
先進的圖像擴散模型需要數十秒才能處理單張圖像。這使得視頻擴散更具挑戰性,需要大量計算資源和高昂成本。通過在搭載 NVIDIA TensorRT 的 NVIDIA Hopper GPU 上利用最新的 FP8 量化功能,可以顯著降低推理成本,并以更少的 GPU 為更多用戶提供服務。雖然量化擴散器的部署可能比較復雜,但 TensorRT 背后的完整生態系統可以幫助克服這些挑戰。
借助此方法,Adobe 將延遲降低了 60%,TCO 降低了近 40%,從而加快了推理速度并提高了響應速度。使用在由 Hopper GPU 加速的 Amazon Web Services (AWS) EC2 P5/P5en 上運行的 TensorRT 進行的優化部署,提高了可擴展性,以更少的 GPU 為更多用戶提供服務。
本文將探討為增強 Adobe Firefly 視頻生成模型的性能而實施的策略和優化,重點關注降低延遲、降低成本和加速市場部署。
借助 AWS 上的 Adobe Firefly 和 NVIDIA TensorRT 革新創意 AI
借助 Firefly,用戶可以在瞬間根據文本提示生成詳細的圖像,從而簡化創意流程。例如,單個視頻 diffusion 模型需要比單個圖像 diffusion 模型更多的計算。
對快速、高效和可擴展的 AI 推理和訓練解決方案的需求推動了 Firefly 和 Adobe 與 NVIDIA 持續合作的快速發展。TensorRT 為 Adobe 提供硬件加速和模型優化工具,以快速、大規模地部署其創新生成式模型,確保它們始終處于創意 AI 技術的前沿。

Adobe Firefly 發布
Adobe Firefly 發布 (2024 年 10 月) 非常精彩。這是 Adobe 有史以來最成功的測試版之一。這些數字不言自明:
- 僅在第一個月就生成了超過 7000 萬張圖像
- 迄今為止,Firefly 已為 超過 20 billion 個資產的創建 提供支持
- 集成 Adobe Photoshop、Adobe Premiere Pro、Adobe Express 和 Adobe Illustrator 等 Adobe 創意套件
利用 TensorRT 實現高效部署
為了應對擴展擴散模型的挑戰,Adobe 使用了高性能深度學習推理優化器 NVIDIA TensorRT。NVIDIA H100 GPU 上的最新 FP8 量化實現了以下功能:
- 減少顯存占用 :FP8 可顯著降低顯存帶寬,同時加速 Tensor Core 運算
- 節省推理成本 :相同工作負載所需的 GPU 更少
- 無縫模型可移植性 :TensorRT 支持 PyTorch、TensorFlow 和 ONNX,提高了部署效率
TensorRT 可在 PyTorch 和 TensorFlow 等各種框架中優化和部署模型,使其成為 Adobe 用例的理想選擇。優化過程涉及幾個關鍵步驟:
第 1 步:ONNX 導出
Adobe 之所以選擇 ONNX (Open Neural Network Exchange) ,是因為它具有通用性和易于導出的特點。這一決策允許在研究和部署之間無縫共享代碼,從而消除了耗時的重新實現。
第 2 步:TensorRT 實現
該團隊實施了 TensorRT,專注于使用 FP8 和 BF16 的混合精度。這種方法顯著減少了權重和激活函數的內存占用,從而降低了內存帶寬并加速了 Tensor Core 運算。FP8 格式可大幅減少權重和激活函數的內存占用。E4M3 FP8 格式可以表示為:

其中:
是符號位 ( 1 位)
是指數 ( 4 位)
是分數 ( 3 位)
- 對于 E4M3,
為 7
這種格式允許的可表示值范圍約為 1.52 × 10-2 到 4.48 × 102。之所以選擇 E4M3 而不是 E5M2,是因為它允許更精細的精度,而不是更高的激活峰值。這種權衡最適合 前向推理 ,而反向傳播可以從更大的值范圍中受益。
第 3 步:量化技術
Adobe 使用 NVIDIA TensorRT Model Optimizer PyTorch API 實現了訓練后量化。PyTorch API 允許使用現有的評估流程進行內置研究。雖然 TensorRT Model Optimizer 提供的 PyTorch FP8 仿真無法反映 FP8 執行的實際性能提升,但它可以在不需要網絡導出的情況下快速進行質量評估。

