
在當今快節奏的 IT 環境中,并非所有事件都始于明顯的警報。這些問題可能始于細微的分散信號、錯過的警報、悄無聲息的 SLO 漏洞,或逐漸影響用戶的降級服務。
ITMonitron 由 NVIDIA IT 團隊設計,是一款有助于理解這些模糊信號的內部工具。通過將實時遙測與 NVIDIA NIM 推理微服務和 AI 驅動的摘要相結合,ITMonitron 可將分散的監控轉化為統一、可操作的智能,從而縮短檢測時間并加快決策速度。
愿景:從分散的信號到統一的智能
從應用程序到基礎設施監控,再到關聯工具,再到SaaS平臺,再到企業安全監控,大量的監控工具充斥著企業。每個工具都會生成自己的數據,而這些數據通常是孤立的。
結果如何?緩慢的事件檢測、腫的Mean Time to Detect、Mean Time to Resolve (MTTR) 以及大量的手動分診。
借助 ITMonitron,我們的目標是充當連接所有部件的結締組織,提供系統運行狀況的統一視圖,從而解決碎片化問題。
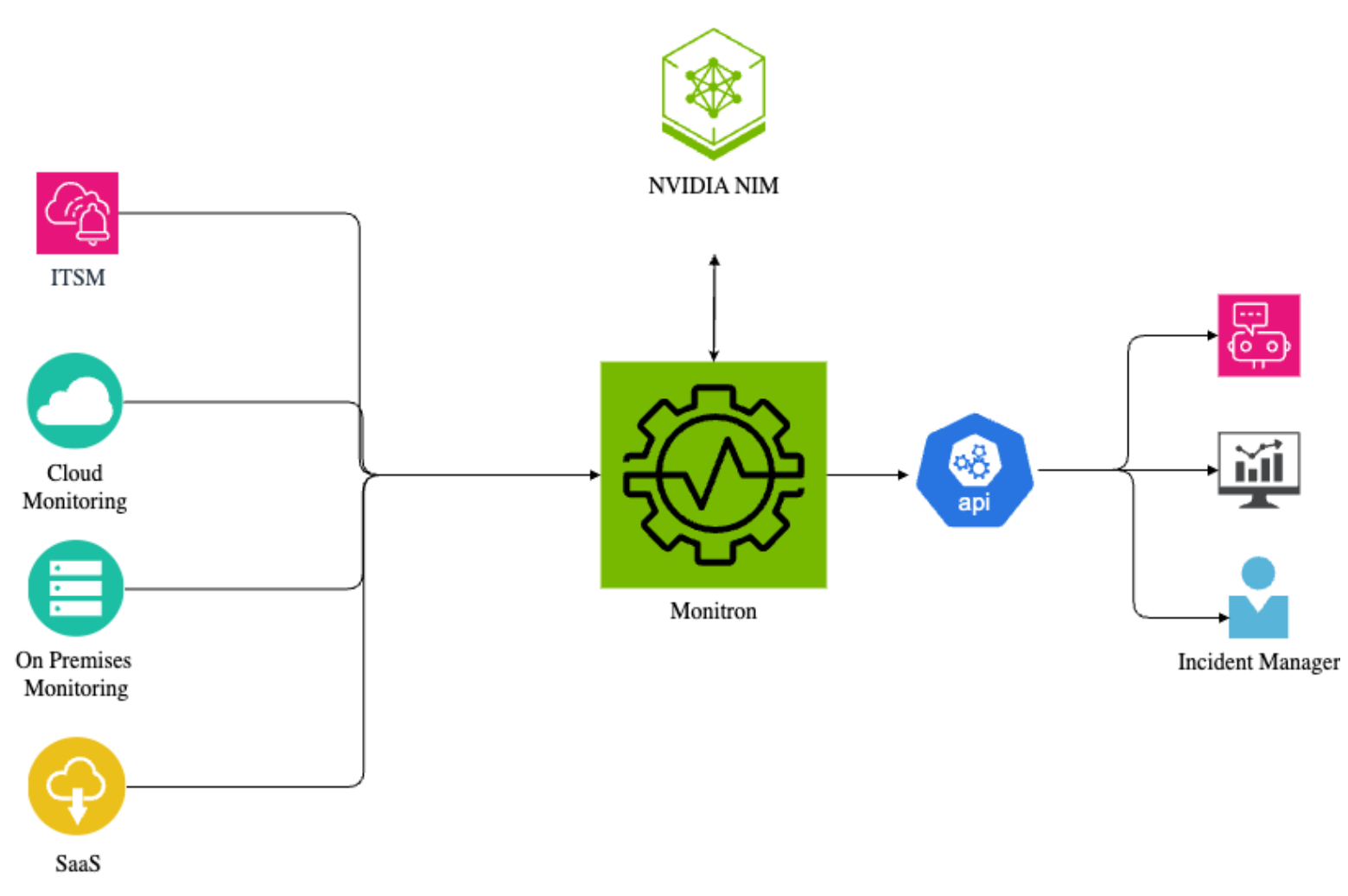
通過實時聚合、關聯和歸一化數據,ITMonitron 為 SRE、事件經理和高管提供 360°全方位的系統運行狀況視圖,幫助他們更快地檢測事件并更高效地做出響應。該組合可提供切實可行的見解,而不僅僅是原始警報。
幕后:設計脈沖
ITMonitron 是一個基于 Go 的模塊化平臺,專為高效的數據提取、歸一化和摘要而設計。該架構旨在與應用、基礎設施、SaaS 和云服務提供商的各種可觀察性和事件管理工具集成,使 SRE 團隊能夠有效地監控和管理系統。
該平臺的關鍵組件包括:
- API 網關層:用于跨多個監控源訪問數據的統一入口點。它可以簡化 API 復雜性,確保一致性,并優化緩存和性能。
- 源連接器:用于遙測提取的專用連接器套件。這些連接器可處理重試和數據格式可變性,確保彈性數據管道。
- 抽象和編排層:將遙測數據歸一化、關聯并豐富到一致的模式中。它還將緩存經常訪問的值,通過重復數據刪除和優先處理信號來減少噪音,并提供高效的數據處理流程。
