
生成式人工智能開啟了一個新的計算時代,這個時代有望徹底改變人機交互。這一技術的前沿是大語言模型 (LLMs),它使企業能夠使用大型數據集進行識別、匯總、翻譯、預測和生成內容。然而,生成式人工智能對企業的潛力也伴隨著相當多的挑戰。
由通用 LLM 提供的云服務提供了一種快速入門生成人工智能技術的方法。然而,這些服務通常專注于一系列廣泛的任務,而不是針對特定領域的數據進行培訓,這限制了它們對某些企業應用程序的價值。這導致許多組織構建自己的解決方案——這是一項艱巨的任務——因為他們必須將各種開源工具拼湊在一起,確保兼容性,并提供自己的支持。
NVIDIA NeMo 提供了一個端到端平臺,旨在簡化企業 LLM 的開發和部署,開創人工智能能力的變革時代。NeMo 為您提供創建企業級、可生產的定制 LLM 的基本工具。NeMo 工具套件簡化了數據管理、培訓和部署過程,有助于根據每個組織的具體需求快速開發定制的人工智能應用程序。
對于依賴人工智能進行業務運營的企業, NVIDIA AI Enterprise 提供了一個安全的端到端軟件平臺。 NVIDIA AI enterprise 將 NeMo 與生成的人工智能參考應用程序和企業支持相結合,簡化了采用過程,為人工智能功能的無縫集成鋪平了道路。
面向生產的生成人工智能的端到端平臺
NeMo 框架通過為各種模型架構提供端到端功能和容器化配方,簡化了構建定制的企業級生成人工智能模型的途徑。
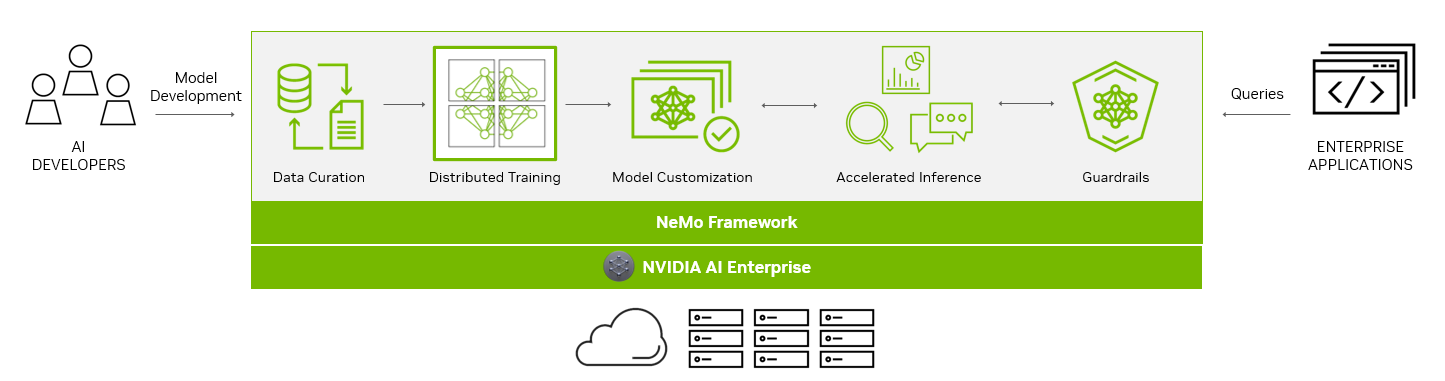
為了幫助您創建 LLM , NeMo 框架提供了強大的工具:
- 數據管理
- 大規模分布式培訓
- 用于定制的預訓練模
- 加速推理
- Guardrails
數據管理
在人工智能快速發展的環境中,對廣泛數據集的需求已成為構建強大 LLM 的關鍵因素。
NeMo 框架通過 NeMo Data Curator 解決了在多語言數據集中管理數萬億代幣的挑戰。該工具的可擴展性使您能夠輕松處理數據下載、文本提取、清潔、過濾以及精確或模糊重復數據消除等任務。
通過利用包括消息傳遞接口( MPI )、 Dask 和 Redis Cluster 在內的尖端技術的力量, Data Curator 可以在數千個計算核心中擴展數據管理過程,大大減少手動工作量并加快開發工作流程。
Data Curator 的主要優勢之一在于其重復數據消除功能。通過確保 LLM 是在唯一的文檔上進行培訓的,您可以避免冗余數據,并在預培訓階段實現可觀的成本節約。這不僅簡化了模型開發過程,還優化了組織的人工智能投資,使人工智能開發更容易實現,更具成本效益。
