
異構計算架構——那些結合了各種協同工作的處理器類型的架構——在人工智能、機器學習( ML )、量子物理和通用數據科學中的計算工作負載的持續可擴展性方面被證明是非常有價值的。
這一開發的關鍵在于能夠抽象出異構體系結構,并促進一個框架,使設計和實現這類應用程序更加高效。實現這一點的最著名的編程模型是 CUDA Toolkit,它能夠按照單指令多數據模型將工作并行地分發到數千個 GPU 核心。
最近,一種新形式的節點級協處理器技術引起了計算科學界的注意:量子計算機,它依靠量子物理的非直觀定律,利用疊加、糾纏和干涉等原理來處理信息。這種獨特的加速器技術可能在非常具體的應用中被證明是有用的,并準備與 CPU 和 GPU 協同工作,開創了一個以前被認為不可行的計算進步時代。
問題變成了:如果你用量子協處理器增強現有的經典異構計算架構,你將如何以適合計算可擴展性的方式對其進行編程?
NVIDIA 使用 CUDA Quantum,一個開源編程模型,用量子內核擴展 C++ 和 Python,用于在量子硬件上編譯和執行。
這篇文章介紹了 CUDA 量子,強調了它的獨特功能,并展示了研究人員如何利用它在日常量子算法研發中積累動力。
CUDA 量子:你好,量子世界
首先來看一下 CUDA 量子編程模型,使用 Python 接口創建一個兩量子位 GHZ 狀態。這將使你習慣它的語法。
import cudaq
# Create the CUDA Quantum Kernel
kernel = cudaq.make_kernel()
# Allocate 2 qubits
qubits = kernel.qalloc(2)
# Prepare the bell state
kernel.h(qubits[0])
kernel.cx(qubits[0], qubits[1])
# Sample the final state generated by the kernel
result = cudaq.sample(kernel, shots_count = 1000)
print(result)
{11:487, 00:513}語言規范借用了 CUDA 已經證明是成功的概念;具體地說,主機和設備代碼在功能邊界級別上的分離。下面的代碼片段在 C ++中的 GHZ 狀態準備示例中演示了此功能。
#include <cudaq.h>
int main() {
// Define the CUDA Quantum kernel as a C++ lambda