- LLM 驅動的事件摘要:此層由 NVIDIA NIM 提供支持,可生成高背景、簡潔的事件報告,為技術團隊和高管降低噪音并提高清晰度。
- 自定義控制面板:Grafana 集成可為 SRE 和高管提供量身定制的實時可視化效果,從而促進快速決策和高效事件響應。
- 可擴展架構:ITMonitron 基于基于 REST 的通信的模塊化微服務框架構建,可確保可擴展性以及與新系統的輕松集成。
深入了解 ITMonitron:可擴展的 AI 引擎示例
與 NVIDIA NIM 的實時 LLM 集成
此層由 NVIDIA NIM 提供支持,可生成高背景、簡潔的事件報告,為技術團隊和高管降低噪音并提高清晰度。默認情況下,我們使用 llama-3.1-nemotron-70b-instruct 模型來平衡生產工作負載的準確性和性能。
為適應各種用例并提供靈活性,ITMonitron 通過 NIM 接口支持多個頂級模型。用戶可以從精心策劃的集合中動態選擇,包括:
- llama-3.1-405b-instruct
llama-3.3-nemotron-super-49b-v1 - llama-3.1-70b-instruct
- llama-3.1-Nemotron-Ultra-253b-v1
這種與模型無關的設計使我們能夠對摘要質量進行基準測試,適應不斷變化的模型性能,并確保事件敘事在各種環境中保持清晰、準確和可行。
示例摘要 (由 NVIDIA NIM 生成):
“由于 DNS 延遲,Service X 的性能降低。站點 A 和站點 B 之間觸發的警報。用戶可能會在西海岸受到影響。正在調查的根本原因。”相關持續變化:
- 站點 A Internet circuit 遷移和升級 (CHG001) 可能與站點 A 中的 Pan-FW 問題有關,盡管沒有明確確認直接相關。
- 錯誤的二級防火墻替換 (CHG002) 可能會關聯到與防火墻相關的警報。
這些簡潔、可操作的摘要使利益相關者能夠做出決策,而無需涉獵冗長的警報流或碎片化的dashboard。
智能停機驗證服務
基于 ITMonitron 平臺,我們最近開發了一項 Outage Validation 服務,解決了一個看似困難的問題:
這個用戶報告的問題是更廣泛的中斷的一部分嗎?
