This post is part of the Path Tracing Optimizations in Indiana Jones? series.
While adding a path-tracing mode to Indiana Jones and the Great Circle? in 2024, we used Shader Execution Reordering (SER), a feature available on NVIDIA GPUs since the NVIDIA GeForce RTX 40 Series, to improve the GPU performance.
To optimize the use of SER in the main path-tracing pass (TraceMain), we used the NVIDIA Nsight Graphics GPU Trace Profiler. What we found was that its RayGen shader was using a large number of ray-tracing (RT) live-state bytes, which was lowering the efficiency of SER. By using the Ray Tracing Live State tab in the GPU Trace Profiler, we identified some of the GLSL variables that caused RT live state bytes, and either eliminated them or reduced their sizes.
As a result, SER now saves 24% of GPU time on the TraceMain pass in the profiled scene below on an NVIDIA GeForce RTX 5080 GPU.
The profiled scene

All of the data in this post is captured from the first moment of gameplay of Indiana Jones and the Great Circle? on a GeForce RTX 5080 GPU, with the graphics settings from Table 1.
| Setting | Value |
| Output Resolution | 4K UHD (3840 x 2160) |
| DLSS Mode | DLSS Ray Reconstruction, Performance Mode |
| Graphics Preset | High |
| Path-Tracing Mode | Full Ray Tracing |
