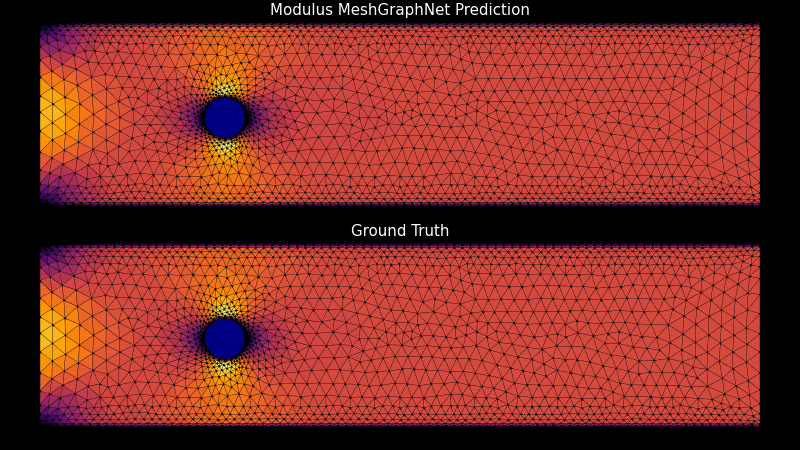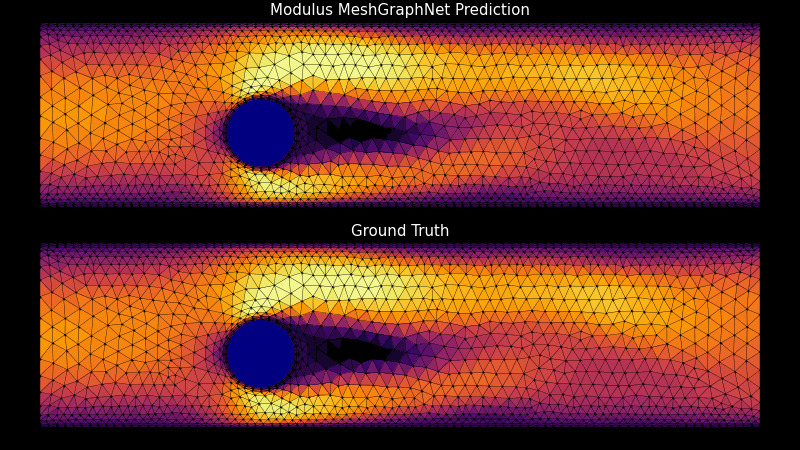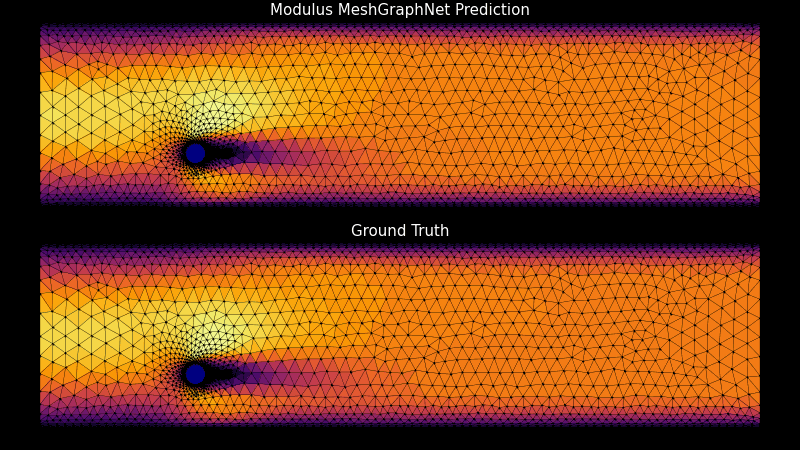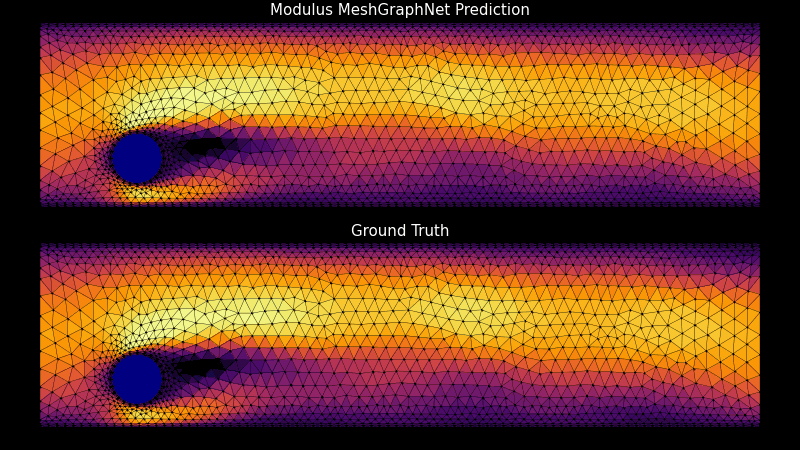
デジタル ツイン、気候モデル、物理ベースのモデリングとシミュレーションのためのカスタマイズ可能なトレーニング パイプラインの作成を可能にする AI フレームワーク、NVIDIA PhysicsNeMo の最新バージョンがダウンロード可能になりました。
Physics-ML フレームワークの今回のリリースである NVIDIA PhysicsNeMo v22.09 には、neural operator アーキテクチャを構成する際の柔軟性の向上、トレーニングの収束性とパフォーマンスを向上させる機能、そして最も重要であるユーザー體験とドキュメントの大幅な改善が盛り込まれています。
PhysicsNeMo コンテナーの最新バージョンは、DevZone または、NGC からダウンロードするか、GitLab 上の PhysicsNeMo リポジトリにアクセスすることができます。
ニューラル ネットワーク アーキテクチャ
このアップデートでは、Fourier Neural Operator (FNO)、physics-informed neural operator (PINO)、および DeepONet ネットワーク アーキテクチャの実裝を拡張し、PhysicsNeMo に実裝されている他のネットワークを用いたカスタマイズをサポートするようにしました。より具體的には、このアップデートで以下のことが可能になります。
- FNO、PINO、DeepONet アーキテクチャの改善により、より優れた初期化、カスタマイズ、問題間の汎化を実現します。
- Sirens、Fourier Feature networks、Modified Fourier Feature networks のような、PhysicsNeMo に実裝されている任意の point-wise ネットワークを FNO/PINO のデコーダー部分にを採用し、スペクトル エンコーダーと組み合わせることにより、新しいネットワーク構成を探求することができます。
- DeepONet の branch net と trunk net に任意のネットワークを使用して、幅広いアーキテクチャを試すことができます。これには、trunk net への physics-informed neural networks (PINN) の適用が含まれます。FNO は、DeepONet の branch net でも使用することができます。
- 多孔質媒體を流れるダルシー流れをモデリングするための新しい DeepONet の例で、DeepONet の改善を実証します。
