
大數據分析領域正在不斷尋找加速處理和降低基礎設施成本的方法。Apache Spark 已成為用于橫向擴展分析的領先平臺,可處理 ETL、機器學習和深度學習工作負載的大型數據集。雖然傳統上基于 CPU,但 GPU 加速的出現提供了一個令人信服的前景:顯著加速數據處理任務。
但是,將 Spark 工作負載從 CPU 遷移到 GPU 并非易事。GPU 加速雖然對某些操作非常強大,但不一定能提高每個場景中的性能。小型數據集、大量數據移動以及使用用戶定義函數 (User-Defined Functions, UDFs) 等因素有時會對 GPU 性能產生負面影響。相反,涉及高基數數據的工作負載,例如連接、聚合、排序、窗口操作和轉碼任務 (例如編碼/壓縮 Apache Parquet 或 Apache ORC 或解析 CSV) 通常是 GPU 加速的積極指標。
這給希望利用 GPU 的組織帶來了一個關鍵問題:在投入時間和資源進行遷移之前,您如何知道您的特定 Spark 工作負載是否真正受益于 GPU 加速?Spark 工作負載在 CPU 和 GPU 上運行的特定環境可能會有很大差異。此外,網絡設置、磁盤帶寬甚至 GPU 類型都會影響 GPU 的性能,并且這些變量可能很難從 Spark 日志中捕獲。
認證工具?
針對此問題提出的解決方案是 Spark RAPIDS 驗證工具。此工具旨在分析您現有的基于 CPU 的 Spark 應用程序,并預測哪些應用程序適合遷移到 GPU 集群。它旨在使用基于行業基準和許多真實示例的歷史結果訓練的機器學習估計模型,在 GPU 上投射 Spark 應用程序的性能。該工具可通過 pip 包 作為命令行界面,并可在各種環境中使用,包括云服務提供商 (CSP) 如 AWS EMR 、Google Dataproc、 Databricks (AWS/Azure) 以及本地環境。有一些快速入門 notebook 專門用于 AWS EMR 和 Databricks 環境。
該工具的工作原理是,將基于 CPU 的 Spark 應用生成的 Spark 事件日志 作為主要輸入。這些事件日志包含有關應用程序、其執行程序和所用表達式的重要信息,以及相關的操作指標。該工具支持來自 Spark 2.x 和 Spark 3.x 作業的事件日志。

作為輸出,定性工具提供了幾個關鍵信息來幫助遷移過程:
- 合格的工作負載列表,指明哪些應用程序是 GPU 遷移的候選者。
- 推薦的 GPU Spark 配置,基于集群信息 (如內存和核心) 以及 Spark 事件日志中可能影響 GPU 上 Spark 應用程序性能的數據進行計算。
- 對于 CSP 環境 – 推薦的 GPU 集群形狀,包括實例類型和數量以及 GPU 信息。
輸出提供了一個起點,但必須注意的是,該工具并不能保證推薦的應用程序將得到最大的加速。該工具是一種預測性估算,我們將在下一節中詳細解釋該方法。該工具通過檢查 SQL Dataframe 操作任務所花費的時間來報告其結果。
您可以使用 CLI 命令從命令行運行該工具:spark_rapids qualification --eventlogs <file-path> --platform <platform>。
資格認證的工作原理?
