
本文是“ Indiana Jones? 系列 中的 Path Tracing Optimizations”的一部分 。
在 2024 年為“ Indiana Jones and the Great Circle?”添加路徑追蹤模式時,我們使用了 Shader Execution Reordering (SER),一項自 NVIDIA GeForce RTX 40 Series 發布以來,NVIDIA GPU 就一直支持的功能,來提高 GPU 性能。
為優化 SER 在主路徑追蹤通道 (TraceMain) 中的使用,我們使用了 NVIDIA Nsight Graphics GPU Trace Profiler。我們發現,其 RayGen 著色器 使用大量光線追蹤 (RT) 實時狀態字節,這降低了 SER 的效率。通過在 GPU Trace Profiler 中使用“ Ray Tracing Live State ”選項卡,我們確定了一些導致 RT 實時狀態字節的 GLSL 變量,并消除了這些變量或減小了其大小。
因此,在 NVIDIA GeForce RTX 5080 GPU 上,SER 現在可以在以下配置場景中的 TraceMain pass 上節省 24% 的 GPU 時間。
剖析的場景?

本文中的所有數據均來自“Indiana Jones and the Great Circle?”在 GeForce RTX 5080 GPU 上的游戲第一幕,圖形設置請參見表 1。
| 設置 | 價值 |
| 輸出分辨率 | 4K UHD ( 3840 x 2160) |
| DLSS 模式 | DLSS 光線重建 、性能模式 |
| 圖形預設 | 高 |
