUDA Quantum 開源庫。





