?
通過最新的 Memgraph 高級圖形擴展( MAGE )版本,您現在可以在幾秒鐘內從 Memgraph 運行 GPU 支持的圖形分析,同時使用 Python 。由 NVIDIA cuGraph 提供支持,以下圖形算法現在將在 GPU 上執行:
- PageRank (圖形分析)
- Louvain (社區檢測)
- 平衡切割(聚類)
- 光譜聚類(聚類)
- 點擊率(集線器與權威分析)
- 萊頓(社區檢測)
- Katz Centrality
- 中間性和中心性
本教程將向您展示如何使用 PageRank 圖分析和 Louvain 社區檢測來分析包含 130 萬關系的 Facebook 數據集。
在本教程結束時,您將知道如何:
- 使用 Python 在 Memgraph 中導入數據
- 在大規模圖形上運行分析并獲得快速結果
- 從 Memgraph 在 NVIDIA GPU 上運行分析
教程先決條件
要學習本圖形分析教程,您需要一個 NVIDIA GPU 、驅動程序和容器工具包。成功安裝后 NVIDIA GPU 驅動程序 和容器工具包,您還必須安裝以下四個工具:
- 碼頭工人 用于運行
mage-cugraph映像 - 朱皮特 為了分析圖形數據
- 煉金術 將 Memgraph 與 Python 連接
- Memgraph 實驗室 為了使圖形可視化
下一節將指導您為本教程安裝和設置這些工具。
碼頭工人
Docker 用于安裝和運行mage-cugraph Docker 映像。設置和運行 Docker 映像涉及三個步驟:
- 下載 Docker
- 下載教程數據
- 運行 Docker 映像,使其能夠訪問教程數據
1.下載 Docker
您可以通過訪問安裝 Docker 網頁,并按照操作系統的說明操作。
2.下載教程數據
在運行mage-cugraph Docker 映像之前,首先下載本教程中使用的數據。這允許您在運行時為 Docker 映像提供對教程數據集的訪問權限。
要下載數據,請使用以下命令克隆 jupyter memgraph 教程 GitHub repo ,并將其移動到jupyter-memgraph-tutorials/cugraph-analytics文件夾:
Git clone https://github.com/memgraph/jupyter-memgraph-tutorials.git
Cd jupyter-memgraph-tutorials/cugraph-analytics3.運行 Docker 鏡像
現在,您可以使用以下命令運行 Docker 鏡像并將車間數據裝載到/samples文件夾:
docker run -it -p 7687:7687 -p 7444:7444 --volume /data/facebook_clean_data/:/samples mage-cugraph運行 Docker 容器時,您應該會看到以下消息:
You are running Memgraph vX.X.X
To get started with Memgraph, visit https://memgr.ph/start執行 mount 命令后,教程所需的CSV文件將位于 Docker 映像內的/samples文件夾中, Memgraph 將在需要時找到它們。
Jupyter 筆記本
現在 Memgraph 已經運行,請安裝 Jupyter.本教程使用 JupyterLab,您可以使用以下命令安裝它:
pip install jupyterlab安裝 JupyterLab 后,使用以下命令啟動它:
jupyter lab煉金術
使用 煉金術 ,一個對象圖映射器( OGM ),用于連接到 Memgraph 并在 Python 中執行查詢。您可以將 Cypher 視為圖形數據庫的 SQL 。它包含許多相同的語言結構,如創建、更新和刪除。
下載 CMake 在您的系統上,然后您可以使用 pip 安裝 GQLAlchemy :
pip install gqlalchemyMemgraph 實驗室
您需要安裝的最后一個先決條件是: Memgraph 實驗室 連接到 Memgraph 后,您將使用它創建數據可視化。學 如何安裝 Memgraph 實驗室 作為操作系統的桌面應用程序。
安裝 Memgraph Lab 后,您現在應該 連接到 Memgraph 數據庫 .