AI 功能可以解決根據實時基礎設施信號驗證用戶報告的問題的問題。
目前有兩個重要選項:
- 函數調用,其中 LLM 會解析用戶的查詢,識別要調用的函數或工具 (例如 checkDatadogMetrics、queryIncidentDB 等),提取正確的參數并編排響應。
- 代理式 AI,其中 LLM 充當自主智能體,可能具有內存,對多個工具和步驟進行推理,通過推理鏈、工具鏈等動態決定如何驗證中斷。
雖然這些方法功能強大,非常適合復雜的工作流程,但我們認為,這兩種方法都經過了過度設計,可用于中斷驗證這一具有明確界限的狹窄任務。
為什么不使用代理式 AI?
代理式系統具有靈活性,但需要進行重大權衡:
- 由于multi-step reasoning,它們的速度較慢。
- 它們在生產環境中更難以監控和調試。
- 它們往往會產生幻覺,尤其是在監控數據模糊或結構化薄弱時。
- 最重要的是,每次從零開始選擇正確工具和參數所產生的認知開銷,使得這些工具和參數不適合中斷檢測等延遲敏感型高精度用例。
為什么不單獨調用函數呢?
LLM 選擇預定義函數來運行的函數調用更輕量級,但仍然假設:
- 該模型可以準確地對問題類型 (app vs. 網絡 vs. 身份 vs. Wi-Fi 等) 進行分類。
- 它可以從雜亂的自然語言輸入中提取參數并對其進行歸一化。
- 即使問題模糊或跨越多個層,它也知道要調用哪個函數。
- 在實踐中,用戶查詢過于開放或依賴于上下文。例如:“我在嘗試從東京的酒店 Wi-Fi 登錄 VPN 時遇到超時”
… 可能涉及網絡、身份驗證、服務可用性,甚至是本地 ISP 問題。讓 LLM 選擇正確的診斷工具,而不會出現過擬合或悄無聲息的故障,這非常困難,而且通常很脆弱。
我們的理念是:在 LLM 真正大放異彩的地方發揮其作用
與讓 LLM 成為決策者和工具編排器不同,我們采用了以下方法:
- 我們通過不斷從監控來源中提取和扁平化停機候選數據,對所有相關信號進行預處理。
- 我們會生成環境中顯著問題 (包括服務、infra layers、和持續維護) 的實時摘要視圖。
- 我們要求 LLM 只執行一項任務:根據現有的中斷摘要交叉檢查自然語言用戶查詢,以確定該問題是否可能是更大的已知事件的一部分。
這種方法可顯著減少 LLM 的認知負荷。憑借更少的自由度和范圍更廣的提示,LLM 可以執行集中推理,從而實現更高的準確性、更少的幻覺和更可信的回答。
結構化響應格式
為了使停機驗證服務的輸出可由機器讀取并易于在不同系統中使用,我們要求 LLM 以嚴格的 JSON 格式返回響應。
{ "is_outage": true | false, "confidence": "NoConfidence" | "LowConfidence" | "HighConfidence", "reasoning": "<natural language explanation>"} |
此結構使我們能夠:
- 將服務作為可集成到各種下游系統 (例如 Slack 機器人、事件響應控制面板、售票系統) 的 REST API 公開。
