隨著人工智能技術的不斷發展,大型語言模型(LLM) 的有效數據管理成為一個重要挑戰。數據是模型性能的核心。盡管大多數先進的 機器學習 算法以數據為中心,但由于各種因素(如隱私、監管、地緣政治、版權問題和移動大型數據集所需的巨大努力),并非所有必要數據都可以集中。
本文探討了如何利用聯邦學習(FL),由NVIDIA FLARE提供支持,以簡單且可擴展的方式應對這些挑戰。這些功能支持監督式微調和參數效率的精細調整,從而增強模型的準確性和穩健性。
數據挑戰
在許多 LLM 任務中,需要從多個來源獲取數據是一種常見場景。例如,為醫學研究收集來自不同醫院的報告,或從各種機構收集金融數據進行分析。集中這些數據可能不切實際,也可能受到隱私問題、法規和其他障礙的限制。聯合學習提供了一個精美的解決方案。
聯合學習
FL 已成為解決這些數據挑戰的技術。這種方法通過共享模型而不是原始數據來繞過使用集中數據的模型訓練,參與者可以在本地使用其私有數據集訓練模型,并將更新的模型參數聚合到全局。
這種方法可以保護底層數據的隱私,同時允許全局模型共享在訓練過程中獲得的知識,從而產生更強大且通用的模型。有關特定示例,請參閱 針對患有新冠肺炎 (COVID-19) 的患者預測臨床結果的聯邦學習。
FL 提供了各種用于訓練 AI 模型的選項。一般來說,FL 可以訓練全局模型,同時保護數據隱私和治理。訓練可以根據每位客戶進行定制,從而提供個性化模型。除了訓練之外,FL 基礎設施還可用于推理和聯邦評估。
基礎模型
基礎模型在大量通用文本數據上進行預訓練。然而,它們可能不專門針對特定領域或下游任務。通過進一步微調,可以使這些模型適應特定領域和任務,從而更有效地提供領域和任務特定的結果。這對于充分發揮其潛力以及適應各種不斷變化的應用需求至關重要。
微調技術
監督式微調(SFT) 和 參數效率的精細調整(PEFT) 是兩種方法,旨在高效、有效地根據基礎模型為特定領域和任務定制模型。這兩種方法均基于基礎模型實現領域和任務特定的調整。
SFT 微調所有 LLM 參數 .PEFT 嘗試在保持 LLM 參數不變的情況下添加調整參數或層,從而成為一種經濟高效且資源高效的選擇。這兩種技術在利用 LLM 的強大功能的各種應用中發揮著關鍵作用,提供定制的資源感知解決方案。
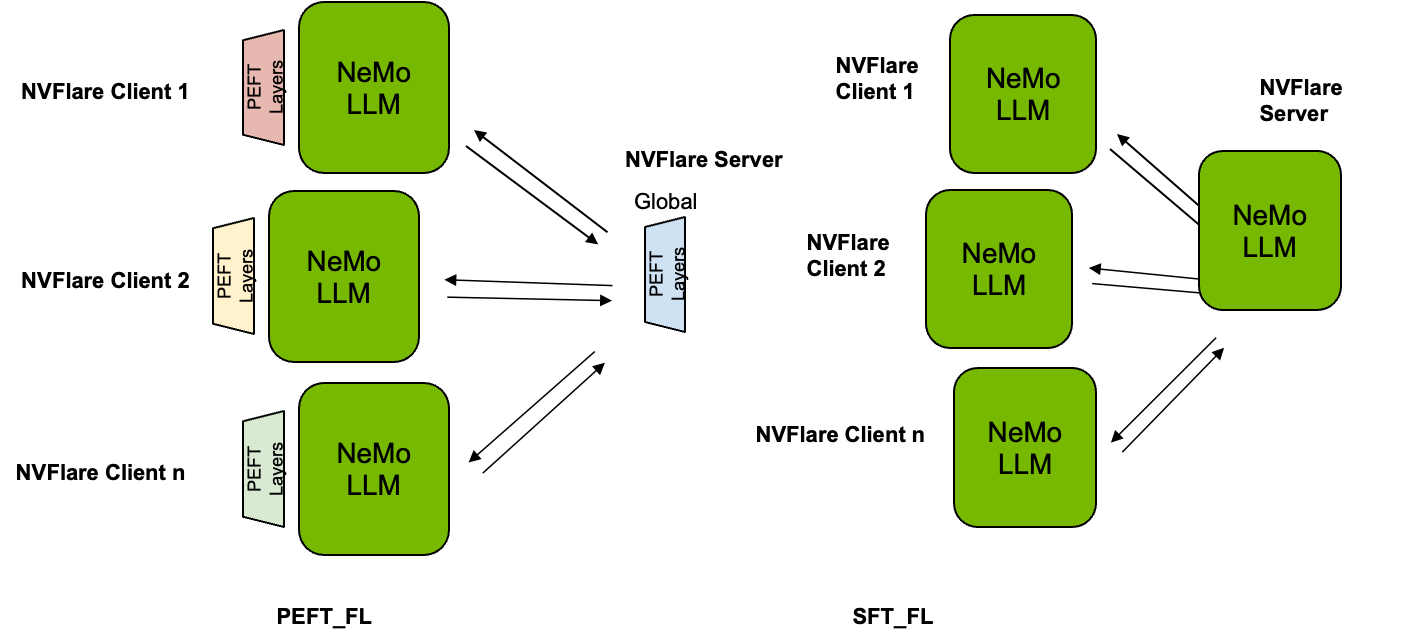
用于 LLM 調整的 FL
與其他 AI 技術一樣,LLM 性能受益于更大、更多樣化的數據集。更多數據通常意味著更高的準確性、更強的可靠性和更強的通用性。
