
本系列第一篇文章是 “ Indiana Jones ? 中的路徑追蹤優化:Shader Execution Reordering 和 Live State Reductions ”,其中 介紹了 ray-gen shader 級別的優化,這些優化可加快“ Indiana Jones and the Great Circle?”的主要路徑追蹤通道 (“TraceMain”) 。
第二篇博文介紹了在游戲的路徑追蹤模式下,在 光線追蹤加速結構 層面針對植被密集的場景進行的其他 GPU 優化:
- 在 NVIDIA GeForce RTX 5080 GPU 上,使用 Opacity MicroMaps (OMMs) 將光線追蹤 Alpha 測試對象 (如植被模型) 所花費的 GPU 時間從 7.90 毫秒縮短到 3.58 毫秒。
- 壓縮動態植被模型的 Bottom-Level Acceleration Structures (BLASs),將所有 BLASs 所需的 VRAM 大小從 1027 MB 減小到 606 MB。
剖析的場景?

本文中的所有數據均來自圖 1 所示的秘魯場景,使用 GeForce RTX 5080 GPU,并使用表 1 中的圖形設置以及 Shader Execution Reordering (SER) 和 Live State Reductions 帖子中的 SER 優化功能。在本例中 (4K UHD with DLSS-RR Performance) ,路徑追蹤是在 1080p 下完成的。
| 設置 | 價值 |
| 輸出分辨率 | 4K UHD ( 3840 x 2160) |
| DLSS 模式 | DLSS 光線重建 、Performance Mode |
| 圖形預設 | 高 |
| 路徑追蹤模式 | 全景光線追蹤 |
| 光線追蹤光源 | 所有光源 |
| 植被動畫質量 | 極致 |
根據 Nsight Graphics RT Inspector 的數據,在此場景中,Ray Tracing Acceleration Structure (RTAS) 包含 2690 萬個三角形。
RT 著色器中的 Alpha 測試?
為了能夠在游戲中對所有經過 Alpha 測試的幾何圖形進行路徑追蹤,我們首先在路徑追蹤代碼中實施基本的 Alpha 測試支持。由于性能原因,該游戲的非路徑追蹤版本一直禁用 ray-traced Alpha 測試支持。
在 TraceMain 通道中,光線追蹤使用來自光線生成 (RayGen) 著色器的 GLSL traceRay 調用完成,并使用 Any-Hit Shaders (AHS) 實施 Alpha 測試。該 AHS 著色器從當前 Alpha 紋理中獲取紋理 LOD 0。然后,如果忽略命中,它會調用 ignoreIntersectionEXT。
對于陰影光線,我們使用了 rayQueryEXT 對象。我們無法使用 RayGen 著色器,因為引擎執行 Forward+ 渲染,因此必須在片段著色器中追蹤其中一些光線。rayQueryProceed 循環主體使用 rayQueryGetIntersectionInstanceShaderBindingTableRecordOffsetEXT 的偏移量獲取包含 covermap-texture 索引的緩沖區。然后,僅當 alpha 測試不應拒絕命中時,它才會調用 rayQueryConfirmIntersectionEXT。
GPU 初始性能?
