Spark RAPID ML 是一個開源 Python 包,它可以使 NVIDIA GPU 加速 PySpark MLlib。它提供了與 PySpark MLlib DataFrame API 兼容,并在使用支持的算法進行訓練時加速。想要了解更多信息,請查看 新的 GPU 庫降低 Apache Spark ML 的計算成本。
PySpark MLlib DataFrame API 的兼容性意味著它可以更容易地融入現有的 PySpark ML 應用程序,最多只需更改包導入。K-means 算法如下所示。更改包導入是使用此庫啟用 GPU 加速所需的唯一額外步驟。
PySpark MLlib
from pyspark.ml.clustering import KMeanskmeans_estm = KMeans()\.setK(100)\.setFeaturesCol("features")\.setMaxIter(30)kmeans_model = kmeans_estm.fit(pyspark_data_frame)kmeans_model.write().save("saved-model")transformed = kmeans_model.transform(pyspark_data_frame) |
Spark RAPID ML
from spark_rapids_ml.clustering import KMeanskmeans_estm = KMeans()\.setK(100)\.setFeaturesCol("features")\.setMaxIter(30)kmeans_model = kmeans_estm.fit(pyspark_data_frame)kmeans_model.write().save("saved-model")transformed = kmeans_model.transform(pyspark_data_frame) |
在 GPU 加速的 Databricks 的 AWS 托管 Spark 服務上,在三節點 Spark 集群中運行的基準測試套件中使用支持的算法進行培訓,與基于 CPU 的 PySpark MLlib 相比,證明了顯著的時間和成本優勢。具體而言,這實現了7 倍到 100 倍的加速(取決于算法)和成本節約增加 3 倍至 50 倍。此外,Spark RAPID ML 庫建立在經過驗證、高度優化的 RAPID cuML GPU 加速 ML 庫之上。
Spark RAPID ML 的初始版本支持 GPU 加速的 PySpark MLlib 算法的一個子集,RAPID cuML 中有現成的對應算法,包括線性回歸,隨機森林分類、隨機森林回歸、k-均值和主成分分析。此外,它還包括一個 PySpark DataFrame API,用于精確 k 最近鄰居(k-NN)的 cuML 分布式實現,以便使用熟悉的 API 將此有用的算法輕松地結合到 Spark 應用程序中。
這個 Spark RAPID ML 23.08 版本發布 包括用于三種新算法的 GPU 加速 PySpark MLlib API:
- L-BFGS 優化的二項邏輯回歸
- 交叉驗證
- 一致流形近似與投影(UMAP)
L-BFGS 的二項邏輯回歸
邏輯回歸是一種廣為人知的機器學習(ML)分類算法,它將有限值類別變量的條件概率分布建模為特征向量的廣義線性函數(例如 softmax 或 sigmoid 和線性函數)。
23.08 版本包括 PySpark MLlib 的 GPU 加速版本分類后勤回歸和分類物流回歸模型支持加速擬合和轉換。這最初用于二元分類(二項式邏輯回歸)和 L2 正則化,并計劃為即將發布的版本提供全面支持(例如,彈性網絡正則化和多類分類)。