Data Curator 被包裝在 NeMo 培訓容器中,可以通過 NGC 獲取。
大規模分布式培訓
從頭開始訓練十億參數 LLM 模型在加速和規模方面提出了獨特的挑戰。這一過程需要巨大的分布式計算能力、基于加速的硬件和內存集群、可靠且可擴展的機器學習( ML )框架以及容錯系統。
NeMo 框架的核心是分布式訓練和高級并行性的統一。 NeMo 熟練地跨節點使用 GPU 資源和內存,帶來了突破性的效率提升。通過劃分模型和訓練數據, NeMo 實現了無縫的多節點和多 GPU 訓練,顯著減少了訓練時間,提高了整體生產力。
NeMo 的一個突出特點是它結合了各種并行技術:
- 數據并行性
- 張量平行度
- 管道平行度
- 序列并行性
- 稀疏注意力減少( SAR )。
這些技術協同工作以優化訓練過程,從而最大限度地利用資源并提高表現。
NeMo 還提供了一系列精度選項:
- FP32 / TF32
- BF16
- FP8
FlashAttention 和 Rotary Positional Embedding ( RoPE )等突破性創新可滿足長序列任務的需求。注意線性偏差( ALiBi )、梯度和部分檢查點以及分布式 Adam Optimizer 進一步提高了模型性能和速度。
用于定制的預訓練模
雖然一些生成性人工智能用例需要從頭開始進行培訓,但越來越多的組織正在使用預訓練模型來啟動他們構建定制 LLM 的工作。
預訓練模型最顯著的好處之一是節省了時間和資源。通過跳過預訓練通用 LLM 所需的數據收集和清理階段,您可以專注于根據其特定需求對模型進行微調,從而加快最終解決方案的時間。此外,基礎設施設置和模型訓練的負擔大大減輕,因為預訓練的模型具有預先存在的知識,可以進行定制。
您可以在如 GitHub,Hugging Face 等平臺上找到成千上萬的開源模型,因此在選擇開始的模型時,您有很多選擇。雖然準確性是評估預訓練模型的一種常見方法,但還有其他需要考慮的因素:
- 大小
- 微調成本
- 延遲
- 內存限制
- 商業許可選項
使用 NeMo,您現在可以訪問廣泛的預訓練模型,包括 NVIDIA 和流行的開源存儲庫,如 Falcon AI,Llama-2 和 MPT 7B。
NeMo 模型經過了推理優化,非常適合生產用例。有了在現實世界應用程序中部署這些模型的能力,您可以推動變革性成果,并為您的組織釋放人工智能的全部潛力。
模型自定義
