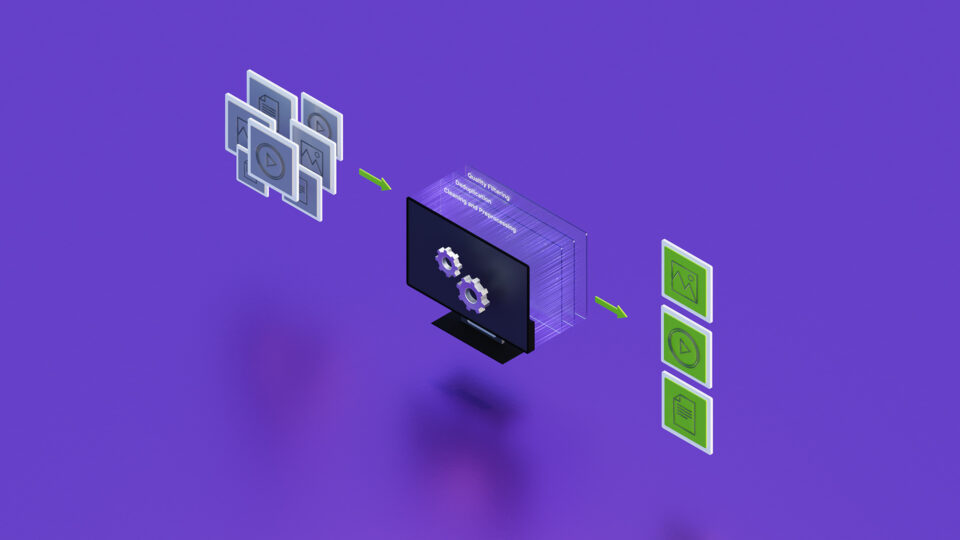
生成 AI はコンピューティングの新時代を切り拓き、人間とコンピューターとのやり取りに革命をもたらすと期待されています。この驚異的な技術の最前線にあるのが大規模言語モデル (LLM) です。LLM により、企業は大規模なデータセットを使用してコンテンツを認識、要約、翻訳、予測、生成できるようになります。しかし、企業向け生成 AI は可能性を秘めている一方で、相応の課題が伴います。
汎用 LLM を利用したクラウド サービスは、生成 AI テクノロジを素早く取り入れるための手軽な方法です。しかし、こうしたクラウド サービスは広範なタスクに焦點を當てていることが多く、ドメイン固有のデータでトレーニングされているわけではないため、エンタープライズ向けアプリケーションによってはその価値は限られています。多くの組織は獨自のソリューションを構築することになりますが、構築の際にはさまざまなオープンソース ツールを組み合わせ、互換性を確保し、サポートまで獨自で行う必要があるため、これは骨の折れる作業です。
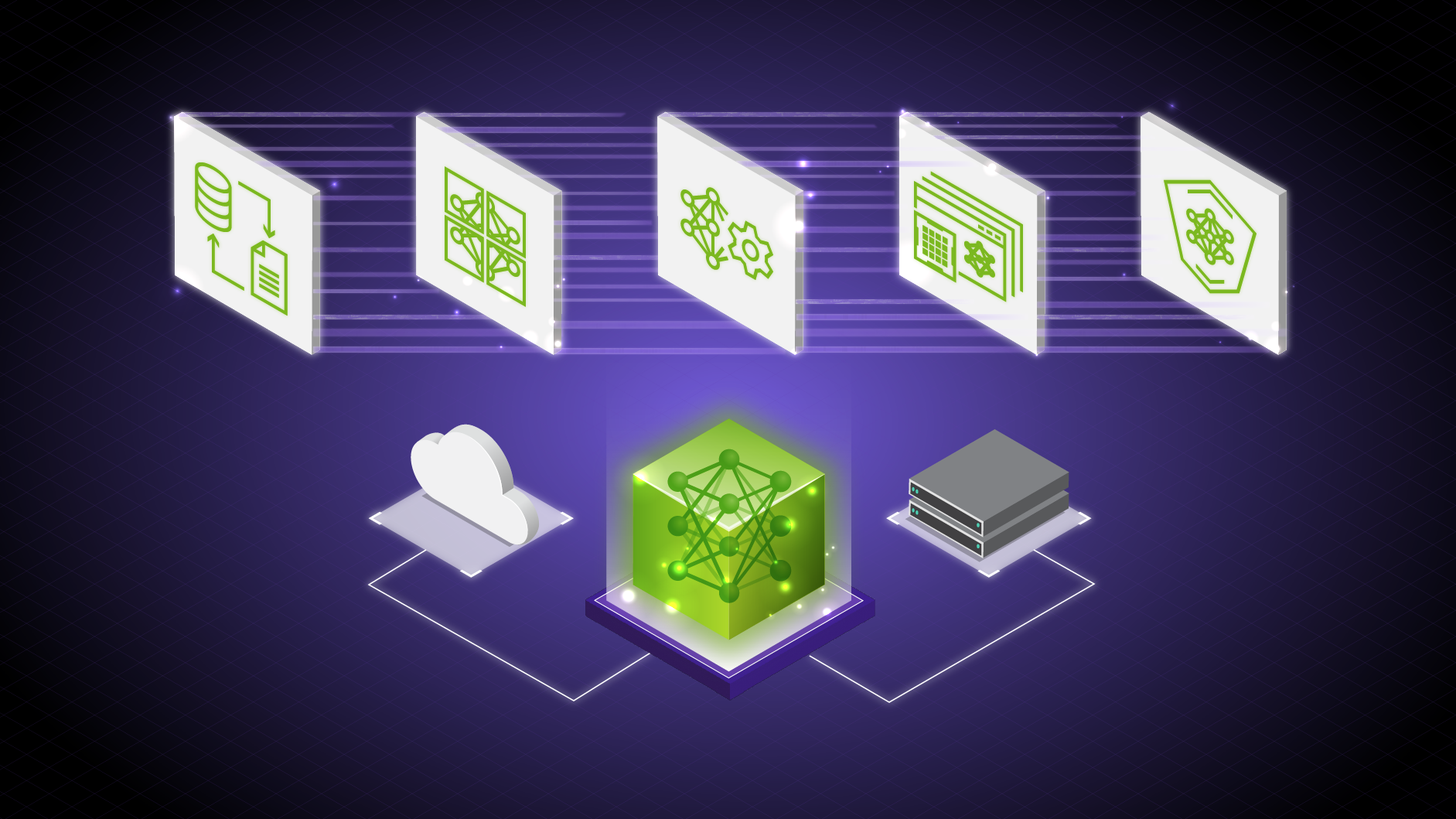
NVIDIA NeMo は、企業が LLM の開発と展開を合理化できるように設計されたエンドツーエンドのプラットフォームを提供します。AI 機能に変革をもたらす時代の到來を告げるツールキットです。NeMo には、エンタープライズグレードの本番環境に対応したカスタム LLM の作成に欠かせないツールが備わっています。NeMo の一連のツールにより、データ キュレーション、トレーニング、展開のプロセスが簡素化され、各組織に特有の要件に合わせてカスタマイズされた AI アプリケーションの迅速な開発が促進されます。
事業運営に AI を活用している企業向けに、NVIDIA AI Enterprise は安全なエンドツーエンドのソフトウェア プラットフォームを提供しています。NeMo を生成 AI リファレンス アプリケーションやエンタープライズ サポートと組み合わせて利用することで、NVIDIA AI Enterprise は導入プロセスを合理化し、AI 機能のシームレスな統合への道を拓きます。
本番環境に対応した生成 AI のためのエンドツーエンド プラットフォーム
NeMo フレームワークによって、エンドツーエンドの機能とコンテナ化された方策がさまざまなモデル アーキテクチャに提供され、エンタープライズ グレードのカスタマイズされた生成 AI モデルを構築する手順がシンプルになります。
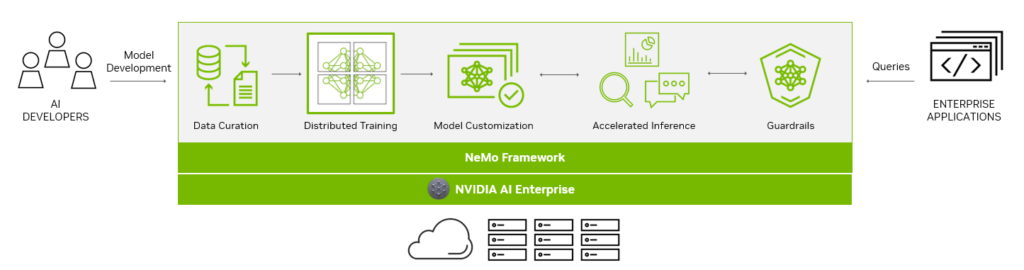
LLM の作成を支援するために、NeMo フレームワークにはパワフルなツールが用意されています。
- データ キュレーション
- 大規模な分散トレーニング
- カスタマイズ用の事前トレーニング済みモデル
- 推論の加速化
- ガードレール
データ キュレーション
AI が急速に進化し続ける中、堅牢な LLM を構築する上で大規模なデータセットには重要な要素となっています。
