你可以提出一個論點,即文明和技術進步的歷史就是物質的探索和發現的歷史。時代不是以領導人或文明命名的,而是以定義他們的材料命名的:石器時代、青銅時代等等。當前的數字或信息時代可以改名為硅或半導體時代,并保留相同的含義。
盡管硅和其他半導體材料可能是當今推動變革的最重要的材料,但研究中還有其他幾種材料同樣可以推動下一代變革,包括以下任何一種:
- 高溫超導體
- 光伏
- 石墨烯電池
- 超級電容器
半導體是構建芯片的核心,這些芯片能夠對這種新型材料進行廣泛而復雜的搜索。
2011 年,美國 Materials Genome Initiative 推動使用模擬識別新材料。然而,在當時,甚至在今天的某種程度上,即使在現代超級計算機上,根據第一原理計算材料性質也可能會非常緩慢。
Vienna Ab initio Simulation Package (VASP) 是用于此類預測的最流行的軟件工具之一,它的編寫目的是利用加速技術并盡可能縮短洞察時間。
新材料審查: Hafnia
本文研究了一種叫做鉿或氧化鉿( HfO )的材料的性質計算2.).
就其本身而言,鉿是一種電絕緣體。它在半導體制造中大量使用,因為在構建動態隨機存取存儲器( DRAM )存儲時,它可以充當高κ介電膜。它還可以作為金屬氧化物半導體場效應晶體管( MOSFET )的柵極絕緣體。 Hafnia 對非易失性電阻 RAM 非常感興趣,這可能會使啟動計算機成為過去。
而理想的純 HfO2.晶體只能用 12 個原子來計算,這只是一個理論模型。這種晶體實際上含有雜質。
有時,必須添加摻雜劑以產生超出絕緣的所需材料特性。這種摻雜可以在純度水平上進行,這意味著在 100 個合格原子中,一個原子被不同的元素取代。至少有 12 個原子,其中只有 4 個是 Hf 。很快,很明顯,這樣的計算很容易需要數百個原子。
這篇文章演示了如何在數百甚至數千 GPU 上高效地并行化此類計算。 Hafnia 是一個例子,但這里所展示的原理當然也可以應用于類似大小的計算。
術語定義
- Speedup :相對于參考的無維度性能度量。對于這篇文章,參考是使用 8x A100 80 GB SXM4 GPU 而不啟用 NCCL 的單節點性能。加速是通過將參考運行時間除以經過的運行時間來計算的。
- Linear scaling: 完全平行的應用程序的加速曲線。根據 Amdahl 定律,它適用于 100% 并行化且互連速度無限快的應用程序。在這種情況下, 2 倍的計算資源將導致一半的運行時間, 10 倍的計算時間將導致十分之一的運行時間。當繪制與計算資源數量相比的加速時,性能曲線是一條向上向右傾斜 45 度的直線。并行運行的效果優于此比例關系。也就是說,坡度將大于 45 度,這被稱為超線性縮放。
- Parallel efficiency: 以百分比表示的特定應用程序執行與理想線性縮放的接近程度的無量綱度量。并行效率通過將所獲得的加速率除以該計算資源數量的線性縮放加速率來計算。為了避免浪費計算時間,大多數數據中心都有最低并行效率目標( 50-70% )的策略。
VASP 用例和區別
VASP 是電子結構計算和第一原理分子動力學中應用最廣泛的應用之一。它提供了最先進的算法和方法來預測材料性能,如前面所討論的。
GPU 加速度使用 OpenACC 實現。 GPU 通信可以使用 NVIDIA HPC-X 或 NVIDIA Collective Communications Library ( NCCL )中的 Magnum IO MPI 庫來執行。
混合 DFT 的用例和區別
本節側重于使用稱為密度泛函理論( DFT )的量子化學方法,通過將精確交換計算與 DFT 內的近似值混合,從而實現更高精度的預測,然后稱為混合 DFT 。這種增加的精度有助于根據實驗結果確定帶隙。
帶隙是將材料分類為絕緣體、半導體或導體的特性。對于基于鉿的材料,這種額外的精度是至關重要的,但計算復雜度會增加。
將這一點與使用多個原子的需求結合起來,證明了在 GPU 加速的超級計算機上擴展到多個節點的需求。幸運的是, VASP 中有更高精度的方法。有關其他功能的更多信息,請參見 VASP6 。
在更高的層次上, VASP 是一種量子化學應用程序,它與 NAMD 、 GROMACS 、 LAMMPS 和 AMBER 等其他高性能計算( HPC )計算化學應用程序不同,甚至可能更為熟悉。這些代碼側重于分子動力學( MD ),通過簡化原子之間的相互作用,例如將它們視為點電荷。這使得模擬這些原子的運動(比如因為溫度)在計算上變得廉價。