| Ray-Traced Lights | All Lights |
| Vegetation Animation Quality | Ultra |
This part of the game is happening in a jungle with a lot of dense, alpha-tested geometry. It is one of the most challenging locations to ray-trace. With DLSS-RR in performance mode and the output resolution set to 4K UHD (3840 x 2160), the path tracing is done in 1080p.
Starting point: 4.08 ms
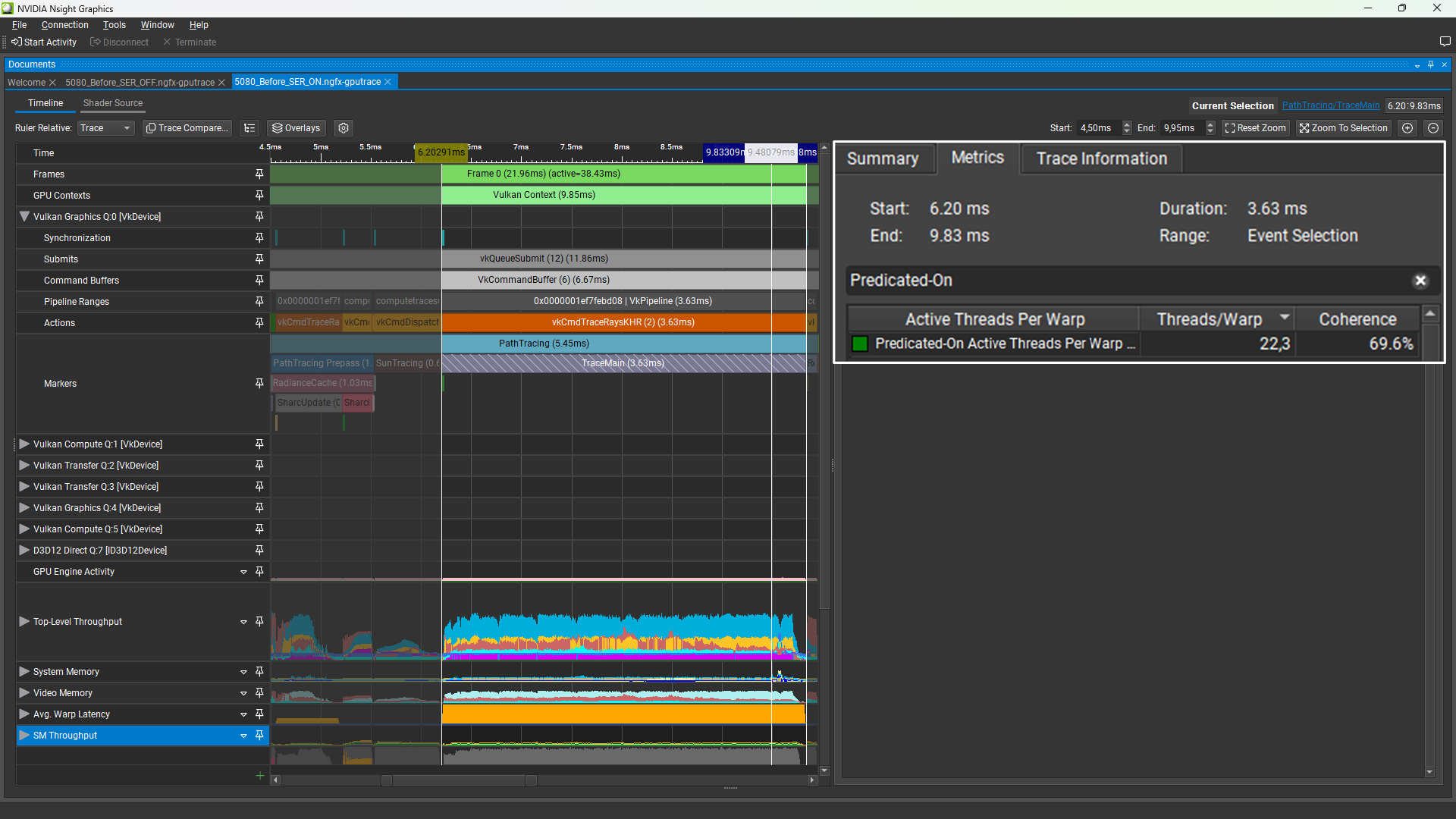
Figure 2 shows the TraceMain pass within the GPU Trace Profiler of Nsight Graphics.

As provided by GPU Trace, this cmdTraceRays workload had the following GPU metrics:
- GPU Time: 4.08 ms
- Predicated-On Active Threads per Warp: 38%
The Predicated-On Active Threads per Warp percentage metric is the average number of SIMT-active thread lanes by warp (32 lanes) per executed instructions at the SM level.
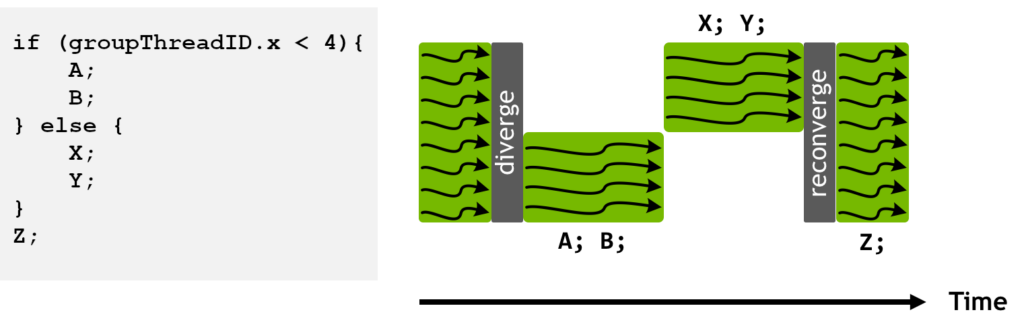
The following reasons can cause suboptimal percentages of active threads per warp:
- Dynamic loops with divergent loop counts within a warp
- Dynamic branches with divergent executed paths within a warp
- Different hit shaders getting invoked within a warp, in RayGen shaders
Figure 3 shows the reason a divergent dynamic branch increases the shader latency. For more information, see Optimize GPU Workloads for Graphics Applications with NVIDIA Nsight Graphics.
