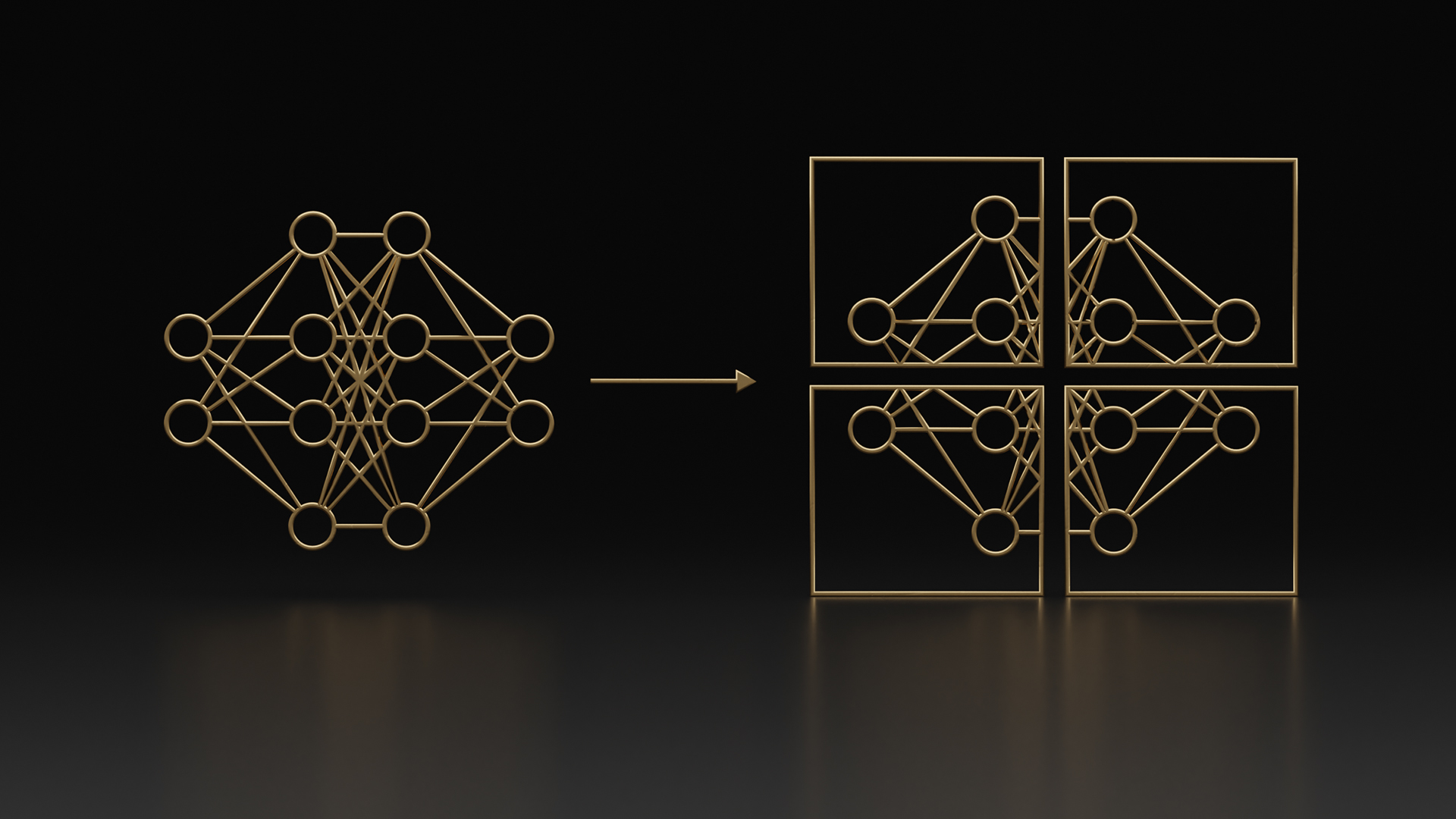
多數據中心訓練對 AI 工廠至關重要,因為預訓練擴展會推動更大模型的創建,導致對計算性能的需求超過單個設施的能力。通過將工作負載分配到多個數據中心,組織可以克服功耗、散熱和空間方面的限制,以更高的效率訓練更大、更準確的模型。
最新版本的 NVIDIA NeMo Framework 25.02 和 NVIDIA Megatron-Core 0.11.0 為 多數據中心大語言模型 (LLM) 訓練帶來了新功能。此次更新使用戶能夠將訓練擴展到單個數據中心的物理和操作限制之外,通過利用多個站點的組合功能,實現前所未有的效率和性能。
在本文中,我們將介紹 NeMo Framework 和 Megatron-Core 如何通過以下關鍵進展徹底改變多數據中心訓練:
- 跨站點高效 :通過在地理位置分散的數據中心中的數千個 NVIDIA GPU 上有效分配訓練,實現 96% 的擴展效率。
- 高級通信策略 :使用分層編排和梯度同步克服數據中心間延遲。
- 現實世界的成功 :通過高效訓練具有 340B 參數的 LLM 來驗證這些創新,為新一代 AI 超級計算鋪平道路。
為什么多數據中心訓練很困難
訓練萬億參數模型不僅需要增加更多 GPU,還需要克服影響成本和性能的關鍵基礎設施挑戰。在跨多個數據中心管理計算時,開發者必須應對高跨地區延遲 (通常為 20 毫秒或更多) ,這可能會在大規模 LLM 訓練期間的梯度更新和模型同步期間引入性能瓶頸。解決這些問題可實現分布式 LLM 訓練架構,從而提高性能、更大限度地提高硬件和能效、減少基礎設施壓力,并使 AI 項目能夠跨地理區域擴展,而不會出現集中資源瓶頸。
主要挑戰包括:
- 高延遲和帶寬限制 :數據中心之間的通信可能緩慢且受到限制,從而降低訓練效率。
- 同步 :保持分布式數據中心的一致性需要復雜的協議和技術。
- 流量管理:最大限度地減少長距網絡的數據流對于保持低延遲和高吞吐量至關重要。
實現高效的 Multi-data center 訓練
為了克服多數據中心 LLM 訓練的挑戰, NeMo Framework 25.02 和 Megatron-Core 0.11.0 引入了四項關鍵創新:
- 自適應資源 orchestration
- 分層 AllReduce ( HAR)
- 分布式 Optimizer 架構
- 數據中心間 Chunked 通信
這些功能可優化跨地理位置分離的站點的通信、編排和計算效率,確保對全球超大型 AI 模型進行可擴展的高性能訓練。
