
截至今日,NVIDIA 現已支持在 NVIDIA RTX 和 Jetson 上全面推出 Gemma 3n。上個月,Google DeepMind 在 Google I/ O 上預覽了 Gemma,其中包括兩個針對多模態設備端部署優化的新模型。
除了 3.5 版本中引入的文本和視覺功能之外,Gemma 現在還包括音頻。每個組件都集成了可信研究模型:適用于音頻的通用語音模型、適用于視覺的 MobileNet v4 和適用于文本的 MatFormer。
最大的使用進步是一項名為“逐層嵌入”的創新。它可以顯著減少參數的 RAM 使用量。Gemma 3n E4B 模型具有 80 億個參數的原始參數計數,但可以使用與 4B 模型相當的動態內存占用來運行。這使開發者能夠在資源受限的環境中使用更高質量的模型。
| 模型名稱 | 原始參數 | 輸入上下文長度 | 輸出上下文長度 | 磁盤大小 |
| E2B | 50 億 | 32K | 32K 減去請求輸入 | 1.55 GB |
| E4B | 8B | 32K | 32K 減去請求輸入 | 2.82 BB |
使用 Jetson 為機器人和邊緣 AI 提供動力支持
Gemma 系列模型在 NVIDIA Jetson 設備上運行良好,這些設備旨在為邊緣應用 (例如新一代機器人) 提供支持。輕量級架構和動態內存的使用適合資源受限的環境。
Jetson 開發者可以參加在 Kaggle 上舉辦的 Gemma 3n Impact 挑戰賽。其目標是利用這項技術在可訪問性、教育、醫療健康、環境可持續性和危機應對等領域為世界帶來有意義的積極變化。一些現金大獎的起售價為 1 萬美元,可用于提交整體展示和使用適合設備端部署的不同技術 (例如 Jetson) 的作品。
首先,請查看 4 月 Gemma 3 開發者日的實時文本和圖像演示,以及使用 Ollama 在本地部署 Gemma 的 GitHub 存儲庫。
面向 Windows 開發者和 AI 愛好者的 NVIDIA RTX
借助 NVIDIA RTX AI PC,開發者可以使用 Ollama 輕松部署 Gemma 3n 模型。AI 愛好者可以在 AnythingLLM 和 LM Studio 等他們喜愛的應用中使用支持 RTX 加速的 Gemma 3n 模型。