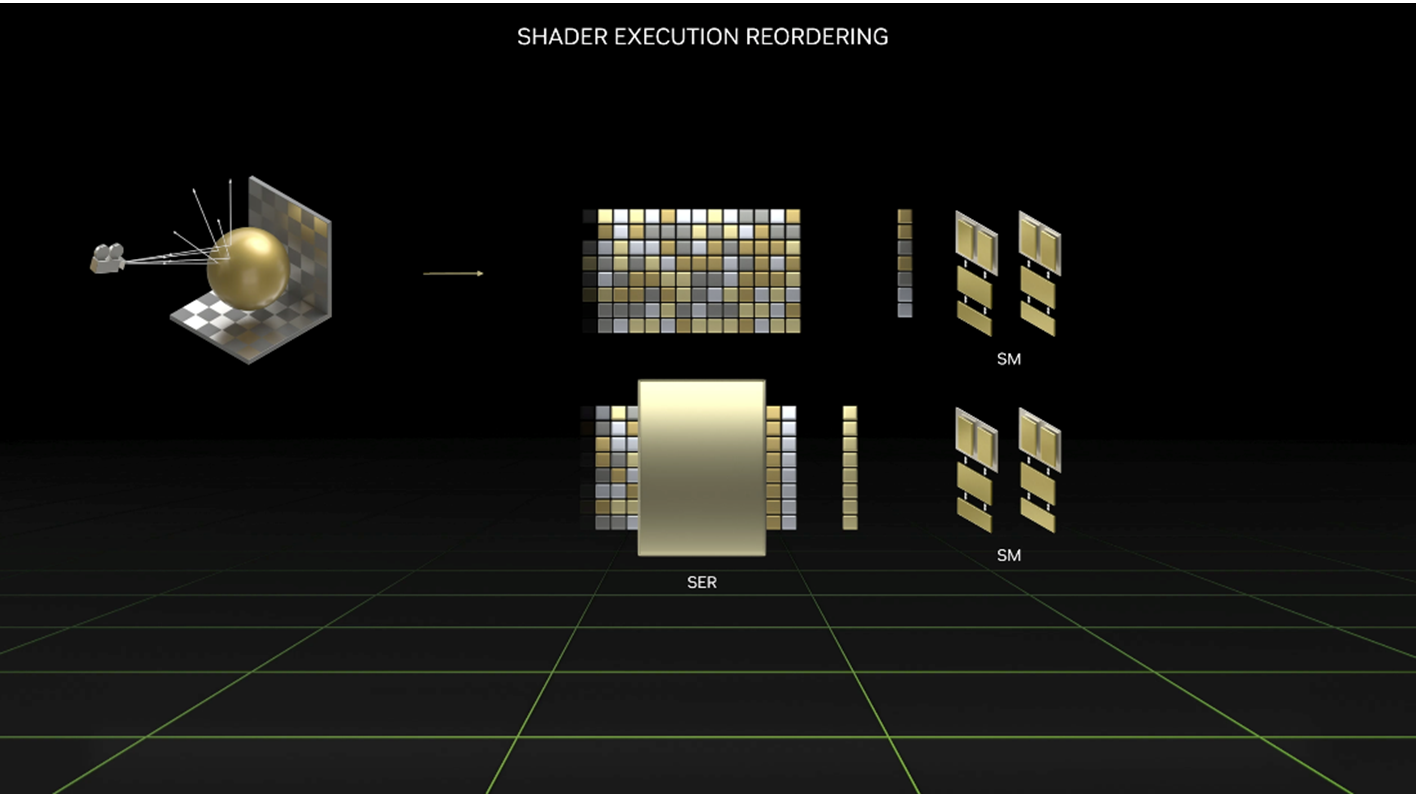
Shader Execution Reordering
For RayGen shaders, Shader Execution Reordering (SER) can be an effective way to increase the average percentage of active threads per warp. SER can be used to reorder the threads of a RayGen shader after a traceRay call, according to a key driven from the hit object and an optional user-provided coherence hint.
Invoking the hit shader or accessing hit-related data will be more coherent after the reorder call, as the threads with same or similar keys are grouped to execute together.
- For Vulkan, SER is exposed by the VK_NV_ray_tracing_invocation_reorder extension.
- For DX12, SER is now available in DXR 1.2 or through NvAPI.