| 路徑追蹤模式 | 全景光線追蹤 |
| 光線追蹤光源 | 所有光源 |
| 植被動畫質量 | 極致 |
游戲的這一部分發生在一個擁有大量密集且經過 Alpha 測試的幾何圖形的叢林中。它是光線追蹤最具挑戰性的位置之一。將 DLSS-RR 設置為“Performance”模式,并將輸出分辨率設置為 4K UHD (3840 x 2160) 時,路徑追蹤將在 1080p 下完成。
起點:4.08 毫秒?
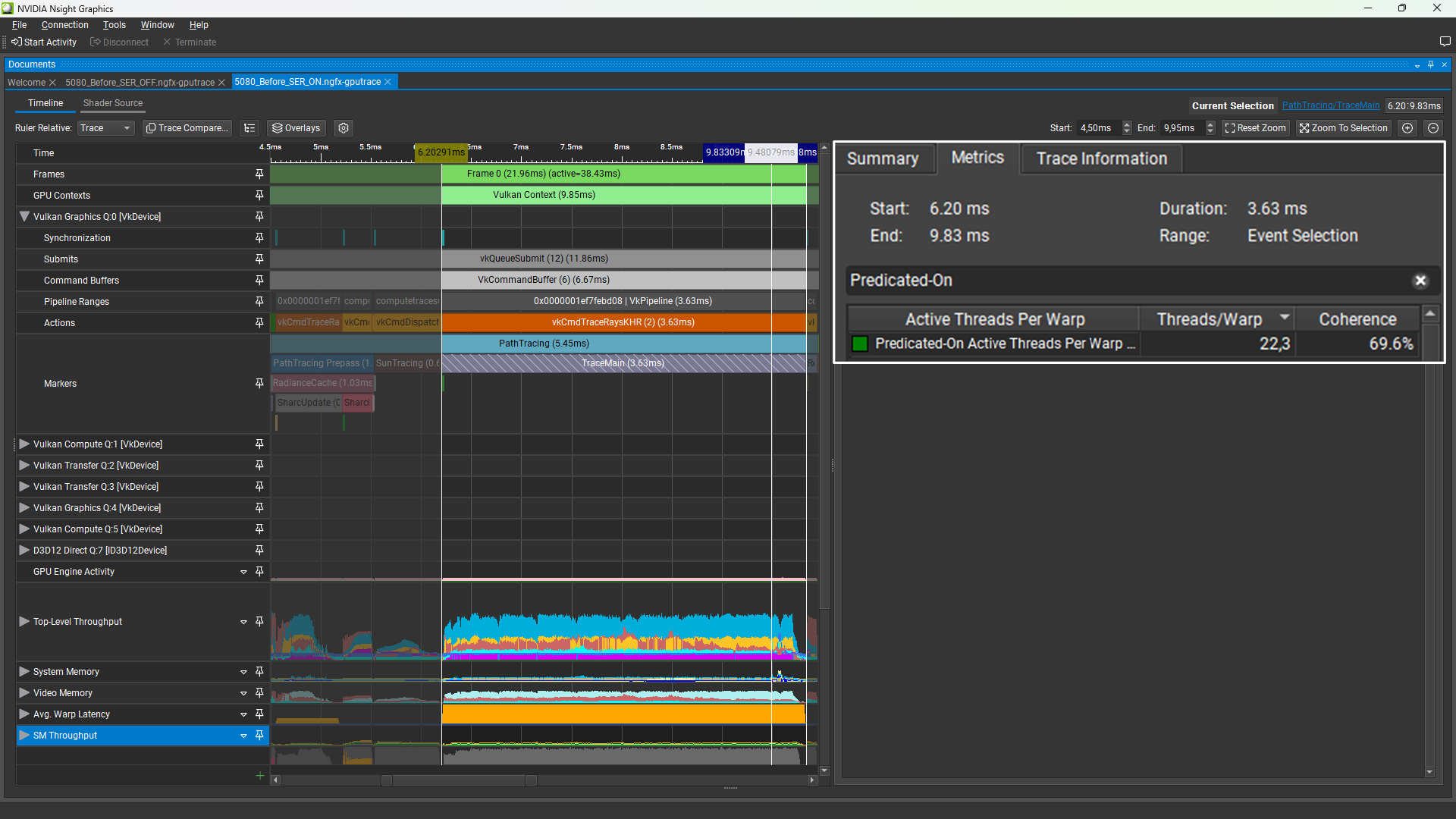
圖 2 顯示了 Nsight Graphics 的 GPU Trace Profiler 中的 TraceMain 通道。

根據 GPU Trace 提供的信息,此 cmdTraceRays 工作負載具有以下 GPU 指標:
- GPU 時間: 4.08 毫秒
- 每個 Warp 基于 預測的活動線程數 :38%
Predicated-On Active Threads per Warp 百分比指標是 SM 級別上每個已執行指令的 SIMT 主動線程通道 (32 通道) 的平均值。
以下原因可能會導致每個 warp 的活動線程百分比欠佳:
- 在線程束中具有離散回路數量的動態回路
- 在線程束中具有離散執行路徑的動態分支
- 在 RayGen 著色器中,warp 內調用不同的 hit shaders
圖 3 顯示離散動態分支增加著色器延遲的原因。有關更多信息,請參閱 使用 NVIDIA Nsight Graphics 優化圖形應用程序的 GPU 工作負載 。
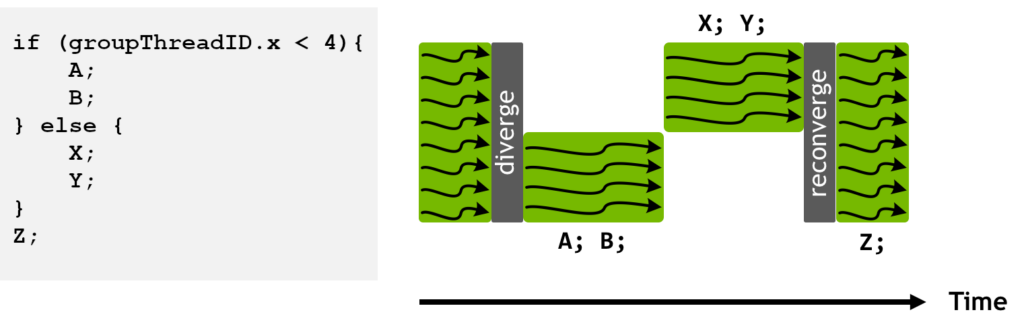
著色器執行重排序?