另一方面, VASP 在量子水平上處理原子之間的相互作用,因為它計算電子如何相互作用并形成化學鍵。它還可以為量子或從頭計算 MD ( AIMD )模擬導出力和移動原子。這確實對本文討論的科學問題很有意思。
然而,這種模擬將包括多次重復混合 DFT 計算步驟。雖然后續步驟可能會更快地收斂,但每個單獨步驟的計算輪廓不會改變。這就是為什么我們在這里只顯示了一個離子步驟。
運行單節點或多節點
許多 VASP 計算使用的化學系統足夠小,不需要在 HPC 設施上執行。一些用戶可能會對在多個節點上擴展 VASP 感到不舒服,并在解決方案的過程中遭受痛苦,甚至可能導致停電或其他故障。其他人可能會限制他們的模擬大小,這樣運行時就不會像研究更適合的系統大小那樣繁重。
有多種原因可以促使您多節點運行仿真:
- 在一個節點上運行模擬需要不可接受的時間,即使后者可能更有效。
- 需要大量內存且無法容納在單個節點上的大型計算需要分布式并行。雖然某些計算量必須在節點之間復制,但大多數計算量都可以分解。因此,每個節點所需的內存量大致由參與并行任務的節點數量決定。
有關多節點并行性和計算效率的更多信息,請參閱最近的 HPC for the Age of AI and Cloud Computing 電子書。
NVIDIA 使用數據集 Si256 _ VJT _ HSE06 發布了 study of multi-node parallelism 。在這項研究中, NVIDIA 提出了一個問題,“對于這個數據集,以及 V100 系統和 InfiniBand 網絡?的 HPC 環境,我們可以合理地擴展到什么程度?”
Magnum IO 并行通信工具
VASP 使用 NVIDIA Magnum IO 庫和技術來優化多 GPU 和多節點編程,以提供可擴展的性能。這些是 NVIDIA HPC SDK 的一部分。
在本文中,我們將介紹兩個通信庫:
- Message Passing Interface ( MPI ):編程分布式內存可擴展系統的標準。
- NVIDIA Collective Communications Library ( NCCL ):使用 MPI 兼容的全聚集、全減少、廣播、減少、減少分散和點對點例程,實現高度優化的多 GPU 和多節點集體通信原語,以利用 HPC 服務器節點內和跨 HPC 服務器節點的所有可用 GPU 。
VASP 用戶可以在運行時選擇應該使用什么通信庫。當 MPI 替換為 NCCL 時,性能通常會顯著提高,這是 VASP 中的默認設置。
在 MPI 上使用 NCCL 時,觀察到的差異有兩個強烈的原因。
使用 NCCL ,通信由 GPU 啟動并具有流感知。這消除了 GPU 到 – CPU 同步的需要,否則,在每個 CPU 啟動 MPI 通信之前都需要進行同步,以確保在 MPI 庫接觸緩沖區之前所有 GPU 操作都已完成。 NCCL 通信可以像內核一樣在 CUDA 流上排隊,并且可以促進異步操作。 CPU 可以對進一步的操作進行排隊,以保持 GPU 忙碌。
在 MPI 情況下, GPU 至少在完成 MPI 通信后 CPU 入隊并啟動下一個 GPU 操作所需的時間內是空閑的。最小化 GPU 空閑時間有助于提高 parallel efficiencies 。
使用兩個單獨的 CUDA 流,您可以輕松地使用一個流進行 GPU 計算,另一個流用于通信。鑒于這些流是獨立的,通信可以在后臺進行,并且可能完全隱藏在計算后面。實現后者是邁向高并行效率的一大步。此技術可用于任何啟用雙緩沖方法的程序中。
非阻塞 MPI 通信也可以帶來類似的好處。但是,您仍然必須手動處理 GPU 和 CPU 之間的同步,并具有所描述的性能缺點。
由于非阻塞 MPI 通信也必須在 CPU 側同步,因此增加了另一層復雜性。與使用 NCCL 相比,這從一開始就需要更詳細的代碼。然而,由于 MPI 通信是由 CPU 啟動的,因此通常沒有硬件資源自動使通信真正異步。
如果您的應用程序有 CPU 內核可供使用,您可以生成 CPU threads 以確保通信進度,但這再次增加了代碼復雜性。否則,通信可能僅在進程進入 MPI _ Wait 時發生,這與使用阻塞調用相比沒有任何優勢。
另一個需要注意的區別是,對于縮減,數據在 CPU 上進行匯總。在單線程 CPU 內存帶寬低于網絡帶寬的情況下,這可能也是一個意外的瓶頸。
另一方面, NCCL 使用 GPU 求和,并了解拓撲結構。在節點內,它可以使用可用的 NVLink 連接,并使用 Mellanox 以太網、 InfiniBand 或類似結構優化節點間通信。
使用 HfO 的計算建模測試用例2.
