隨著全球每個人可用的數據量不斷增加,消費者做出明智決策的能力也越來越難。幸運的是,對于推薦系統而言,大型數據集是一個非常有用的組件,有時這會讓某些情況下的決策變得更加容易。
對于為推薦系統提供支持的數據中固有的關系建模而言,圖形是一個很好的選擇,而 NetworkX 是許多數據科學家在 Python 中進行圖形分析時非常喜歡的選擇。NetworkX 易于學習和使用,擁有各種圖形算法,并由龐大而友好的社區提供支持,并且在 Notebook、文檔、Stack Overflow 和您喜歡的 LLM 中提供了大量示例。然而,令無數開發人員失望的是,他們使用 NetworkX 或甚至因為 NetworkX 而涉足圖形分析,但眾所周知,它在典型推薦系統使用的規模上的性能表現不佳。
這就引出了一個問題:能否用 Python 的幾行簡單代碼編寫有效的基于圖形的推薦系統?更一般地說,開發者和數據科學家能否同時進行易于使用的高性能圖形分析?
這兩個問題的答案都是“Yes”
請繼續閱讀,了解如何使用 NetworkX、Jaccard Similarity 算法和 NVIDIA cuGraph 后端 (可將現代大規模圖形數據所需的速度提高 250 倍以上),在 Python 中創建簡單有效的推薦系統,使用 3300 萬條電影評論的數據集。
MovieLens 數據集?
我們先從系統中最重要的部分開始:數據。MovieLens 數據集 1 可供公開 下載 , README 文件 中有更詳細的說明。該系列包括大約 331k 匿名用戶,他們在觀看 87k 部電影,獲得了 34M 的評分。

從數據中提取建議:二分圖和 Jaccard Similarity
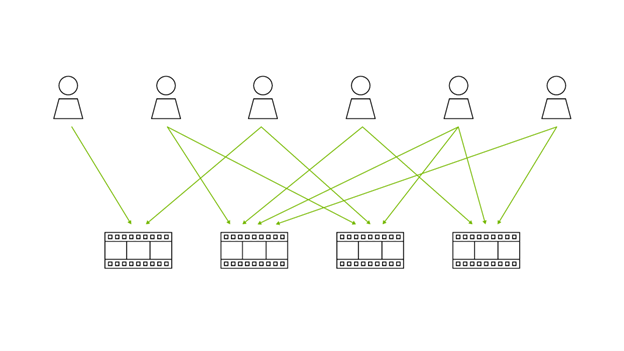
我們根據 MovieLens 數據創建的圖形類型是二部圖,因為只有兩種類型的節點:電影節點和用戶節點,并且評論(邊緣)只能在用戶和電影之間發生。這使得應用 Jaccard Similarity 算法來查找電影之間的相似性變得特別容易。Jaccard Similarity 比較節點對,并使用它們在圖形中的關系計算相似性系數。在這種情況下,電影根據用戶選擇的觀看和審查方式相互關聯。

