
實例分割是檢測和分割目標的一個核心視覺識別問題。在過去幾年中,該領域一直是計算機視覺領域的圣杯之一,其應用范圍廣泛,包括自動駕駛汽車( AV )、機器人技術、視頻分析、智能家居、數字人類和醫療保健。
注釋是對圖像或視頻中的每個對象進行分類的過程,是實例分割的一個具有挑戰性的組成部分。訓練 面具 R-CNN 等傳統實例分割方法需要同時使用對象的類標簽、邊界框和分割遮罩。
然而,獲取分割掩模既昂貴又耗時。例如, 可可數據集 需要大約 70000 小時的時間來注釋 200k 圖像,其中 55000 小時用于收集對象遮罩。
介紹 Discobox
為了加快注釋過程, NVIDIA 研究人員開發了 DiscoBox 框架。該解決方案使用了一種弱監督學習算法,可以在訓練期間輸出高質量的實例分割,而無需掩碼注釋。
該框架直接從邊界框監控生成實例分段,而不是使用掩碼注釋直接監控任務。邊界框作為一種基本的注釋形式被引入,用于訓練現代對象檢測器,并使用帶標簽的矩形來緊密地包圍對象。每個矩形對對象的定位、大小和類別信息進行編碼。
邊界框標注是工業計算機視覺應用的最佳選擇。它包含豐富的本地化信息,并且非常容易繪制,使得在注釋大量數據時,它更經濟、更具可擴展性。然而,它本身不提供像素級信息,不能直接用于訓練實例分割。
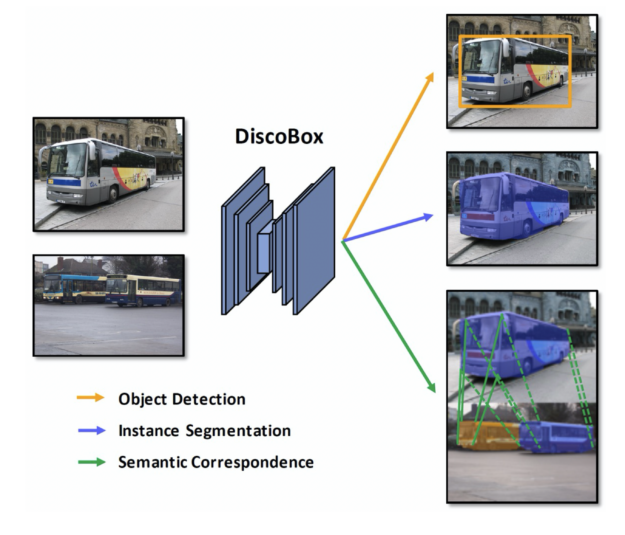
DiscoBox 的創新功能
DiscoBox 是第一個弱監督的實例分割算法,它在減少標記時間和成本的同時,提供了與完全監督方法相當的性能。例如,這種方法比傳說中的面具 R-CNN 更快、更準確,在訓練期間不需要面具注釋。這就提出了一個問題,即在未來的實例分割應用中,是否真的需要掩碼注釋,因為需要更少的標記。
DiscoBox 也是第一個在盒子監督下將實例分割和多對象語義對應結合起來的弱監督算法。這兩項任務在許多計算機視覺應用中都很有用,例如 3D 重建,并且可以相互幫助。例如,通過實例分割預測的對象遮罩可以幫助語義對應關注前景對象像素,而語義對應可以細化遮罩預測。 DiscoBox 將這兩項任務統一在盒子的監督下,使他們的模型訓練變得簡單且可擴展。
DiscoBox 的中心是一個師生設計。該設計的特點是使用自我一致性作為自我監督,以取代 DiscoBox 培訓中缺失的面罩監督。該設計有效地促進了高質量的口罩預測,即使在訓練中沒有口罩注釋。
DiscoBox 應用
除了作為 NVIDIA 人工智能應用程序的自動標簽工具包之外, DiscoBox 還有許多應用程序。通過自動化昂貴的掩碼注釋,該工具可以幫助智能視頻分析或 AV 領域的產品團隊節省大量注釋預算。




另一個潛在的應用是 3D 重建,在這個領域中,對象遮罩和語義對應都是重建任務的重要信息。 DiscoBox 能夠在只有邊界框監控的情況下提供這兩個輸出,幫助在開放世界場景中生成大規模 3D 重建。這將有助于構建虛擬世界的許多應用程序,如內容創建、虛擬現實和數字人類。
有關模型或使用代碼的更多信息,請訪問 GitHub 上的 DiscoBox 。
要了解更多關于 NVIDIA 正在進行的研究,請訪問 NVIDIA Research 。
?