鉿晶體由兩種元素構成:鉿( Hf )和氧( O )。在沒有摻雜劑或空位的理想系統中,對于每個 Hf 原子,將有兩個 O 原子。描述無限延伸晶體結構所需的最小原子數是四個 Hf (黃色)和八個 O (紅色)原子。圖 2 顯示了結構。
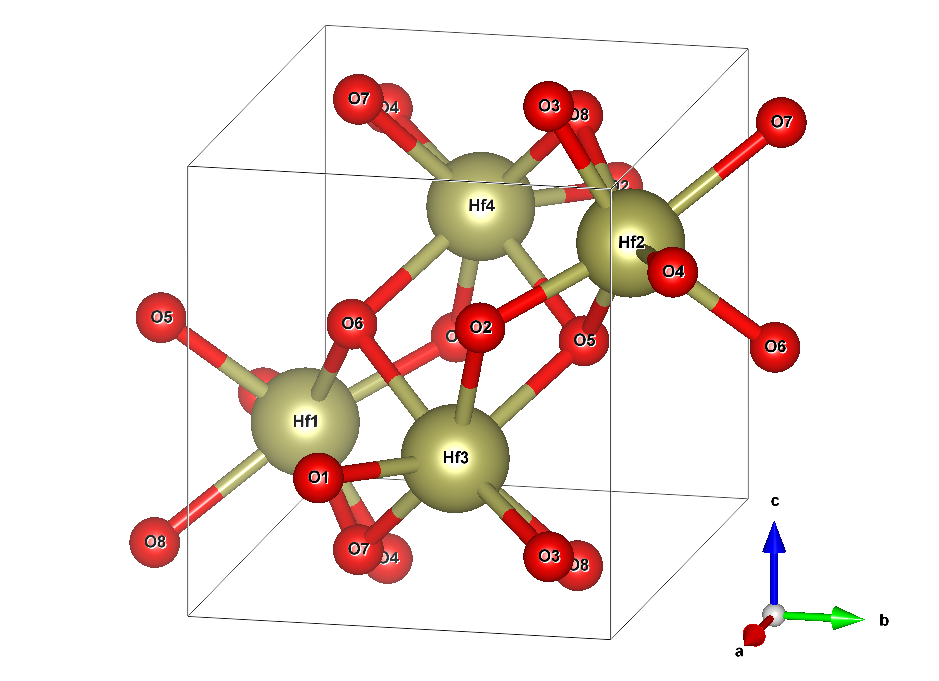
框線框指定所謂的單位單元。它在所有三維空間中重復,產生無限延伸的晶體。這張圖片暗示了通過在晶胞外復制原子 O5 、 O6 、 O7 和 O8 來顯示它們與 Hf 原子的各自鍵。該電池的尺寸為 51.4 × 51.9 × 53.2 納米。這不是一個完美的長方體,因為它的一個角度是 99.7 °而不是 90 °。
最小模型僅明確地處理圖 2 中框中的 12 個原子。但是,您也可以將長方體在一個或多個空間方向上延長相應邊的整數倍,并將原子的結構復制到新創建的空間中。這樣的結果被稱為超級細胞,可以幫助治療在最小模型內無法達到的效果,例如 1% 的氧空位。
當然,用更多的原子處理更大的細胞在計算上要求更高。當您再添加一個單元時,在 a 方向上總共有兩個單元,同時保留 b 和 c ,這稱為具有 24 個原子的 2x1x1 超級單元。
為了本研究的目的,我們只考慮了成本足以證明至少使用少數超級計算機節點的超級單元:
- 2x2x2 : 96 個原子, 512 個軌道
- 3x3x2 : 216 個原子, 1280 個軌道
- 3x3x3 : 324 個原子, 1792 個軌道
- 4x4x3 : 576 個原子, 3072 個軌道
- 4x4x4 : 768 個原子, 3840 個軌道
請記住,計算工作量與原子數或晶胞體積不成正比。本案例研究中使用的粗略估計是,它與任何一個都成立方比例。

當然,這里使用的哈夫尼亞系統只是一個例子。由于基本算法和通信模式不會改變,因此這些經驗教訓也可以轉移到使用類似大小單元和混合 DFT 的其他系統。
如果你想用 HfO 做一些測試2.,您可以 下載輸入文件?用于本研究。出于版權原因,我們可能不會重新分發 POTCAR 文件。此文件在所有超級單元格中都是相同的。作為 VASP 許可證持有人,您可以通過以下 Linux 命令從提供的文件中輕松創建它:
# cat PAW_PBE_54/Hf_sv/POTCAR PAW_PBE_54/O/POTCAR > POTCAR
對于這些定標實驗,我們強制使用恒定數量的晶體軌道,或 bands 。這會略微增加工作量,超出所需的最小值,但不會影響計算精度。
