
堆疊泛化是機器學習 (ML) 工程師廣泛使用的技術,通過組合多個模型來提高整體預測性能。另一方面,超參數優化 (HPO) 涉及系統搜索最佳超參數集,以更大限度地提高給定 ML 算法的性能。
同時使用堆棧和 HPO 時,一個常見的挑戰是巨大的計算需求。這些方法通常需要訓練多個模型,并針對每個模型迭代大量超參數組合。這可能會很快變得耗費大量資源和時間,尤其是對于大型數據集而言。
在本文中,我們將演示如何簡化此工作流,該工作流將堆棧泛化與 HPO 相結合。我們將展示如何使用 cuML 庫的 GPU 加速計算在短短 15 分鐘內執行此工作流。得益于 cuML 與 scikit-learn 的零代碼更改集成,您可以使用現有的 ML 工作流進行 GPU 加速 (無需修改代碼) ,并實現相同的模型準確性。與基于 CPU 的執行 (通常一次只運行一個試驗) 不同,GPU 加速支持并行執行多個 HPO 試驗,顯著縮短訓練時間。
我們首先討論我們使用的堆疊方法、其實現以及準確性的提高。然后,我們將討論 HPO 如何通過搜索最佳 hyperparameters 來提高整體準確性。
堆疊泛化
堆疊泛化是一種成熟的技術,已在實驗中得到廣泛應用,包括許多 Kaggle 比賽。它是一種有效的集成方法,但由于其計算成本,在實際應用中通常未得到充分利用。
圖 1 展示了我們實現的堆棧架構。在基本層面,我們使用了三個不同的模型:Random Forest、K-Nearest Neighbors (KNN) 和 Logistic Regression。然后,將這些基礎模型的預測傳遞給 KNN 元模型,由其根據組合輸出進行最終分類。
在實驗中,我們使用了分類數據集,其中包含從 源數據集 推斷出的 1M 個樣本和九個特征。這種設置使我們能夠利用每個基礎模型的優勢,并通過堆疊提高整體預測準確性。

要在現有的 scikit-learn 工作流程中啟用 GPU 加速,您只需使用 cuML 庫即可。安裝完成后,只需添加 magic 命令:
%load_ext cuml.accel |
此命令可在底層激活 GPU 加速,無需更改模型創建、訓練或評估代碼。您可以繼續使用熟悉的 scikit-learn 語法,但使用 GPU 加速的 cuML 庫實現執行提升。以下代碼片段展示了我們如何使用隨機森林、KNN 和邏輯回歸作為基礎模型,并以 KNN 模型作為元學習器來設置堆棧管道。如需親自試用,請查看 隨附的 Jupyter Notebook 。
%load_ext cuml.accel# Load the cuML librariesfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.neighbors import KNeighborsClassifier# Define base models (level-0 models)base_models = [ ("logistic_regression", LogisticRegression(**lr_study.best_params, max_iter = 20000, tol=1e-3)), ("random_forest", RandomForestClassifier(**rf_study.best_params, random_state = 42)), ("k_nearest_neighbors", KNeighborsClassifier(**knn_study.best_params))]# Function to generate meta features for stackingdef generate_meta_features_for_stacking(base_models, X, y, X_meta): kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) meta_features = cp.zeros((X_meta.shape[0], len(base_models))) for