<xmp id="om0om">
<td id="om0om"></td>
<table id="om0om"><noscript id="om0om"></noscript></table>
DEVELOPER
首頁
博客
論壇
論壇 (英文)
文檔
下載
培訓
Search
Join
RAPIDS
2025年 7月 23日
在 Azure 上使用 Apache Spark 和 NVIDIA AI 進行無服務器分布式數據處理
將大量文本庫轉換為數字表示 (稱為嵌入) 的過程對于生成式 AI 至關重要。從語義搜索和推薦引擎到檢索增強生成 (RAG) ,
2 MIN READ
在 Azure 上使用 Apache Spark 和 NVIDIA AI 進行無服務器分布式數據處理
2025年 7月 18日
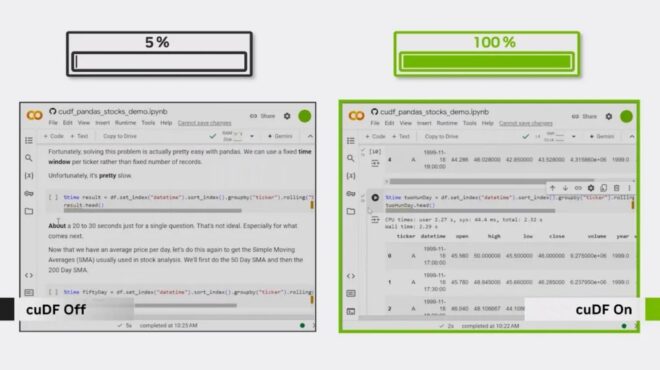
3 個 pandas 工作流在大型數據集上嚴重變慢,直到啟用了 GPU 加速
如果您使用 pandas,您可能已經撞到了墻壁。正是在這個時刻,您值得信賴的工作流程在處理較小的數據集時表現出色,在處理大型數據集時陷入停頓。
1 MIN READ
3 個 pandas 工作流在大型數據集上嚴重變慢,直到啟用了 GPU 加速
2025年 7月 17日
大規模特征工程:利用 NVIDIA CUDA-X 數據科學優化半導體制造的機器學習模型
在上一篇博文中,我們介紹了芯片制造和運營中的預測建模設置,重點介紹了數據集不平衡等常見挑戰,以及對更細致的評估指標的需求。
2 MIN READ
大規模特征工程:利用 NVIDIA CUDA-X 數據科學優化半導體制造的機器學習模型
2025年 7月 3日
RAPIDS 新增 GPU Polars 串流、統一 GNN API 和零代碼 ML 加速功能
RAPIDS 是一套用于 Python 數據科學的 NVIDIA CUDA-X 庫,發布了 25.06 版本,引入了令人興奮的新功能。
2 MIN READ
RAPIDS 新增 GPU Polars 串流、統一 GNN API 和零代碼 ML 加速功能
2025年 6月 27日
如何在 Polars GPU 引擎中處理超過 VRAM 的數據
在量化金融、算法交易和欺詐檢測等高風險領域,數據從業者經常需要處理數百 GB 的數據,才能快速做出明智的決策。
1 MIN READ
如何在 Polars GPU 引擎中處理超過 VRAM 的數據
2025年 6月 18日
NVIDIA 在制造和運營領域的 AI 應用:借助 NVIDIA CUDA-X 數據科學加速 ML 模型
從晶圓制造和電路探測到封裝芯片測試,NVIDIA 利用數據科學和機器學習來優化芯片制造和運營工作流程。這些階段會產生 TB 級的數據,
3 MIN READ
NVIDIA 在制造和運營領域的 AI 應用:借助 NVIDIA CUDA-X 數據科學加速 ML 模型
2025年 6月 12日
借助 RAPIDS 單細胞技術推動十億細胞分析和生物學突破
細胞生物學和虛擬細胞模型的未來取決于大規模測量和分析數據。在過去 10 年里,單細胞實驗一直以驚人的速度增長,從數百個細胞開始,
2 MIN READ
借助 RAPIDS 單細胞技術推動十億細胞分析和生物學突破
2025年 6月 5日
利用 NVIDIA cuML 中的森林推理庫加速樹模型推理
樹集成模型仍然是表格數據的首選,因為它們準確、訓練成本相對較低且速度快。但是,如果您需要低于 10 毫秒的延遲或每秒數百萬次的預測,
