生成式人工智能已成為我們時代的變革力量,使各行各業的組織能夠實現無與倫比的生產力水平,提升客戶體驗,并提供卓越的運營效率。
大語言模型 (LLMs) 是生成式人工智能背后的大腦。獲得 Llama 和 Falcon 等功能強大、知識淵博的基礎模型,為創造驚人的機會打開了大門。然而,這些模型缺乏服務于企業用例所需的特定領域的知識。
開發人員有三種選擇來為其生成的人工智能應用程序提供動力:
- 預訓練 LLM:最簡單的方法是使用基礎模型,這對于依賴于通用知識的用例非常有效。
- 定制化的 LLM:這是一種預訓練模型,使用領域特定知識和任務特定技能進行定制,連接到企業的知識庫,根據最新的專有信息執行任務并提供響應。
- 開發 LLM:擁有專門數據的組織(例如,適合區域語言的模型)不能使用預先訓練的基礎模型,必須從頭開始構建模型。
NVIDIA NeMo 是一個端到端的云原生框架,用于構建、定制和部署生成人工智能模型。它包括訓練和推理框架 Guardrails,以及數據管理工具,以實現采用生成人工智能的簡單、經濟高效和快速的方式。
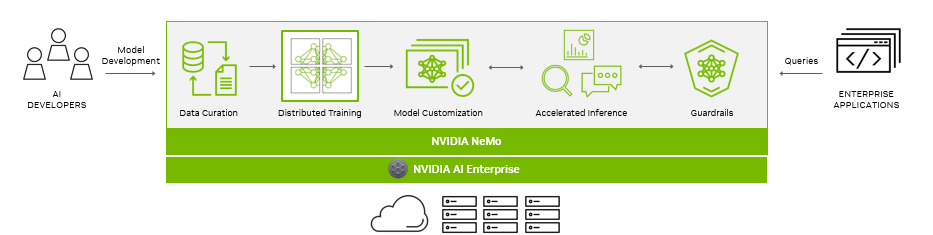
隨著生成性人工智能模型及其發展的不斷進步,人工智能堆棧及其依賴關系變得越來越復雜。對于在人工智能上運營業務的企業,NVIDIA AI Enterprise 為他們提供了一個生產級、安全的端到端軟件解決方案。
各組織正在谷歌云上運行其任務關鍵型企業應用程序,谷歌云是 GPU 加速云平臺的領先提供商。 NVIDIA AI Enterprise 包括 NeMo ,可在谷歌云上使用,幫助組織更快地采用生成人工智能。
構建生成型人工智能解決方案需要從計算到網絡、系統、管理軟件、訓練和推理 SDK 的完整堆棧協調工作。
在 Google Cloud Next 2023 上,Google Cloud 宣布由 NVIDIA H100 Tensor Core GPU 提供支持的 A3 實例全面可用。兩家公司的工程團隊正在合作,將 NeMo 引入 A3 實例,以實現更快的訓練和推理。
在這篇文章中,我們介紹了開發人員在 NVIDIA H100 GPU 上構建和運行自定義生成人工智能模型時可以享受的培訓和推理優化。
大規模數據管理
單個 LLM 在不同任務中取得卓越成果的潛力是由于對大量互聯網規模數據的培訓。