如果沒有這樣做, VASP 將自動選擇一個可以被 GPU 的整數整除的數字,這可能會增加某些節點計數的工作量。我們選擇了可被所有 GPU 計數整除的軌道數。此外,為了更好的計算可比性, k 點的數量保持固定為 8 ,即使更大的超級單元在實踐中可能不需要這一點。
基于 VASP 的超級電池建模測試方法
以下列出的所有基準測試均使用最新的 VASP 6.3.2 版本,該版本使用 NVIDIA HPC SDK 22.5 和 CUDA 11.7 編譯。
作為完整參考,makefile.include?已可下載?。它們在由 560 個 DGX A100 節點組成的 NVIDIA Selene supercomputer 上運行,每個節點提供八個 NVIDIA A100-SXM4-80GB GPU 、八個 NVVIDIA ConnectX-6 HDR InfiniBand 網絡接口卡( NIC )和兩個 AMD EPYC 7742 CPU 。
為了確保最佳性能,進程和線程被固定到 CPU 上的 NUMA 節點,這些節點為它們將使用的相應 GPU 和 NIC 提供理想的連接。 AMD EPYC 上的反向 NUMA 節點編號產生以下最佳硬件位置的進程綁定。
| Node local rank | CPU NUMA node | GPU ID | NIC ID |
| 0 | 3 | 0 | mlx5_0 |
| 1 | 2 | 1 | mlx5_1 |
| 2 | 1 | 2 | mlx5_2 |
| 3 | 0 | 3 | mlx5_3 |
| 4 | 7 | 4 | mlx5_6 |
| 5 | 6 | 5 | mlx5_7 |
| 6 | 5 | 6 | mlx5_8 |
| 7 | 4 | 7 | mlx5_9 |
downloadable files 集合中包括一個名為selenerun-ucx.sh的腳本。該腳本通過在工作負載管理器(例如 Slurm )作業腳本中執行以下操作來包裝對 VASP 的調用:
# export EXE=/your/path/to/vasp_std # srun ./selenerun-ucx.sh
selenerun-ucx.sh文件必須根據可用的資源配置進行定制,以匹配您的環境。例如,每個節點的 GPU 數量或 NIC 數量可能與 Selene 不同,腳本必須反映這些差異。
