要使場景文本檢測和識別適用于不規則文本或特定用例,您必須完全控制模型,以便根據用例和數據集執行增量學習或微調。請記住,此工作流是場景理解、基于 AI 的檢查和文檔處理平臺的主要構建塊。它應該準確且低延遲。
在本系列的第一篇文章中,強大的場景文本檢測和識別:簡介 討論了穩健的場景文本檢測和識別(STDR)在各行各業中的重要性以及所面臨的挑戰。第三篇博文 強大的場景文本檢測和識別:推理優化 涵蓋了 STDR 工作流的生產就緒型優化和性能。
在這篇博文中,我們決定采用高度精確的先進深度學習模型。為了確保準確性并維持較低的端到端延遲,我們采用了以下工具和框架來執行模型推理優化:NVIDIA TensorRT 和 ONNX Runtime。為了確保標準模型能夠被部署和執行,同時保證具有可擴展性的高性能推理,我們還選擇使用了 NVIDIA Triton 推理服務器。
為了訓練模型,我們使用了NGC 目錄 作為 GPU 優化 AI 和 ML 軟件的中心。NGC 容器利用 NVIDIA GPU 的強大功能,可以在配置了 NVIDIA 虛擬 GPU (vGPU) 軟件的虛擬機 (VM) 中運行,適用于 NVIDIA vGPU 和 GPU 透傳部署。這些容器預配置了適用于 PyTorch 和 TensorRT 等 SDK 的優化庫。
為了在云端、本地和邊緣實現高性能推理,我們還使用了 Triton 推理服務器 Docker 容器。此容器支持在單個 GPU 或 CPU 上同時執行來自不同框架的多個模型。在多 GPU 服務器上,Triton 推理服務器會自動為每個 GPU 上的每個模型創建一個實例,以更大限度地提高利用率。
