當一項技術達到所需的成熟度時,采用將從那些被認為是有遠見的人轉變為早期的多數采用者。現在是工業 high-performance computing ( HPC )最大單一細分市場的關鍵和過渡時刻。
2021 年底和 2022 年初,兩家最大的商業計算流體動力學( CFD )工具供應商 Ansys 和西門子都推出了其旗艦 CFD 工具版本,支持 GPU 加速。僅這一事實就足以證明 CFD 的新時代已經到來。
CFD 工程應用的發展
過去十年, CFD 被廣泛采用,作為工程師和設備設計師研究或預測其設計行為的關鍵工具。然而, CFD 不僅僅是一種分析工具,它現在被用來進行設計改進,而無需對每個正在評估的設計/操作點進行耗時且昂貴的物理測試。這種普遍性是為什么今天有這么多 CFD 工具、商業和開源軟件可用的部分原因。
對模擬精度的日益增長的需求有助于將測試最小化,這導致了 將多種物理功能納入 CFD 工具 ,例如包括傳熱、傳質、化學反應、顆粒流等。 CFD 工具增長的另一個原因是,在一個工具中捕獲每種類型用例的所有相關物理數據是一項耗時的工作。
例如,在車輛空氣動力學的使用案例中,數字風洞可用于研究和評估幾何體上的氣流,并評估設計表面產生的阻力,這對車輛性能有直接影響。根據模擬的預期目的,用戶可以選擇是否使用傳統的流體流動 Navier-Stokes 公式或使用 替代框架,如晶格玻耳茲曼方法 進行穩態或瞬態模擬。
即使在 Navier-Stokes 解決方案的領域內,也有各種湍流模型和方法,如分辨率和建模的尺度,可供選擇用于模擬。在進行設計選擇時,如果考慮到其他物理因素,例如研究對客戶感知、乘客安全和舒適性有影響的汽車氣動聲學,或研究道路車輛排列,模型的復雜性會迅速增加。
所有用于建模不同流動情況的工具都需要驚人的計算處理能力。隨著各組織開始在其設計周期的早期將 CFD 納入其中,同時在模型尺寸和代表性物理方面增加其模型的復雜性,以提高模擬的保真度,該行業已經達到了一個轉折點。
并行性等同于性能
單個模擬需要數千個 CPU 核心小時才能提供結果的情況已不再少見,單個設計產品可能需要10000到1000000個模擬或更多。
就在最近, NVIDIA 的一家合作伙伴 Resolved Analytics 發布了一份 CFD 用戶和工具調查。 統計數據,其中顯示了 CFD 用戶目前常用的并行度。在 CFD 中,并行執行是指將域或網格劃分為子網格,并為每個子網格分配一個處理單元。在每次數值迭代中,子網格與相鄰子網格傳遞邊界信息, CFD 解趨于收斂。
調查結束時得出的結論是,硬件和軟件成本繼續限制 CFD 的并行化。
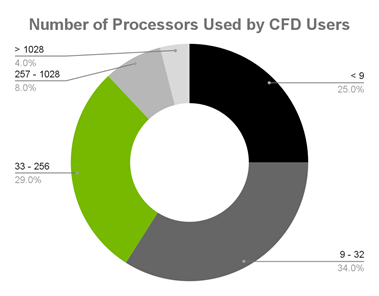
Resolved Analytics 調查了 CFD 用戶,發現絕大多數用戶使用的處理器少于 257 個,影響了并行編程能力:
- 25% 的 CFD 用戶使用的處理器少于 9 個。
- 34% 的用戶使用 9-32 個處理器。
- 29% 使用 33-256 個處理器。
- 8% 使用 257-1028 處理器。
- 4% 使用超過 1028 個處理器。
另一種思考方法是 并行性等同于性能,運行時等同于最小化 。這意味著,如果您不受硬件和軟件許可證的限制,您可以將性能提升到今天的水平。