與之前發布的算法相比,支持加速邏輯回歸更為復雜。與以前版本中的算法不同,cuML 中沒有現成的分布式實現可供利用。
因此,第一步是對基于 L-BFGS 的邏輯回歸優化算法(也在 Spark MLlib 中使用)進行單 GPU 加速的 cuML 進行多節點多 GPU(MNMG)擴展。為此,該團隊遵循了其他 cuML 分布式實現的設計模式,其設計類似于以 GPU 優化為中心的消息傳遞接口(MPI)NVIDIA 集體通訊庫(NCCL)。
我們對 Spark RAPIDSML 的實現進行了使用 PySpark Barrier RDD 和 MLlib API 兼容性的自舉分層(見圖 1)。與之前發布的算法一樣,這種設計使 GPU 加速的分布式實現能夠以優化 GPU 利用率的方式并通過 GPU 之間的最佳可用互連來執行通信。其中包括以太網或更高性能的互連,如NVLink和 InfiniBand。
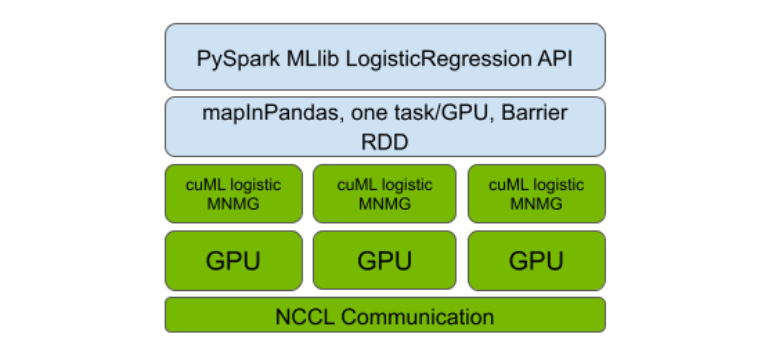
表演
用于先前發布的算法的基準設置也用于比較 GPU 加速的 Spark RAPID ML 邏輯回歸與基于 CPU 的 Spark ML 版本。PySpark RAPID MLlib 實現比 PySpark MLlib CPU 實現快 6 倍,成本效益高 3 倍。
這些基準測試在 Databricks 托管的 AWS Spark 服務上的三個節點 Spark 集群(一個驅動程序,兩個執行器)中運行,硬件配置如下。
- 在 CPU 集群中,m5.2xlarge 執行器和驅動程序節點各有八個 CPU 核心和 32GB RAM。
- 在 GPU 集群中,g5.2xlarge 執行器節點的 CPU 和 RAM 與 m5.2 xlarge 節點相同,都配備了 NVIDIA A10 24GB GPU。
基準測試在一個 3000 功能的 12GB 合成數據集上運行,該數據集使用 scikit 學習合成數據生成例程生成,并以 Parquet 格式存儲在 Amazon S3 上。請注意,運行時用于從 AmazonS3 加上 fit 方法執行的端到端數據加載,spark rapids 插件用于加速 GPU 運行的數據加載。
如果您想了解更多信息,包括與此基準測試相關的腳本,請訪問 NVIDIA/spark-rapids-ml GitHub。另外,您可以參考示例 Jupyter 筆記本,它演示了如何使用加速的 LogisticRegression API。
交叉驗證
交叉驗證是一種眾所周知的算法,用于優化模型或訓練算法超參數,這些超參數不是由核心訓練算法本身直接調整的,例如邏輯回歸中的正則化參數。PySpark MLlib 長期以來一直通過調優來支持它。CrossValidator 類。
由于 Spark RAPID ML 的 MLlib API 兼容性,支持的加速算法估計器類可以開箱即用地進行 PySpark CrossValidator 超參數調整。與 CPU 訓練的交叉驗證相比,它提供了加速和成本效益,與 CPU 情況相比,這與單個訓練運行的 GPU 不相上下。然而,對于超參數值的每次變化,它都會重復地將數據從 CPU 復制到 GPU,這是低效的。
這種過度復制是 GPU 計算中已知的性能瓶頸。對于 Spark RAPID ML 來說,這一點更為明顯,因為這些副本也存在于 JVM 執行器和 Python 工作器之間的本地套接字連接上。
