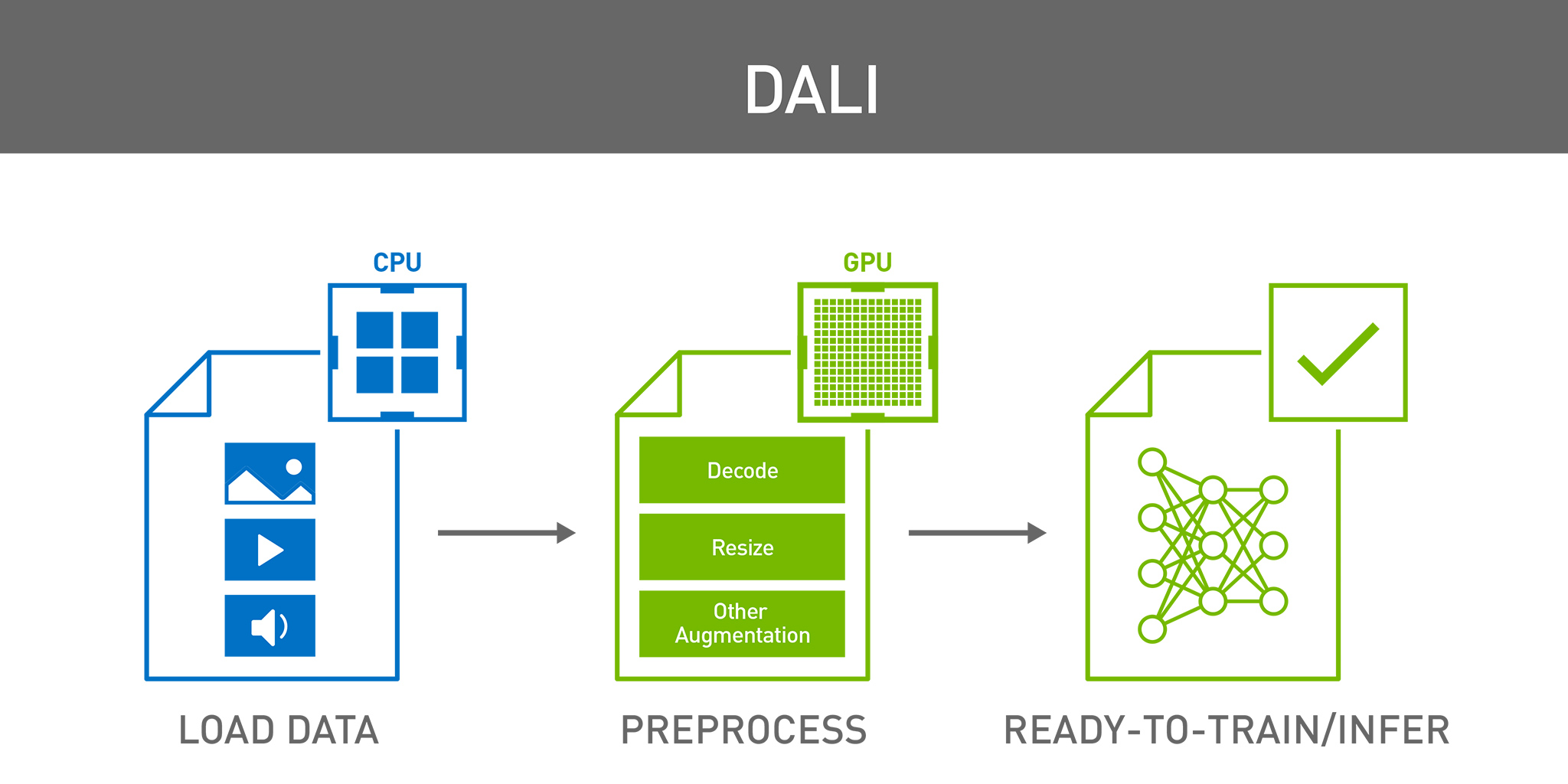
NVIDIA DALI 是一個用于解碼和增強圖像、視頻和語音的便攜式開源軟件庫,最近推出了多項功能,可提高性能并支持 DALI 的新用例。這些更新旨在簡化 DALI 與現有 PyTorch 數據處理邏輯的集成,通過啟用 CPU 到 GPU 流以及添加新的視頻解碼模式來提高構建數據處理流程的靈活性。這些新功能使 DALI 成為深度學習從業者不可或缺的工具,包括:
- ?