SER was implemented in the engine by adding a shader permutation of the main path-tracing RayGen shader for the GPUs that support SER (GeForce RTX 40 and beyond), with the following GLSL code:
#if defined( RPF_RT_ENABLE_SER ) hitObjectNV hitObject; traceRayHitObject( hitObject, rayFlags, instanceMask , ray, rayPayload, topLevelAccelerationStructure ); reorderThreadNV( hitObject, bounceNum == ( bounceId + 1 ) ? 1 : 0 , 1 ); hitObjectExecuteShaderNV( hitObject, _hitPayloadIndex( rayPayload ) );#else traceRayEXT( rayFlags, instanceMask , ray, rayPayload, topLevelAccelerationStructure );#endif |
The coherence hint bounceNum == ( bounceId + 1 ) ? 1 : 0 is an implementation of the idea described in the original Shader Execution Reordering whitepaper: “A related situation can be found in path tracers or multi-bounce reflections. There, it is often highly effective to include in the coherence hint some additional information about whether the main loop will terminate.”
With SER: 3.63 ms
With the SER implementation, the TraceMain pass has become 11% cheaper (4.08 => 3.63 ms), and the average Predicated-On Active Threads per Warp metric has increased from 38% to 70% (Figure 4).
| SER OFF | SER ON | |
| GPU Time | 4.08 ms | 3.63 ms |
| Active Threads / Warp | 38% | 70% |
Ray-tracing live-state spills
Table 3 shows the GPU metrics so you can get a sense of what changed between the two traces:
| SER OFF | SER ON | |
| VidL2 Throughput | 58.3% | 85.6% |
| L1TEX Throughput | 30.6% | 43.0% |
| VidL2 Total from L1TEX | 9.22 GiB | 12.55 GiB |
Adding SER to a RayGen shader is actually expected to increase L2 traffic if a RayGen shader has a significant number of spilled ray-tracing live-state bytes with SER off. These are the local variables that the ray-tracing driver is saving to memory before a traceRay call, and then reloading after a traceRay call is complete, when continuing the execution of the RayGen shader.
With the presence of reorderThread, RT live-state spills can get more costly as the live-state data potentially must be transferred across the GPU by the SER implementation when reordering threads. The higher the number of RT live-state spilled bytes is at traceRay or reorderThread call sites, the more GPU overhead the live state can produce.
Ray Tracing Live State tab
Figure 5, from the GPU Trace Profiler, shows in the bottom-right area of the tool a section with summaries of the shader profiler data associated with the selected time range (the TraceMain pass in this case).

First, let’s drag the horizontal separator between the bottom-left and bottom-right sections of the tool all the way to the left, and choose the Ray Tracing Live State tab:

Figure 6 shows, for each RT call site (traceRay, reorderThread, or callable), the GLSL declarations of the variables that were declared before a RT call site and re-used after the call site, and for which the RT driver has performed live-state spilling around the call site (writing the value of the variable to memory before the call site, and reloading it after).
In this case, a total 222 bytes per thread were spilled to global memory for this RayGen shader.
Optimization 1: Loop removal
Now, let’s expand the information on callsite #2, to see the list of the GLSL lines that correspond to spilled RT live-state declarations:
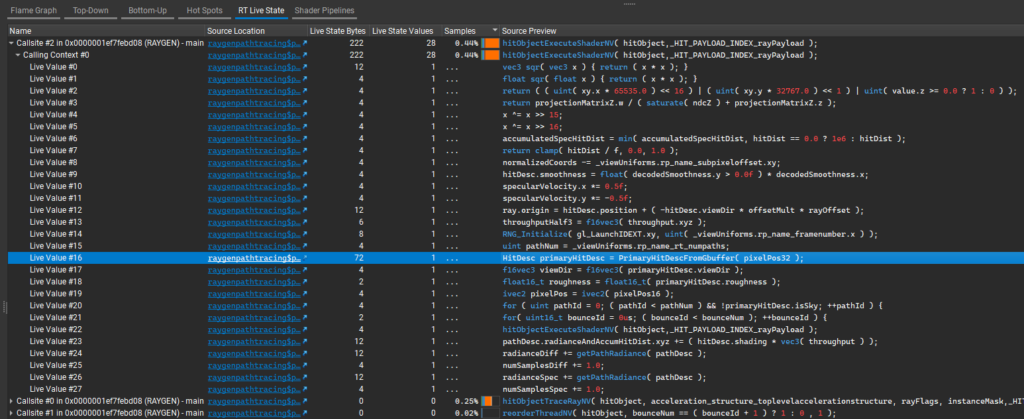
The largest entry in the list is:
HitDesc primaryHitDesc = PrimaryHitDescFromGbuffer( pixelPos32 ); |
This primaryHitDesc struct is initialized from GBuffer at the beginning of the RayGen, and its values are used to decide if and how the first ray should be traced.