為了消除這種低效性,Spark RAPID ML 現在包括一個專門的PySpark 本地 CrossValidator 的版本,它與 MLlib API 兼容。它只向 Python 工作人員和 GPU 復制一次數據,而在給定的交叉驗證倍數內,超參數值會發生變化。
Spark RAPID ML 專用 CrossValidator 在單獨的訓練和評估 Spark 階段訓練和評估所有模型的測試超參數值,每個階段復制一次數據。圖 2 顯示了時間線跟蹤,顯示了 PySpark MLlib 和 Spark RAPID ML CrossValidator 版本的副本模式以及訓練和評估計算步驟。
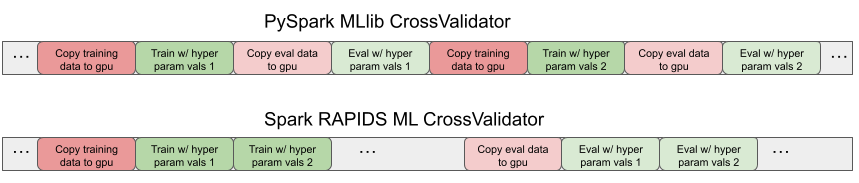
性能
我們的團隊對新的專業 CrossValidator 類進行了三倍交叉驗證的基準測試,每個 GPU 加速了四個超參數值的 RandomForest 分類器,隨機森林回歸和線性回歸。我們觀察到在 GPU 加速實現上的 CrossValidator 的基線之上有 2 倍的加速 。
請注意,當考慮與純 CPU 交叉驗證的總體比較時,這種加速會乘以由于核心訓練算法的 GPU 實現而導致的現有加速因子。
訪問 GitHub 上的 NVIDIA/spark-rapids-ml 獲取示例 Jupyter 筆記本,該筆記本展示了兼容 Spark MLlib API 的加速交叉驗證程序。
UMAP
UMAP 是一種最先進的非線性降維算法,它在將結構從高維數據捕獲到計算的低維表示或嵌入中是非常有效的。它可以用于簡化下游 ML 任務,如分類和聚類,或用于可視化。
該算法涉及計算密集型步驟,以在原始高維空間中獲得低維嵌入,如 k 近鄰(k-NN),并對嵌入上的隨機圖進行迭代交叉熵優化。因此,它是 GPU 加速的自然候選者,并已在 cuML 庫中實現,這比原始的 CPU 實現更優秀。
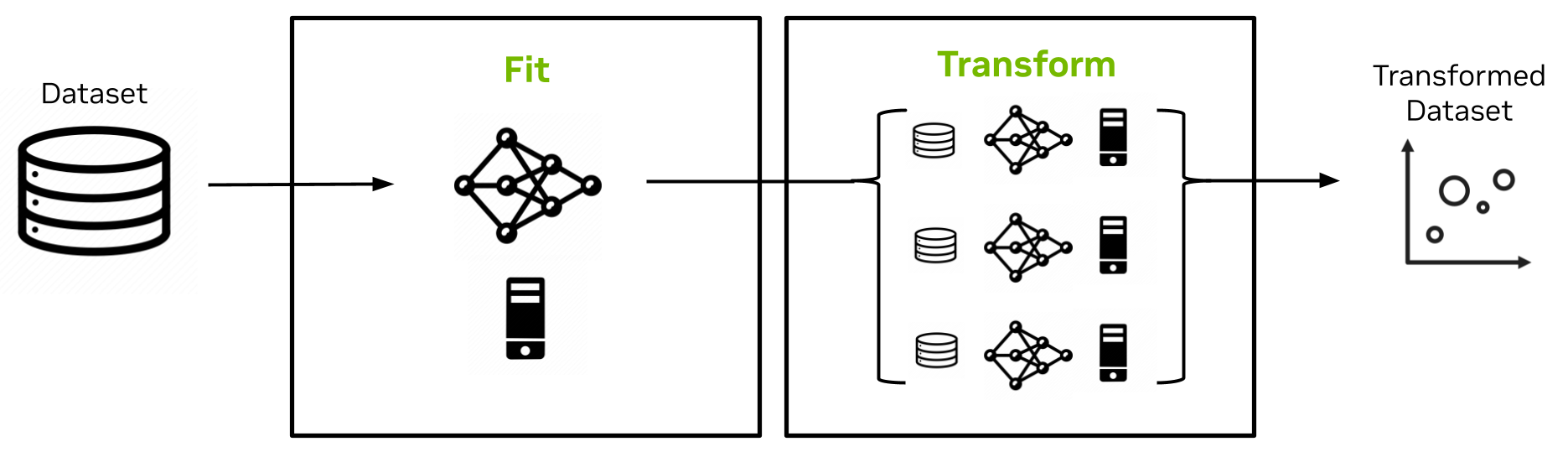
在最新的 Spark RAPID ML 版本中,UMAP 加入了精確的 k-NN,作為 cuML 中的非 MLlib 加速算法,該算法封裝在 PySpark MLlib API 中,可輕松集成到 Spark 應用程序中。設計如圖 3 所示。
UMAP 估計器的擬合方法實現是單節點的,并且對完整數據集的隨機樣本進行操作以創建包括該隨機樣本及其嵌入的 UMAP 模型。UMAP 模型的變換方法然后以可擴展的分布式方式將嵌入擴展到數據集的其余部分。
它針對原始隨機樣本和模型中捕獲的嵌入使用 k-NN 和交叉熵優化。該實現克服了 Spark 中的序列化限制,實現了大模型大小(許多 GB)。
請訪問 GitHub 上的 NVIDIA/spark-rapids-ml Jupyter 筆記本,查看在 Spark 上演示 GPU 加速的 UMAP 示例。如果想了解更多關于 API 的詳細信息,請參閱 UMAP 文件。
總結
有了 Spark RAPID ML 及其不斷增長的功能,您可以通過一行代碼的更改大大加快 Spark ML 應用程序的速度,同時降低計算成本。Spark RAPID ML 的最新版本將 GPU 加速的這些好處擴展到了邏輯回歸和交叉驗證。此外,GPU-accelerated UMAP 現在可與 PySpark MLlib API 一起使用,以便在 Spark ML 應用程序中更容易采用。
歡迎訪問 NVIDIA/spark-rapids-ml 在 GitHub 上的 Spark RAPID ML 源代碼 和 文檔,并 提供反饋。您也可以查看 如何開始使用 Spark RAPID ML 的資源。
?