在 GeForce RTX 5080 GPU 上,通過此初始實施,TraceMain 通道與 Nsight Graphics GPU Trace Profiler 中的圖 2 類似。
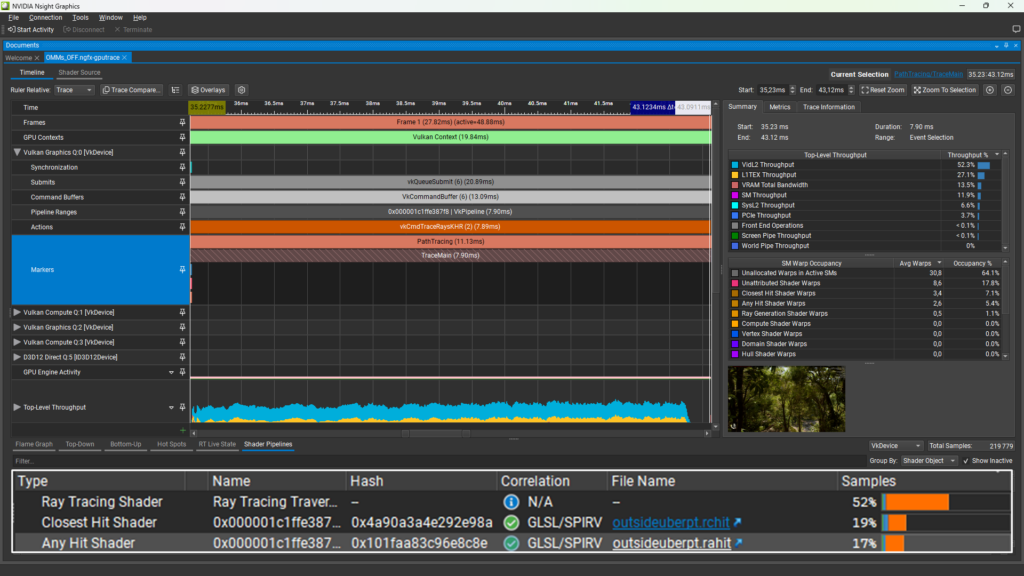
圖 2 顯示,TraceMain 通道耗時 7.90 毫秒,并且在 AHS 中花費了 17% 的周期著色器樣本。AHS 正在做的唯一一件事是進行 Alpha 測試。事實上,由于在遍歷和 AHS 評估之間切換會產生開銷,因此在 AHS 中進行 Alpha 測試的開銷要大于執行 AHS 本身所花費的時間。有關更多信息,請參閱 NVIDIA Ada GPU 架構白皮書。
為了加快路徑追蹤通道中的 Alpha 測試,我們使用 VK_EXT_opacity_micromap 添加了 Opacity MicroMaps 。
使用 Opacity MicroMap?
Opacity MicroMaps 可讓 GPU 通過預先計算微三角形的不透明度狀態來減少 AHS 調用的數量,并將其分類為以下狀態之一:
- 不透明
- 未知不透明
- 透明未知
- 透明
如果狀態是兩種未知狀態之一,則微三角形的不透明度狀態通常由 AHS 或 RayQuery 對象確定。對于陰影光線,我們使用了完全保守的四態 OMM。
對于間接照明光線,我們使用 gl_RayFlagsForceOpacityMicromap2StateEXT 標志,這使得 RTCore 單元使用 OMM 的雙狀態近似版本進行追蹤。這種近似值對于間接照明來說已經足夠好了,讓我們完全避免在著色器中評估帶有 OMM 的 BLAS 的 Alpha 測試。
在圖 1 的場景中,對大多數 alpha 測試模型啟用 OMM 后,路徑追蹤器的 SharcUpdate 和 TraceMain 通道的 GPU 時間減少了 55%,其中 SharcUpdate 最多可執行四次反彈以更新 SHARC 輻射緩存,而 TraceMain 最多可執行兩次反彈并重復使用 SHARC 緩存結果。在 SunTracing 通道上花費的 GPU 時間也加快了 14%。
| GPU 時間 | OMM 關閉 | OMM 已開啟 | 三角洲 |
SharcUpdate |
1.99 毫秒 | 0.89 毫秒 | -55% |
TraceMain |
7.90 毫秒 | 3.58 毫秒 | -55% |
SunTracing |
0.83 毫秒 | 0.71 毫秒 | -14% |
通過觀察 DispatchRays 通道的 Nsight Graphics GPU Trace Profiler,可以發現 AHS 中使用的周期樣本數量已經減少,并且增量與 GPU 時間增量處于相同的范圍內。
| 樣本 | OMM 關閉 | OMM 已開啟 | 三角洲 |
SharcUpdate |
4.37 K ( 12%) | 1.79 K ( 3%) | -59% |
TraceMain |
37.5 K ( 17%) | 12.2 K ( 3%) | -67% |
我們使用 VK_BUILD_MICROMAP_PREFER_FAST_TRACE 標志構建了所有 OMM,這使得 TraceMain 通道的 GPU 時間減少了 5%,而 BLAS 更新的速度稍慢。
烘焙 OMM?