auto ghz =[](int numQubits) __qpu__ {
// Allocate a vector of qubits
cudaq::qvector q(numQubits);
// Prepare the GHZ state, leverage standard
// control flow, specify the x operation
// is controlled.
h(q[0]);
for (int i = 0; i < numQubits - 1; ++i)
x<cudaq::ctrl>(q[i], q[i + 1]);
};
// Sample the final state generated by the kernel
auto results = cudaq::sample(ghz, 15);
results.dump();
return 0;
}
CUDA Quantum 允許將量子代碼定義為獨立的內核表達式。這些表達式可以是 C++ 中的任何可調用表達式(這里展示了 lambda,它是隱式類型的可調用表達式),但必須使用 __qpu__ 屬性啟用 nvq++ 編譯器 單獨編譯。內核表達式可以接受經典輸入(這里是量子位的數量),并利用標準 C++ 控制流,例如循環和 if 語句。
GPU 的效用
將實驗性努力QPUs從研究實驗室中擴大規模,并將其托管在云上以供普通訪問,這是一個了不起的成就。然而,目前的 QPU 噪聲大且規模小,阻礙了算法研究的發展。為了幫助解決這一問題,電路仿真技術正在滿足推動研究前沿的迫切需求。
桌面 CPU 可以模擬小規模的量子位統計;然而,狀態向量的存儲器需求隨著量子位的數量呈指數級增長。一臺典型的臺式計算機擁有 8GB 的 RAM ,使其能夠緩慢地模擬大約 15 個量子位。最新消息NVIDIA DGX H100使您能夠以前所未有的速度超越 35 量子位大關。
圖 1 顯示了典型變分算法工作流的 GPU 和 GPU 后端上的 CUDA Quantum 的比較。對 GPU 的需求在這里是顯而易見的,因為在 14 個量子位處的加速是 425x ,并且隨著量子位計數的增加而增加。外推到 30 個量子位, CPU – GPU 的運行時間為 13 年,而不是 2 天。這釋放了研究人員超越小規模概念驗證結果,實現更接近現實世界應用的算法的能力。
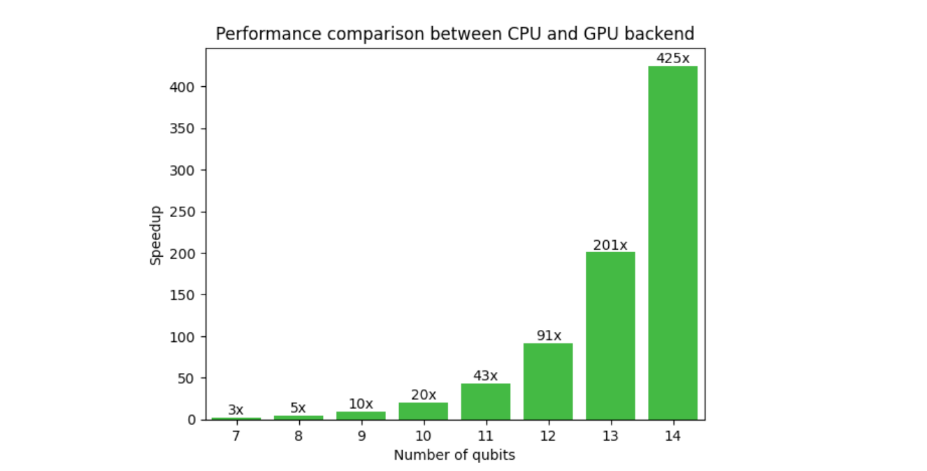