モデル並列がベータ機能として導入され、モデル並列 AFNO が実裝されました。これにより、チャネル次元に沿って複數の GPU でモデルを並列化することができます。この分解により、FFT と IFFT が高度に並列化されます。行列の乗算は、各 GPU が各 MLP 層の重みの異なる部分を保持するように分割され、順伝播、逆伝播パスに対して適切な gather、scatter、reduction、その他の通信ルーチンが実裝されます。
さらに、self-scalable tanh (Stan) 活性化関數がサポートされました。Stan は、PINN 學習モデルにおいて、より優れた収束特性を示し、精度を向上させることが知られています。
最後に、PyTorch の勾配計算方法の変更に伴い、TorchScript による Sigmoid Linear Unit (SiLU) のカーネル融合のサポートが追加されました。これは physics-informed な學習において高次導関數を計算する必要がある問題で特に有用で、そのような例では最大 1.4 倍のスピードアップを提供します。
モデリング機能強化およびトレーニング機能
NVIDIA PhysicsNeMo の各リリースでは、トレーニングの収束性を向上させるとともに、偏微分方程式 (PDE: Partial Differential Equations) をニューラル ネットワーク モデルにより良くマッピングできるよう、モデリング面を改善しています。
PhysicsNeMo の新しい推奨プラクティスは、PDE のスケーリングと無次元化を促進し、システムの単位を適切にスケーリングするために利用可能です。
- 物理量を値と単位で定義する
- 無次元化されたオブジェクトをインスタンス化し、量をスケーリングする
- 代數的操作を行う際にも、無次元化された量を追跡する
- 無次元化された量を、ユーザーが指定した任意の単位、量にスケールバックし、後処理に利用する
また、SETS (Selective Equations Term Suppression) により、システム內の異なるスケールを効果的に処理する機能も追加されました。これにより、同じ PDE の異なるインスタンスを作成し、PDE 內の特定の項をフリーズさせることができます。そうすることで、小さいスケールでの損失が最小限に抑えられ、PINN における stiff PDE での収束が改善されます。
さらに、新しい PhysicsNeMo API により、合計損失や個別の損失、あるいはその他のメトリックなどの収束條件に基づいた學習の終了など、Hydra の YAML ファイルを通して、エンドユーザーが指定できるようになりました。