那么,該工具如何在內部提供這些預測和建議呢?該驗證工具的核心在于它能夠分析輸入事件日志并提取各種指標,然后將其用作特征。該工具會解析原始事件日志,并生成包含每個 SQL 執行 ID (sqlID) 的原始特征的中間 CSV 文件。這些特征來自事件日志中的信息,例如磁盤字節溢出、使用的最大堆內存、估計的掃描帶寬、查詢計劃中各個運算符的詳細信息以及數據大小。
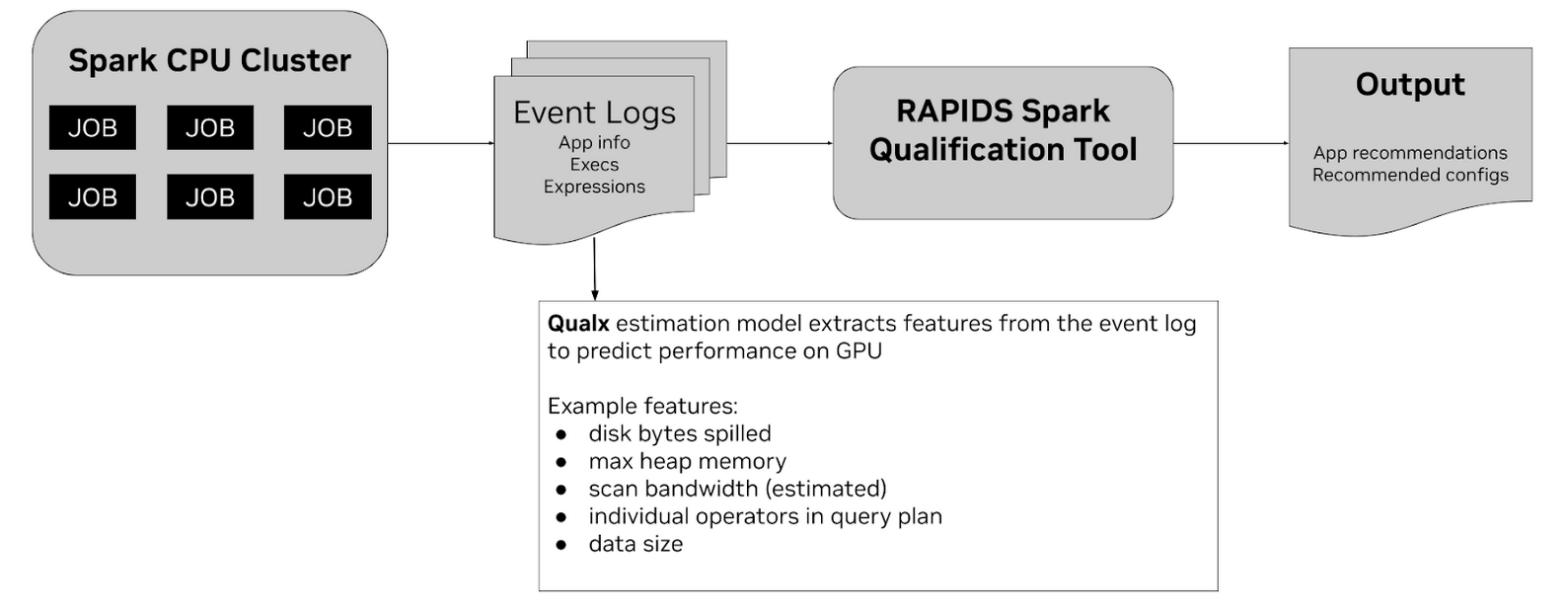
這些提取的特征可作為機器學習估計模型的輸入。此模型已基于各種 Spark 應用程序的 CPU 和 GPU 運行匹配的歷史數據進行訓練。通過利用這些訓練數據,模型可以學習預測應用程序在 GPU 上運行時可能實現的加速。該工具使用這些歷史基準測試中的數據來估算單個操作員的速度。然后,將此估計與其他相關啟發式算法相結合,以確定 GPU 遷移工作負載的總體資格。該工具附帶針對各種環境定制的預訓練估計模型,主要在 NDS 基準工作負載 上進行訓練。
構建自定義資格模型
雖然預訓練模型適用于許多場景,但您可能會遇到開箱即用的預測無法準確滿足特定需求的情況。如果您的工作負載與主要訓練模型的 NDS 基準測試不相似,如果您的 Spark 環境(硬件、網絡等)與預訓練環境明顯不同,或者您已在環境中的 CPU 和 GPU 上對大量工作負載進行基準測試,并觀察到與預測的差異。
在這些情況下,Spark RAPIDS 資格工具能夠構建自定義資格估計模型。這允許您專門根據自己的數據和環境訓練估計模型,從而有可能實現更準確的預測。

運行 CPU 和 GPU 工作負載并收集事件日志
要訓練能夠準確預測環境中 GPU 性能的模型,您需要包含為相同工作負載運行的 CPU 和 GPU 的訓練數據。該過程涉及在 CPU 和 GPU 集群上運行目標 Spark 應用程序,并收集生成的 Spark 事件日志。為每個工作負載收集 CPU 和 GPU 事件日志對至關重要。CPU 事件日志用于推導模型的特征,GPU 事件日志用于計算實際實現的加速,以此作為訓練的標簽。
預處理事件日志?