此時,您終于準備好:
- 使用 GQLAlchemy 連接到 Memgraph
- 導入數據集
- 在 Python 中運行圖形分析
使用 GQLAlchemy 連接到 Memgraph
首先,將自己定位在 Jupyter 筆記本 .前三行代碼將導入gqlalchemy,通過host:127.0.0.1和port:7687連接到 Memgraph 數據庫實例,并清除數據庫。一定要從頭開始。
from gqlalchemy import Memgraph
memgraph = Memgraph("127.0.0.1", 7687)
memgraph.drop_database()
從 CSV 文件導入數據集。
接下來,您將執行以下操作: PageRank 以及使用 Python 的 Louvain 社區檢測。
導入數據
這個 Facebook 數據集 由八個 CSV 文件組成,每個文件具有以下結構:
node_1,node_2
0,1794
0,3102
0,16645
每條記錄表示連接兩個節點的邊。節點表示頁面,它們之間的關系是相互的。
有八種不同類型的頁面(例如,政府、運動員和電視節目)。頁面已重新編制匿名索引,所有頁面均已通過 Facebook 驗證真實性。
由于 Memgraph 在數據具有索引時導入查詢速度更快,因此在id屬性上使用標簽Page為所有節點創建查詢。
memgraph.execute(
"""
CREATE INDEX ON :Page(id);
"""
)
Docker 已經擁有對本教程中使用的數據的容器訪問權限,因此您可以通過./data/facebook_clean_data/文件夾中的本地文件進行列表。通過連接文件名和/samples/文件夾,可以確定它們的路徑。使用連接的文件路徑將數據加載到 Memgraph 中。
import os
from os import listdir
from os.path import isfile, join
csv_dir_path = os.path.abspath("./data/facebook_clean_data/")
csv_files = [f"/samples/{f}" for f in listdir(csv_dir_path) if isfile(join(csv_dir_path, f))]使用以下查詢加載所有 CSV 文件:
for csv_file_path in csv_files:
memgraph.execute(
f"""
LOAD CSV FROM "{csv_file_path}" WITH HEADER AS row
MERGE (p1:Page {{id: row.node_1}})
MERGE (p2:Page {{id: row.node_2}})
MERGE (p1)-[:LIKES]->(p2);
"""
)
有關使用 LOAD CSV 導入 CSV 文件的更多信息,請參閱 Memgraph 文檔 .
接下來,將 PageRank 和 Louvain 社區檢測算法與 Python 結合使用,以確定網絡中哪些頁面最重要,并找到網絡中的所有社區。
PageRank 重要性分析
要識別 Facebook 數據集中的重要頁面,您將執行 PageRank 。了解不同的 算法設置 這可以在調用 PageRank 時設置。
請注意,您還會發現MAGE中集成了其他算法。 Memgraph 應該有助于在大規模圖形上運行圖形分析。找到其他 Memgraph 教程 關于如何運行這些分析。
MAGE被集成以簡化 PageRank 的執行。以下查詢將首先執行算法,然后創建每個節點的rank屬性,并將其設置為cugraph.pagerank算法返回的值。
然后,該屬性的值將另存為變量rank。請注意,這項測試(以及本文介紹的所有測試)是在 NVIDIA GeForce GTX 1650 Ti 和 Intel Core i5-10300H CPU 上執行的,頻率為 2.50GHz ,內存為 16GB ,并在大約四秒鐘內返回結果。
memgraph.execute(
"""
CALL cugraph.pagerank.get() YIELD node,rank
SET node.rank = rank;
"""
)
接下來,使用以下 Python 調用檢索列組:
results = memgraph.execute_and_fetch(
"""
MATCH (n)
RETURN n.id as node, n.rank as rank
ORDER BY rank DESC
LIMIT 10;
"""
)
for dict_result in results:
print(f"node id: {dict_result['node']}, rank: {dict_result['rank']}")
node id: 50493, rank: 0.0030278728385218327
node id: 31456, rank: 0.0027350282311318468