NeMo フレームワークは NeMo Data Curator によって、複雑なデータ キュレーションのプロセスを合理化します。NeMo Data Curator は、多言語データセットに含まれる何兆ものトークンをキュレーションするという課題に対処し、その優れた可用性により、データのダウンロード、テキスト抽出、クリーニング、フィルタリング、完全重複排除やあいまい重複排除などのタスクが簡単に処理できます。
Data Curator は、メッセージ パッシング インターフェイス (MPI)、Dask、Redis Cluster といった最先端技術のパワーを活用することで、データ キュレーション プロセスを數千のコンピューティング コアに拡張できるため、手作業が大幅に減り、開発ワークフローが加速されます。
Data Curator の主なメリットの 1 つに挙げられるのが、重複排除機能です。LLM が固有のドキュメントでトレーニングされるようになることで、データの冗長性が排除され、事前トレーニング段階での大幅なコスト削減が実現する可能性があります。これにより、モデル開発プロセスが合理化されるだけでなく、組織の AI 投資が最適化されることになり、AI 開発にさらに著手しやすくなるとともに、コスト効率が向上します。
Data Curator は NeMo トレーニング コンテナのパッケージに含まれており、NGC から入手できます。
大規模な分散トレーニング
10 億パラメーターの LLM モデルをゼロからトレーニングする際に直面する特有の課題が、高速化とスケーリングです。このプロセスには、大規模な分散コンピューティング性能、アクセラレーションベースのハードウェアとメモリのクラスター、信頼性と拡張性の高い機械學習 (ML) フレームワーク、およびフォールトトレラント システムが必要です。
NeMo フレームワークの中核を成すのは、分散トレーニングと高度な並列処理の統合です。NeMo はノード全體で GPU のリソースとメモリを専門的に使用するため、効率性が畫期的に向上します。NeMo はモデルとトレーニング データを分割することで、マルチノードおよびマルチ GPU のシームレスなトレーニングを可能にし、トレーニング時間を大幅に短縮し、全體的な生産性を向上させます。
NeMo の特徴の中で特に目を引く點は、さまざまな並列化手法が組み込まれていることです。
- データ並列化
- テンソル並列化
- パイプライン並列化
- シーケンス並列化
- スパース アテンション リダクション (SAR)
これらの手法が連攜してトレーニング プロセスを最適化されるため、結果としてリソースの使用量が最大化され、パフォーマンスが向上します。
また、NeMo には各種精度オプションも用意されています。
- FP32/TF32
- BF16
- FP8
FlashAttention や Rotary Positional Embedding (RoPE) などの畫期的なイノベーションは、シーケンス長の長いタスクに対応します。Attention with Linear Biases (ALiBi)、勾配チェックポイントおよび部分的チェックポイントの設定、Distributed Adam Optimizer により、モデルのパフォーマンスと速度がさらに向上します。