NVIDIA NeMo 數據策展人為 LLM 處理萬億代幣多語言訓練數據提供便利。它由一組 Python 模塊組成,這些模塊利用 MPI、Dask 和 Redis 集群來高效地擴展數據管理中涉及的任務。這些任務包括數據下載、文本提取、文本重新格式化、質量過濾以及刪除精確或模糊的重復數據。該工具可以將這些任務分布在數千個計算核心中。
使用這些模塊可以幫助開發人員快速篩選非結構化數據源。這項技術加速了模型訓練,通過高效的數據準備降低了成本,并產生了更精確的結果。
加速模型培訓
NeMo 采用分布式訓練,使用復雜的并行方法在多個節點上大規模使用 GPU 資源和內存。通過分解模型和訓練數據, NeMo 實現了最佳吞吐量,并顯著減少了訓練所需的時間,這也加快了 TTM。
H100 GPU 采用 NVIDIA transformer 引擎(TE),這是一個通過將 16 位和 8 位浮點格式與高級算法相結合來增強 AI 性能的庫。它通過將數學運算從人工智能工作負載中使用的典型 FP16 和 FP32 格式減少到 FP8,在不損失準確性的情況下實現了更快的 LLM 訓練。此優化使用逐層統計分析來提高每個模型層的精度,從而實現最佳性能和準確性。
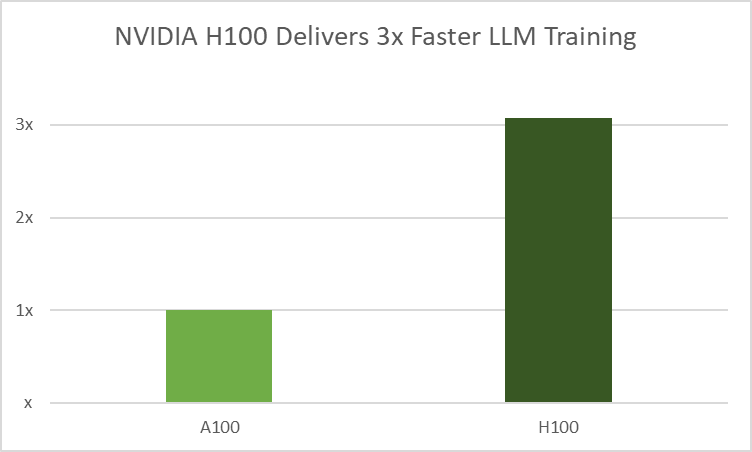
AutoConfigurator 可提高開發人員的工作效率
在分布式基礎設施中查找 LLM 的模型配置是一個耗時的過程。 NeMo 提供了 AutoConfigurator,這是一種超參數工具,可以自動找到最佳訓練配置,使高通量 LLM 能夠更快地訓練。這節省了開發人員搜索高效模型配置的時間。
它將啟發式和網格搜索技術應用于各種參數,如張量并行度、流水線并行度、微批量大小和激活檢查點層,旨在確定具有最高吞吐量的配置。
AutoConfigurator 還可以找到在推理過程中實現最高吞吐量或最低延遲的模型配置。可以提供延遲和吞吐量約束來部署模型,并且該工具將推薦合適的配置。
查看 構建生成性 AI 模型 的食譜,包括 GPT、MT5、T5 和 BERT 架構的各種大小。
模型自定義
在 LLM 領域,通用模式很少適用,尤其是在企業應用程序中。現成的 LLM 往往無法滿足組織的獨特需求,無論是專業領域知識的復雜性、行業術語還是獨特的運營場景。
這正是定制 LLM 的意義所在。企業必須對支持特定用例和領域專業知識的功能的模型進行微調。這些定制模式為企業提供了創建個性化解決方案的手段,以匹配其品牌聲音?并簡化工作流程,以獲得更準確的見解,以及?豐富的用戶體驗。