ML 模型的定制正在迅速發展,以適應企業和行業的獨特需求。 NeMo 框架提供了一系列技術來為專門的用例細化通用的、預訓練的 LLM 。通過這些多樣化的定制選項, NeMo 提供了廣泛的靈活性,這對于滿足不同的業務需求至關重要。
Prompt engineering 是一種有效的定制方法,可以在許多下游任務中使用預訓練的 LLM,而無需調整預訓練模型的參數。提示工程的目標是設計和優化足夠具體和清晰的提示,以從模型中獲得所需的輸出。
P-tuning 和即時調整是參數有效微調(PETF)技術的一部分,它使用巧妙的優化策略來選擇性地只更新 LLM 的少數參數。如在 NeMo 中實現的那樣,可以將新任務添加到模型中,而不會覆蓋或中斷模型已經調整的先前任務。
NeMo 優化了其 p 調諧方法,用于多 GPU 和多節點環境,從而實現加速訓練。 NeMo p 調諧還支持一種“早期停止”機制,該機制可以識別模型何時收斂到進一步訓練不會大大提高精度的點。然后它停止了培訓工作。此技術減少了自定義模型所需的時間和資源。
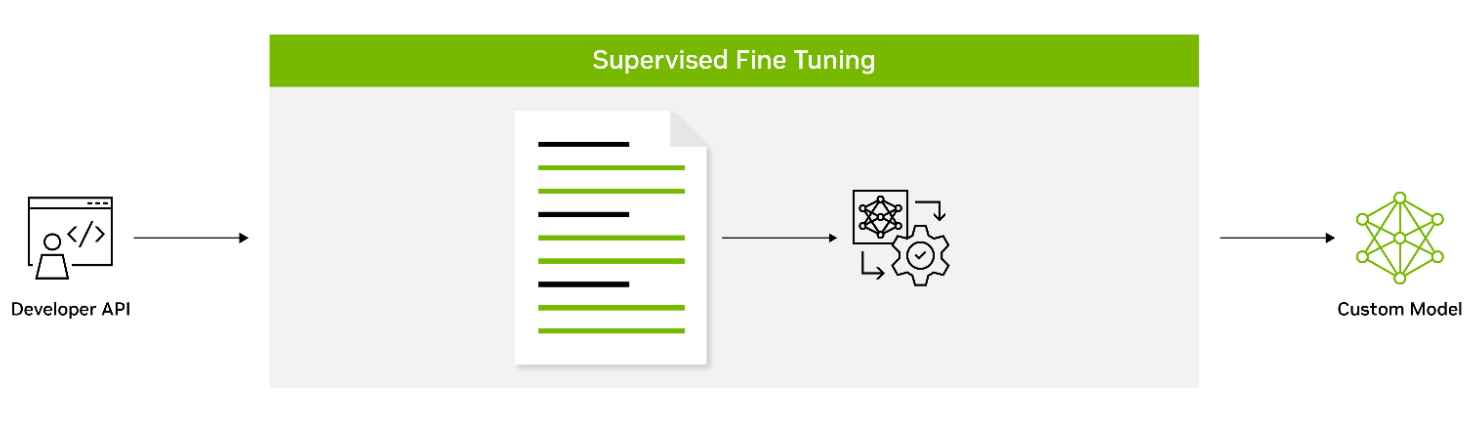
有監督的微調(SFT)涉及使用標記數據來微調模型的參數。這種方法也被稱為指令調整,通常在預訓練后進行。它提供了使用最先進的模型而不需要初始訓練的優勢,從而降低了計算成本并減少了數據收集要求。
Adapters 在模型的核心層之間引入了小的前饋層。然后,這些適配器層會針對特定的下游任務進行微調,從而提供針對當前任務需求的獨特定制級別。
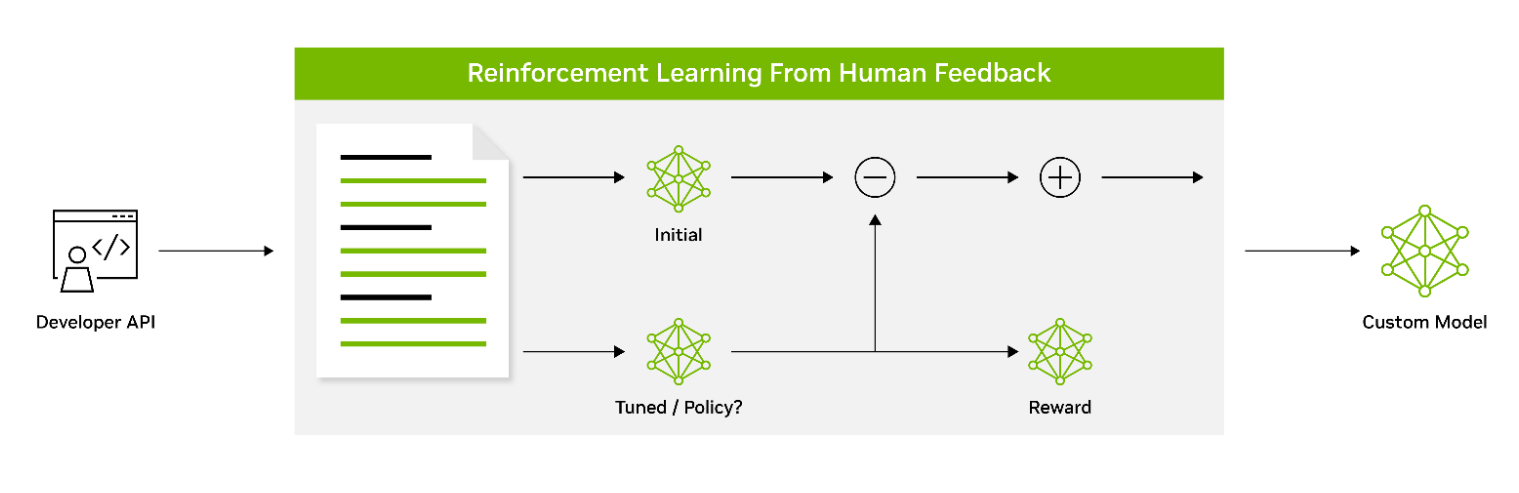
通過人類反饋進行強化學習( RLHF )采用了三階段的微調過程。該模型根據反饋調整其行為,以更好地與人類的價值觀和偏好保持一致。這使得 RLHF 成為創建能與人類用戶產生共鳴的模型的強大工具。
AliBi 使 transformer 模型能夠在推理時處理比訓練時更長的序列。這在處理信息較長或復雜的情況下特別有用。
NeMo Guardrails 有助于確保 LLM 支持的智能應用程序準確、適當、主題明確且安全。NeMo Guardrails 是開源的,包括企業為生成文本的人工智能應用程序添加安全性所需的所有代碼、示例和文檔。NeMo Guardrails 與 NeMo 以及所有 LLM 一起工作,包括 OpenAI 的 ChatGPT。
加速推理
NeMo 與 NVIDIA Triton Inference Server 的無縫集成顯著加快了推理過程,提供了卓越的準確性、低延遲和高吞吐量。這種集成有助于安全高效的部署,從單個 GPU 到大規模多節點 GPU ,同時遵守嚴格的安全和安保要求。