カスタマイズ用の事前トレーニング済みモデル
生成 AI のユースケースにはゼロからトレーニングする必要があるものもありますが、カスタマイズされた LLM を構築する際に、事前トレーニング済みモデルを使用して作業を促進させる組織が増えています。
事前トレーニング済みモデルの最も大きなメリットの 1 つは、時間とリソースの節約です。汎用 LLM の事前トレーニングに必要なデータの収集およびクリーニングのフェーズをスキップすることで、特定のニーズに合わせてモデルをファインチューニングすることに集中でき、最終的なソリューションを得るまでの時間を短縮できます。また、事前トレーニング済みモデルには既知のナレッジが含まれており、すぐにカスタマイズできるため、インフラストラクチャのセットアップとモデルのトレーニングの負擔が大幅に軽減されます。
數千のオープンソース モデルが GitHub や Hugging Face などのハブでも利用できるため、どのモデルから著手するか選択することができます。事前トレーニング済みモデルを評価するための最も一般的な測定値としては精度がありますが、他にも以下の點を考慮すべきです。
- サイズ
- ファインチューニングにかかるコスト
- レイテンシ
- メモリの制約
- 商用ライセンスのオプション
NeMo を利用すると、NVIDIA のほか、Falcon AI、Llama-2、MPT 7B などの一般的なオープンソース リポジトリの幅広い事前トレーニング済みモデルを入手できます。
NeMo モデルは推論用に最適化されているため、本番稼働のユースケースに最適です。NeMo のモデルは現実世界のアプリケーションに展開できるため、斬新な成果がもたらされ、組織の AI の可能性を最大限に引き出すことができます。
モデルのカスタマイズ
ML モデルのカスタマイズは、ビジネスや業界固有のニーズに対応するために急速に進化しています。NeMo フレームワークでは、専門的なユースケースに対応できる汎用的な事前トレーニング済み LLM を改良するための各種手法を用意しています。これらの多様なカスタマイズ オプションを通じて、NeMo はさまざまなビジネス要件を満たすために欠かせない幅広い柔軟性を提供します。
プロンプト エンジニアリングは、事前トレーニング済みモデルのパラメータを調整せずに多くの下流タスクで事前トレーニング済み LLM を使用できるようにする、効果的なカスタマイズ方法です。プロンプト エンジニアリングの目標は、モデルから目的の出力を引き出せる具體的かつ明確なプロンプトを設計、最適化することです。
P チューニングとプロンプト チューニングは、巧みな最適化を用いて LLM のいくつかのパラメータのみを選択的に更新する Parameter-Efficient Fine-Tuning (PETF) 手法です。NeMo で実裝されているように、モデルにおいてすでにチューニング済みの以前のタスクを上書きしたり中斷したりすることなく、新しいタスクを當該モデルに追加できます。