- 無論使用何種接口,均可確保對驗證結果進行一致的programmatic handling。
- 根據結構化輸出 (例如,自動分配工單、在 is_outage:true 的情況下通知應召接線員) 啟用自動分類和警報。
- 隨著時間的推移記錄和分析響應,以改進模型行為,并系統地追蹤False Positives/ False Negatives。
通過避免非結構化自然語言回復,我們確保人類和機器都能從 LLM 的推理中受益,同時保持簡潔、確定性的 APIs 以實現自動化。
提示設計:精度受限
我們的停機驗證服務的核心是一個精心設計的提示,它引導 LLM 像確定性評估器一樣行事,而不是對話助手。
提示將模型定位為專家,將用戶報告的問題與實時監控摘要進行匹配。它被明確指示嚴格根據可用的監控數據做出決策,而不要在可驗證的數據之外進行推理或假設。
關鍵設計原則
嚴格匹配規則:只有當用戶的問題和中斷摘要之間存在直接、明確的匹配時,LLM 才允許確認中斷。它必須精確匹配服務名稱、位置和標識符,才能聲明高置信度結果。
明確的置信度值:提示定義了符合 HighConfidence 與 LowConfidence 決策條件的選項。這有助于下游系統和人類以結構化、機器可操作的方式解釋模型的確定性。
歸一化邏輯:由于用戶查詢是自由格式的,因此系統會指示模型執行基本歸一化 (刪除空格、處理大小寫不敏感等)處理用戶提及服務時的細微變化 (例如,“nv bot”與“nvbot”) 。
支持的服務列表:每個查詢都使用受支持應用程序的動態列表來確定范圍,該列表在運行時注入到提示中。這可確保模型僅評估其監控可見性的內容,并在事物超出該范圍時優雅地拒絕猜測。
通過 Slack Bot 實現高級易用性:Outage intelligence 在您的指尖
停機驗證服務現已在我們基于 Slack 的停機機器人中上線,使用戶和呼叫響應人員能夠無縫交互。任何人都可以使用:
/outage-validate is Service X down?/outage-validate having trouble connecting to wifi in Finland |
機器人會將查詢發送到我們的 REST API,運行基于 LLM 的驗證,并立即回復:提交查詢的用戶或呼叫事件管理器 (如果檢測到潛在的中斷匹配) 。這種實時反饋回路可提高用戶信任度,減少重復工單,并使事件團隊能夠更快、更智能地做出響應。
結果和后續動態
我們使用拇指向上/ 向下的反應將輕量級反饋回路直接引入停機機器人。在完成每個驗證響應后,用戶可以投票確定答案是否有用。這種反饋非常寶貴,因為它使我們能夠:
- 不斷完善提示,以提高清晰度和準確性。
- 在生產環境中試驗多個 LLM 和 LRM。
- 衡量現實世界的準確性,而不僅僅是理論評估分數。
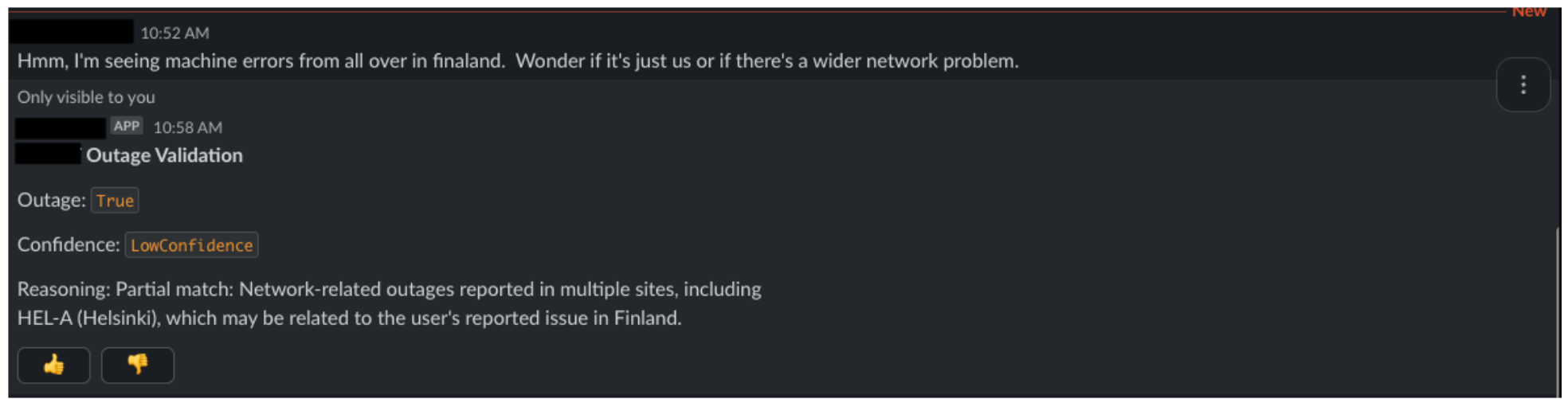