NVIDIA Triton 使 NeMo 能夠簡化和標準化生成人工智能推理。這使團隊能夠在任何基于 GPU 或 CPU 的基礎設施上從任何框架部署、運行和擴展經過訓練的 ML 或深度學習( DL )模型。這種高度的靈活性使您可以自由選擇最適合您的人工智能研究和數據科學項目的框架,而不會影響生產部署的靈活性。
Guardrails
作為 NVIDIA AI Enterprise software suite 的一部分,NeMo 使組織能夠放心地部署生產就緒的人工智能。組織可以利用長達 3 年的長期分支機構支持,確保無縫運營和穩定。定期的常見漏洞和暴露( CVE )掃描、安全通知和及時的補丁增強了安全性,而 API 的穩定性簡化了更新。
購買 NVIDIA AI Enterprise 軟件套件時會附帶 NVIDIA 人工智能企業支持服務。我們提供與 NVIDIA AI 專家的直接聯系、定義的服務級別協議,以及通過長期支持選項控制升級和維護時間表。
為企業級生成人工智能提供動力
作為 NVIDIA AI Enterprise 4.0 的一部分,NeMo 提供了跨多個平臺的無縫兼容性,包括云、數據中心,以及現在由 NVIDIA RTX 供電的工作站和 PC。這實現了真正的一次性開發和隨時隨地部署體驗,消除了集成的復雜性,并最大限度地提高了運營效率。
NeMo 在希望構建定制 LLM 的前瞻性組織中已經獲得了巨大的吸引力。Writer 和 Korea Telecom 已經接受了 NeMo ,并利用其能力推動其人工智能驅動的舉措。
NeMo 提供的無與倫比的靈活性和支持為企業打開了一個充滿可能性的世界,使他們能夠根據自己的特定需求和行業垂直領域設計、培訓和部署復雜的 LLM 解決方案。通過與 NVIDIA AI Enterprise 合作并將 NeMo 集成到其工作流程中,您的組織可以開啟新的增長途徑,獲得有價值的見解,并向客戶、客戶和員工提供尖端的人工智能應用程序。
開始使用 NVIDIA NeMo
NVIDIA NeMo 已成為一種改變游戲規則的解決方案,彌合了生成性人工智能的巨大潛力與企業面臨的現實之間的差距。作為 LLM 開發和部署的綜合平臺, NeMo 使企業能夠高效、經濟地利用人工智能技術。
有了這些強大的能力,企業可以將人工智能集成到運營中,簡化流程,增強決策能力,并開啟新的增長和成功途徑。
了解更多關于 NVIDIA NeMo 以及它如何幫助企業構建可生產的生成人工智能的信息。
?