NeMo は、マルチ GPU やマルチノード環境での使用に合わせて P チューニング手法を最適化し、トレーニングの高速化を実現しています。また、NeMo の P チューニングは「早期停止」メカニズムもサポートしています。このメカニズムは、これ以上トレーニングしても精度があまり向上しない時點にモデル収束時點を特定するものです。「早期停止」によりトレーニング ジョブが停止するため、モデルのカスタマイズに必要な時間とリソースが削減されます。
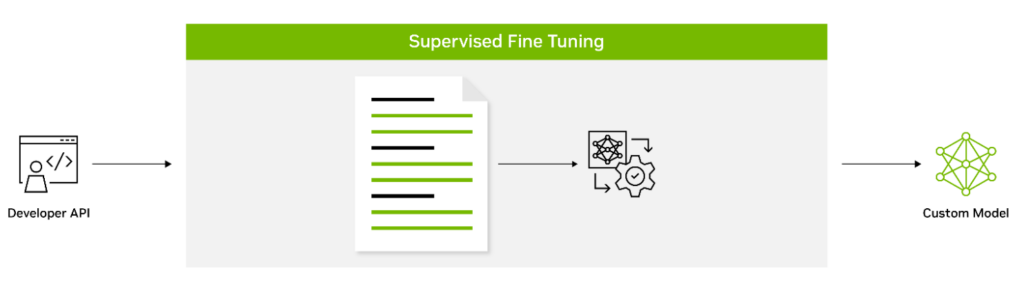
教師ありファインチューニング (SFT) では例えば、ラベル付きデータを使用してモデルのパラメータをファインチューニングします。命令チューニングとも呼ばれるこの形式のカスタマイズは通常、事前トレーニング後に実行されます。初期トレーニングを必要とせずに最先端のモデルを使用できるため、計算コストが削減されデータ収集要件が少なくなるという利點があります。
アダプターは、モデルのコア層の間に小さなフィードフォワード層を取り込みます。これらのアダプター層は、特定の下流タスクに合わせてファインチューニングされ、著手中のタスク要件に特有なレベルのカスタマイズが提供されます。
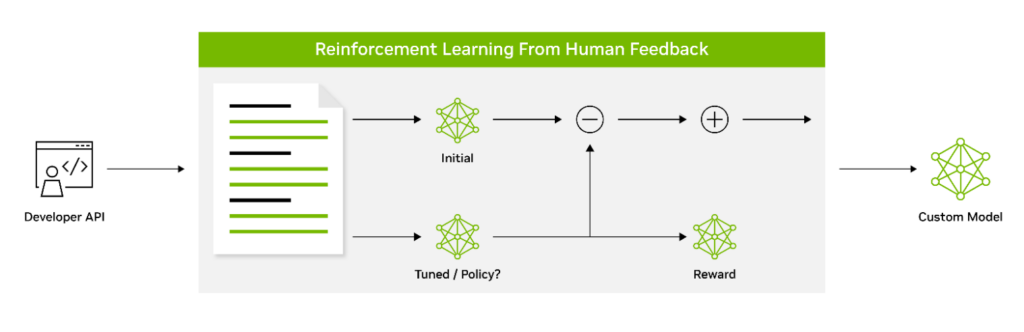
人間のフィードバックからの強化學習 (RLHF) では、ファインチューニングのプロセスが 3 段階採用されています。モデルはフィードバックに基づいてその動作を適応させることで、人間の価値観や好みとさらに一致するようになります。このため、RLHF は人間のユーザーの共感を呼ぶモデルを作成するためのパワフルなツールになります。
AliBi によって Transformer モデルは、トレーニングに使用されたモデルよりも長いシーケンスを推論時に処理できます。AliBi は、処理する情報が長い、または複雑であるシナリオで特に有用です。
NeMo Guardrails によって、LLM を利用したスマート アプリケーションの正確性、適切性、トピックへの対応性、安全性が確保されます。オープンソースとして入手できる NeMo Guardrails には、テキストを生成する AI アプリの安全性向上のために企業が必要とするすべてのコード、サンプル、ドキュメントが備わっています。NeMo Guardrails は NeMo だけでなく、OpenAI の ChatGPT などすべての LLM と連攜します。
推論の加速化
NeMo は NVIDIA Triton Inference Server とシームレスに連攜することで、推論プロセスを大幅に加速し、精度向上、低遅延、高スループットを実現します。この連攜により、単一の GPU から大規模なマルチノード GPU までの安全かつ効率的な展開が容易になるとともに、安全性およびセキュリティに関する厳しい要件に遵守できます。
NVIDIA Triton により、NeMo は生成 AI の推論を合理化、標準化できるようになります。これによって GPU または CPU ベースの任意のインフラストラクチャにある任意のフレームワークから、トレーニング済みの ML モデルやディープラーニング (DL) モデルを展開、実行、スケーリングできます。こうした高いレベルの柔軟性により、本番環境への展開における柔軟性を損なうことなく、AI 研究やデータ サイエンス プロジェクトに最適なフレームワークを選択する自由が得られます。