我們集成了 OMM SDK ,并在 CPU 上為游戲中具有 covermaps 或 alpha textures 的大多數靜態模型烘焙了所有 OMM。這包括所有 vegetation,但也包括所有其他經過 alpha 測試的靜態模型,例如 fences、cloth、containers、tents 等。
最初,OMM 烘焙是在開發者工作站上完成的,但速度很慢,我們將所有烹飪過程都轉移到離線 cooker 中進行。該 cooker 在藝術家提交 mesh 或 covermap 更改后運行。通常,OMM 會與其他 cooked 數據一起推送到 Perforce 中。
以下是我們用于烘焙 OMM 的參數。我們使用四態格式制作了所有 OMM,并調整了細分參數,以便在 VRAM 大小和效率之間實現良好的權衡:
ommFormat_OC1_4_StateommUnknownStatePromotion_ForceOpaquemaxSubdivisionLevel: 6dynamicSubdivisionScale: 2.0
在烘焙游戲中的所有 OMM 時,我們遇到了一個意想不到的問題:少數 OMM 的烘焙時間超過 30 分鐘,有時需要數小時。在這些情況下,對 OMM baker 的輸入 (UV 和 alpha 貼圖) 沒有任何錯誤。只是因為 UV 三角形或 alpha 貼圖的復雜性使得烘焙過程比平常更長。
如果使用 OMM SDK 的 GPU 烘焙路徑,則這一時間將大大減少,但這不可能實現,因為烹飪機沒有 GPU,并且在添加 OMM 時無法更改。為了解決這個問題,我們使用以下 OMM SDK 參數讓 OMM 烘焙師跳過 OMM,而這些 OMM 在 CPU 上烘焙會花費太長時間:
bakeFlags: ommCpuBakeFlags_EnableWorkloadValidationmaxWorkloadSize: 1ull << 32
烘焙時間與微三角形覆蓋的 texels 數量成正比。這就是工作負載大小。這反過來又是三角形數量、紋理分辨率、細分比例和 UV 坐標的函數。當工作負載驗證標志啟用時,OMM baker 會發出警告消息,這有助于調整 maxWorkloadSize 閾值。
以下是復雜植被模型的此類警告示例:
[Perf Warning] - The workload consists of 869,002,294 work items (number of texels to classify), which corresponds to roughly 828 1024x1024 textures. |
在圖 3 和圖 4 中,X 軸是 OMM index。

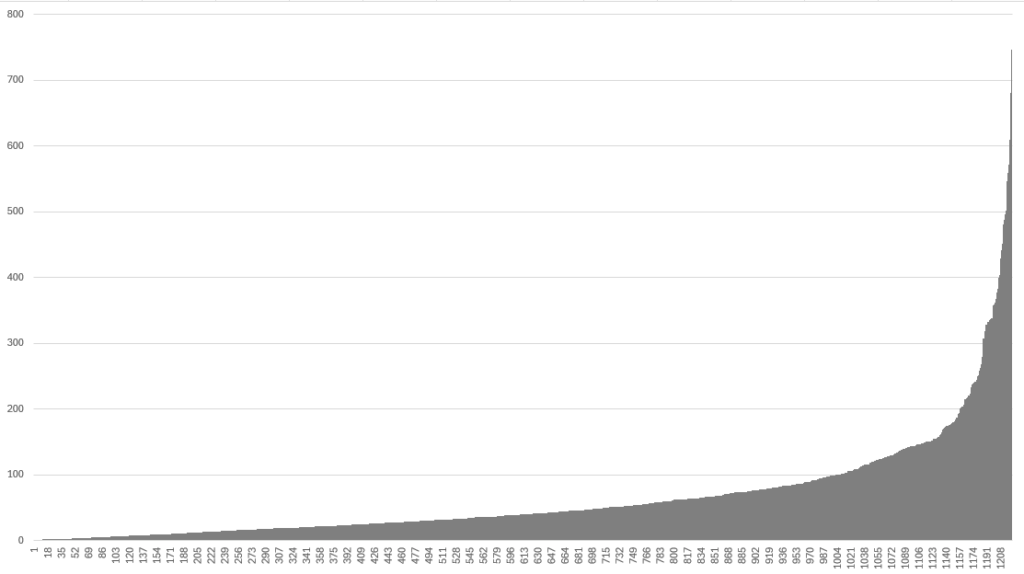
圖 3 和圖 4 中的直方圖顯示,在秘魯地圖和啟用 OMM 工作負載驗證標志的情況下,95% 的 OMM 只需不到 1 秒即可生成,每個 OMM 占用的空間不到 200 kB。在這項研究中,OMM 在本地重新烘焙,并在引擎中禁用多線程資源生成。
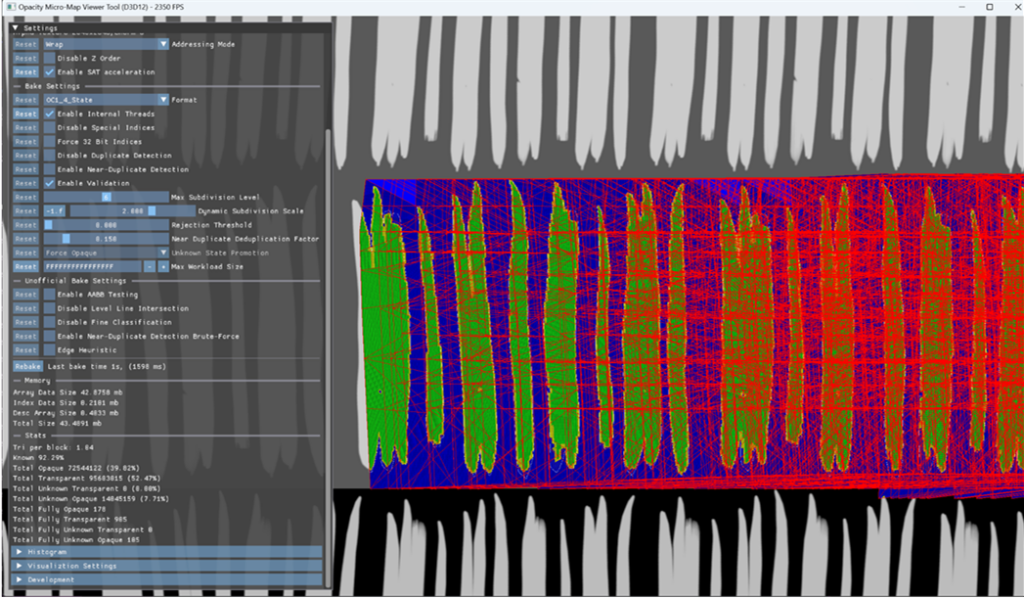
后來,我們發現還有一個問題:一些 OMM 占用了大量 VRAM。例如,其中一家單獨占用了 43 MB 的 VRAM (圖 5) 。同樣,OMM baker 輸入沒有任何問題,只是 UV 封裝的復雜性和覆蓋圖的復雜性導致生成的 OMM 非常龐大。
當存在 UV 三角形重用時,例如樹上的葉子被實例化多次時,OMMs 的內存效率更高。在這種情況下,baker 幾乎沒有發現任何重疊或可能的重復使用,導致 OMM 數據陣列中出現超過 55K 個唯一條目。作為最后一分鐘的變通方法,我們實施了一個額外步驟,跳過了所有 OMM,而這些 OMM 會占用超過 0.5 MB 的 VRAM。大多數 OMM 都低于該值。最后,游戲中每個地圖的所有 OMM 都符合 128-MB VRAM 預算。Release 1.7.0 的 OMM SDK 添加了替代解決方案,將 OMM 輸出大小保持在每個 OMM 的特定 VRAM 預算下。以下代碼顯示了 OMM CPU baker 的此新參數:
// Max allowed size in bytes of ommCpuBakeResultDesc::arrayData// The baker will choose to downsample the most appropriate omm blocks (based on area, reuse, coverage and other factors) until this limit is metuint32_t maxArrayDataSize; |
驗證 OMM 是否存在?