i, (name, model) in enumerate(base_models): # Initialize array to hold out-of-fold predictions (for training data only) meta_predictions = cp.zeros((X.shape[0],)) print("Model name: ", name) # Out-of-fold predictions (only used if X_meta == X) for train_idx, val_idx in kfold.split(X, y): model.fit(cp.array(X.iloc[train_idx]), cp.array(y.iloc[train_idx])) predictions = model.predict(cp.array(X.iloc[val_idx])) meta_predictions[val_idx] = predictions.ravel() # Refit model on full training data for final prediction on X_meta model.fit(cp.array(X), cp.array(y)) # Predict meta features for test data predictions = model.predict(cp.array(X_meta)) meta_features[:, i] = cp.array(predictions).ravel() return meta_features# meta_train uses out-of-fold predictions to prevent leakagemeta_train = generate_meta_features_for_stacking(base_models, X_train_scaled, y_train_df, X_train_scaled)# meta_valid uses predictions from base models trained on full training setmeta_valid = generate_meta_features_for_stacking(base_models, X_train_scaled, y_train_df, X_valid_scaled) |
如圖 2 所示,使用 5-fold stratified cross-validation 測量時,堆疊泛化使預測準確率整體提高了 0.28%。

超參數優化
為了進一步提高堆疊集成的性能,我們將 HPO 應用于每個基礎模型和元模型。為便于執行,我們選擇了性能最佳的基礎模型來生成折疊外預測,并對這些模型進行堆疊以創建新的元數據集。此數據集用于在 KNN 元模型上運行 HPO,進一步優化其性能。
對于 HPO,我們使用 Optuna 庫 ,優化分類準確性作為指標。需要注意的是,通過使用 %load_ext cuml.accel 啟用 cuML 內核,整個 HPO 過程都得到了 GPU 加速。因此,其語法與 scikit-learn 保持不變。
以下代碼段展示了如何為邏輯回歸執行 HPO。該方法同樣適用于隨機森林、KNN 和 KNN 元模型。如需了解完整實現,請查看 隨附的 Jupyter Notebook 。
%load_ext cuml.accel# Load the cuML librariesfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.neighbors import KNeighborsClassifier# Define the model training and evaluation functiondef train_and_eval(C=1, penalty='l2'): lr = LogisticRegression(C = C, penalty = penalty, max_iter = 20000, tol=1e-3) lr.fit(X_train_scaled, y_train_df) y_proba = lr.predict_proba(X_valid_scaled)[:, 1] # Compute accuracy score score = cp.round(lr.score(cp.asnumpy(X_valid_scaled), cp.asnumpy(y_valid_df)) * 100, 2) return score# Define the Optuna objective function for hyperparameter tuningdef objective(trial): C = trial.suggest_float("C", 1e-2, 1e2, log = True) penalty = trial.suggest_categorical("penalty", ["l1", "l2"]) return train_and_eval(C, penalty)# Create an Optuna study to maximize accuracy scorelr_study = optuna.create_study( direction="maximize", study_name="optuna_logistic_acc_score", sampler=optuna.samplers.RandomSampler(seed=142),)# Launch hyperparameter optimization with the defined objectivelr_study.optimize(objective, n_trials=40)# Print the best hyperparameter set and its corresponding evaluation scoreprint(f"Best params: {lr_study.best_params}")print(f"Best accuracy score: {lr_study.best_value}") |
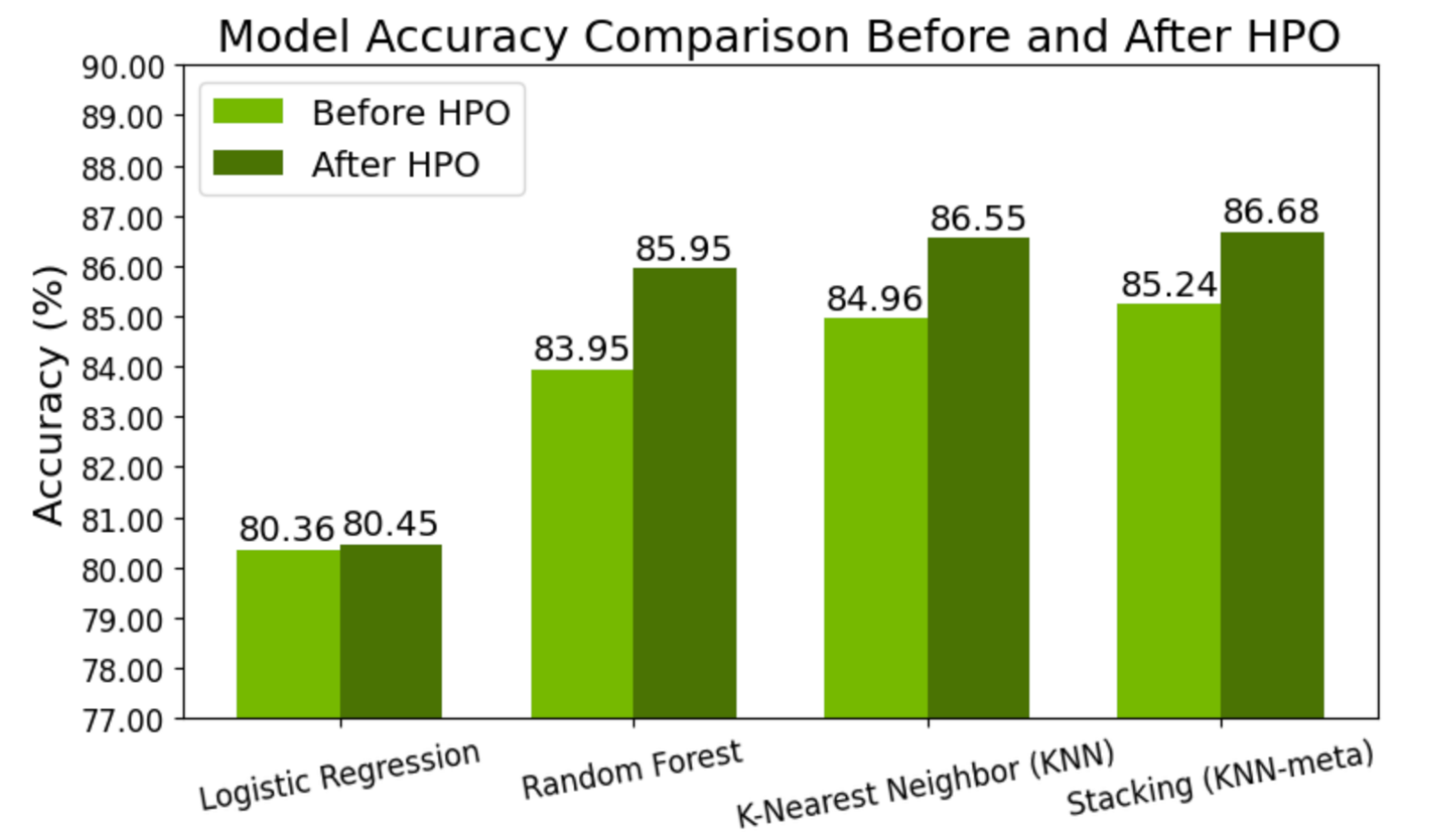
如圖 3 所示,與不使用 HPO 的模型相比,在基礎模型和元模型上應用 HPO 后,預測準確率提高了 1.44%。
將 GPU 加速與 cuML 結合使用的優勢
為了提高執行速度,尤其是在四個不同模型的 HPO 期間,利用 GPU 加速的 cuML 庫非常有用。它支持在基于 CPU 的執行僅需一次迭代所需的相同時間范圍內完成多次迭代。
在我們的場景中,我們設法為每個模型進行了大約 40 次迭代,每次迭代大約需要 5 秒,而在 CPU 上,模型的一次迭代通常大約需要 5 分鐘。此外,激活 GPU 加速非常簡單,只需在代碼中包含 the %load_ext cuml.accel 命令,即可與 scikit-learn 無縫集成。
開始使用
通過將堆疊泛化與 HPO 集成,可以提高系統的準確性。我們提出的解決方案使用 GPU 加速的 cuML 庫,使數據科學家能夠為堆棧泛化堆棧中的每個模型執行深度 HPO。cuML 庫與 scikit-learn 語法的兼容性使開發者能夠將此技術無縫整合到生產環境中。該集成不僅有助于開發出色的模型,還加速了迭代過程,從而使數據科學家和開發者能夠在現實世界的應用中實現更快的執行并提高模型性能。
要在您自己的應用中試用此方法,請下載最新版本的 NVIDIA cuML 。您可以隨時在 Slack 上分享您的反饋,網址是 #RAPIDS-GoAi 。
如需詳細了解 零代碼更改 cuML ,請參閱 NVIDIA cuML 為 scikit-learn 帶來零代碼更改加速 。有關此功能的更多示例,請參閱 Google Colab 筆記本 。最新版本的 cuML 具有零代碼更改功能,已預安裝在 Google Colab 中。有關自定進度課程和講師指導課程,請參閱 適用于數據科學的 DLI 學習路徑 。
?