新しい causual weighting スキームは、過渡問題に対して物理的因果関係に違反する連続時間 PINN が內包するバイアスに対処します。殘差と初期條件に対する損失を再定式化することで、動的システムに対する PINN の収束性と精度をより良くすることができます。
PhysicsNeMo トレーニングのパフォーマンス、スケーラビリティ、ユーザビリティ
NVIDIA PhysicsNeMo の各リリースは、トレーニングのパフォーマンスとスケーラビリティの向上に焦點を當てています。この最新リリースでは、PINN トレーニングにおけるより高速な勾配計算のために FuncTorch が PhysicsNeMo に統合されました。通常の PyTorch Autograd はリバース モード自動微分を使用し、ヤコビアンとヘシアン項を for ループで一行ずつ計算する必要があります。FuncTorch は不要な重み勾配計算を削除し、リバース モードとフォワード モードの自動微分を組み合わせてより効率的にヤコビアンとヘシアンを計算することができ、トレーニングのパフォーマンスを向上させることができるのです。
PhysicsNeMo v22.09 のドキュメントの改善は、新しいユーザーを支援するために、フレームワークのワークフローの主要な概念について、より多くの文脈と詳細を提供します。
Physics-driven のみ、data-driven のみ、そして physics-driven と data-driven 両方を組み合わせたモデリング アプローチに対応した、より多くのサンプルガイド付きワークフローにより、PhysicsNeMo の概要が強化されました。PhysicsNeMo ユーザーは、改良された導入例に従って、各ワークフローの主要なコンセプトの説明とともに、ステップバイステップでモデルを構築できるようになりました。
PhysicsNeMo のすべての機能についての詳細は、PhysicsNeMo ユーザー ガイドと PhysicsNeMo 構成を參照してください。また、PhysicsNeMo GitLab リポジトリの一部としてフィードバックと貢獻を提供することもできます。
NVIDIA Deep Learning Institute の自習コース、「Introduction to Physics-Informed Machine Learning with PhysicsNeMo」をご覧ください。NVIDIA PhysicsNeMo の研究とブレイクスルーの詳細については、GTC 2022 の特集セッションにご參加ください。
翻訳に関する免責事項
この記事は、「Enhancing Digital Twin Models and Simulations with NVIDIA PhysicsNeMo v22.09」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の內容の正確性に関して疑問が生じた場合は、原典である英語の記事を參照してください。