對于 RayGen 著色器, Shader Execution Reordering (SER) 是提高每個線程束活動線程的平均百分比的有效方法。SER 可用于在調用 traceRay 后,根據命中對象驅動的密鑰和用戶提供的可選一致性提示,對 RayGen 著色器的線程進行重新排序。
在重新排序調用后,調用 hit shader 或訪問 hit-related 數據將更加一致,因為具有相同或相似密鑰的線程會分組在一起執行。
- 對于 Vulkan,SER 由 VK_NV_ray_tracing_invocation_reorder 擴展程序公開。
- 對于 DX12,SER 現已在 DXR 1.2 或通過 NvAPI 提供。
為在引擎中實施 SER,我們為支持 SER (GeForce RTX 40 及更高版本) 的 GPU 添加了主路徑追蹤 RayGen 著色器的著色器置換,并使用以下 GLSL 代碼:
#if defined( RPF_RT_ENABLE_SER ) hitObjectNV hitObject; traceRayHitObject( hitObject, rayFlags, instanceMask , ray, rayPayload, topLevelAccelerationStructure ); reorderThreadNV( hitObject, bounceNum == ( bounceId + 1 ) ? 1 : 0 , 1 ); hitObjectExecuteShaderNV( hitObject, _hitPayloadIndex( rayPayload ) );#else traceRayEXT( rayFlags, instanceMask , ray, rayPayload, topLevelAccelerationStructure );#endif |
一致性提示 bounceNum == ( bounceId + 1 ) ? 1 : 0 是原始 Shader Execution Reordering 白皮書中所述理念的實現:“可以在路徑追蹤器或多次反射反射中找到相關情況。在一致性提示中包含一些關于主循環是否會終止的額外信息通常非常有效。”
使用 SER 時:3.63 毫秒?
通過實施 SER,TraceMain 傳遞成本降低了 11% (4.08 => 3.63 ms),并且每個 Warp 指標的平均 Predicated-On 活動線程數 從 38% 增加到 70% (圖 4)。
| ? | SER 關閉 | SER ON |
| GPU 時間 | 4.08 毫秒 | 3.63 毫秒 |
| 活動線程/ 線程束 | 38% | 70% |
光線追蹤實時狀態溢出?
表 3 顯示了 GPU 指標,以便您了解兩種追蹤之間的變化:
| ? | SER 關閉 | SER ON |
| VidL2 吞吐量 | 58.3% | 85.6% |
| L1TEX 吞吐量 | 30.6% | 43.0% |
| 來自 L1TEX 的 VidL2 總計 | 9.22 GiB | 12.55 GiB |
如果 RayGen 著色器在關閉 SER 的情況下具有大量溢出的光線追蹤實時狀態字節,則向 RayGen 著色器添加 SER 實際上預計會增加 L2 流量。在繼續執行 RayGen 著色器時,這些是 ray-tracing 驅動程序在調用 traceRay 并在完成 traceRay 調用后重新加載之前保存到內存中的局部變量。
由于在重新排序線程時,實時狀態數據可能必須通過 SER 實現在 GPU 中傳輸,因此在出現 reorderThread 時,RT 實時狀態溢出的成本可能會更高。traceRay 或 reorderThread 調用站點的 RT 實時狀態溢出字節數越多,實時狀態可能產生的 GPU 開銷就越多。
光線追蹤實時狀態選項卡?
圖 5 來自 GPU Trace Profiler,在工具的右下角區域顯示了與選定時間范圍 (本例中為 TraceMain 通道) 相關的 Shader Profiler 數據摘要部分。

首先,將水平分隔符從工具的左下角和右下角一直拖動到左側,然后選擇“Ray Tracing Live State”選項卡:

圖 6 顯示,對于每個 RT 調用站點 (traceRay、reorderThread 或 callable) ,GLSL 聲明了在 RT 調用站點之前聲明并在調用站點之后重新使用的變量,并且 RT 驅動程序已針對這些變量在調用站點周圍執行 live-state spilling (在調用站點之前將變量值寫入內存,然后在之后重新加載) 。
在本例中,此 RayGen 著色器的每個線程總共向全局內存溢出了 222 字節。
優化 1:循環移除?