為了盡可能縮短基準測試的計算時間,我們通過在 INCAR 文件中設置NELM=1,將所有計算限制為僅一個電子步驟。我們之所以能做到這一點,是因為我們不關心總能量等科學結果,而運行一個電子步驟就足以預測整個運行的性能。這樣的運行需要 19 次迭代才能與 3x3x2 超級單元收斂。
當然,每個不同的單元設置可能需要不同的迭代次數,直到收斂。為了對縮放行為進行基準測試,無論如何都需要比較固定的迭代次數,以保持工作負載的可比性。
然而,僅使用一次電子迭代評估跑步的性能會誤導您,因為配置文件是不平衡的。與凈迭代相比,初始化時間所占的份額要大得多,而像力計算這樣的后收斂部分也是如此。
幸運的是,電子迭代都需要同樣的努力和時間。您可以使用以下公式預測代表性運行的總運行時間:
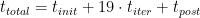
您可以從 VASP 內部 LOOP 計時器中提取一次迭代的時間
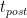
另一方面,初始化時間
VASP 中混合 DFT 迭代的并行效率結果
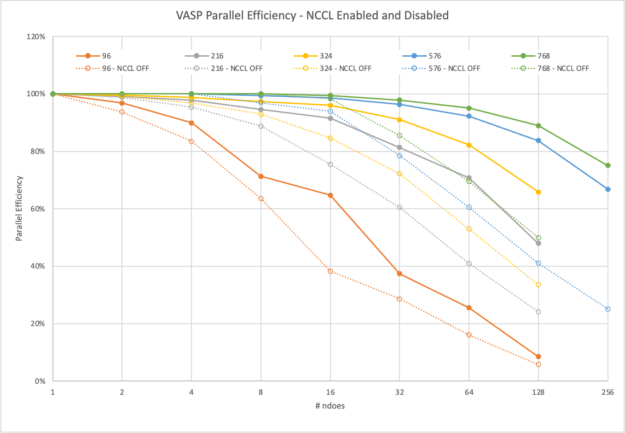
我們首先回顧了 96 個原子的最小數據集: 2x2x2 超級電池。如今,這個數據集幾乎不需要超級計算機。它的完整運行, 19 次迭代,在一個 DGX A100 上大約 40 分鐘內完成。
盡管如此,通過 MPI ,它可以以 93% 的并行效率擴展到兩個節點,然后在四個節點上下降到 83% ,甚至在八個節點上降低到 63% 。
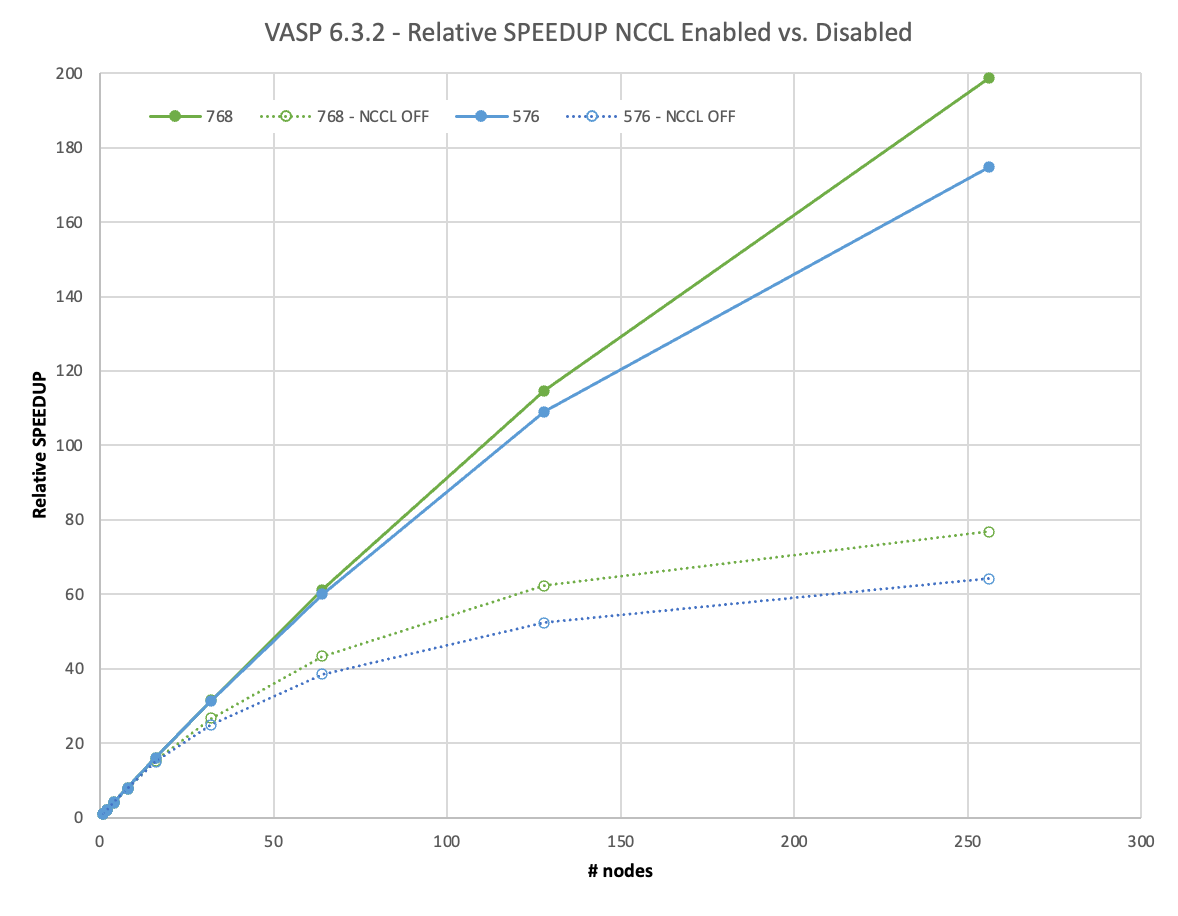
另一方面, NCCL 在兩個節點上實現了近乎理想的 97% 的縮放,在四個節點上達到了 90% ,甚至在八個節點上也達到了 71% 。然而, NCCL 的最大優勢在 16 個節點上得到了明顯的證明。與僅使用 MPI 的 6 倍相比,您仍然可以看到> 10 倍的相對加速。
超過 64 個節點的負縮放需要解釋。要使用 1024 GPU 運行 128 個節點,還必須使用 1024 個軌道。其他計算只使用了 512 ,因此這里的工作量增加了。不過,我們不想在低節點運行中包含如此多的軌道計數。
下一個例子已經是一個具有計算挑戰性的問題。在單個節點上的 8xA100 上,完成具有 216 個原子的 3x3x2 超級電池的完整計算需要超過 7.5 小時。
隨著計算需求的增加,有更多的時間在后臺使用 NCCL 異步完成通信。 VASP 在 16 個節點之前保持在 91% 以上,僅在 128 個節點上接近 50% 。