3 MIN READ
利用 NVIDIA cuML 中的森林推理庫加速樹模型推理
2025年 5月 29日
RAPIDS 實現零代碼更改加速、IO 性能提升和核外 XGBoost 加速
在過去的兩個版本中,RAPIDS 為 Python 機器學習引入了零代碼更改加速、巨大的 IO 性能提升、大于內存的 XGBoost 訓練、
3 MIN READ
RAPIDS 實現零代碼更改加速、IO 性能提升和核外 XGBoost 加速
2025年 5月 22日
特級大師專業提示:使用 cuML 通過堆疊奪得 Kaggle 競賽冠軍
堆疊是一種先進的表格數據建模技術,通過結合多個不同模型的預測來實現高性能。利用 GPU 的計算速度,可以高效地訓練大量模型。
2 MIN READ
特級大師專業提示:使用 cuML 通過堆疊奪得 Kaggle 競賽冠軍
2025年 5月 19日
聚焦:Atgenomix SeqsLab 提升健康組學分析以支持精準醫療
在傳統的臨床醫學實踐中,治療決策通常基于一般準則、以往經驗和試錯方法。如今,隨著電子病歷 (EMRs) 和基因組數據的訪問,
2 MIN READ
聚焦:Atgenomix SeqsLab 提升健康組學分析以支持精準醫療
2025年 5月 15日
使用 GPU 預測 Apache Spark 的性能
大數據分析領域正在不斷尋找加速處理和降低基礎設施成本的方法。Apache Spark 已成為用于橫向擴展分析的領先平臺,可處理 ETL、
2 MIN READ
使用 GPU 預測 Apache Spark 的性能
2025年 5月 15日
使用 NVIDIA CUDA-X 和 Coiled 簡化云端環境設置并加速數據科學運算
想象一下,分析紐約市數百萬次的拼車旅程 — — 跟蹤各自治市的模式、比較服務定價或確定有利可圖的取車地點。
4 MIN READ
使用 NVIDIA CUDA-X 和 Coiled 簡化云端環境設置并加速數據科學運算
2025年 5月 8日
云端 Apache Spark 加速深度學習和大語言模型推理
Apache Spark 是用于大數據處理和分析的行業領先平臺。隨著非結構化數據(documents、emails、
4 MIN READ
云端 Apache Spark 加速深度學習和大語言模型推理
2025年 5月 7日
使用 NVIDIA NeMo Curator 構建 Nemotron-CC:一個高質量萬億令牌數據集,用于大型語言模型預訓練,源自 Common Crawl
對于想要訓練先進的 大語言模型 (LLM) 的企業開發者而言,整理高質量的預訓練數據集至關重要。為了讓開發者能夠構建高度準確的 LLM,
2 MIN READ
使用 NVIDIA NeMo Curator 構建 Nemotron-CC:一個高質量萬億令牌數據集,用于大型語言模型預訓練,源自 Common Crawl
2025年 5月 1日
借助超參數優化實現堆疊泛化:使用 NVIDIA cuML 在15分鐘內最大化準確性
堆疊泛化是機器學習 (ML) 工程師廣泛使用的技術,通過組合多個模型來提高整體預測性能。另一方面,超參數優化 (HPO)…
3 MIN READ
借助超參數優化實現堆疊泛化:使用 NVIDIA cuML 在15分鐘內最大化準確性
加載更多
人人超碰97caoporen国产
Search
Join
首頁
博客
論壇
論壇 (英文)
文檔
下載
培訓