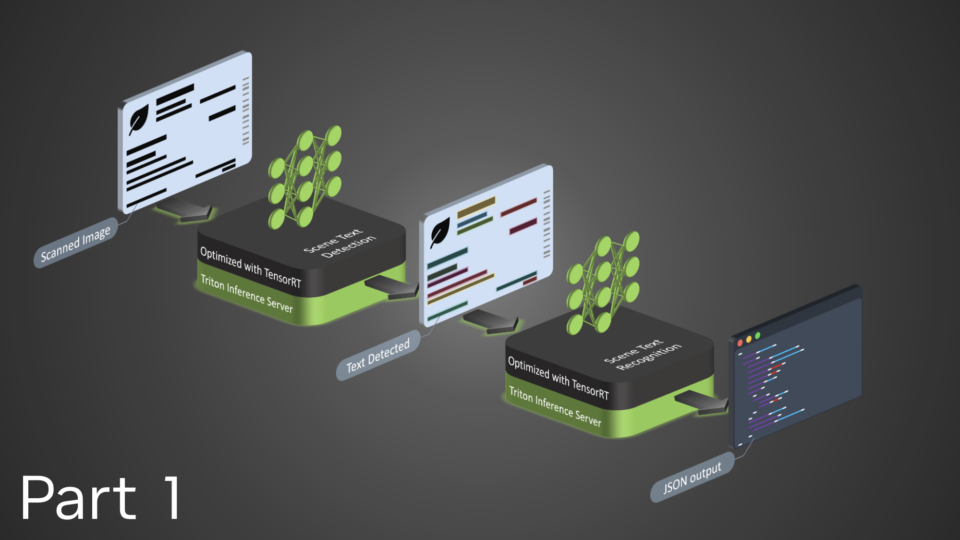
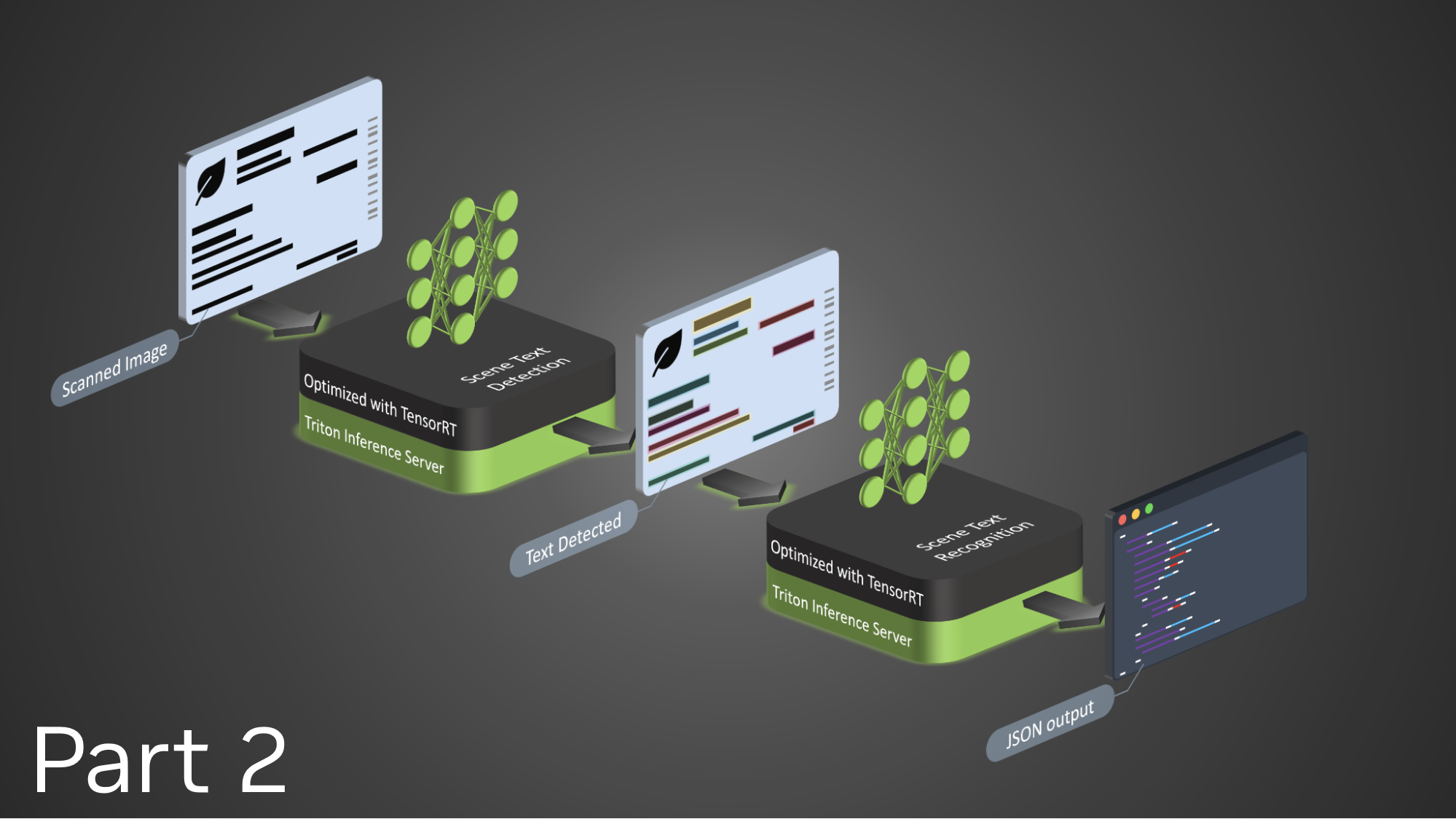
STDR 管道有三個構建塊:
- 場景文本檢測
- 場景文本識別
- 編排
場景文本檢測
在當前工作流中,文本檢測算法有以下選項:
- FCENet
- CRAFT
- TextFuseNet
您可以針對特定用例訓練和微調 FCENet 和 TextFuseNet。但是,由于 Clova AI 出于知識產權原因未發布訓練代碼,因此無法訓練或微調 CRAFT。我們的通用型工作流程使用了在 synthText、IC13 和 IC17 數據集上進行訓練的預訓練 CRAFT 模型。有關更多信息,請參閱用于文本檢測的字符區域感知。