在訓練之前,需要處理收集的事件日志,以提取模型所需的特征。預處理步驟使用 Profiler 工具解析原始事件日志,并生成包含每個 sqlID 的“原始特征”的 CSV 文件。此過程可能需要一些時間,具體取決于事件日志的數量和大小。為優化后續運行,可以將 $QUALX_CACHE_DIR 環境變量設置為緩存這些中間 Profiler CSV 文件。可以使用 CLI 命令 qualx preprocess --dataset datasets 執行預處理步驟。
訓練 XGBoost 模型?
通過預處理提取特征后,您可以訓練自定義 XGBoost 模型。可以使用 spark_rapids train CLI 命令啟動訓練過程。您需要提供包含數據集 JSON 文件的目錄的路徑、要保存經過訓練的模型的路徑,以及生成的 CSV 文件的輸出文件夾。例如,您可以運行 spark_rapids train --dataset datasets --model custom_onprem.json --output_folder train_output。訓練過程利用機器學習并 利用 Optuna 進行超參數優化 。您還可以配置超參數搜索的試驗次數。模型在 SQL 執行 ID 級別 (sqlID) 上進行訓練。一般來說,對于“初始”模型,建議使用大約 100 個 sqlID,對于“良好”模型,建議使用大約 1000 個 sqlID。
評估功能重要性和模型性能
在訓練后,評估模型所使用特征的重要性非常有用。雖然估計模型具有內置的特征重要性指標 (增益、覆蓋、頻率) ,但也有可用的 Shapley (SHAP) 值,這些值提供博論重要性分配,并且是疊加的,可對最終預測進行求和。典型的重要特性包括持續時間、compute、和網絡 I/O。
您還可以通過比較預測的加速與從訓練數據中觀察到的實際加速來評估訓練模型的性能。理想的預測結果將落在單位線上 (預測的加速等于實際的加速) 。您可以選擇適合您用例的評估指標,例如 Mean Absolute Percentage Error (MAPE) 、精度或召回率。

使用自定義模型進行預測
在對自定義訓練模型的性能感到滿意后,您可以將其與驗證工具結合使用,以預測新的未見過的 Spark 應用的加速情況。運行 spark_rapids prediction 命令時,只需使用 --custom_model_file 參數提供經過訓練的模型文件 (例如 custom_onprem.json) 的路徑即可。然后,該工具將使用您的自定義模型 (而非默認的預訓練模型) 來分析事件日志,并提供加速預測和建議。輸出將包括每個應用程序和每個 SQL 的加速預測、用于預測的特征值以及特征重要性值。
通過構建自定義資格模型,您可以根據特定環境和工作負載定制預測過程,提高推薦的準確性,最終幫助您更有效地將 GPU 用于 Spark 應用。
在 GPU 上開始使用 Apache Spark
企業可以利用 適用于 Apache Spark 的 RAPIDS 加速器 將 Apache Spark 工作負載無縫遷移到 NVIDIA GPU。適用于 Apache Spark 的 RAPIDS 加速器將 RAPIDS cuDF 庫的強大功能與 Spark 分布式計算框架的規模相結合,利用 GPU 加速處理。通過使用 RAPIDS 加速器為 Apache Spark 插件 JAR 文件啟動 Spark,在不更改代碼的情況下在 GPU 上運行現有 Apache Spark 應用程序。
驗證工具也是 Project Aether 的一部分,Project Aether 是一系列工具和流程,可自動驗證、測試、配置和優化 Spark 工作負載,以實現大規模 GPU 加速。有興趣使用 Project Aether 協助其 Spark 遷移的組織可以 申請這項免費服務 。
有關資格認證工具的更多信息,請查看 Spark RAPIDS 用戶指南。如需了解有關此主題的更詳細的技術視圖,您可以觀看 GTC 2025 Spark RAPIDS 工具點播會議。
?