ガードレール
NVIDIA AI Enterprise ソフトウェア スイートの 1 つである NeMo を使用することで、組織は自信を持って本番環境に対応した生成 AI を展開できます。組織は最長 3 年間の長期ブランチ サポートを利用できるため、シームレスな運用と安定性が確保できます。共通脆弱性識別子 (CVE) の定期的なスキャン、セキュリティ通知、タイムリーなパッチによりセキュリティが強化され、API が安定しているため簡単に更新できます。
NVIDIA AI Enterprise のサポート サービスは、NVIDIA AI Enterprise ソフトウェア スイートを購入することで利用できます。NVIDIA の AI 専門家に直接アクセスできるほか、明確なサービス レベル アグリーメントが提供され、長期サポートを選択することでアップグレードやメンテナンスのスケジュールが管理されます。
エンタープライズグレードの生成 AI を強化する
NVIDIA AI Enterprise 4.0 の 1 つである NeMo は、クラウド、データ センター、さらには NVIDIA RTX を搭載したワークステーションや PC を含む複數のプラットフォームにわたってシームレスな互換性を実現します。これにより、Develop Once, Deploy Anywhere (一度開発すればどこにでも展開できる) を真に體験することができ、統合の複雑さが解消され、運用効率が最大化されます。
NeMo は、カスタム LLM の構築を検討している先進的な組織の間ですでに大きな注目を集めています。Writer や Korea Telecom は NeMo を採用し、その機能を活用して AI 主導の取り組みを進めています。
NeMo の比類ない柔軟性とサポートは、企業にさまざまな可能性をもたらし、企業は個別のニーズや業種に合わせた高度な LLM ソリューションを設計、トレーニング、展開できるようになります。NVIDIA AI Enterprise と連攜して自社のワークフローに NeMo を統合することで、組織は新たな成長の道を切り拓き、有用なインサイトを獲得し、最先端の AI を活用したアプリケーションを顧客やクライアント、あるいは従業員に提供できます。
NVIDIA NeMo の利用を開始する
NVIDIA NeMo は、生成 AI の計り知れない可能性と企業が直面する現実との間のギャップを埋める革新的なソリューションとして生まれました。LLM の開発と展開に利用できる包括的なプラットフォームである NeMo により、企業は AI テクノロジを効率的かつコスト効率よく活用できます。
そのパワフルな機能により、企業は AI を自社の業務に統合し、プロセスを合理化し、意思決定力を強化し、成長と成功を収めるための新たな道を切り拓くことができます。
NVIDIA NeMo は、本番環境に対応した生成 AI を構築する際にとても役に立ちます。その詳細をご確認ください。