node id: 50150, rank: 0.0025153975342989345
node id: 48099, rank: 0.0023413620866201052
node id: 49956, rank: 0.0020696403564964
node id: 23866, rank: 0.001955167533390466
node id: 50442, rank: 0.0019417018181751462
node id: 49609, rank: 0.0018211204462452515
node id: 50272, rank: 0.0018123518843272954
node id: 49676, rank: 0.0014821440895415787
此代碼返回具有最高秩分數的 10 個節點。結果以字典形式提供。
現在,是時候用可視化方法顯示結果了 Memgraph 實驗室 除了通過以下方式創建美麗的視覺效果外: D3.js 和我們的 圖形樣式腳本語言 ,您可以使用 Memgraph Lab 來:
- 查詢圖形數據庫 并用 Python 或 C ++甚至 Rust 編寫圖形算法
- 檢查 Memgraph 數據庫日志
- 可視化圖形模式
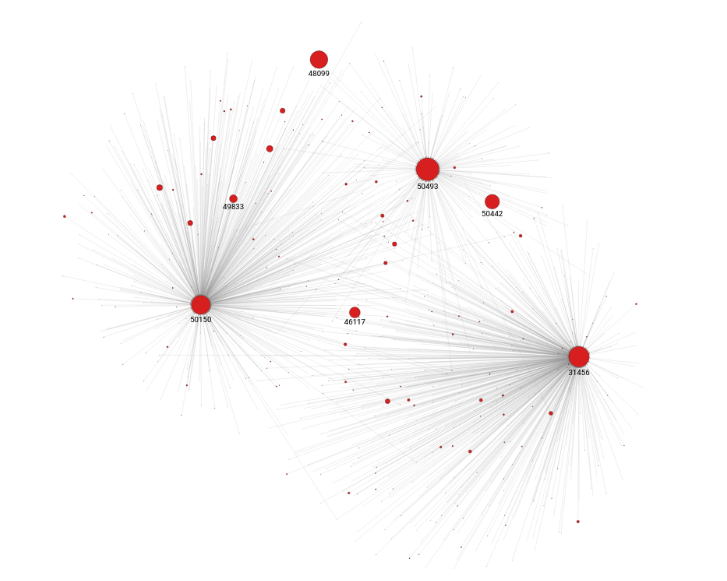
Memgraph Lab 提供了各種預構建的數據集,幫助您入門。在 Memgraph Lab 中打開執行查詢視圖并運行以下查詢:
MATCH (n)
WITH n
ORDER BY n.rank DESC
LIMIT 3
MATCH (n)<-[e]-(m)
RETURN *;
此查詢的第一部分將MATCH所有節點。查詢的第二部分將按rank的降序排列ORDER節點。
對于前三個節點,獲取連接到它們的所有頁面。我們需要WITH子句來連接查詢的兩個部分。圖 1 顯示了 PageRank 查詢結果。
下一步是學習如何使用 Louvain 社區檢測來查找圖中存在的社區。
Louvain 的社區檢測
Louvain 算法測量社區內節點的連接程度,與它們在隨機網絡中的連接程度進行比較。
它還遞歸地將社區合并到單個節點中,并在壓縮圖上執行模塊化聚類。這是最流行的社區檢測算法之一。
使用 Louvain ,您可以在圖中找到社區的數量。首先執行 Louvain 并將 cluster_id保存為每個節點的屬性:
memgraph.execute(
"""
CALL cugraph.louvain.get() YIELD cluster_id, node
SET node.cluster_id = cluster_id;
"""
)
要查找社區的數量,請運行以下代碼:
results = memgraph.execute_and_fetch(
"""
MATCH (n)
WITH DISTINCT n.cluster_id as cluster_id
RETURN count(cluster_id ) as num_of_clusters;
"""
)
# we will get only 1 result
result = list(results)[0]
#don't forget that results are saved in a dict
print(f"Number of clusters: {result['num_of_clusters']}")
Number of clusters: 2664
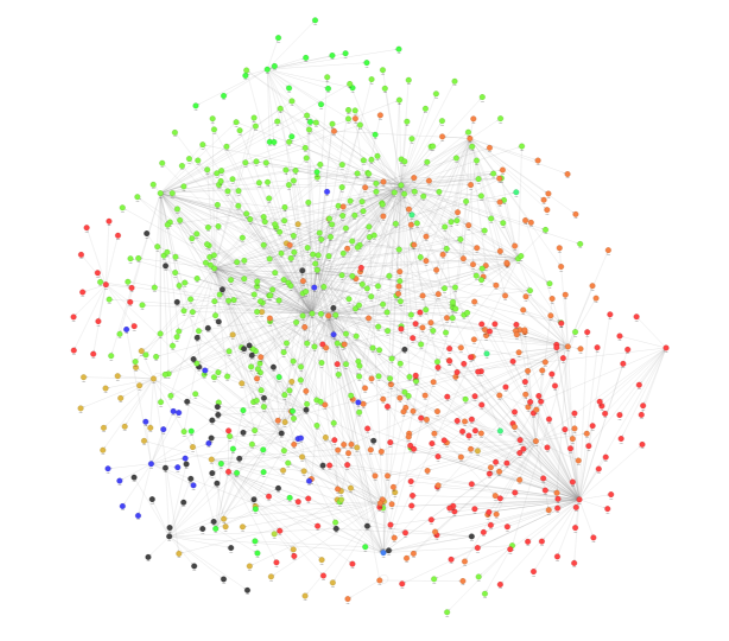
接下來,仔細看看其中的一些社區。例如,您可能會發現屬于一個社區的節點,但連接到另一個屬于相反社區的節點。 Louvain 試圖最小化此類節點的數量,因此您不應該看到很多節點。在 Memgraph Lab 中,執行以下查詢:
MATCH (n2)<-[e1]-(n1)-[e]->(m1)
WHERE n1.cluster_id != m1.cluster_id AND n1.cluster_id = n2.cluster_id
RETURN *
LIMIT 1000;
此查詢將顯示MATCH節點n1及其與其他兩個節點n2和m1的關系,分別包含以下部分:(n2)<-[e1]-(n1)和(n1)-[e]->(m1)。然后,它將僅過濾出n1的那些節點WHERE、cluster_id,并且n2與節點cluster_id的m1不同。
為了簡化可視化,使用LIMIT 1000僅顯示 1000 個此類關系。
使用 圖形樣式腳本 在 Memgraph Lab 中,您可以設置圖形的樣式,例如,用不同的顏色表示不同的社區。圖 2 顯示了 Louvain 查詢結果。
總結
現在,您可以使用 Memgraph 導入數百萬個節點和關系,并使用 cuGraph PageRank 和 Louvain graph 分析算法進行分析。借助由 NVIDIA cuGraph 提供的 Memgraph 的 GPU 圖形分析功能,您可以探索海量圖形數據庫并進行推理,而無需等待結果。您可以在上找到更多涵蓋各種技術的教程 Memgraph 網站 .
?