這篇文章最初發表在 RAPIDS 人工智能博客上。
介紹
RAPIDS 森林推理庫,親切地稱為 FIL ,極大地加速了基于樹的模型的推理(預測),包括梯度增強的決策樹模型(如 XGBoost 和 LightGBM 的模型)和隨機森林 ( 要深入了解整個庫,請查看 最初的 FIL 博客 。原始 FIL 中的模型存儲為密集的二叉樹。也就是說,樹的存儲假定所有葉節點都出現在同一深度。這就為淺樹提供了一個簡單、運行時高效的布局。但對于深樹,它也需要 lot 的 GPU 內存2d+1-1深度樹的節點 d 。為了支持最深的森林, FIL 支持
稀疏 樹存儲。如果稀疏樹的分支早于最大深度 d 結束,則不會為該分支的潛在子級分配存儲。這可以節省大量內存。雖然深度為 30 的 稠密的 樹總是需要超過 20 億個節點,但是深度為 30 的最瘦的 稀疏 樹只需要 61 個節點。
在 FIL 中使用稀疏森林
在 FIL 使用稀疏森林并不比使用茂密森林困難。創建的林的類型由新的 storage_type 參數控制到 ForestInference.load() 。其可能值為:
DENSE為了營造一片茂密的森林,SPARSE要創建稀疏的森林,AUTO(默認)讓 FIL 決定,當前總是創建一個密林。
無需更改輸入文件、輸入數據或預測輸出的格式。初始模型可以由 scikit learn 、 cuML 、 XGBoost 或 LightGBM 進行訓練。下面是一個將 FIL 用于稀疏森林的示例。
from cuml import ForestInference
import sklearn.datasets
# Load the classifier previously saved with xgboost model_save()
model_path = 'xgb.model'
fm = ForestInference.load(model_path, output_class=True,
?????????????????????????storage_type='SPARSE')
# Generate random sample data
X_test, y_test = sklearn.datasets.make_classification()
# Generate predictions (as a gpu array)
fil_preds_gpu = fm.predict(X_test.astype('float32'))
實施
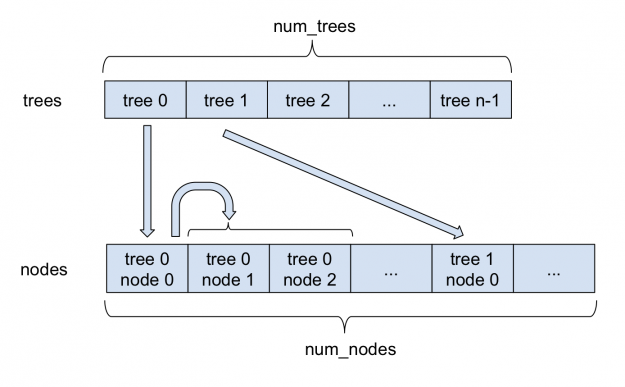
圖 1 描述了稀疏森林是如何存儲在 FIL 中的。所有節點都存儲在單個大型 nodes 陣列中。對于每個樹,其根在節點數組中的索引存儲在 trees 數組中。每個稀疏節點除了存儲在密集節點中的信息外,還存儲其左子節點的索引。由于每個節點總是有兩個子節點,所以左右節點相鄰存儲。因此,右子級的索引總是可以通過將左子級的索引加 1 來獲得。在內部, FIL 繼續支持密集節點和稀疏節點,這兩種方法都來自一個基林類。
與內部更改相比,對 pythonapi 的更改保持在最低限度。新的 storage_type 參數指定是創建密集林還是稀疏林。此外,一個新的值 'AUTO' 已經成為推斷算法參數的新默認值;它允許 FIL 自己選擇推理算法。對于稀疏林,它當前使用的是 'NAIVE' 算法,這是唯一受支持的算法。對于密林,它使用 'BATCH_TREE_REORG' 算法。
基準
為了對稀疏樹進行基準測試,我們使用 sciket learn 訓練了一個隨機林,具體來說就是 sklearn.ensemble.RandomForestClassifier 。然后,我們將得到的模型轉化為一個 FIL 林,并對推理的性能進行了測試。數據是使用 sklearn.datasets.make_classification() 生成的,包含 200 萬行,在訓練和驗證數據集之間平分, 32 列。對于基準測試,在一百萬行上執行推斷。
我們使用兩組參數進行基準測試。
- 深度限制設置為 10 或 20 ;在這種情況下,密集或稀疏的 FIL 林都可以放入 GPU 內存中。
- 無深度限制;在這種情況下, SKLearn 訓練的模型包含非常深的樹。在我們的基準測試運行中,樹的深度通常在 30 到 50 之間。試圖創建一個稠密的 FIL-forest 會耗盡內存,但是可以順利創建一個稀疏的 forest 。
在這兩種情況下,林本身的大小仍然相對較小,因為樹中的葉節點數限制為 2048 個,并且林由 100 棵樹組成。我們測量了 CPU 推理和 GPU 推理的時間。 GPU 推理是在 V100 上進行的, CPU 推理是在一個有兩個插槽的系統上進行的,每個插槽有 16 個內核,帶有雙向超線程。基準測試結果如圖 2 所示。
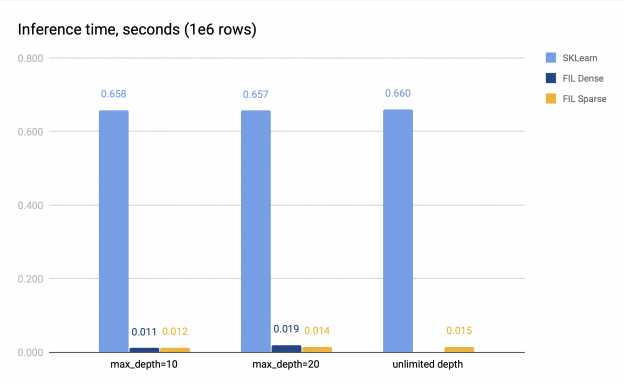
稀疏和密集 FIL 預測器(如果后者可用)都比 SKLearn CPU 預測器快 34-60 倍。對于淺層森林,稀疏 FIL 預報器比稠密 FIL 預報器慢,但是對于較深的森林,稀疏 FIL 預報器可以更快;具體的性能差異各不相同。例如,在圖 2 中, max \ u depth = 10 時,密集預測器比稀疏預測器快 1 . 14 倍,但 max \ u depth = 20 時,速度較慢,僅達到稀疏預測器的 0 . 75 倍。因此,對于淺層森林應采用稠密 FIL 預報。
然而,對于深林,稠密預測器的內存不足,因為它的空間需求隨著森林深度呈指數增長。稀疏預測器沒有這個問題,即使對于非常深的樹,它也能在 GPU 上提供快速的推斷。
結論
在稀疏森林的支持下, FIL 適用于更廣泛的問題。無論您是使用 XGBoost 構建梯度增強的決策樹,還是使用 cuML 或 sciket learn 構建隨機林, FIL 都應該是一個方便的選擇,可以加速您的推理。一如既往,如果您遇到任何問題,請隨時訪問 GitHub 上的文件問題 或在 我們的公共休閑頻道 中提問!
?