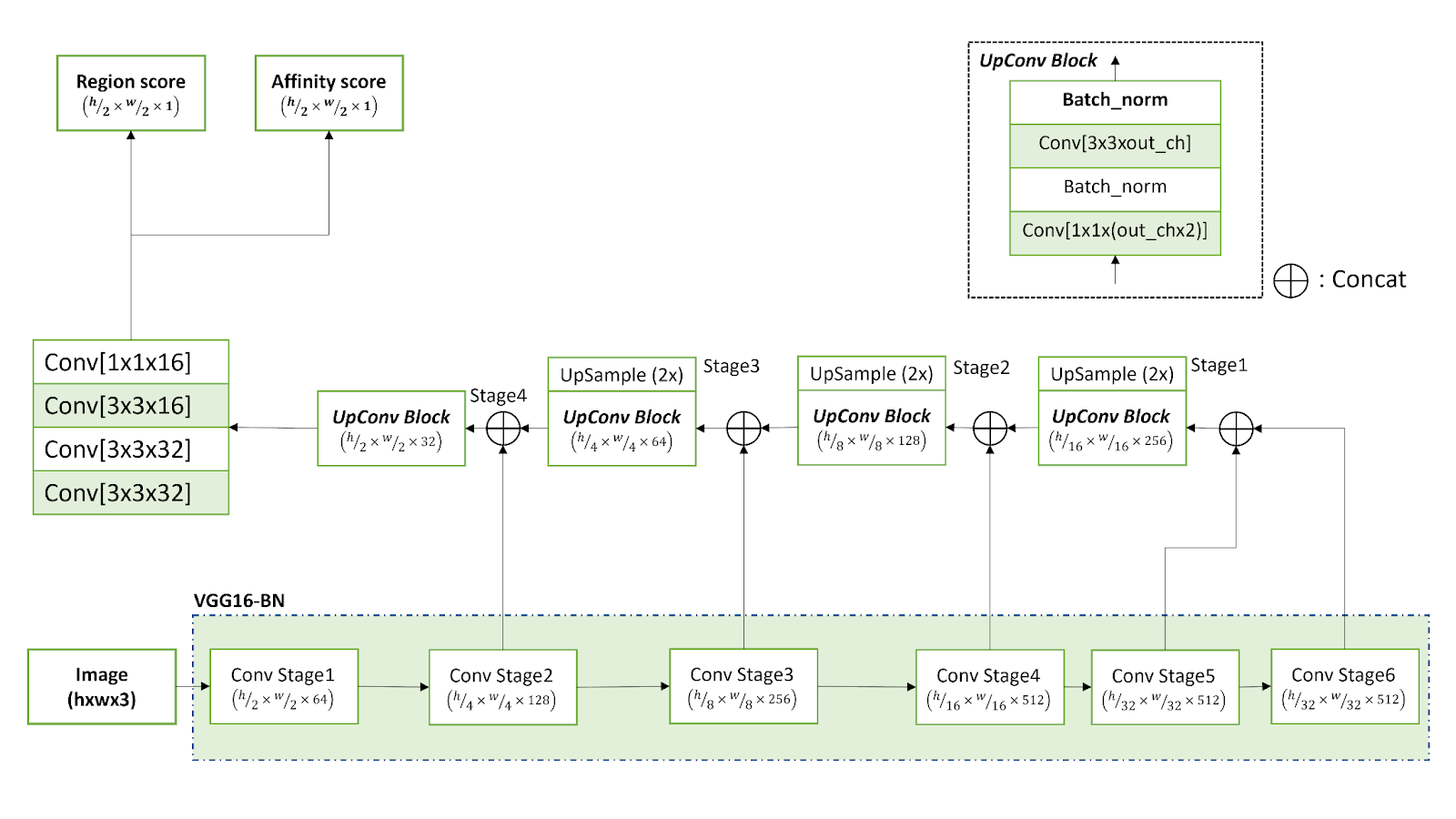
此網絡使用基于 VGG-16 模型的全卷積網絡架構,該架構將輸入編碼為獨特的特征表示。CRAFT 的解碼段與 UNet 的解碼段類似,包括聚合低級別特征的跳轉連接。
CRAFT 為每個角色預測兩個單獨的分數:
- 地區評分:提供有關角色所在區域的信息。
- 親和力分數:展示角色組合成為單一實體的程度。

場景文本識別
在本文中,我們采用了先進的場景文本識別技術和置換自回歸序列 (PARseq) 算法。欲了解更多信息,請參閱使用置換自回歸序列模型進行場景文本識別。
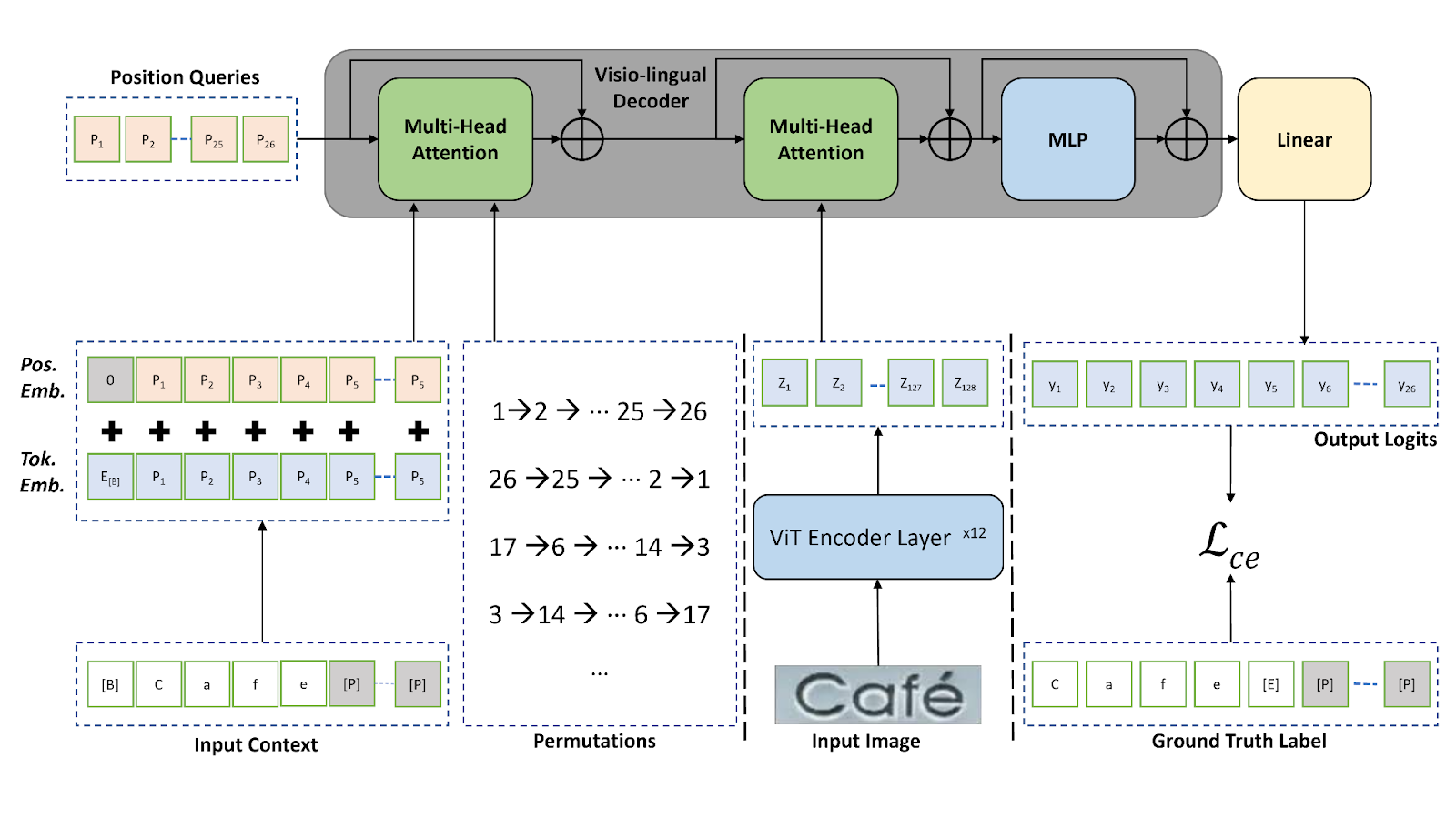