獲得更高級別的性能是正確的,因為它優化了最昂貴的資源:工程師和研究人員的時間。通常,熟練人員的時間可能是第二昂貴資源(軟件許可證或計算硬件)成本的 5-10 倍。邏輯要求分配資金,以消除這些低成本資源造成的瓶頸。
另一個 NVIDIA 合作伙伴 Rescale 以類似的方式陳述了 perspective :
大多數 HPC 經濟模型忽略了工程時間或工程生產率,而這是最有價值和最昂貴的資源,需要首先進行優化。確保硬件和軟件資產使研究人員能夠以最大速度生成知識產權,這是對待組織核心價值生成器的最合理方式。
NVIDIA 很高興與CFD用戶社區分享硬件限制正在解除。最近,西門子數字工業軟件公司(Siemens Digital Industries Software)和Ansys Fluent提供的兩種最流行的CFD工具Simcenter STAR-CCM+已經提供了軟件版本,以幫助支持特定的物理。這些物理模擬可以充分利用加速計算的極端速度。
在發布本文時, Simcenter STAR-CCM + 2022.1 GPU 加速版已普遍可用,目前支持車輛外部空氣動力學應用程序進行穩態和非穩態模擬。 Ansys Fluent 版本目前正在公測中。
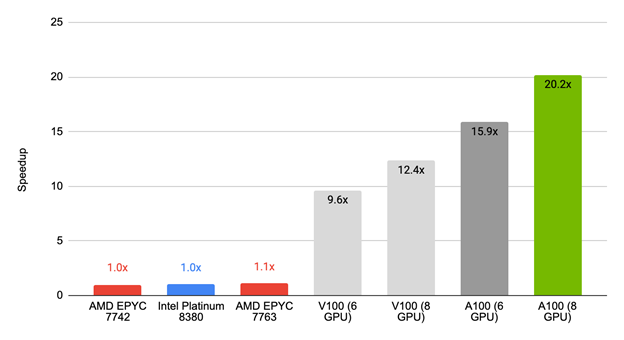
圖 2 顯示了 Simcenter STAR-CCM + 2022.1 的第一個版本相對于常見的僅 CPU 服務器的性能。對于經過測試的基準測試,配備 NVIDIA GPU 的服務器提供的結果比 100 多核 CPU 快近 20 倍。
AMD EPYC 7763 的加速比為 1.1 倍,相比之下, NVIDIA V100 (六個 GPU )的加速比為 9.6 倍, NVIDIA V100 (八個 GPU )的加速比為 12.4 倍, NVIDIA A100 (六個 GPU )的加速比為 15.9 倍, NVIDIA A100 (八個 GPU )的加速比為 20.2 倍。
從更實際的角度來看,這意味著在一臺 CPU 服務器上進行一整天的模擬只需一個多小時,就可以用一個節點和八個 NVIDIA A100 GPU 完成。
隨著 Simcenter STAR-CCM +團隊繼續致力于改進和優化其 GPU 產品,您可以期望在即將發布的版本中獲得更好的性能。

Corvette C6 ZR1 外部空氣動力學,偽穩態模擬, 110M 單元使用 SST-DDES 和車輪移動參考框架( MRF )運行。 GPU 在 4xA100 DGX 站上運行。
與僅使用 CPU 的運行相比, GPU 加速運行可提供一致的結果,西門子提供的產品可以無縫地從 CPU 移動到 GPU ,以更快、更輕松地獲得結果。結果是,您現在可以在本地或云上運行模擬,因為所有主要云服務提供商都提供了 100 個 GPU 實例。
西門子在其 2022.1 版中宣布支持 GPU 比較上一代 V100 GPU 和當前一代 A100 GPU 的本地和云中僅 CPU 的服務器時。他們還展示了一個大型工業模型的性能,以及獲得與具有八個 GPU 的單個節點相似的運行時間所需的 CPU 核的等效數量。
NVIDIA 和 Ansys 宣布 在 2021 GTC 秋季主題演講上, GPU 加速、功能有限 Fluent 的公測可用性。
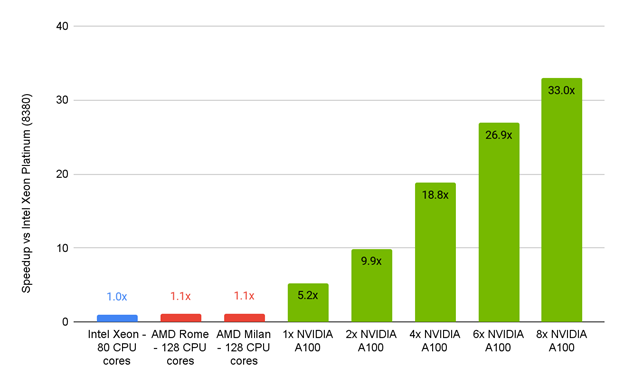
該比較基于 100 次迭代定時穩態 GEKO 湍流模型 .