使用 MPI , VASP 無法有效隱藏通信,即使在 8 個節點上也無法達到 90% ,在 64 個節點上已降至 41% 。
圖 5 顯示,對于下一個具有 324 個原子的更大 3x3x3 超級電池,縮放行為的趨勢保持不變,這需要一整天的時間才能在單個節點上解決。然而,使用 NCCL 和 MPI 之間的差異顯著增加。在使用 NCCL 的 128 個節點上,您可以獲得 2 倍的相對加速。
如果是一個更大的 4x4x3 超級電池,包含 576 個原子,那么使用一個 DGX A100 進行完整計算需要等待 5 天以上。
然而,對于如此苛刻的數據集,必須討論一個新的影響:內存容量和并行化選項。 VASP 提供在 k 點上分配工作負載,同時在這種設置中復制內存。雖然這對于標準 DFT 運行更有效,但也有助于提高混合 DFT 計算的性能,而且無需保留未使用的可用內存。
對于較小的數據集,即使在所有 k 點上進行并行化,也很容易適合 8xA100 GPU ,每個點都有 80GB 的內存。對于 576 原子數據集,在單個節點上,情況不再如此,我們必須減少 k 點的并行性。從兩個節點開始,我們可以再次充分利用它。
雖然在圖 6 中無法區分,但在 MPI 情況下,兩個節點上存在輕微的超線性縮放( 102% 的并行效率)。這是因為在兩個或更多節點上提升的一個節點上的并行度必然降低。然而,這也是你在實踐中會做的。
對于一個節點和兩個節點上有 768 個原子的 4x4x4 超級電池,我們面臨著類似的情況,但超線性縮放效應在那里更不明顯。
我們將 4x4x3 和 4x4x4 超級單元擴展到 256 個節點。這相當于 2048 A100 GPU 。使用 NCCL ,他們實現了 67% 甚至 75% 的并行效率。這使您能夠在不到 1.5 小時的時間內生成結果,而以前在一個節點上幾乎需要 12 天的時間! NCCL 的使用使這種大型計算的相對速度比 MPI 快 3 倍。
VASP 模擬中使用 NCCL 的建議
VASP 6.3.2 計算 HfO2.當 NVIDIA InfiniBand 網絡增強的 NVIDIA GPU 加速 HPC 環境可用時,通過在多個節點上使用 NVIDIA NCCL ,范圍從 96 到 768 個原子的超級單元實現了顯著的性能。
基于此測試,我們建議有能力訪問 HPC 環境的用戶考慮以下事項:
- 使用 GPU 加速度運行除最小計算之外的所有計算。
- 考慮使用 GPU 和多個節點運行更大的原子系統,以盡量縮短洞察時間。