But why are 72 bytes from this struct reused after the first traceRay call, given that it should only be used to set up that first ray? The RayGen had the following loop across paths, where PATHTRACE calls traceRayHitObject and reorderThreadNV in an inner loop internally:
for( uint pathId = 0; ( pathId < pathNum ) && !primaryHitDesc.isSky; ++pathId ) { PathOutputDesc pathDesc = PathOutputDescNull(); //... PATHTRACE( pixelPos, primaryHitDesc, bounceNum, pathDesc ); if( pathDesc.isValid == false ) { continue; } //... if( pathDesc.isDiffuse ) { hitDistanceDiff = normHitDist; radianceDiff += pathDesc.radiance; numSamplesDiff += 1.0; } else { NRD_FrontEnd_SpecHitDistAveraging_Add( hitDistanceSpec, normHitDist ); radianceSpec += pathDesc.radiance; numSamplesSpec += 1.0; }}radianceDiff /= max( 1.0, numSamplesDiff );radianceSpec /= max( 1.0, numSamplesSpec ); |
In the shipping game, pathNum is always 1, so this loop really is a branch. As a result, for each new iteration of the loop, the complete primaryHitDesc struct was spilled before the for loop, and reloaded at the start of each loop iteration. Because this loop really is a branch in practice, we rewrote it as such:
PathOutputDesc pathDesc = PathOutputDescNull();if ( !primaryHitDesc.isSky ) { //... PATHTRACE( pixelPos, primaryHitDesc, bounceNum, pathDesc, throughput ); //... if ( pathDesc.isValid ) { if( pathDesc.isDiffuse ) { hitDistanceDiff = normHitDist; radianceDiff += pathDesc.radiance; } else { NRD_FrontEnd_SpecHitDistAveraging_Add( hitDistanceSpec, normHitDist ); radianceSpec += pathDesc.radiance; } }} |
Changing the loop into an isSky branch removed the 72 bytes of spilled RT live state.
Optimization 2: Using FP16 Precision
The following GLSL line is listed in the Ray Tracing Live State tab from Figure 7:
pathDesc.radianceAndAccumHitDist.xyz |
This keeps track of the accumulated radiance per path:
pathDesc.radianceAndAccumHitDist.xyz += ( hitDesc.shading.xyz * throughput.xyz ); |
The radianceAndAccumHitDist variable was declared as a float4, which was overkill in this case. By demoting the precision of radianceAndAccumHitDist from float4 to half4 (f16vec4), which compiles to four FP16 values, the resulting RT live-state size for this four-dimensional vector was reduced by half, without affecting image quality.
Before and after RT live-state optimizations
With SER enabled, for the TraceMain pass, the RT live-state optimizations have reduced the RT live state reported in GPU Trace from 222 to 84 bytes, and the GPU time spent on that pass by 15% (3.63 => 3.08 ms) on an NVIDIA RTX 5080 GPU.
| With SER ON | Before | After |
| GPU Time | 3.63 ms | 3.08 ms |
| Active Threads / Warp | 70% | 68% |
| RT Live State Spilled | 222 bytes | 84 bytes |
Figure 8 shows the Before version with SER ON, at 222 bytes.