自適應資源 orchestration
自適應資源編排是一種分布式訓練策略,可利用集群內和集群間各種 GPU 之間的延遲和帶寬層次結構。它可以選擇能夠抵御通信延遲和帶寬限制的并行方法并確定其優先級,非常適合跨數據中心開發部署。在這些設置中,模型并行技術(例如 tensor、context 和 expert 并行)需要頻繁的高帶寬同步,而這并不適合數據中心之間的高延遲環境。相反,數據并行和 pipeline 并行技術受到青睞,因為:
- 延遲容忍度 :數據并行的批量梯度聚合可適應數據中心間通信中固有的較大延遲。
- 帶寬效率 :數據并行中的分層縮減模式整合了跨數據中心流量,顯著降低了帶寬需求。
- 硬件不可知論 :這兩種方法都通過標準化的 sharding 來消除站點之間的硬件差異。
通過將并行技術的選擇與網絡的限制保持一致,自適應資源編排可將每個 GPU 的數據中心間帶寬需求降低到數據中心內部需求的大約 1/N,與傳統的平面方法相比,實現了顯著的效率提升。
分層全局歸約
HAR 包含三個步驟來同步梯度:
- 在每個組或數據中心內 ReduceScatter,
- 跨數據中心的 AllReduce。
- AllGather 在每個數據中心內。
此方法通過首先優化數據中心間通信,確保高吞吐量和低延遲,最大限度地減少長距網絡的流量。 圖 1 說明了 HAR 的工作原理。
分布式 Optimizer 架構
部分數據并行分布式優化器通過在每個數據中心內進行局部權重更新和梯度降低來提高效率,然后跨站點進行單一同步梯度降低,從而消除冗余優化器狀態重復,同時最大限度地減少跨數據中心通信。通過在數據中心內 (而非全局) 對優化器狀態進行分片,并在站點之間復制優化器實例,該架構可在減少數據中心間流量的同時大規模保持內存效率。
數據中心間 Chunked 通信
通過將通信拆分成塊并將這些塊與計算重疊,數據中心間的通信可能會被隱藏在數據中心內部的運營中。此技術可確保即使在大規模訓練中,訓練過程也保持高效,從而對站點之間的延遲具有很高的容忍度。
NVIDIA Nemotron-4 340B 多數據中心訓練
最近,我們有機會對 Nemotron-4 340B 進行大規模訓練。為確定基準,我們使用配備 3,072 個 NVIDIA GPU 的單個數據中心對 LLM 進行了訓練。
接下來,在相距約 1000 公里的兩個數據中心對模型進行訓練,以展示這些新功能的有效性。如 表 1 所示,該設置在 3072 個 GPU 規模 (每個數據中心配備 1500 個 GPU) 下實現了超過 96% 的基準吞吐量,并且數據中心間和數據中心內的獨立通信相互重疊,以更大限度地提高效率。通過利用 NeMo Framework 和 Megatron-Core 的功能,訓練過程實現了非凡的效率和可擴展性,為 LLM 開發樹立了新的標準。
