這是標準并行編程系列的第四篇文章,旨在指導開發人員在標準語言中使用并行來加速計算的優勢:
標準語言已經開始添加編譯器可用于加速 GPU 和 CPU 并行編程的功能,例如 Fortran 中的do concurrent循環和數組數學內部函數。
使用標準語言特性有許多優點,主要優點是未來的可驗證性。由于 Fortran 的do concurrent是一種標準語言功能,因此將來失去支持的可能性很小。
這個特性在初始代碼開發中使用起來也相對簡單,并且增加了可移植性和并行性。在初始代碼開發中使用do concurrent有助于鼓勵您在編寫和實現循環時從一開始就考慮并行性。
對于初始代碼開發,do concurrent是添加 GPU 支持的好方法,無需學習指令。然而,即使是已經通過使用 OpenACC 和 OpenMP 等指令進行 GPU 加速的代碼,也可以從重構到標準并行性中獲益,原因如下:
- 為那些不懂指令的人清理代碼,或者刪除大量使源代碼分心的指令。
- 在供應商支持和支持壽命方面提高代碼的可移植性。
- 該代碼經得起未來考驗,因為 ISO 標準語言在穩定性和可移植性方面有著可靠的記錄。
替換多核 CPU 和 GPU 上的指令
POT3D 是一個 Fortran 代碼,它使用表面場觀測值作為輸入,計算勢場解以近似太陽日冕磁場。它繼續被用于日冕結構和動力學的大量研究。
該代碼使用 MPI 進行高度并行化,并使用 MPI 和 OpenACC 進行 GPU 加速。 它是開源的,在 GitHub 上可用 。它也是 SPEHPC 2021 基準套件 的一部分。
我們最近于 2021 于 WACCPD 舉辦了 使用 do concurrent 重構了另一個代碼示例 。結果表明,可以用do concurrent替換指令,而不會損失多核 CPU 和 GPU 上的性能。然而,該代碼有點簡單,因為沒有 MPI 。
現在,我們想探索在更復雜的代碼中替換指令。 POT3D 包含標準 Fortran 并行處理的重要功能:縮減、原子、 CUDA-aware MPI 和本地堆棧數組。我們想看看do concurrent 是否可以替換指令并保持相同的性能。
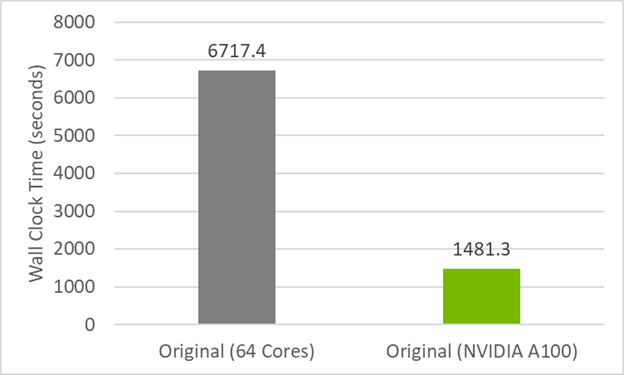
為了建立將代碼重構為do concurrent的性能基線,首先查看圖 1 中原始代碼的初始計時。 CPU 結果在雙插槽 AMD EPYC 7742 服務器上的 64 個 MPI 列組(每個插槽 32 個)上運行,而 GPU 結果在 NVIDIA A100 ( 40GB )服務器上的一個 MPI 列組上運行。 GPU 代碼依賴于數據傳輸的數據移動指令(此處不使用托管內存),并使用 -acc=gpu -gpu=cc80、cuda11.5編譯。運行時間是四次運行的平均值。
以下突出顯示的文本顯示了當前版本代碼的代碼行數和指令。您可以看到有 80 條指令,但我們希望通過使用do concurrent重構來減少這一數字。
| ? | POT3D (Original) |
| Fortran | 3,487 |
| Comments | 3,452 |
| OpenACC Directives | 80 |
| Total | 7,019 |
執行并發和 OpenACC
以下是一些與代碼 POT3D 中的 OpenACC 相比的do concurrent 示例,例如三層嵌套的 OpenACC 并行循環:
!$acc enter data copyin(phi,dr_i)
!$acc enter data create(br)
…