現在,我們來展開有關 callsite #2 的信息,查看與溢出的 RT 實時狀態聲明對應的 GLSL 行列表:
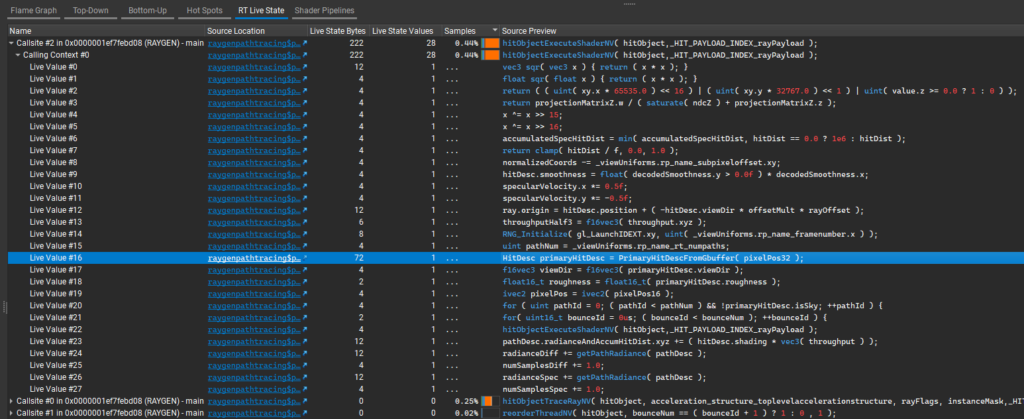
列表中最大的條目是:
HitDesc primaryHitDesc = PrimaryHitDescFromGbuffer( pixelPos32 ); |
此 primaryHitDesc 結構體從 RayGen 開頭的 GBuffer 初始化,其值用于確定是否追蹤以及如何追蹤第一束光線。
但是,鑒于此結構體應僅用于設置第一個光線,為何在首次調用 traceRay 后重復使用此結構體的 72 字節?RayGen 的路徑循環如下,其中 PATHTRACE 在內部循環中調用 traceRayHitObject 和 reorderThreadNV:
for( uint pathId = 0; ( pathId < pathNum ) && !primaryHitDesc.isSky; ++pathId ) { PathOutputDesc pathDesc = PathOutputDescNull(); //... PATHTRACE( pixelPos, primaryHitDesc, bounceNum, pathDesc ); if( pathDesc.isValid == false ) { continue; } //... if( pathDesc.isDiffuse ) { hitDistanceDiff = normHitDist; radianceDiff += pathDesc.radiance; numSamplesDiff += 1.0; } else { NRD_FrontEnd_SpecHitDistAveraging_Add( hitDistanceSpec, normHitDist ); radianceSpec += pathDesc.radiance; numSamplesSpec += 1.0; }}radianceDiff /= max( 1.0, numSamplesDiff );radianceSpec /= max( 1.0, numSamplesSpec ); |
在發布游戲中,pathNum 始終為 1,因此此循環實際上是一個分支。因此,對于循環的每次新迭代,完整的 primaryHitDesc 結構體都會在 for 循環之前溢出,并在每次循環迭代開始時重新加載。由于此循環在實踐中確實是一個分支,因此我們將其重寫為:
PathOutputDesc pathDesc = PathOutputDescNull();if ( !primaryHitDesc.isSky ) { //... PATHTRACE( pixelPos, primaryHitDesc, bounceNum, pathDesc, throughput ); //... if ( pathDesc.isValid ) { if( pathDesc.isDiffuse ) { hitDistanceDiff = normHitDist; radianceDiff += pathDesc.radiance; } else { NRD_FrontEnd_SpecHitDistAveraging_Add( hitDistanceSpec, normHitDist ); radianceSpec += pathDesc.radiance; } }} |
將循環更改為 isSky 分支可刪除溢出的 72 字節 RT 實時狀態。
優化 2:使用 FP16 Precision
圖 7 的“ Ray Tracing Live State ”選項卡中列出了以下 GLSL 行:
pathDesc.radianceAndAccumHitDist.xyz |
這將跟蹤每條路徑的 accumulated radiance:
pathDesc.radianceAndAccumHitDist.xyz += ( hitDesc.shading.xyz * throughput.xyz ); |
radianceAndAccumHitDist 變量被聲明為 float4,這在本例中是多余的。通過將 radianceAndAccumHitDist 的精度從 float4 降級為 half4 (f16vec4),它編譯為四個 FP16 值,該四維向量的 RT 實時狀態大小將減半,且不會影響圖像質量。
RT 實時狀態優化前后
啟用 SER 后,對于 TraceMain 通道,RT 實時狀態優化已將 GPU Trace 中報告的 RT 實時狀態從 222 字節減少到 84 字節,并且在 NVIDIA RTX 5080 GPU 上,該通道花費的 GPU 時間減少了 15% (3.63 => 3.08 毫秒)。
| 開啟 SER | 之前 | 之后 |
| GPU 時間 | 3.63 毫秒 | 3.08 毫秒 |
| 活動線程/ 線程束 | 70% | 68% |
| RT 實時狀態泄露 | 222 字節 | 84 字節 |