如圖 1 所示,使用 PEFT 時,基礎 LLM 的參數凍結,并且在訓練和評估期間保持不變,因此只有這些參數在本地客戶端進行調整,并在全局級別進行聚合。相反,使用 SFT 時,整個 LLM 進行微調,并使用所有參數進行聚合。
使用 Lightning 客戶端 API 輕松進行調整
為了在本文中展示 PEFT 和 SFT 的應用,我們使用了來自 NVIDIA NeMo 的模型。NeMo 利用 PyTorch Lightning 進行模型訓練。NVIDIA FLARE 2.4 提供了 Lightning 客戶端 API,它顯著簡化了將本地訓練腳本轉換為在 FL 場景中運行的過程。只需少量代碼更改,您便可無縫集成 PEFT 和 SFT 等方法。
如下所示,Lightning 訓練器可通過調用flare.patch(trainer).接下來是額外的 while 循環 (while flare.is_running:),以便在每輪 FL 中重復使用相同的訓練器對象。可選地,調用trainer.validate(model)在客戶端的數據上評估來自 FL 服務器的全局模型,這有助于基于從每個客戶端接收的驗證分數選擇服務器上的全局模型。
from nemo.core.config import hydra_runnerfrom nemo.utils import loggingfrom nemo.utils.exp_manager import exp_managermp.set_start_method("spawn", force=True)# (0): import nvflare lightning apiimport nvflare.client.lightning as flare |
# (1): flare patch flare.patch(trainer) # (2): Add while loop to keep receiving the FLModel in each FL round. # Note, after flare.patch the trainer.fit/validate will get the # global model internally at each round. while flare.is_running(): # (optional): get the FL system info fl_sys_info = flare.system_info() print("--- fl_sys_info ---") print(fl_sys_info) # (3) evaluate the current global model to allow server-side model selection. print("--- validate global model ---") trainer.validate(model) # (4) Perform local training starting with the received global model. print("--- train new model ---") trainer.fit(model) |
通過串流實現可擴展模型訓練
主流 LLM 的規模巨大,從幾十億個參數到數十億個參數不等,這會導致模型規模大幅增加 .SFT 會對整個網絡進行微調,因此整個模型需要傳輸和聚合。為了在 FL 中使用最新的 LLM,這種傳輸挑戰需要得到適當的解決。
NVIDIA FLARE 2.4 可加快大型文件的流式傳輸速度。利用此功能,可以在 FL 設置下通信大量數據。
聯邦 PEFT 和 SFT 性能
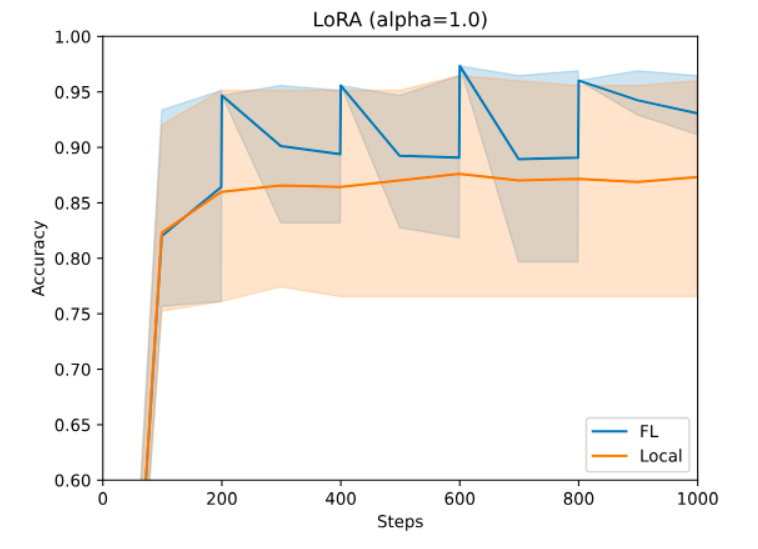
對于 PEFT,您可以使用 NeMo 的 PEFT 方法。通過簡單的配置更改,您可以嘗試多種 PEFT 技術,如 p-tuning、adapters 或 LoRA,這些技術向 LLM 引入了少量的可訓練參數。這些參數使得模型能夠生成下游任務所需的輸出。圖 3 展示了在使用 LoRA 進行金融情緒預測任務時,NeMo Megatron-GPT2 345M 模型的準確性。
使用 Dirichlet 采樣策略創建異構分區,詳情請參閱 匹配平均值的聯邦學習.在這種情況下,任何一個站點都無法僅使用本地數據實現所需的性能。但是,它們可以使用 FL 進行協作,因為它們可以有效使用更大的數據集,同時不會丟失數據的隱私和治理權。有關詳細信息,請訪問 NVIDIA/NVFlare 在 GitHub 上提供。
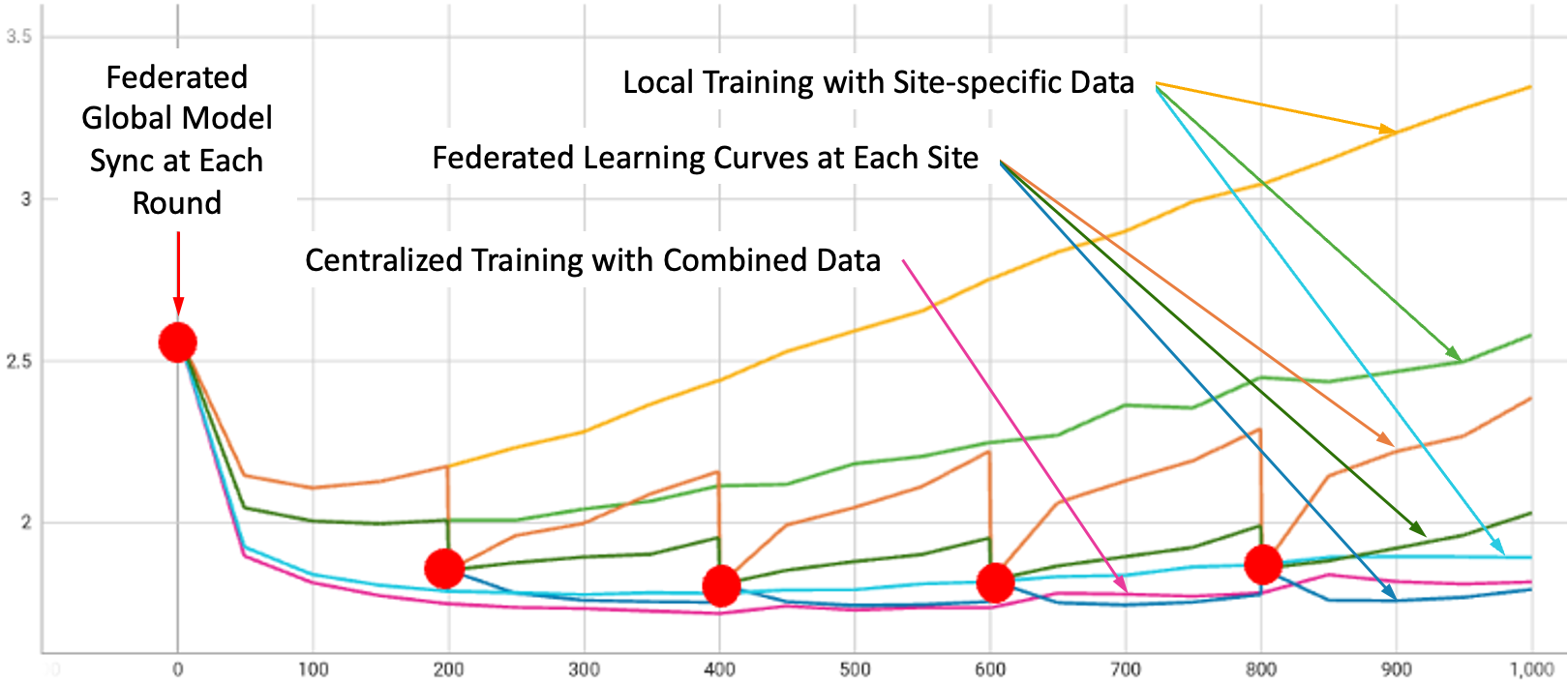
在 SFT 過程中,我們使用了 NeMo Megatron-GPT 1.3B 模型進行五輪訓練,每輪使用三個不同的數據集:Alpaca、databricks-dolly-15k 和 OpenAssistant 對話。每個客戶端都有自己對應的數據集。
