識別和識別自然場景和圖像中的文本對于視頻標題文本識別、檢測車載攝像頭的標牌、信息檢索、場景理解、車牌識別以及識別產品文本等用例變得非常重要。
大多數這些用例都需要近乎實時的性能。常用的文本提取技術包括使用光學字符識別 (OCR) 系統。但是,大多數免費的商用 OCR 系統都經過訓練,可以識別文檔中的文本。在識別自然場景或帶字幕的視頻(如圖像透視、反射、模糊等)中的文本方面存在許多挑戰。
在本系列的下一篇文章中,強大的場景文本檢測和識別:實施,討論了如何使用先進的深度學習算法和技術(例如增量學習和微調)實現 STDR 工作流。第三篇博文強大的場景文本檢測和識別:推理優化,涵蓋了為您的 STDR 工作流提供生產就緒型優化和性能。
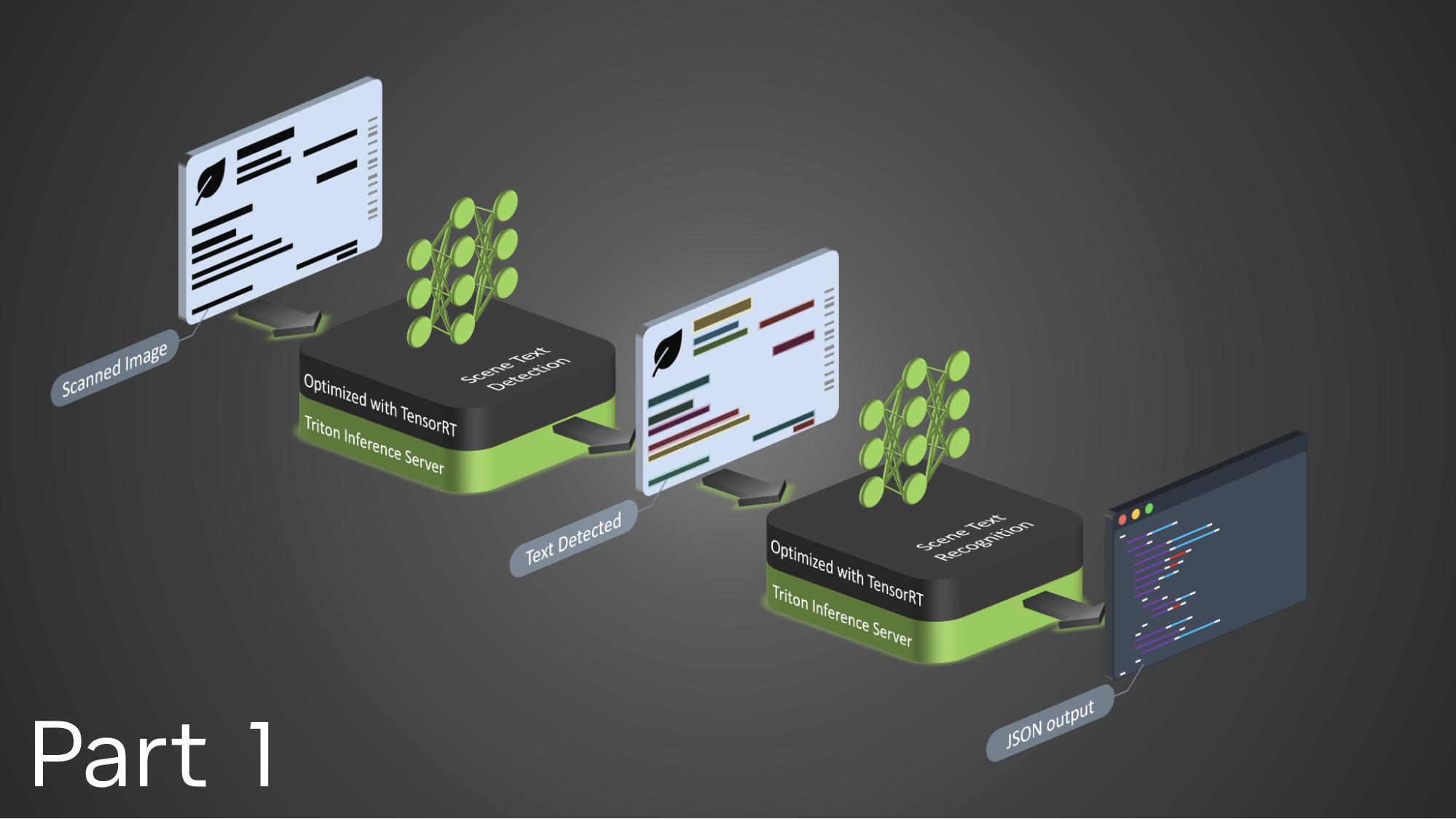
通常,文本提取過程涉及以下步驟:
- 通過文本檢測算法從更大的場景中檢測文本字段。
- 此文本使用自定義 OCR 技術進行提取和識別。
由于文本外觀的可變性(例如曲率、方向和失真),識別自然場景圖像中的不規則文本可能具有挑戰性。為了克服這一問題,通常需要復雜的深度學習架構和細粒度注釋。
然而,在創建和部署這些算法時,這些問題可能會導致優化和延遲挑戰。盡管存在這些挑戰,計算機視覺的進步在文本檢測和識別方面取得了重大進展,為各行各業提供了強大的工具。為了進一步優化推理,您可以使用專業的優化工具來降低延遲并提高性能。
在本文中,我們將介紹這些挑戰以及優化和加速推理的方法。我們強調,部署場景文本檢測和識別 (STDR) 流程需要仔細考慮現實世界的場景和條件。為了滿足這些需求,我們使用了先進的深度學習算法和利用技術,例如針對特定用例的增量學習和微調。
為確保低延遲,我們使用了以下模型推理優化工具:
- ONNX Runtime 是一個跨平臺的機器學習模型加速器,它提供了與特定硬件庫集成的靈活性。它可以與 PyTorch、TensorFlow 和 Keras、TensorFlow Lite、scikit-learn 以及其他框架中的模型一起使用。
- NVIDIA TensorRT SDK 用于高性能深度學習推理,提供深度學習推理優化器和運行時環境,確保推理應用程序具有低延遲和高吞吐量。
- NVIDIA Triton 推理服務器 旨在為云端、本地和邊緣設備提供高性能的推理服務。
NVIDIA AI Enterprise 的軟件層中包含了 TensorRT 和 Triton 推理服務器。