我們在 MJSynth 和 SynthText、COCO-Text、RCTW17、Uber-Text、ArT、LSVT 以及 MLT19 等多個數據集上訓練了已發布的預訓練模型。此外,我們還使用增量學習技術在自定義數據集上對預訓練模型進行了微調。
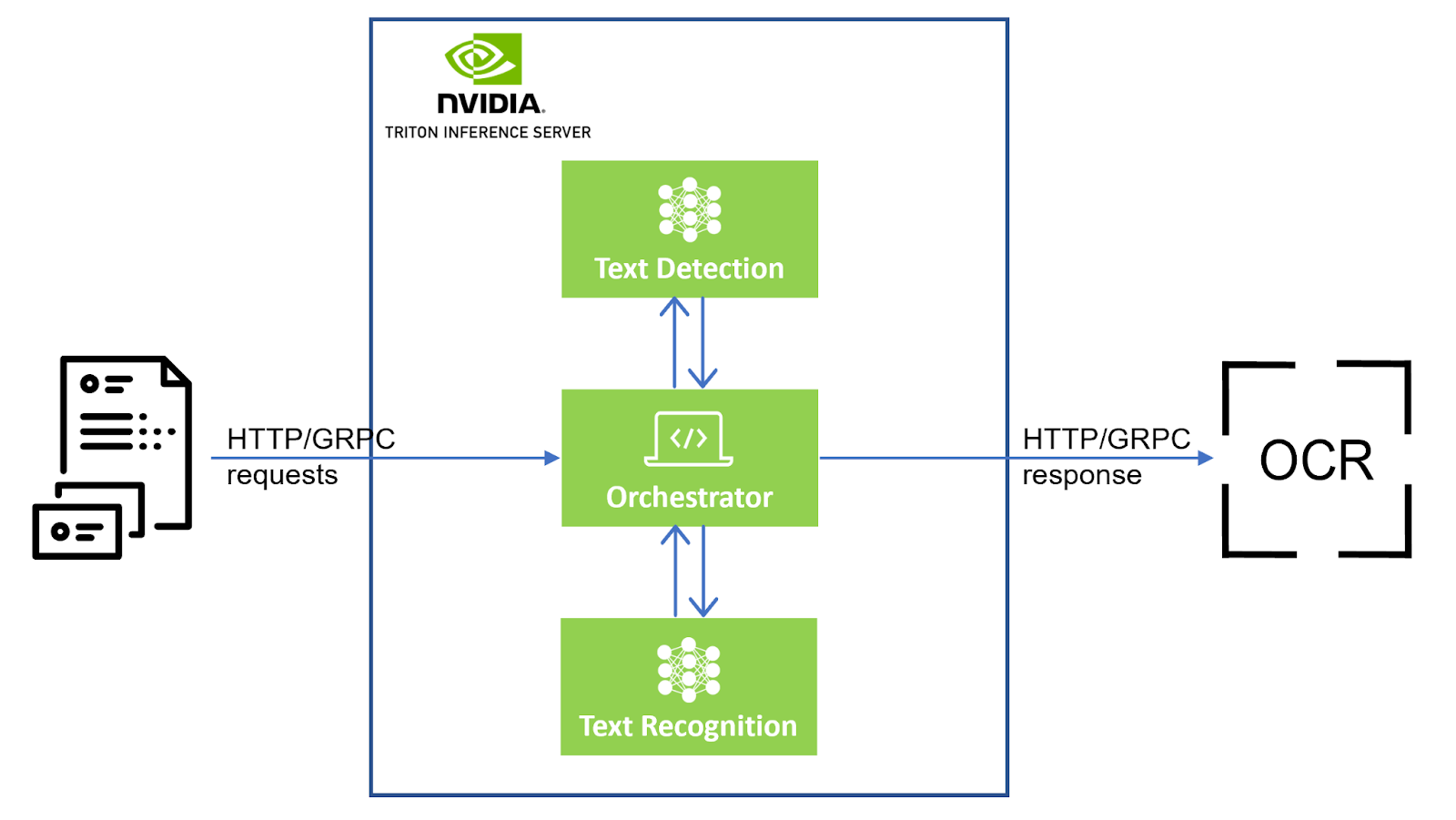
編排師
編排器模塊是流程的控制單元。此模塊負責協調場景文本檢測和場景文本識別。
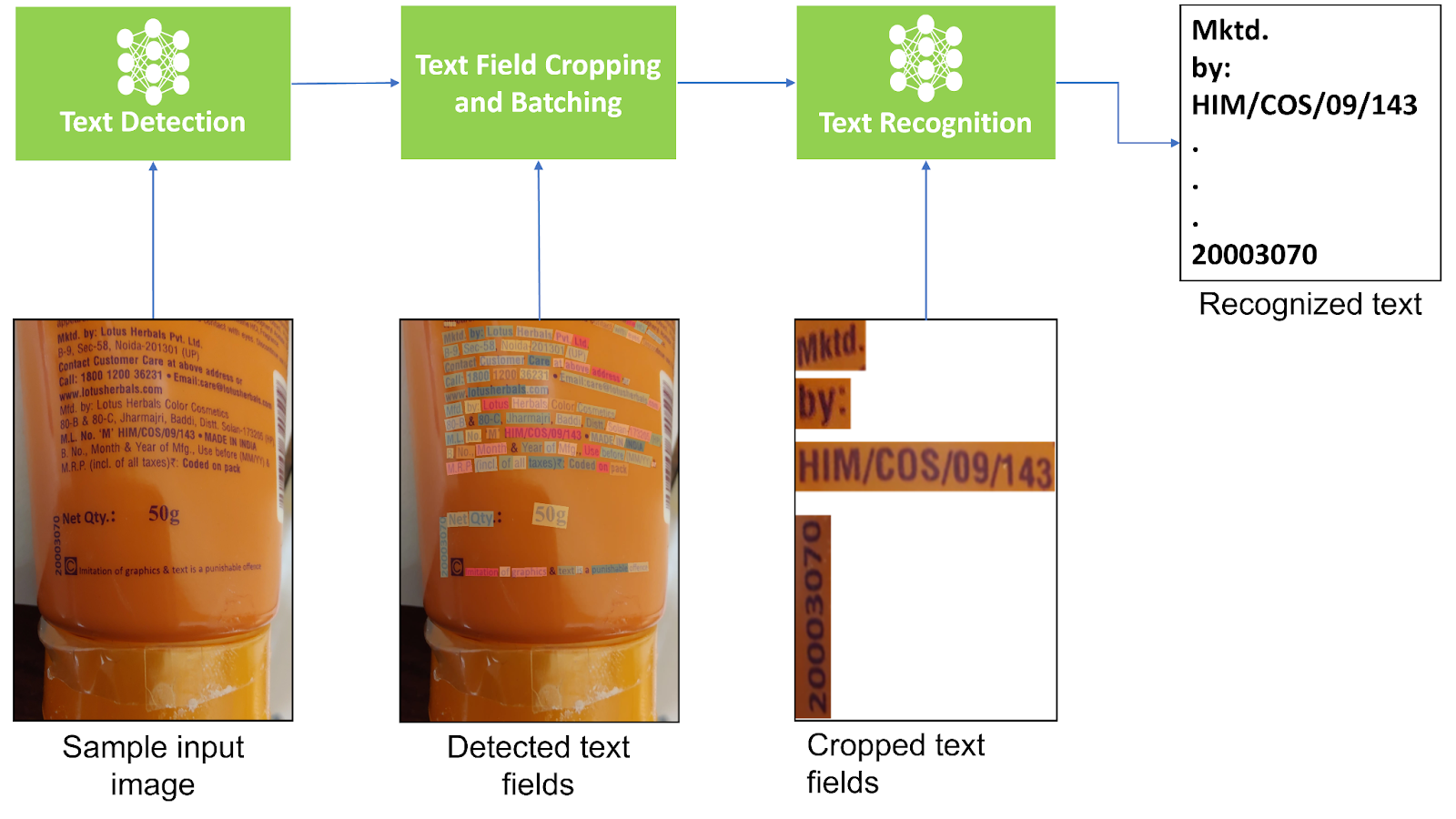
- 它會接收來自請求的輸入圖像。
- 系統會對該圖像進行預處理,并將其發送到場景文本檢測模塊。
- 檢測模塊會返回輸入圖像中文本字段的位置。
- Orchestrator 會將輸入圖像中的文本字段裁剪為
ndarrays. - 它根據預定義批量大小的裁剪文本圖像創建批量,并一次將一個批量發送到文本識別模塊。
- 識別模塊會返回 STR 輸出,并為該批處理中的每個裁剪文本圖像提供置信度分數。
編排器會維護每個文本字段位置、相應 STR 輸出和置信度分數的跟蹤。它會使用所有這些信息創建響應 JSON.
總結
在本文中,我們討論了使用先進的深度學習算法以及增量學習和微調等技術實現 STDR 工作流的問題。我們使用 CRAFT 算法進行文本檢測,使用 PARSeq 算法進行文本識別。我們設計了一個獨特的編排模塊,以促進文本檢測和識別之間的協調。本文還重點介紹了使用 NVIDIA TensorRT、ONNX Runtime 和 NVIDIA Triton Inference Server 進行模型優化和高性能推理服務的情況。
有關更多信息,請參閱強大的場景文本檢測和識別:簡介和推理優化相關文章。
?