我們實施了 path-tracing 調試模式,可將 ray-tracing 主光線的結果可視化,并根據 RayQuery 循環是否必須執行多次迭代,使用不同的調試顏色。循環僅迭代一次的主光線可以在 RTCore 硬件單元中進行全景光線遍歷,并以綠色顯示。其他光線以紫色顯示。一些像素還以藍色顯示,在此上下文中可以忽略。
為了驗證所有原本配備 OMM 的 BLAS 是否確實配備了 OMM,我們發現將此調試模式與強制設置 gl_RayFlagsForceOpacityMicromap2StateEXT 光線標志并檢查游戲各區域中所有具有紫色像素的模型相結合非常有用。我們甚至請求通過此模式的 QA 環節,要求報告此模式中包含紫色像素的游戲區域。

圖 6 在與圖 1 相同的場景中使用此調試視圖與強制 2 狀態 OMM。有幾棵樹沒有 OMM,很可能是由于每個 OMM 按上述最大大小刪除了已 cooked OMM,但大多數樹確實有 OMM。
壓縮動態 BLAS?
通常,BLAS Compaction 僅用于一次性構建、壓縮且從未重建或更新的 BLAS。但是,BLAS Compaction 也適用于 BLAS,這些 BLAS 經過構建、壓縮,然后進行更新或改裝。
BLAS 與 BLAS 規整兼容的唯一限制是,此 BLAS 在規整后不應重建。其原因是,在重建后,BLAS 的壓縮大小可能會有所不同。
事實證明,游戲中動態植被模型的 BLAS 無需重建,因此它們與 BLAS Compaction 兼容,我們也將其用于這些模型。通常情況下,最好定期為動態幾何圖形重建 BLAS,但動態植被在風中波動,在角色的腳下變形,并且總是在某個點返回到其初始位置。因此,為了保持 BLAS 的高質量,無需針對動態植被定期重建 BLAS。
游戲中為所有動態植被模型啟用了 Dynamic-BLAS 規整。在圖 1 的場景中,這樣一來,在 NVIDIA RTX 5080 GPU 上,分配給所有 BLAS 的 VRAM 從 1027 MB 減少到 606 MB,節省了 41%。
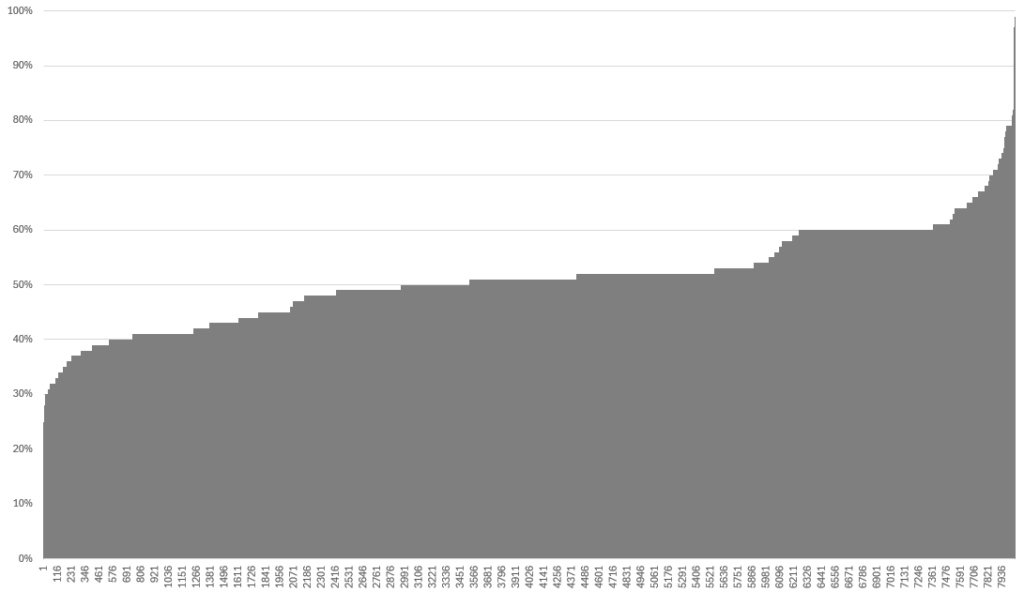
圖 7 顯示了基于 NVIDIA RTX 5080 GPU 的基于 BLAS 的動態 BLAS 規整所節省的 BLAS VRAM。X 軸是 BLAS 索引,Y 軸是壓縮后的 VRAM 大小 (占原始 BLAS 大小的百分比) 。通常,壓縮后的 BLAS 的大小是原始 BLAS 的 50%。
據記錄,所有采用動態 BLAS 規整的 BLAS 都具有以下 BLAS 構建標志:PREFER_FAST_BUILD | ALLOW_UPDATE | ALLOW_COMPACTION。
總結?