STDR 應用
識別圖像和視頻中的文本用于各行各業。
醫療健康和生命科學:場景文本檢測和識別技術在醫療保健行業中應用廣泛,用于掃描患者的病史記錄并將其數字化存儲,包括病歷報告、X光片、過往疾病、治療方案、診斷結果和醫院記錄。此外,醫療設備和藥品制造領域的物流與倉儲運營也依賴于場景文本檢測和識別技術。
制造業供應鏈/物流:在整個供應鏈的質量控制中,場景文本檢測和識別對于食品、飲料和化妝品行業至關重要。它用于跟蹤產品并讀取產品代碼、批次代碼、過期日期和序列號。這些信息有助于確保遵守安全和防偽法規,并能夠在任何時候準確地追蹤供應鏈中的產品位置。OCR 通常與條形碼結合使用,以進一步提高信息收集的準確性。

銀行:場景文本檢測和識別在銀行業有廣泛應用,能夠自動處理出生證明、結業證書等“了解你的客戶”(KYC)文檔。
汽車和公共事業:自動駕駛汽車和電力線路維護駕駛通常需要識別場景圖像并提取數據(例如,街道名稱、場所名稱、電線桿編號以及變壓器和發電機的詳細信息)。通常情況下,文本在車輛移動時只出現一小段時間,從而產生運動模糊。在這種情況下,手動檢測變得不可能。
STDR 挑戰
從視頻和手機拍攝的復雜圖像中檢測和提取文本的最大挑戰是,此類圖像中的文本通常是不規則的,并且覆蓋在玻璃、塑料、橡膠等不同背景上。
此外,即使機器學習模型的開發具有相當高的準確性,模型也應實時或近乎實時地處理圖像。因此,滿足準確性和性能預期需要高度優化的模型,這些模型可以在云和邊緣設備中進行優化。本文將詳細介紹這些挑戰。
創建穩健的模型
通常,場景文本模型中存在準確性問題的主要原因是輸入數據的變異數量。以下是一些數據變異。
文本大小比例模糊:自然場景中的文本可能以各種大小和比例出現。文本與攝像頭的距離對于文本的縮放同樣起著重要作用。攝像頭的角度可能會引入透視失真。此外,光照條件可能在文本周圍產生反射和陰影。移動物體或攝像頭的移動都有可能增加模糊效果。所有這些因素共同作用,可能會導致圖像中文本的大小比例出現模糊失真。
文本方向、顏色和字體:文本可能以水平、垂直、對角線甚至循環的方式顯示。這種文本方向的變化會使算法難以正確檢測和識別文本。如果訓練數據未能反映實際使用中的顏色、透明度和字體風格,同樣會帶來挑戰。
背景和疊加:自然場景中的文本可能出現在各種背景之上,如建筑物、樹木、車輛等,并且常常覆蓋在玻璃、金屬、塑料或貼紙等物體上。它還可能被浮雕或凹凸處理在不同的材質上。