- 使用 NCCL 啟動所有多節點計算,因為它只會在運行大型模型時提高效率。
初始化 NCCL 時稍微增加的開銷值得權衡。
總結
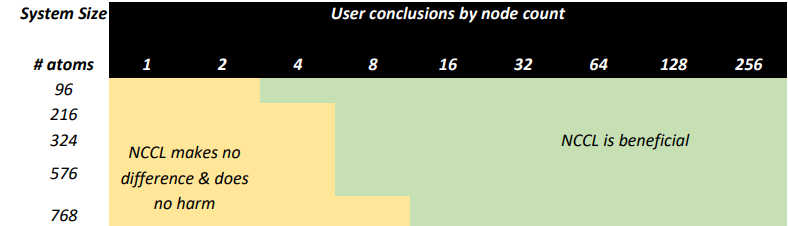
總之,您已經看到 VASP 中混合 DFT 的可伸縮性取決于數據集的大小。鑒于數據集越小,每個個體 GPU 的計算負載越早耗盡,這在某種程度上是意料之中的。
NCCL 也有助于隱藏所需的通信。圖 7 顯示了具有不同節點數的特定數據集大小的并行效率水平。對于大多數計算密集型數據集, VASP 在 32 個節點上的并行效率達到 80% 以上。對于我們的一些客戶要求的最苛刻的數據集,可以在 256 個節點上高效地進行橫向擴展。
VASP 用戶體驗
根據我們與 VASP 用戶的經驗,在 GPU 加速基礎設施上運行 VASP 是一種積極而富有成效的體驗,使您能夠考慮更大、更復雜的模型進行研究。
在未加速的場景中,您可能運行的模型比您想要的小,因為您希望運行時增長到無法忍受的水平。使用具有 GPU 的高性能、低延遲 I / O 基礎設施,以及具有 Magnum IO 加速技術(如 NCCL )的 InfiniBand ,可以實現高效、多節點并行計算,并為研究人員提供更大的模型。
HPC 系統管理員的好處
HPC 中心,特別是商業中心,通常有禁止用戶以低并行效率運行作業的政策。這防止了在短期限內或需要高周轉率的用戶以犧牲其他用戶的工作等待時間為代價使用更多的計算資源。通常情況下,一個簡單的經驗法則是 50% 的并行效率決定了用戶可能請求的最大節點數,從而增加了解決問題的時間。
我們在這里已經表明,通過將 NCCL 作為 NVIDIA Magnum IO 的一部分,加速 HPC 系統的用戶可以在效率限制內保持良好狀態,并在單獨使用 MPI 時比可能的工作擴展得更遠。這意味著,在保持 HPC 系統的總體吞吐量處于最高水平的同時,您可以最小化運行時間并最大化模擬次數,以完成新的令人興奮的科學。
HPC 應用程序開發人員的優勢
作為應用程序開發人員,您也可以從 VASP 的優勢中獲益。要開始:
- 下載 NCCL 。
- 閱讀 NCCL User Guide 。
- 回顧流行的 Fast Inter-GPU Communication with NCCL for Deep Learning Training, and More (a Magnum IO session) GTC 會話。
- 閱讀以下信息性帖子:
?