!$acc parallel loop default(present) collapse(3) async(1)
do k=1,np do j=1,nt do i=1,nrm1 br(i,j,k)=(phi(i+1,j,k)-phi(i,j,k))*dr_i(i) enddo enddo
enddo
…
!$acc wait
!$acc exit data delete(phi,dr_i,br)如前所述,此 OpenACC 代碼使用標志-acc=gpu -gpu=cc80、cuda11.5進行編譯,以在 NVIDIA GPU 上運行。
您可以使用 do concurrent 并行化這個相同的循環,并依賴于 NVIDIA CUDA 統一內存 用于數據移動,而不是指令。這將產生以下代碼:
do concurrent (k=1:np,j=1:nt,i=1:nrm1) br(i,j,k)=(phi(i+1,j,k)-phi(i,j,k ))*dr_i(i)
enddo如您所見,循環已從 12 行壓縮為 3 行,而 CPU 中的 nvfortran 編譯器保留了 CPU 的可移植性和 HPC SDK NVIDIA 的并行性
行數的減少得益于將多個循環壓縮為一個循環,并依賴于托管內存,這將刪除所有數據移動指令。使用cuda11.5、cuda11.5為 GPU 編譯此代碼。
對于 nvfortran ,激活標準并行(-stdpar=gpu)會自動激活托管內存。要使用 OpenACC 指令和do concurrent控制數據移動,請使用以下標志:-acc=gpu -gpu=nomanaged。
do concurrent 的 nvfortran 實現還允許定義變量的位置:
do concurrent (k=1:N, j(i)>0) local(M) shared(J,K) M = mod(K(i), J(i)) K(i) = K(i)- M
enddo這對于某些代碼可能是必要的。對于 POT3D ,變量的默認位置將根據需要執行。默認位置與使用 nvfortran 的 OpenACC 相同。
并行執行 CPU 性能和 GPU 實現
用do concurrent 替換所有 OpenACC 循環,并依靠托管內存進行數據移動,這會導致代碼中的指令為零,行數更少。我們刪除了 80 條指令和 66 行 Fortran 。
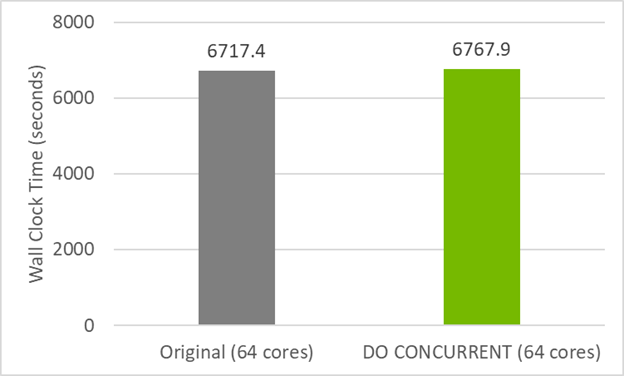
圖 2 顯示了此代碼的do concurrent 版本在 CPU 上的性能與原始 GitHub 代碼幾乎相同。這意味著您沒有通過使用 do concurrent 破壞 CPU 兼容性。相反,還添加了多核并行,可以通過使用標志-stdpar=multicore進行編譯來使用。
與 CPU 不同,要在 GPU 上運行 POT3D ,必須添加幾個指令。
首先,要利用 MPI 的多個 GPU ,需要一個指令來指定 GPU 設備編號。否則,所有 MPI 級別將使用相同的 GPU 。
!$acc set device_num(mpi_shared_rank_num)在本例中,mpi_shared_rank_num是節點內的 MPI 等級。假設啟動代碼時,每個節點的 MPI 列組數與每個節點的 GPU 數相同。這也可以通過為每個 MPI 列組設置CUDA_VISIBLE_DEVICES來實現,但我們更喜歡通過編程實現。
將托管內存與多個 GPU 一起使用時,請確保在分配任何數據之前完成設備選擇(如!$acc set device_num(N))。否則,將創建額外的 CUDA 上下文,從而引入額外的開銷。