圖 8 顯示了具有 SER ON 的 Before 版本,大小為 222 字節。

圖 9 顯示了具有 SER ON 的 After 版本,共 84 bytes。

在 RT 實時狀態優化后,SER ON 與 SER OFF 的比較
在 RT 實時狀態優化之前,啟用 SER 可使 GeForce RTX 5080 GPU 上的 TraceMain 通道成本降低 11%。
| 之前 | SER 關閉 | SER ON |
| RT 實時狀態泄露 | 180 字節 | 222 字節 |
| GPU 時間 | 4.08 毫秒 | 3.63 毫秒 ( -11%) |
| 活動線程/ 線程束 | 38% | 70% |
現在,在使用 Nsight GPU Trace Profiler 優化 RT 實時狀態后,我們將在與之前相同的條件下,再次比較該通道上的 SER ON 與 SER OFF,但 GLSL 與實時狀態優化的差異除外。
| 之后 | SER 關閉 | SER ON |
| RT 實時狀態泄露 | 68 字節 | 84 字節 |
| GPU 時間 | 4.07 毫秒 | 3.08 毫秒 ( -24%) |
| 活動線程/ 線程束 | 38% | 68% |
減少 GLSL 中 RT 實時狀態溢出的字節數使 SER 成為更強大的加速器。在 RT 實時狀態歸約優化后,啟用 SER 可節省 24% 的 GPU 時間。
其他 RT live state 優化
本文比較了在應用 RT 實時狀態優化前后,SER 與兩個版本的 GLSL 的性能:
- After: 2024 年 12 月發布的 GLSL 發行版本,包含所有優化。
- 之前: 已恢復兩項優化的 After 版本 (循環移除,并對
radianceAndAccumHitDist使用 FP16 精度) 。
實際上,我們在 TraceMain 通道的 GLSL 中實施了額外的 RT 實時狀態優化,這是 After 版本的一部分,但由于在本文中生成“Before”狀態而未恢復:
- 路徑追蹤器的 RGB 吞吐量向量為
float3。將其更改為half3有助于實現相同的效果。 - 反彈循環的
bounceId和bounceNum變量為 32 位整數。制作uint16_t對他們有所幫助。(uint8_t也可以實現。) - 反射循環主體中的光線方向為
float3。將其打包成uint32_t有助于實現相同的效果。 - 通過消除對
GBuffer材質數據的依賴關系,將信號解調從 RayGen 的末尾轉移到后續傳遞會有所幫助。
所有這些優化都是在游戲 path-tracing 模式的初始版本發布之前及時實施的。
總結?
在每個線程束所占平均活動線程百分比較低的 RayGen 著色器中,添加 SER 可以顯著加速,同時盡可能減少代碼更改。減少 Nsight Graphics GPU Trace Profiler 中報告的 RT 實時狀態溢出字節數可以使 SER 成為更強大的加速器。
在 HLSL 中,可以使用 DXC 和 Shader Model 6.2 或更高版本以及此顯式 HLSL 類型:float16_t 將浮點變量聲明為 FP16。如需了解更多信息,請參閱 Half The Precision, Twice The Fun: Working With FP16 In HLSL 。
本系列的下一篇文章是“Indiana Jones? 中的路徑追蹤優化:Opacity Micro-Maps 和動態 BLAS 的規整”,介紹了如何使用 Opacity MicroMaps (OMMs) 作為一種有效方法,在使用 alpha 測試材質的場景中加速 traceRay 調用 (或 rayQuery 對象) ,以及壓縮動態植被的 BLAS 以節省 VRAM。
致謝?
在此,我們要感謝 NVIDIA 和 MachineGames 的所有人員,感謝他們于 2024 年 12 月 9 日發布了帶有路徑追蹤功能的“Indiana Jones and the Great Circle?”:
MachineGames:Sergei Kulikov、Andreas Larsson、Marcus Buretorp、Joel de Vahl、Nikita Druzhinin、Patrik Willbo、Markus ?lind、Magnus Auvinen、Jim Kjellin、Truls Bengtsson、Jorge Luna (MPG)。
NVIDIA:Ivan Povarov、Juho Marttila、Jussi Rasanen、Jiho Choi、Oleg Arutiunian、Dmitrii Zhdan、Evgeny Makarov、Johannes Deligiannis、Fedor Gatov、Vladimir Mulabaev、Dajuan Mcdaniel、Dean Bent、Jon Story、Eric Reichley、Magnus Andersson、Pierre Moreau、Rasmus Barringer、Michael Haidl、Martin Stich。
?