NeMo 支持多種自定義技術,供開發人員使用NVIDIA 構建的模型,通過添加功能技能、專注于特定領域以及實施 Guardrails 來防止不適當的響應。
此外,該框架支持社區構建的預訓練 LLM,包括 Llama 2、BLOOM 和 Bart,并支持 GPT、T5、mT5、T5 MoE 和 Bert 架構。
- P-調諧訓練小助手模型來設置凍結 LLM 的上下文,以生成相關且準確的響應。
- 適配器/IA3在核心 transformer 架構中引入小型、特定于任務的前饋層,為每個任務添加最小的可訓練參數。這使得新任務的集成變得容易,而無需重新設計現有任務。
- 低階自適應使用緊湊的附加模塊來增強模型在特定任務上的性能,而不會對原始模型進行實質性更改。
- 監督微調在輸入和輸出的標記數據上校準模型參數,教授模型領域特定術語以及如何遵循用戶指定的說明。
- 人的反饋強化學習使 LLM 能夠更好地與人類價值觀和偏好保持一致。
了解有關各種 LLM 定制技術。
加速推理
社區 LLM 正以爆炸性的速度增長,公司對將這些模型部署到生產中的需求也在增加。這些 LLM 的大小導致部署的成本和復雜性更高,需要優化生產應用程序的推理性能。更高的性能不僅有助于降低成本,還可以改善用戶體驗。
LLM,如 LLaMa、BLOOM、ChatGLM、Falcon、MPT 和 Starcoder,已經展示了先進架構和運營商的潛力。這給開發一種能夠有效優化這些模型進行推理的解決方案帶來了挑戰,這在生態系統中是非常可取的。
NeMo 采用 MHA 和 KV 緩存優化、閃存注意力、量化 KV 緩存和分頁注意力等技術來解決 LLM 優化的大量挑戰。它使開發人員能夠嘗試新的 LLM 并自定義基礎模型以獲得最高性能,而無需深入了解 C++或 NVIDIA CUDA 優化。
NeMo 還利用 NVIDIA TensorRT 深度學習編譯器、預處理和后處理優化以及多 GPU 多節點通信。在開源 Python neneneba API 中,它定義、優化并執行 LLM,用于生產應用程序中的推理。
NeMo Guardrails
LLM 可能有偏見,提供不恰當的反應,并產生幻覺。 NeMo Guardrails 是一個開源、可編程的工具包,用于應對這些挑戰。它位于用戶和 LLM 之間,篩選和過濾不適當的用戶提示以及 LLM 響應。
針對各種場景構建 Guardrails 非常簡單。首先,通過用自然語言提供幾個例子來定義護欄。然后,在生成關于該主題的問題時定義一個響應。最后,定義一個流,它規定了在觸發主題或流時要采取的一組操作。