多語言環境:真實世界的圖像中常包含多種文字腳本和語言的文本。例如,標牌或餐廳菜單通常使用混合語言編寫。
在 ML 項目中,另一個常見的挑戰是獲取已標記的數據來訓練模型。然而,在此管道中,我們使用了預訓練的CRAFT 模型進行文本檢測,該模型在SynthText、IC13以及IC17數據集上進行了訓練。
對于文本識別,我們使用了PARseq 模型在各種數據集上進行訓練MJSynth, SynthText,COCO 文本, RCTW17, Uber-Text, ArT, LSVT, MLT19以及ReCTS, TextOCR)并根據內部數據進行微調。
滿足性能預期
部署場景文本檢測解決方案也會帶來各種挑戰。
計算資源:當今,現代 STDR 系統采用了復雜的深度學習算法。這些模型參數眾多,導致運行成本高昂。因此,在計算資源受限的設備上(如智能手機或物聯網 (IoT) 設備)部署這些解決方案變得頗具挑戰。
延遲和響應時間摘要:在許多應用場景中,文本檢測和識別必須實時進行才能發揮其效用。盡管深度學習模型能夠提供高準確率,但其龐大的參數數量相較于參數較少的模型,會增加推理時間,從而導致不可接受的延遲和響應時間。為了在保持準確性的同時優化推理速度,可以采用先進算法,并通過量化、降低精度、剪枝等技術進行模型優化。然而,這些優化措施可能會對模型的準確性產生一定影響。
數據隱私和安全:在真實場景中部署解決方案時,用于訓練和運行模型的數據的隱私和安全性極為重要。需要采取措施保護模型不受惡意攻擊和防止數據泄露。同時,必須確保嚴格遵守數據隱私法規。
部署場景文本檢測解決方案需要仔細考慮使用該解決方案的真實場景和條件。此過程是一個關鍵步驟,需要進行全面的測試、評估和微調。
假設一家包裹配送公司需要在傳送帶上使用標簽讀取應用程序。在這種情況下,高精度至關重要,因為任何錯誤都會導致延遲并給公司帶來額外成本。傳送帶的速度是另一個需要考慮的關鍵因素,因為它會影響處理包裹所需的總時間。
實現高精度可能需要復雜的深度學習模型,而這些模型的計算成本高昂,會影響系統延遲。為了優化性能,必須考慮部署場景(例如傳送帶速度和計算資源)的具體要求和限制,并相應調整深度學習模型,以在準確性、延遲和資源之間取得平衡。
總結
在本文中,我們討論了穩健的場景文本檢測和識別 (STDR) 在各行各業中的重要性。我們重點介紹了 STDR 面臨的挑戰,包括創建準確的模型、滿足性能預期以及處理真實世界的場景和條件。
有關更多信息,請參閱此系列的后續文章:
?