Figure 9 shows the After version with SER ON, at 84 bytes.

SER ON compared to SER OFF, after RT live-state optimizations
Before the RT live-state optimizations, enabling SER made the TraceMain pass 11% cheaper on a GeForce RTX 5080 GPU.
| Before | SER OFF | SER ON |
| RT Live State Spilled | 180 bytes | 222 bytes |
| GPU Time | 4.08 ms | 3.63 ms (-11%) |
| Active Threads / Warp | 38% | 70% |
Now, after having optimized the RT live state using the Nsight GPU Trace Profiler, let’s do another comparison of SER ON compared to SER OFF on that pass, with the same conditions as before, except for the differences in GLSL from the live-state optimizations.
| After | SER OFF | SER ON |
| RT Live State Spilled | 68 bytes | 84 bytes |
| GPU Time | 4.07 ms | 3.08 ms (-24%) |
| Active Threads / Warp | 38% | 68% |
Reducing the number of RT live-state spilled bytes in the GLSL made SER an even greater accelerator. After the RT live-state reduction optimizations, enabling SER saves 24% of GPU time in that pass.
Other RT live state optimizations
This post compares the performance of SER with two versions of the GLSL, before and after applying the RT live state optimizations:
- After: The shipping version of the GLSL from December 2024, with all optimizations.
- Before: The After version with the two optimizations reverted (loop removal, and using FP16 precision for
radianceAndAccumHitDist).
In reality, we implemented additional RT live-state optimizations in the GLSL of the TraceMain pass, which are part of the After version, but were not reverted for generating the Before state for this post:
- The RGB throughput vector of the path tracer was a
float3. Changing it to ahalf3helped and looked the same. - The
bounceIdandbounceNumvariables of the bounce loop were 32-bit integers. Making themuint16_thelped. (uint8_twould have been possible, too.) - The ray direction in the bounce loop body was a
float3. Packing it into auint32_thelped and looked the same. - Moving the signal demodulation from the end of the RayGen to a subsequent pass helped, by removing dependencies on
GBuffermaterial data.
All of these optimizations were implemented in time for the initial release of the path-tracing mode of the game.
Conclusion
In RayGen shaders that have a poor percentage of average active threads per warp, adding SER can produce significant speedups with minimal code changes. Reducing the number of RT live-state spilled bytes reported in the Nsight Graphics GPU Trace Profiler can make SER an even greater accelerator.
In HLSL, declaring a floating-point variable as FP16 can be done using DXC and Shader Model 6.2 or later, and this explicit HLSL type: float16_t. For more information, see Half The Precision, Twice The Fun: Working With FP16 In HLSL.
The next post in this series, Path Tracing Optimizations in Indiana Jones?: Opacity Micro-Maps and Compaction of Dynamic BLASs, covers using Opacity MicroMaps (OMMs) as an effective way to speedup traceRay calls (or rayQuery objects) in scenes with alpha-tested materials, as well as compacting the BLASs of the dynamic vegetation to save VRAM.
Acknowledgements
We would like to thank all of the people from NVIDIA and MachineGames who made it possible to ship Indiana Jones and the Great Circle? with path tracing on December 9 2024:
MachineGames: Sergei Kulikov, Andreas Larsson, Marcus Buretorp, Joel de Vahl, Nikita Druzhinin, Patrik Willbo, Markus ?lind, Magnus Auvinen, Jim Kjellin, Truls Bengtsson, Jorge Luna (MPG).
NVIDIA: Ivan Povarov, Juho Marttila, Jussi Rasanen, Jiho Choi, Oleg Arutiunian, Dmitrii Zhdan, Evgeny Makarov, Johannes Deligiannis, Fedor Gatov, Vladimir Mulabaev, Dajuan Mcdaniel, Dean Bent, Jon Story, Eric Reichley, Magnus Andersson, Pierre Moreau, Rasmus Barringer, Michael Haidl, Martin Stich.