NetworkX 可以輕松處理較小的圖形
不足為奇的是,NetworkX 支持我們上述的分析類型,而且只需使用幾行 Python 代碼即可輕松查看結果。但正如我們將看到的,當使用無 GPU 加速的 cuGraph 后端的 NetworkX 時,大型圖形 (例如我們的電影推薦系統所需的圖形) 的性能會受到限制。
我們將在下方查看推薦系統的關鍵部分,但可在 此處 獲取完整源代碼。
由于我們使用的 Jaccard Similarity 算法未考慮邊緣權重,因此會將所有評論視為相同。我們不希望推薦好評度低的電影,因此我們會過濾掉某個值下的所有好評度,這會導致圖形也變小。
# Create a separate DataFrame containing only "good" reviews (rating >= 3).good_ratings_df = ratings_df[ratings_df["rating"] >= 3]good_user_ids = good_ratings_df["userId"].unique()good_movie_ids = good_ratings_df["movieId"].unique() |
如果我們打印正在處理的數據的大小,我們會看到好評圖大約有 330k 個節點,28M 個邊緣,平均度數 (每個節點的近鄰數) 為 84:
total number of users: 330975
total number of reviews: 33832162
average number of total reviews/user: 102.22
total number of users with good ratings: 329127
total number of good reviews: 27782577
average number of good reviews/user: 84.41
如上所述,這種規模的圖形通常會給 NetworkX 帶來挑戰,但使用 cuGraph 后端的 GPU 加速消除了通常與如此多的數據相關的性能限制。不過,我們將繼續使用 CPU 環境來演示默認性能。
注意 以下所有示例均在使用 NetworkX 3.4.2 和 Intel(R) Xeon(R) Platinum 8480CL@2.0GHz(2TB RAM)的工作站上運行
使用由用戶創建的 NetworkX 圖形和優秀的電影評論,我們來選擇一個用戶,找到他們評分最高的電影之一,并使用 Jaccard Similarity 找到類似的其他電影。
# Pick a user and one of their highly-rated moviesuser = good_user_ids[321]user_reviews = good_user_movie_G[user]highest_rated_movie = max( user_reviews, key=lambda n: user_reviews[n].get("rating", 0)) |
當我們在電影名稱貼圖中查找節點 ID 時,我們會發現該用戶評分最高的電影之一是動畫電影“Mulan”:
highest rated movie for user=289308 is Mulan (1998), id: 1907, rated: {'rating': 5.0}
我們現在可以使用 Jaccard Similarity 根據用戶的偏好和觀看歷史記錄來推薦電影:
%%time# Run Jaccard Similarityjacc_coeffs = list(nx.jaccard_coefficient(good_user_movie_G, ebunch)) |
CPU times: user 2min 5s, sys: 15.4 ms, total: 2min 5s
Wall time: 2min 14s
使用默認 NetworkX 實現的 Jaccard 相似性計算運行了兩分鐘以上。根據這些結果,我們現在可以提供推薦。
# Sort by coefficient value, which is the 3rd item in the tuplesjacc_coeffs.sort(key=lambda t: t[2], reverse=True) # Create a list of recommendations ordered by "best" to "worst" based on the# Jaccard Similarity coefficients and the movies already seenmovies_seen = list(good_user_movie_G.neighbors(user))recommendations = [mid for (_, mid, _) in jacc_coeffs if mid not in movies_seen] |
現在,我們只需在已排序的推薦列表中打印出第一部電影:
User ID 289308 might like Tarzan (1999) (movie ID: 2687)
代碼很簡單,結果看起來不錯,但性能卻拖累了我們
如我們所見,這個推薦似乎是合理的;喜歡“Mulan”的人似乎也喜歡 1999 年的迪士尼動畫電影“Tarzan”。
但是,如果我們的目標是提供服務,或分析數百乃至數千部電影,那么兩分鐘的運行時間就能讓我們開始尋找 NetworkX 的替代方案。我們可以看到,使用此系統查找其他電影相似點的速度并沒有加快:
%%time# 1196: "Star Wars: Episode V - The Empire Strikes Back (1980)"print_similar_movies(1196) |
movies similar to Star Wars: Episode V - The Empire Strikes Back (1980):
movieId=260, Star Wars: Episode IV - A New Hope (1977)
movieId=1210, Star Wars: Episode VI - Return of the Jedi (1983)
movieId=1198, Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981)
CPU times: user 13min 47s, sys: 71.8 ms, total: 13min 47s
Wall time: 11min 30s
%%time# 318: "Shawshank Redemption, The (1994)"print_similar_movies(318) |
movies similar to "Shawshank Redemption, The (1994)":
movieId=296, Pulp Fiction (1994)
movieId=593, "Silence of the Lambs, The (1991)"
movieId=356, Forrest Gump (1994)
CPU times: user 28min 28s, sys: 172 ms, total: 28min 28s
Wall time: 16min 49s
鑒于此系統僅由幾行代碼組成,因此所返回的推薦內容的質量令人印象深刻。但是,運行時性能使其幾乎無法使用。如上所述,根據“Shawshank Redemption, The (1994)”查找推薦內容大約需要 17 分鐘。
NVIDIA cuGraph 使其變革性地加快
上述工作流程中的圖形算法成本高昂,但通過使用 NVIDIA cuGraph 后端和兼容的 GPU,我們可以在不更改代碼的情況下顯著提高性能。
nx-cugraph 版本 25.02 或更高版本支持 Jaccard Similarity。版本 25.02 可在 nightly builds 中使用,并將于本月晚些時候納入未來的穩定版本中。有關如何使用 conda 或 pip 從 nightly 和 stable 通道安裝 nx-cugraph 以及其他 RAPIDS 包的說明,請參閱 RAPIDS Installation Guide 。
安裝后,只需設置環境變量即可啟用 nx-cugraph:
NX_CUGRAPH_AUTOCONFIG=True
cuGraph 利用 GPU 顯著加速近鄰查找,并設置 Jaccard 相似性計算所需的比較結果。此外,隨著圖形規模以及每部電影的電影和評論數量的增加,性能幾乎保持不變。
該系統最優秀的部分,即代碼的簡單性,并沒有改變,結果也是一樣的,但在過去近 17 分鐘的運行中,性能提高了 250 倍以上,縮短到 4 秒以內。

結束語?
這篇博文介紹了一個簡單而有效的推薦系統,它可以使用 NetworkX 輕松地用 Python 編寫。雖然我們可以采用許多其他方法(如此處所述),但很少有方法能夠做到與開始探索 NetworkX 圖形分析提供的數據所需的工作量不相上下。然而,高效和有意義的數據探索需要快速的周轉,而 NetworkX 傳統上一直難以擴展到更大的實際問題規模。
適用于 NetworkX 的 NVIDIA cuGraph 后端可對熟悉且靈活的 NetworkX API 進行加速,還可大規模提升其性能,在幾秒鐘 (而非數十分鐘) 內生成結果,從而讓您專注工作并高效工作。現在,用戶只需向環境中添加 GPU 和 cuGraph 后端,即可繼續使用熱門的圖形分析庫 NetworkX,而無需擔心擴展問題。
如需了解有關使用 NetworkX 和 NVIDIA cuGraph 進行加速圖形分析的更多信息,請訪問 https://rapids.ai/nx-cugraph 。
?