開發者只需使用 Ollama CLI,即可在 RTX 和 Jetson 設備本地部署 Gemma 3n:
- 下載并安裝適用于 Windows 的 Ollama
- 打開終端窗口并完成以下命令:
ollama pull gemma3n:e4bollama run gemma3n:e4b “Summarize Shakespeare’s Hamlet” |
NVIDIA 與 Ollama 合作,為 NVIDIA RTX GPU 提供性能優化,加速 Gemma 3n 等最新模型。對于此模型,Ollama 利用后端的 Ollama 引擎,該引擎基于 GGML 庫構建。詳細了解 NVIDIA 如何助力 GGML 庫在 NVIDIA RTX GPU 上實現卓越性能。
使用開放式 NVIDIA NeMo 框架為您的數據自定義 Gemma
開發者可以將 Hugging Face 的 Gemma 3n 模型與開源 NVIDIA NeMo 框架結合使用。它為后訓練 Llama 模型提供了一個全面的框架,以實現更高的準確性,特別是通過對企業特定數據進行微調。NeMo 中的工作流專為端到端設計,涵蓋數據準備、高效微調和模型評估。
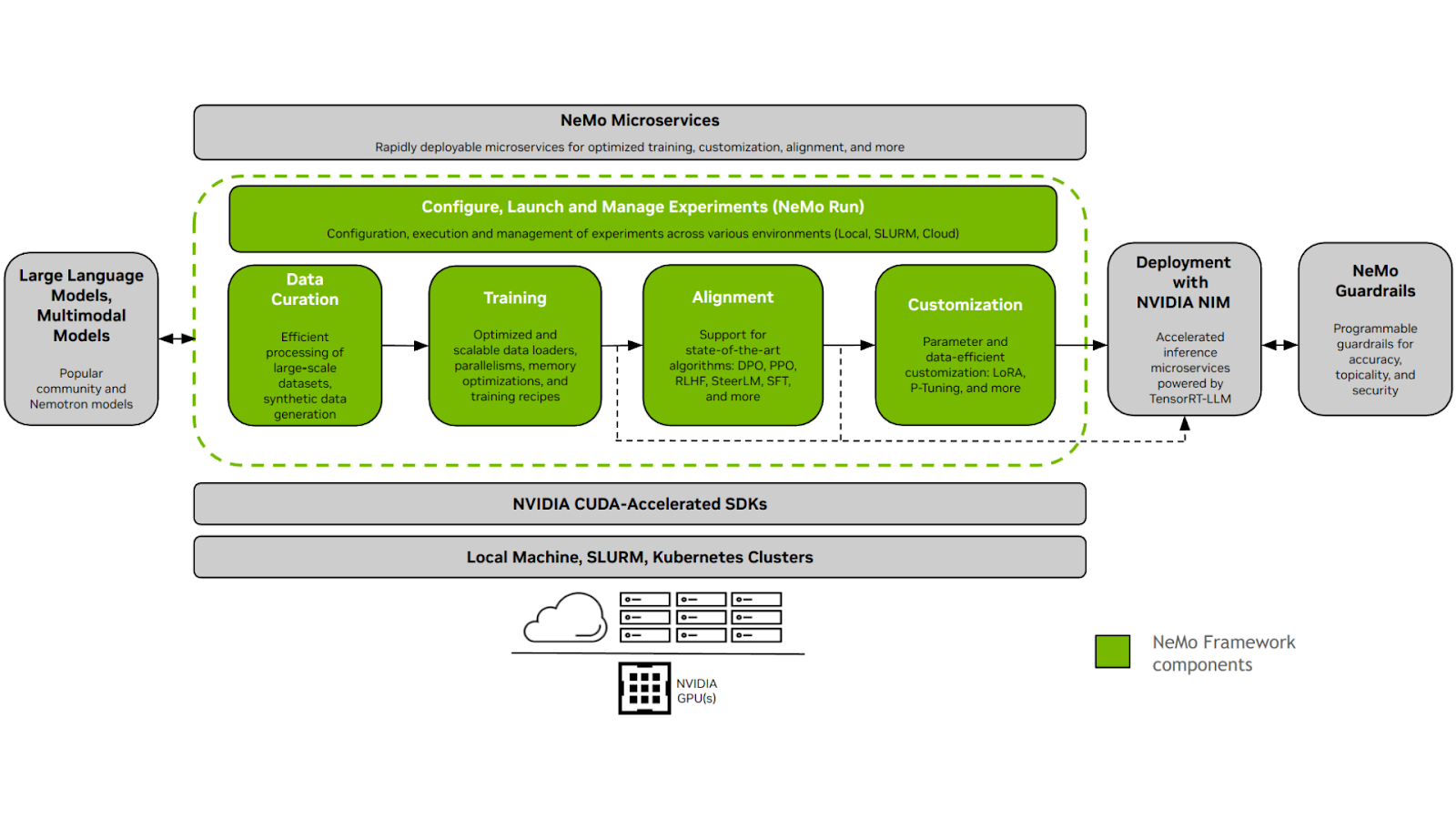
工作流程包括:
- 數據管護 (NeMo Curator) :Curator 通過提供用于提取、篩選和重復大量結構化和非結構化數據的工具,為預訓練或微調準備高質量數據集。它可確保模型輸入數據的質量。
- 微調 (NeMo) :數據經過整理后,NeMo 可實現對 Llama 模型的高效微調。它支持多種技術來優化此過程,包括 LoRA (低秩自適應) 、PEFT (參數高效微調) 和用于全面定制的完整參數調優。
- 模型評估 (NeMo Evaluator) :經過微調后,NeMo Evaluator 可用于通過自定義測試和基準測試來評估經過調整的模型的性能。
推進社區模型和協作
NVIDIA 是開源生態系統的積極貢獻者,已根據開源許可發布了數百個項目。NVIDIA 致力于 Gemma 等開放模型,以提高 AI 透明度,并讓用戶廣泛分享在 AI 安全性和彈性方面的工作。
立即開始
在 NVIDIA API Catalog 中的 NVIDIA 加速平臺上引入您的數據并試用 Gemma 3n E4B。
?