與純 CPU 服務器相比, Ansys Fluent 2022 beta1 服務器的性能表明, Intel Xeon 、 AMD Rome 和 AMD Milan 的加速比為 1.1 倍左右,而 NVIDIA A100 PCIe 80GB 的加速比為 5.2 倍(一個 GPU )到令人印象深刻的 33 倍(八個 GPU )。
Ansys 流暢的數字讓人興奮不已。他們表明,為他們選定的基準測試和相關物理性能設計的一臺 GPU 加速服務器,其性能可以達到目前常見的標準純英特爾處理器服務器的近 33 倍。
如此快速的周轉時間是由于兩個最常用的商業CFD應用程序的加速。這意味著設計工程師不僅可以在設計周期的早期將仿真納入其中,還可以在一天內探索多個設計迭代。他們可以快速做出關于產品性能的明智決策,而無需等待數周。
GPU 加速的其他選項
以這樣的速度,產品研究過程中可能會出現其他瓶頸。有時,工程時間的主要消耗是預處理,或手動構建要運行的模型的過程。
解決這個問題尤其重要,因為它需要工程人員的時間來解決。這與其他因素不同,比如模擬運行時間,它讓研究人員可以自由地專注于其他任務。這是最近在 CFD 網格生成器:影響分析速度的三大原因及解決方法 中強調的一個活躍的焦點領域。
盡管如此,加速度并不是一個全新的現象。更多的工具要么誕生于GPU加速的世界,要么很快就會出現:
- Altair CFD 、 nanoFluidX 、 ultraFluidX 和 Acusolve
- Cascade Technologies , CharLES
- 梭魚
- 達索系統, Simulia XFlow
- 數字系統, pacefish
- Prometec , Particleworks
- M-Star CFD
- NASA , FUN3D
NVIDIA 展示了 NASA 的 FUN3D 工具 令人興奮和視覺震撼的結果,包括黃仁勛分享火星著陸器進入大氣層的模擬。
ORNL Summit 使用 IBM AC922 Dual Power9 CPU 和 6x NVIDIA V100 SXM2 16 GB 2x EDR InfiniBand 提供硬件訪問。
最近的超級計算會議的一個研究小組研究了大規模并行計算環境所需的VZX19。幾個內核的運行時間主要取決于更新速度,因此在這一領域發現的效率可能帶來巨大的好處。此外,盡管FUN3D是NASA和美國政府的專用工具,但本文的討論也適用于其他非結構化雷諾平均Navier-Stokes CFD工具。
除了節省成本和消除障礙之外, GPU 加速的主流 CFD 工具最令人興奮的部分可能是新的科學和工程技術,它將運行時間縮短了 15-30 倍。到目前為止,由于沒有領導級超級計算能力,從運行時和問題規模的角度來看,對這些領域的調查都太困難了:
- 發動機罩下車輛建模: 帶傳熱的湍流
- 大渦流和燃燒:詳細的環境排放建模需要?
- 磁流體動力學: 受磁場影響的流動對聚變能發生器、恒星內部和氣體巨行星的建模非常重要
- 機器學習培訓:自動生成用于 訓練機器學習 算法的模型和解決方案,以估計流量初始條件、模型湍流、混合等
有關用于其他流體或工業模擬的加速計算的更多信息,請觀看最近推薦的 GTC 2022 會議,重點討論制造業和 HPC :
- 用 GPU 加速汽車噪聲、振動和平順性
- Accelerating high- fidelity 多物理流模擬
- 使用 NVIDIA DRIVE 加速自主車輛開發
- 解決車輛自主性方面的開放性研究挑戰
- Fluent 中的非結構化多 GPU 隱式 CFD 求解器
- GP GPU 車輛外部空氣動力學模擬的加速啟用
特色圖片:Omniverse Altair UltraFluidX 繞 Rimac 汽車模型流動模擬的可視化
?