- 視頻處理改進,通過支持更廣泛的選擇性解碼模式和快速視頻容器索引,無需支付不必要的解碼開銷,從而提高 DALI 的通用性。
- 執行流增強功能,可優化內存消耗。此外,它通過在執行流程中啟用 GPU 到 CPU 的傳輸,為執行模型帶來了更大的靈活性。
DALI 代理:高效的 GPU 加速
- 其中一個主要限制是,由于 Python 全局解釋器鎖定 (GIL) ,使用最新的多核 CPU 架構存在困難。當多核 CPU 架構在消費市場廣泛使用時,Python 生態系統引入了全局鎖定來簡化多線程編程模型,但以降低性能為代價,這會降低處理效率。解決這一問題的最常見方法是在多個獨立進程中運行 Python 解釋器,使用共享內存或其他 IPC 機制進行通信。雖然這適用于 CPU,但對 GPU 工作編排有一些限制:
- 每個進程都會創建一個單獨的 GPU 上下文,在切換不同線程調度的任務時增加了開銷。
- 每個進程都會分配自己的 GPU 顯存,從而增加整體使用率。
- 在進程之間共享 GPU 顯存會增加額外的開銷。DALI 通過使用原生多線程來解決這一問題,克服了 Python GIL。
- 在多個 Python 進程之間傳輸內存時,CPU 和 GPU 之間的數據往返效率可能會降低。這會鼓勵在 GPU 運算之后進行 CPU 運算的次優模式,從而增加在 GPU 上來回傳輸數據的時間,最終降低 GPU 加速的優勢。DALI 不鼓勵這種模式,確保盡可能減少往返行程,或者根本不會發生。
- 為每個進程創建單獨的上下文并分配單獨的內存會導致 GPU 工作編排效率低下,從而導致開銷和內存占用率過高。

圖 1 顯示了 Python 中不同的數據處理方法及其局限性。左圖展示了最簡單的方法,即同時創建多個 Python 線程。但是,由于 Python GIL,一次只能執行一個線程,導致 CPU 未得到充分利用。
中間圖使用獨立進程而非線程。雖然對 CPU 而言十分高效,但每個進程都會編排 GPU 以獨立工作,并且需要昂貴的 IPC 來聚合每個進程的結果。
右圖使用帶有原生處理功能的 DALI,它可以高效使用所有 CPU 核心并編排 GPU 以正常工作,而不會產生不必要的開銷。
DALI 以取代 PyTorch 數據加載程序為代價,有效地解決了這些問題。雖然使用 DALI 從頭開始創建新的數據管道非常簡單,但重寫現有流可能需要大量工作。DALI Proxy 使用戶能夠有選擇地將現有數據管道的一部分卸載到 DALI,非常適合多模態應用,在這種應用中,只有特定的模式 (如視覺處理) 需要加速,而其他部分則使用外部庫。此外,它還使 PyTorch 多進程環境中的數據處理 GPU 加速變得方便高效。
該概念基于在主進程中運行的 DALI 服務器實例,該實例還負責編排訓練。輕量級 DALI 代理對象將仍在 CPU 上的數據傳輸到主進程,然后使用原生代碼并行處理。這使得 DALI 流水線能夠集成到現有的數據加載代碼中,僅加速耗時的部分,而不影響邏輯的其余部分,例如復雜的數據讀取模式。

使用最簡潔方法的 DALI 代理使用示例 (更多示例請參閱 API 文檔):
@pipeline_def(num_threads=4, device_id=0)def rn50_train_pipe(): # the PyTorch data loader passes file names and DALI loads it filepaths = fn.external_source(name="images", no_copy=True) jpegs = fn.io.file.read(filepaths) # decode data on the GPU images = fn.decoders.image_random_crop( images, device="mixed", output_type=types.RGB) # the rest of processing happens on the GPU as well images = fn.resize(images, resize_x=256, resize_y=256) images = fn.crop_mirror_normalize( images, crop_h=224, crop_w=224, mean=[0.485 * 255, 0.456 * 255, 0.406 * 255], std=[0.229 * 255, 0.224 * 255, 0.225 * 255], mirror=fn.random.coin_flip()) return images, labelspipe = rn50_train_pipe(train_dir)with