圖 3 展示了所有實驗設置下的驗證曲線:在每個三個數據集上進行本地訓練、在組合數據集上進行本地訓練,以及使用 FedAvg 算法訓練所有三個客戶端的 FL。平滑曲線表示本地訓練,而紅點識別的步驟曲線表示 FL。步驟是由于在每輪 FL 開始時進行的全局模型聚合和更新。
評估大語言模型(LLM)可能是一項非常困難的任務。根據熱門基準任務,我們在零樣本設置下執行了三項語言 modeling 任務,包括HellaSwag(H)、PIQA(P) 和 WinoGrande(W)。表 1 顯示了每個 SFT 模型的結果,BaseModel 表示 SFT 之前的模型。
如圖所示,FL 可以通過結合來自各種來源的更新來實現比使用單個站點數據進行訓練更好的整體性能。
| ? | H_acc | H_acc _norm |
P_acc | P_acc _norm |
W_acc | 平均值 |
| 基礎模型 | 0.357 | 0.439 | 0.683 | 0.689 | 0.537 | 0.541 |
| 羊駝 | 0.372 | 0.451 | 0.675 | 0.687 | 0.550 | 0.547 |
| 杜利 | 0.376 | 0.474 | 0.671 | 0.667 | 0.529 | 0.543 |
| Oasst1 | 0.370 | 0.452 | 0.657 | 0.655 | 0.506 | 0.528 |
| 混合 | 0.370 | 0.453 | 0.685 | 0.690 | 0.548 | 0.549 |
| FedAvg | 0.377 | 0.469 | 0.688 | 0.687 | 0.560 | 0.556 |
總結
NVIDIA FLARE 和 NVIDIA NeMo 借助熱門微調方案 (包括使用 FL 的 PEFT 和 SFT) 輕松實現 LLM 的可擴展化,其中兩個主要特征是客戶端 API 和大型文件串流能力 .FL 提供了協作學習的潛力,以保護隱私并提高模型性能。
FL 為適應基礎 LLM 并在注重隱私的世界中解決數據挑戰帶來了激動人心的前景。專為針對各種領域和任務調整基礎 LLM 而設計的微調技術可在 FL 環境中輕松應用,并受益于更多樣化的數據的更大可用性 . NVIDIA FLARE 提供通信支持,以便促進協同 LLM 訓練。
這些技術與模型開發方面的進步相結合,為更靈活、更高效的 LLM 鋪平了道路。有關更多信息,請查看以下資源:
?