在 alpha 版本中,我們已收到 100 多個反饋響應,到目前為止,我們看到 93% 的反饋是積極的。這一早期信號表明,用戶期望的結果與模型返回的結果高度一致。我們目前正在使用這些反饋數據:
- 識別弱點 (false negatives/positives)
- 在候選模型之間運行 A/B 評估
- 調整提示策略以保持大規模性能
學習
構建 ITMonitron 既是一項工程挑戰,也是一次學習之旅。以下是我們開發過程中的一些關鍵要點:
- 警報降噪并非可選。并非所有警報都是平等的,并非每個事件都值得關注。其中一項最重要的學習是,高保真總結始于規范的Telemetry衛生條件。
- 抽象就是力量,但只有借助護欄才能實現。在不同平臺上對數據進行標準化是一項復雜的工作。學習意味著,雖然激進抽象化提高了 ITMonitron 的 API 可用性,但它必須與為高級用例公開特定于源的詳細信息的需求保持平衡。
- 提示工程是真實的。推動決策的執行摘要需要的不僅僅是語言流暢性。它們需要結構化上下文、特定領域的邏輯和有針對性的提示。所有這些都不是“開箱即用”的。我們了解到,Prompt Engineering和情境豐富是生產LLM系統的關鍵技能。
- 中斷驗證需要精確的范圍和約束。使用 LLM 成功驗證中斷需要嚴格范圍的提示和定義明確的匹配規則,以避免產生幻覺和誤報。將 LLM 的任務范圍縮小到根據精心策劃的停機摘要交叉檢查用戶查詢,可顯著提高準確性和可靠性。
- 實時用戶反饋回路可提高模型信任度。將用戶反饋直接整合到停機驗證機器人中,有助于快速識別邊緣案例,這對于持續改進和提高用戶對 AI 驅動的驗證的信心至關重要。
衡量重要事項
為了量化 ITMonitron 的影響,我們不斷跟蹤以下核心指標:
- 依賴項覆蓋:確保跨關鍵系統 100% 監控可見性
- 平均檢測時間 (Mean Time to Detect, MTTD) :通過智能關聯將 MTTD 減少 30%
- 信噪比降低:通過持續調整增強基于監控的檢測。
展望未來
展望未來,我們的目標不僅是減少 MTTR,而且要在中斷發生之前預測和預防。ITMonitron 體現了我們將智能系統與卓越運營相結合的承諾。即將推出的功能包括:
- 中斷驗證的置信度評分
- 歷史事件融合,以識別重復的模式和先兆
總結
ITMonitron 由 NVIDIA NIM 推理微服務提供支持,可將碎片化的遙測變得清晰明了,提供簡潔、可行的見解,并為 SRE、事件管理器和高管提供快速、統一的系統運行狀況視圖。此外,借助其智能停機驗證服務,ITMonitron 可幫助快速確認用戶報告的問題是否屬于更廣泛的事件,從而減少噪音并實現更快、更準確的響應。如果您面臨警報疲勞、數據孤島或延長的 MTTR,這些方法可能會提供一條前進的道路。
致謝
我們要對 IT 領導團隊的持續支持表示最衷心的感謝。特別感謝 Nina Mushiana 的遠見卓識和付出,她致力于確保 ITMonitron 的指示器和可視化效果不僅清晰直觀,而且還能為用戶提供清晰、可行的視圖。如果沒有他們的支持,這項計劃就不會充分發揮潛力。
?