dali_proxy.DALIServer(pipe) as dali_server: # we want torchvision.datasets to pass just filenames to DALI def read_filepath(path): return np.frombuffer(path.encode(), dtype=np.int8) # use proxy as the any other transform list dataset = torchvision.datasets.ImageFolder( jpeg, transform=dali_server.proxy, loader=read_filepath) # usual data loader loader = torch.utils.data.DataLoader( dataset, batch_size=batch_size, num_workers=nworkers, drop_last=True, ) for data, target in loader: # produce_data could be skipped if we use nvidia.dali.plugin.pytorch.experimental.proxy.DataLoader data = dali_server.produce_data(data) |
視頻處理改進
DALI 的近期更新對其視頻處理能力進行了一系列重大擴展,增加了對可變幀率視頻解碼的支持,并使用戶能夠在解碼期間直接提取特定幀。這些新功能提高了視頻數據工作流的靈活性和可控性。除了這些功能升級之外,視頻解碼器的初始化時間也得到了優化,使性能與 DALI 之前提供的更專業的解碼器保持一致。索引時間的減少對于訓練視頻基礎模型尤其重要,因為這些模型通常需要高效處理數百萬個視頻樣本。
隨著深度學習的發展,視頻已成為關鍵數據源。與易于單獨加載和處理的圖像不同,視頻是幀的集合,必須以不同的方式進行處理。每個視頻都像是一個迷你數據集,研究人員通常需要使用自定義策略來讀取幀。例如,為了提高視頻的幀速率,模型可能需要連續的幀。相比之下,對于動作識別,讀取每 N 幀有助于減少冗余并避免網絡不堪重負。
DALI 支持所有這些用例,能夠指定幀數、第一幀、最后一幀、stride (幀之間的步長) 和/ 或顯式幀列表。用戶可以定義 padding mode,以確保無論視頻時長如何,他們始終能收到所請求的確切大小的幀序列。如果視頻不包含請求的幀,則復制現有幀。支持的 padding mode 包括 reflect padding、constant padding 和 edge padding。
執行程序增強功能
執行程序增強功能由 exec_dynamic 參數提供,可通過重用內存緩沖區來提高內存管理效率。最初,由于分配成本高昂,DALI 會在不釋放內存的情況下主動按需分配內存。最近的進步支持異步按需分配和釋放,以便操作有效地重復使用相同的物理內存,同時確保內存不會被覆蓋。此更新可提高內存占用率,從而更高效地處理大型數據集。
另一個值得注意的改進是,新的執行模型支持 CPU 到 GPU 到 CPU 的數據傳輸模式。過去,由于 CPU 和 GPU 之間存在大量數據傳輸用度,因此不鼓勵采用這種模式。然而,NVIDIA GH200 Grace Hopper 超級芯片和 NVIDIA GB200 NVL72 等先進架構的引入及其在 CPU 和 GPU 之間的快速互連開辟了新的可能性,使以前低效的模式得以實現。用戶現在可以加速 GPU 上的并行部分,并將數據移回 CPU,以應用本質上屬于串行的或 DALI 尚不支持的算法。
總結
最后,NVIDIA DALI 的最新進展顯著擴展了其作為深度學習高性能數據預處理庫的能力。通過引入 DALI 代理,用戶可以獲得精細的控制,將 DALI 集成到現有的 PyTorch 工作流中,同時克服 Python 多處理模型施加的限制。增強的視頻處理功能使 DALI 更適合現代基于視頻的 AI 任務,從而能夠靈活高效地處理復雜的幀選擇場景。同時,執行程序的改進可以減少內存占用并解鎖新的執行模式,特別是在具有快速 CPU-GPU 互連(如 GH200 和 GB200)的系統中。這些更新共同使 DALI 成為跨各種 AI 工作負載擴展數據預處理的通用高效解決方案。
立即試用
要開始使用這些新功能,請探索以下資源:
- ?
- 使用增強的video decoder進行視頻模型訓練,以利用改進的解碼功能。
- 測試新的 DALI 執行流程,了解優化的內存管理和靈活的數據傳輸的優勢。
使用 DALI GitHub 頁面提問或提出改進建議,了解詳情。
?