目前, nvfortran 編譯器不支持并行循環上的數組縮減,這在代碼的兩個位置都是必需的。幸運的是,可以使用 OpenACC 原子指令代替數組縮減:
do concurrent (k=2:npm1,i=1:nr)
!$acc atomic sum0(i)=sum0(i)+x(i,2,k)*dph(k )*pl_i
enddo添加此指令后,使用-stdpar=gpu -acc=gpu -gpu=cc80、cuda11.5更改編譯器選項以顯式啟用 OpenACC 。這只允許您使用三條 OpenACC 指令。這是該代碼目前最接近沒有指令的情況。
所有數據移動指令都是不必要的,因為所有數據結構都使用了 CUDA 托管內存。表 2 顯示了此版本 POT3D 所需的指令數和代碼行數。
| ? | POT3D (Original) | POT3D (Do Concurrent) | Difference |
| Fortran | 3487 | 3421 | (-66) |
| Comments | 3452 | 3448 | (-4) |
| OpenACC Directives | 80 | 3 | (-77) |
| Total | 7019 | 6872 | (-147) |
對于 POT3D 中的歸約循環,您依賴于隱式歸約,但這可能并不總是有效的。最近, nvfortran 添加了即將推出的 Fortran 202X reduce 子句,該子句可用于還原循環,如下所示:
do concurrent (k=1:N) reduce(+:cgdot) cgdot=cgdot+x(i)*y(i)
enddoGPU 性能、統一內存和數據移動
您已經用最少數量的 OpenACC 指令和依賴托管內存進行數據移動的do concurrent 開發了代碼。這是目前最接近的無指令代碼。
圖 3 顯示,與原始 OpenACC GPU 代碼相比,此代碼版本的性能下降了約 10% 。造成這種情況的原因可能是do concurrent , 托管內存或兩者的組合。
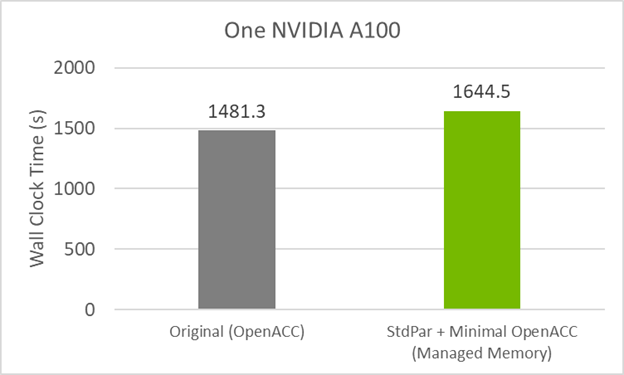
要查看托管內存是否會導致較小的性能損失,請在啟用托管內存的情況下編譯原始 GitHub 代碼。這是通過在 GPU 之前使用的標準 OpenACC 標志之外使用編譯標志-gpu=managed來實現的。
圖 4 顯示了 GitHub 代碼現在在托管內存中的性能與最小指令代碼類似。這意味著性能損失較小的罪魁禍首是統一內存。
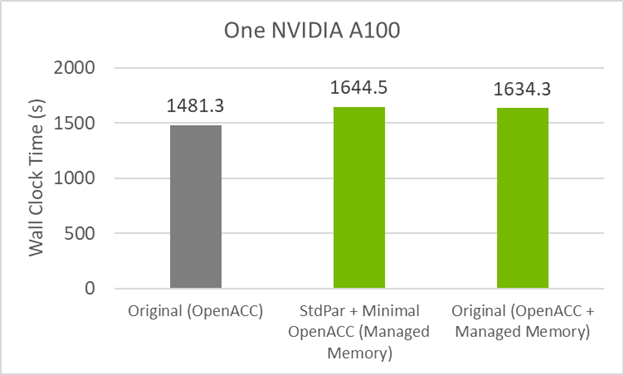
要用最少的指令代碼恢復原始代碼的性能,必須將數據移動指令添加回。do concurrent和數據移動指令的組合如下代碼示例所示:
!$acc enter data copyin(phi,dr_i)
!$acc enter data create(br)
do concurrent (k=1:np,j=1:nt,i=1:nrm1) br(i,j,k)=(phi(i+1,j,k)-phi(i,j,k ))*dr_i(i)
enddo
!$acc exit data delete(phi,dr_i,br)這導致代碼有 41 條指令,其中 38 條負責數據移動。要編譯代碼并依賴數據移動指令,請運行以下命令:
-stdpar=gpu -acc=gpu -gpu=cc80,cuda11.5,nomanaged
nomanaged關閉托管內存,-acc=gpu打開指令識別。
圖 5 顯示了與原始 GitHub 代碼幾乎相同的性能。此代碼的指令比原始代碼少 50% ,并提供相同的性能!