NeMo Guardrails 可以幫助 LLM 專注于主題,防止有毒反應,并確保向用戶提供信息。閱讀有關建筑的信息,了解如何建立可信賴、安全、保密的 LLM 對話系統。
使用生態系統工具簡化部署
NeMo 與 MLOps 生態系統技術合作,如權重和偏差(W&B),為加速 LLM 的開發、調整和采用提供強大的功能。
開發人員可以使用 W&B MLOps 平臺調試、微調、比較和復制模型。W&B Prompts 幫助組織理解、調整和分析 LLM 性能。W&B 集成了 ML 開發中常用的谷歌云產品。
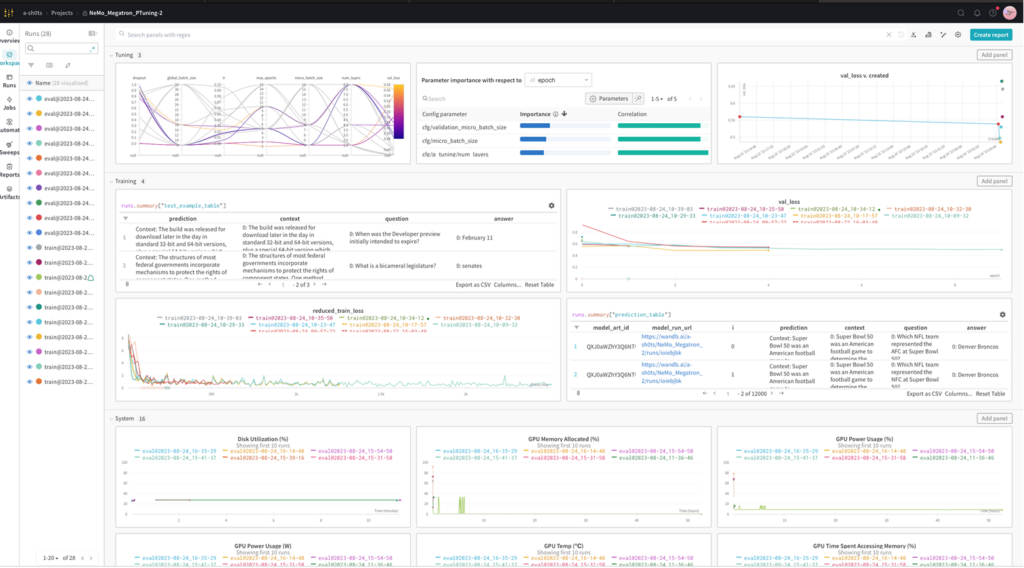
NeMo 、W&B 和 Google Cloud 的組合在 Google Cloud Next 的 NVIDIA 展位上展出。
推動生成型人工智能應用
Writer 是一家領先的基于人工智能的生成性內容創建服務公司,正在谷歌云上利用 NeMo 功能和加速計算。他們已經建立了高達 40B 的參數語言模型,現在可以滿足數百名客戶的需求,正在革新內容生成。
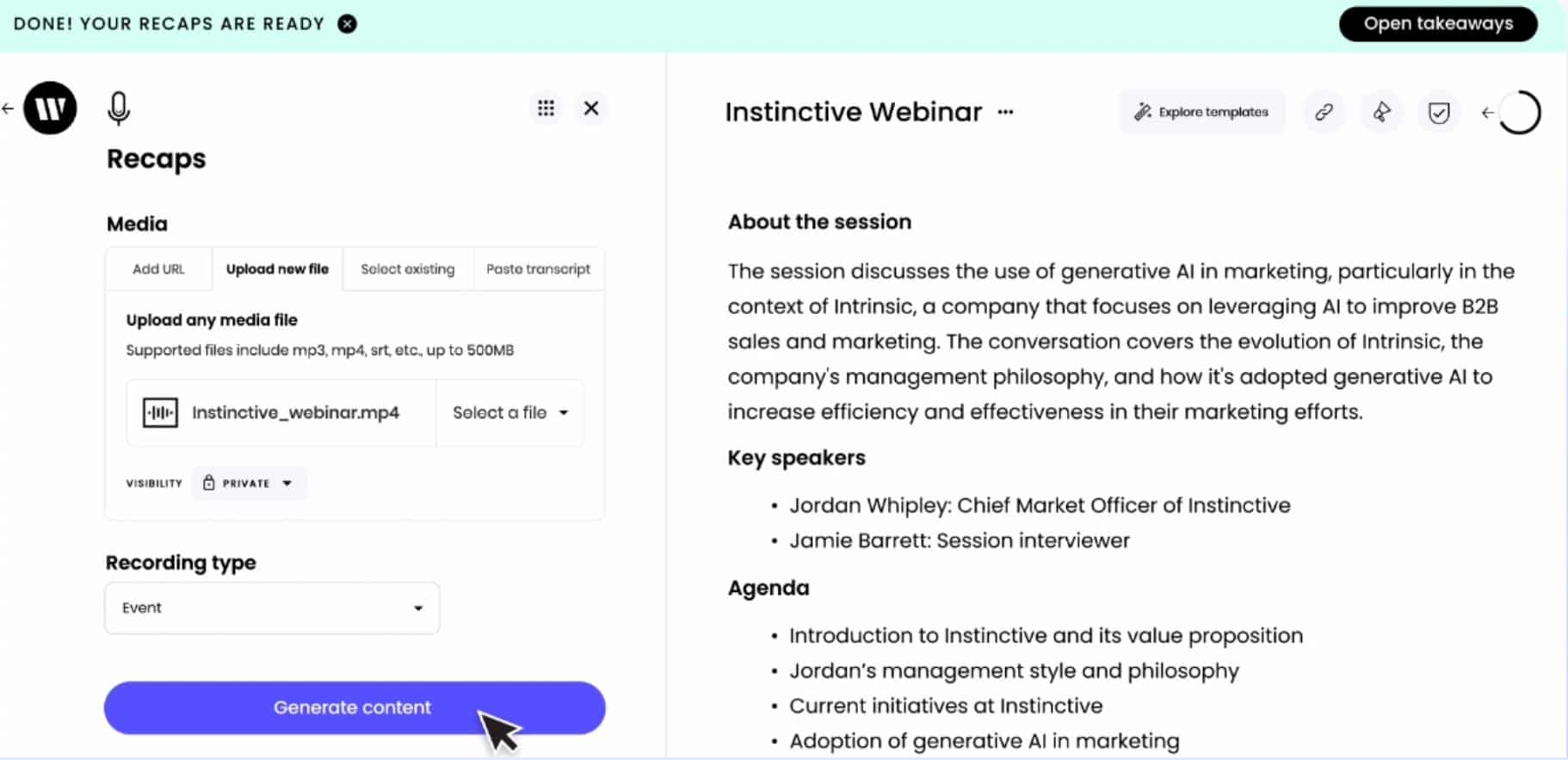
圖 4。Writer Recap 工具從采訪或事件的錄音中創建書面摘要
APMIC 是另一個以 NeMo 為核心的成功案例。他們在兩個不同的應用場景中使用了 NeMo。他們通過實體鏈接,快速從文檔中提取重要信息,從而優化了合同驗證和判決摘要的流程。他們還使用 NeMo 定制了 GPT 模型,為問答系統提供動力,提供客戶服務和數字人機交互解決方案。
開始構建生成型人工智能應用程序
您可以使用 AI playground,直接通過 web 瀏覽器體驗社區和 NVIDIA 構建的生成 AI 模型的全部潛力,這些模型針對 NVIDIA 加速堆棧進行了優化。
使用 Google Cloud 上的 NeMo 自定義來自 HuggingFace 的 GPT、mT5 或 基于 BERT 的預訓練 LLMs:
- 請訪問 NeMo 的 GitHub 頁面。
- 在 GPU 加速平臺上運行從 NGC 中拉出的 NeMo 容器。
- NVIDIA AI Enterprise 提供的 NeMo Google Cloud Marketplace 具有企業級支持和安全性。
今天就開始使用NVIDIA NeMo。
?
?