Opacity MicroMaps (OMMs) 是在使用 alpha 測試材質的場景中加速 traceRay 調用或 rayQuery 對象的有效方式。OMMs 讓硬件避免在 RTCore 單元級別調用 Any Hit Shaders 或 rayQuery 循環中的等效著色器代碼。OMMs 在 GeForce RTX 40 和 50 系列的 RTCore 單元中進行硬件加速。在 DX12 應用中,它們通過 DXR 1.2 或 NVAPI 公開。只要 BLAS 經過更新或改裝,并且在初始構建后從未重建,BLAS 規整就與動態幾何的 BLAS 兼容。壓縮動態植被模型的所有 BLAS 對于讓 Indiana Jones and Great Circle 在 12-GB GPUs 上以無損的路徑追蹤質量進行游戲至關重要,從而將秘魯叢林場景中 BLAS 所需的顯存總量從 1027 MB 減少到 606 MB。
這兩種優化在游戲初始版本中均支持 Path Tracing。
第一篇博文 Shader Execution Reordering 和 Live State Reductions 介紹了光線生成著色器級別的優化,在“ Indiana Jones and the Great Circle ”的簡介場景中,這些優化使 GPU 上的主要路徑追蹤通道 (TraceMain) 成本降低了 25%。
致謝?
在此,我們要感謝來自 NVIDIA 和 MachineGames 的所有人,他們于 2024 年 12 月 9 日推出了帶有路徑追蹤功能的“ Indiana Jones and the Great Circle?”。
MachineGames:Sergei Kulikov、Andreas Larsson、Marcus Buretorp、Joel de Vahl、Nikita Druzhinin、Patrik Willbo、Markus ?lind、Magnus Auvinen、Jim Kjellin、Truls Bengtsson、Jorge Luna (MPG)。
NVIDIA:Ivan Povarov、Juho Marttila、Jussi Rasanen、Jiho Choi、Oleg Arutiunian、Dmitrii Zhdan、Evgeny Makarov、Johannes Deligiannis、Fedor Gatov、Vladimir Mulabaev、Dajuan Mcdaniel、Dean Bent、Jon Story、Eric Reichley、Magnus Andersson、Pierre Moreau、Rasmus Barringer、Michael Haidl 和 Martin Stich。
?