使用 NVIDIA Nsight Deep Learning Designer 識別瓶頸
借助 NVIDIA Nsight Deep Learning Designer ,工程師查明了擴散管道中的關鍵瓶頸,包括:
- Scaled Dot Product Attention (SDPA) 是導致過度延遲的主要計算瓶頸。
- ONNX 分析允許映射內核執行時間,這表明高分辨率圖像和視頻擴散模型效率低下。

通過隔離這些性能問題,Adobe 團隊對 Transformer 主干進行了微調,以提高執行速度并降低內存消耗。
使用量化 Diffusers 克服部署挑戰
量化擴散器的部署可能非常復雜,需要仔細調整模型參數和量化設置。然而,TensorRT 背后的完整生態系統(包括 NVIDIA Deep Learning SDK 和 TensorRT Model Optimizer)幫助 Adobe 克服了這些挑戰。
Adobe 的工程師實施了評估和提高量化質量的技術,包括分布分析和使用 TensorRT Model Optimizer 進行自動量化。
量化
量化使用縮放系數 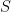

其中:
是量化的 FP8 值
定義 FP8 動態范圍,例如: 對于 E4M3:大約 [?448,448] 對于 E5M2:大約 [?57344,57344]
可確保值保持在可表示的 FP8 范圍內
去量化
要恢復近似的全精度值:

其中:
是重建的 floating-point 值
縮放系數選擇
擴展系數
- 基于 Max 的擴展:
- 每個 Tensor 擴展 :整個 Tensor 的一個擴展

誤差分析 (量化噪音)
量化誤差通常建模為:

如果正確擴展,這將遵循 uniform distribution。
處理 FP8 格式
TensorRT 支持 E4M3 和 E5M2 FP8 格式:
- E4M3 (1 個符號位、4 個指數位、3 個尾數位):在較小的動態范圍內提供更高的精度。它可以表示大約在 ±[1.52×10?2, 448] 范圍內的值,包括 NaN。
- E5M2 (1 個符號位、5 個指數位、2 個尾數位):以更低的精度提供更寬的動態范圍。它可以表示范圍大致為 ±[5.96×10??, 57344] 的值,包括 ±inf 和 NaN。
選擇取決于 precision 和 dynamic range 之間的權衡。
AI 工作負載的可擴展性和成本優勢
Adobe Firefly 在 AWS 上的部署在優化性能和確保無縫可擴展性方面發揮了關鍵作用。通過利用 AWS 高性能云基礎設施,該團隊能夠更大限度地提高效率、降低延遲并提高大規模 AI 工作負載的成本效益。
使用 TensorRT 優化部署后,擴散延遲降低了 60%,總體擁有成本降低了 40%,顯著節省了成本,并提高了 Adobe 創意應用程序的可擴展性。通過減少擴散模型推理所需的計算資源,Firefly 能夠用更少的 GPU 為更多用戶提供服務,從而降低成本并提高效率。

未來步驟
優化擴散模型部署對于讓更多用戶訪問這些強大的模型至關重要。隨著 Adobe 不斷突破創意 AI 的界限,從 Firefly 的開發和部署中汲取的經驗教訓將塑造未來的創新。快速開發、戰略技術決策和不懈優化的結合為生成式 AI 領域樹立了新的標準。NVIDIA 很高興能繼續與 Adobe 和 AWS 合作,利用擴散模型和 Deep Learning 不斷突破極限。
有關更多信息,請查看 NVIDIA TensorRT 文檔 ,并觀看 NVIDIA GTC 會議: Quantize Large Transformer Diffusion Models 以改善端到端延遲并節省推理成本 。
?