NVIDIA 與 CUDA Quantum 共同開發了 cuQuantum,一個庫,通過手工優化的 CUDA 內核,使用狀態向量和張量網絡方法實現量子計算機的快速模擬。內存分配和處理完全在 GPU 上完成,從而顯著提高了性能和規模。CUDA Quantum 與 cuQuantum 的結合,形成了一個強大的混合算法研究平臺。
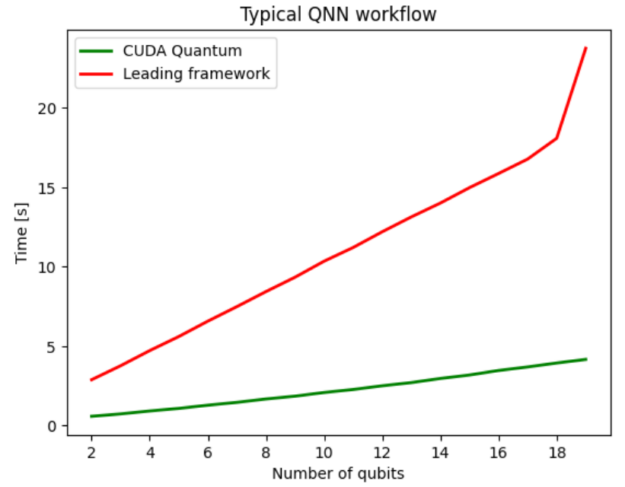
圖 2 將 CUDA Quantum 與領先的量子計算 SDK 進行了比較,兩者都利用 NVIDIA -cuQuantum 后端將電路模擬優化卸載到 NVIDIA GPU 上。在這種情況下,使用 CUDA Quantum 的好處是孤立的,與領先的框架相比,平均性能提高了 5 倍。
實現未來的多 QPU 工作流
CUDA 量子并不局限于考慮當前基于云的量子執行模型,而是充分預期了緊密耦合的系統級量子加速。此外, CUDA Quantum 使應用程序開發人員能夠設想具有多 GPU 后端的多 QPU 架構的工作流。
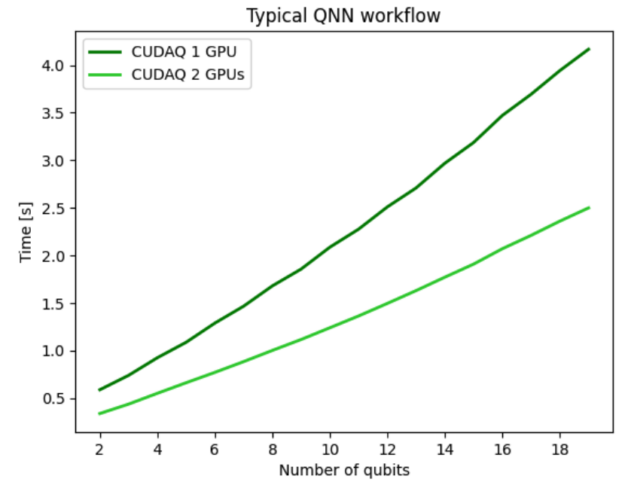
對于前面的量子神經網絡( QNN )示例,您可以使用 multi- GPU 功能來運行數據集的前向傳遞,使我們能夠執行未來的多 QPU 工作流。圖 3 顯示了將 QNN 工作流分布在兩個 GPU 上的結果,并展示了強大的擴展性能,表明所有 GPU ‘計算資源都得到了有效利用。使用兩個 GPU 使整個工作流程的速度是單個 GPU ‘的兩倍,顯示出強大的可擴展性。
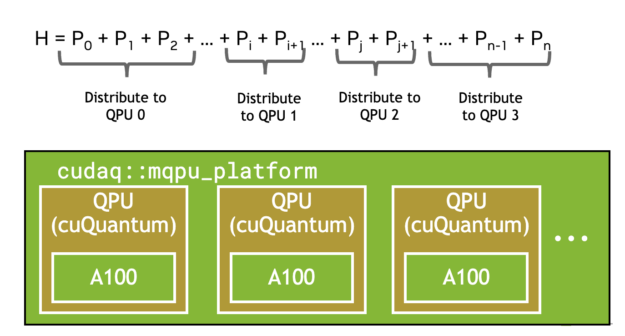
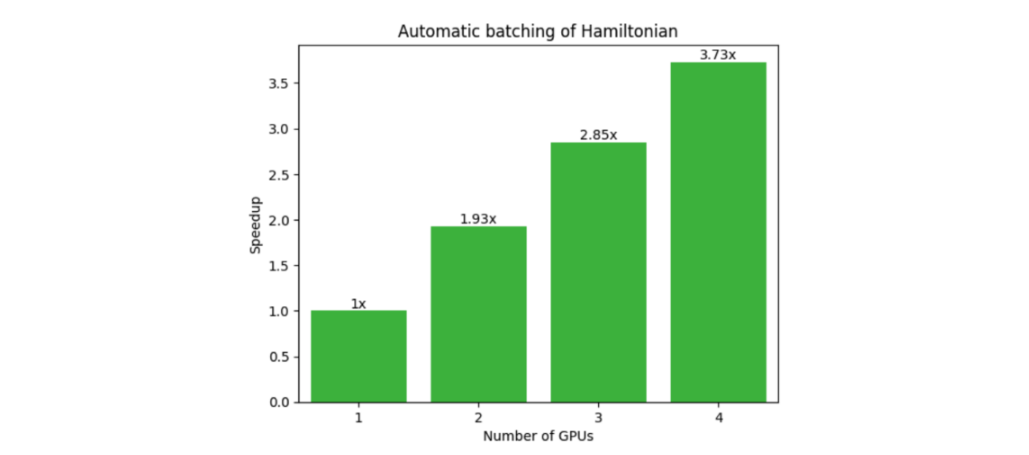
另一個受益于多 QPU 并行化的常見工作流程是變分量子特征解算器( VQE )。這需要由多個單泡利張量乘積項組成的復合哈密頓量的期望值。如下圖所示, CUDA Quantum 觀察調用會自動批量處理術語(圖 4 ),并在可用的情況下卸載到多個 GPU 或 QPU ,顯示出強大的可擴展性(圖 5 )。
numQubits, numTerms = 30, 1e5
hamiltonian = cudaq.SpinOperator.random(numQubits, numTerms)
cudaq.observe(ansatz, hamiltonian, parameters)
GPU -QPU 工作流