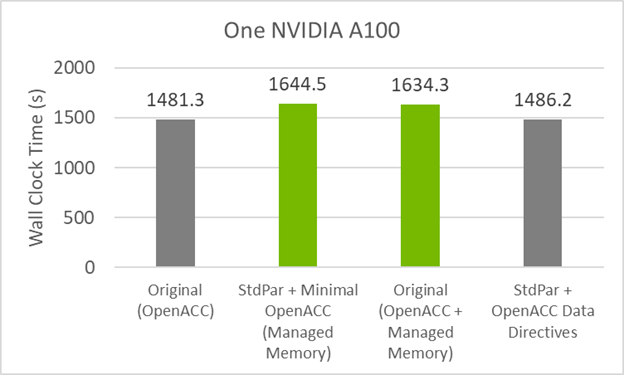
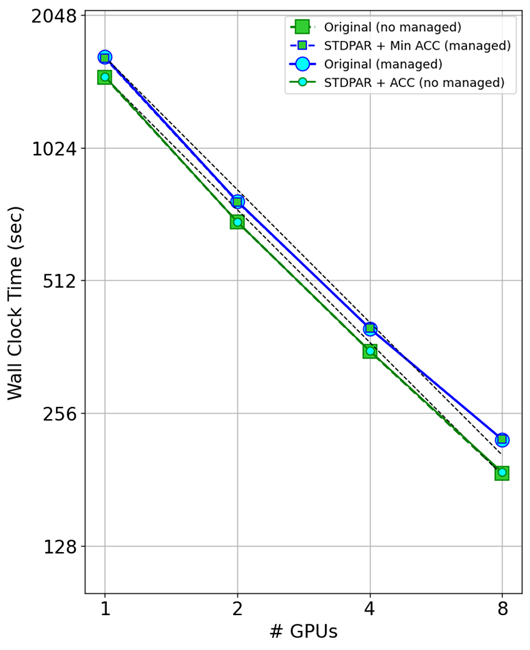
MPI + DO 并行擴展
圖 7 顯示了使用多個 GPU 的計時結果。主要的收獲是do concurrent在多個 GPU 上與 MPI 一起工作。
查看打開托管內存的代碼(藍線),可以看到原始代碼和最小指令代碼的性能與使用多個 GPU 的性能幾乎相同。
查看關閉托管內存的代碼(綠線),您可以再次看到原始 GitHub 代碼和代碼的do concurrent版本之間的相同比例。這表明do concurrent可以與 MPI 一起工作,并且對您應該看到的縮放沒有影響。
您可能還注意到,隨著 GPU 的擴展,托管內存會導致開銷。受管內存運行(藍線)和數據指令線(綠線)彼此平行,這意味著開銷隨著 GPU 的數量而變化。
Fortran 標準并行編程綜述
您可能會想,“標準 Fortran 聽起來太好了,不可能是真的,有什么問題嗎?”
Fortran 標準并行編程支持更干凈的代碼,并通過依賴 ISO 語言標準提高代碼的未來證明性。使用最新的 nvfortran 編譯器,您可以獲得前面提到的所有好處。
雖然您在過渡到do concurrent時失去了當前的 GCC OpenACC / MP GPU 支持,但隨著其他供應商在 GPU 上增加對do concurrent的支持,我們預計將來會獲得更多的 GPU 支持。鑒于 ISO 語言標準的歷史記錄,我們相信這種支持會到來。
使用do concurrent目前確實存在一些限制,即缺乏對原子、設備選擇、異步或優化數據移動的支持。然而,正如我們所展示的,這些限制中的每一個都可以使用編譯器指令輕松解決。由于 Fortran 中的本機并行語言特性,所需的指令要少得多。
準備好開始了嗎? 下載免費的 NVIDIA HPC SDK ,然后開始測試!如果您還對我們的研究結果感興趣,請參閱 從指令到并行:標準并行的一個案例研究 GTC 課程。有關標準語言并行性的更多信息,請參閱 使用標準語言并行性開發加速代碼 。
確認書
這項工作得到了國家科學基金會、 NASA 和空軍科學研究辦公室的支持。計算資源由圣地亞哥州立大學計算科學資源中心提供 .
?