| 指標 | 單數據中心 (ORD) | 多數據中心 (ORD+ IAD) |
| GPU 總數 | 3072 個 GPU | 3072 個 GPU (ORD 1536 個,IAD 1536 個) |
| GPU 節點 | 375 個節點 (每個節點 8 個 GPU) | 375 個節點 (每個節點 8 個 GPU) |
| 數據中心位置 | Oracle Cloud Infrastructure (OCI) – 伊利諾伊州芝加哥市 (ORD) | OCI – 伊利諾伊州芝加哥市 (ORD) 和弗吉尼亞州 Ashburn 市 (IAD) |
| 數據中心之間的距離 | 不適用 | 約 1000 千米 |
| 測量的往返延遲 | 不適用 | 21 毫秒 |
| 擴展效率 | 基準 ( 100%) | 與單站點基準相比,超過 96% |
| 模型 FLOPS 利用率 (MFU) | 51% | 49% |
| 訓練模型 | Nemotron-4 340B | Nemotron-4 340B |
跨多個設施釋放超級計算的潛力
多數據中心訓練正在成為 AI 工廠中的一種變革性方法,為分布在多棟建筑甚至多個地區的分布式系統奠定了基礎。通過集成先進的網絡和同步技術,這種方法可以協調不同設施中的大量 GPU,確保復雜的訓練任務能夠同時無縫運行。
NVIDIA GPU 數據中心平臺 (包括 低延遲網絡解決方案 和 AI 軟件堆棧) 可實現出色的并行性。這個全棧平臺為超級計算機鋪平了道路,最終可以跨多個數據中心利用超過 500,000 個 GPU。該架構不僅可以擴展計算能力,還可以通過動態平衡多個站點的工作負載來提高可靠性和靈活性,從而減少瓶頸并優化能效。
立即開始使用
Megatron-Core 內置了跨多個數據中心訓練 LLM 的支持,并與 NVIDIA NeMo 框架深度集成 。 NVIDIA NeMo 框架是一個端到端平臺,用于隨時隨地開發自定義生成式 AI,包括大語言模型 (LLM) 、視覺語言模型 (VLM) 、檢索模型、視頻模型和語音 AI 。它采用了用于大規模 LLM 訓練的 Megatron-Core,并提供了一套更廣泛的工具,用于構建先進的自定義生成式 AI、多模態和語音 AI 代理系統。如需了解詳情,請參閱 NVIDIA NeMo 框架文檔 和 GitHub 示例資源庫 。
?