到目前為止,這篇文章已經探索了使用 GPU 將量子電路模擬擴展到 CPU 上可能的范圍之外,以及多 QPU 工作流程。以下部分將使用 PyTorch 和 CUDA quantum ,以混合量子神經網絡為例,深入探討真正的異構計算。
如圖 6 所示,混合量子神經網絡包含量子電路作為整個神經網絡架構中的一層。這是一個活躍的研究領域,有望在某些領域發揮優勢,改善泛化誤差。
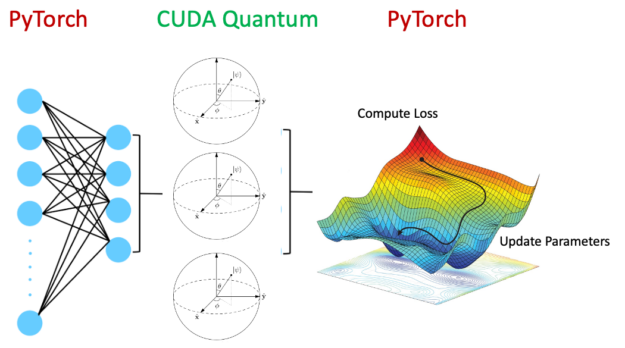
顯然,在 GPU 上運行經典神經網絡層和在 QPU 上運行量子電路是有利的。通過設置以下內容,可以使用 CUDA Quantum 加速整個工作流程:
quantum_device = cudaq.set_target('ion-trap')
classical_device = torch.cuda.set_device(gpu0)
這樣做的效用是深遠的。 CUDA Quantum 能夠以緊密集成、無縫的方式卸載適用于 QPU 和 GPU 的相關內核。除了混合應用程序之外,涉及糾錯、實時最優控制和通過 Clifford 數據回歸減少錯誤的工作流程都將受益于緊密耦合的計算架構。
QPU 硬件提供商
嵌入 CUDA 量子編程范式中的基本信息單元是量子位,它表示能夠訪問 d 態的量子比特。 Qubit 是 d = 2 的一個特定實例。通過使用量子位, CUDA Quantum 可以有效地針對各種量子計算架構,包括超導電路、離子阱、中性原子、基于金剛石的光子系統等。
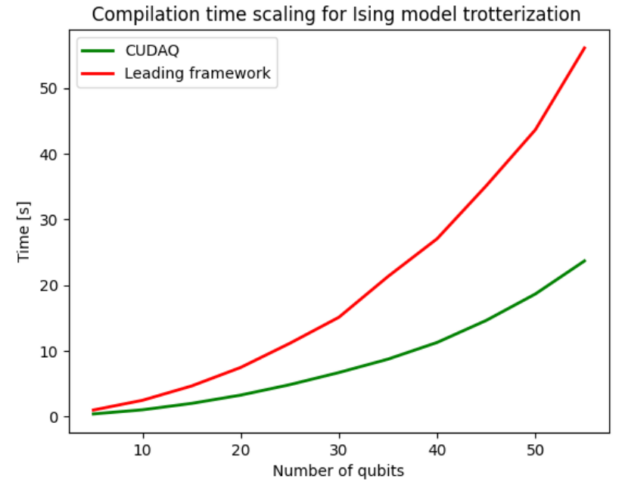
您可以輕松地開發工作流,使用 nvq++ 編譯器 在指定的體系結構上自動編譯和執行程序。圖 7 展示了新型編譯器產生的編譯加速。編譯過程包括電路優化,將其分解為硬件支持的原生門集和量子位路由。CUDA Quantum 使用的 nvq++ 編譯器與競爭對手相比,平均快 2.4 倍。
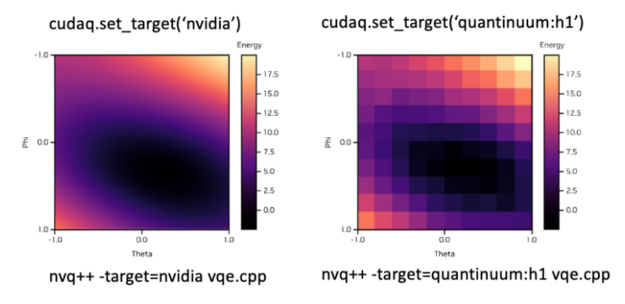
為了適應所需的后端,您可以簡單地修改set_target()旗幟圖 8 顯示了如何在模擬后端和 QuantinuumH1 離子阱系統之間無縫切換的示例。頂部顯示在 Python 中設置所需后端的語法,底部顯示在 C ++中。
開始使用 CUDA Quantum
本文簡單介紹了 CUDA 量子編程模型的一些特性。訪問 CUDA Quantum 社區的 GitHub 開始嘗試一些 示例代碼片段。我們期待著看到 CUDA Quantum 為您帶來的研究成果。
?




