欺詐是許多金融服務公司的一個主要問題,據最近的一份報告 Federal Trade Commission report 稱,每年損失數十億美元。財務欺詐、虛假評論、機器人攻擊、賬戶接管和垃圾郵件都是在線欺詐和有害活動的例子。
盡管這些公司采用技術打擊在線欺詐,但這些方法可能有嚴重的局限性。簡單的基于規則的技術和基于特征的算法技術(邏輯回歸、貝葉斯信念網絡、 CART 等)不足以檢測所有欺詐或可疑的在線行為。
例如,欺詐者可能會建立許多協調賬戶,以避免觸發對個人賬戶的限制。此外,由于要篩選的數據量巨大(數十億行,數十 TB ),不斷改進方法的復雜性,以及訓練分類算法所需的欺詐活動真實案例的稀缺性,大規模檢測欺詐行為模式很困難。有關更多詳細信息,請參閱 Intelligent Financial Fraud Detection Practices: An Investigation 。
雖然欺詐的成本每年高達數十億美元,但在許多合法交易中,欺詐交易很少,導致標記數據的不平衡,即使數據是可用的。由于個人數據的安全問題以及檢測欺詐活動所用方法的透明度的需要,金融服務行業的欺詐檢測變得更加復雜。
一個可解釋的模型使欺詐分析人員能夠了解分析中使用的算法輸入內容以及標記交易的原因,從而在系統中建立更強的信任。其他好處包括能夠向內部團隊傳達反饋并向客戶提供解釋。
近年來,圖形神經網絡( GNN )在欺詐檢測問題上獲得了廣泛的應用,通過不同的關系聚合其鄰域信息,從而揭示可疑節點(例如在賬戶和交易中)。換言之,通過檢查某個特定賬戶過去是否向可疑賬戶發送了交易。
在欺詐檢測的背景下, GNN 能夠聚合包含在交易本地鄰居中的信息,這使它們能夠識別僅查看單個交易可能會遺漏的較大模式。
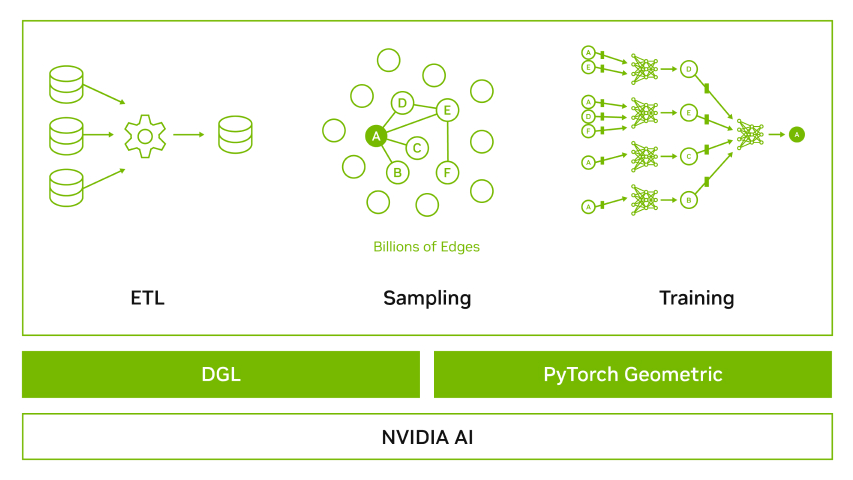
為了使開發人員能夠快速利用 GNN 來優化和加速欺詐檢測, NVIDIA 與深度圖形庫( DGL )團隊和 PyTorch 幾何( PyG )團隊合作,提供了一個 GNN framework containerized solution ,其中包括最新的 DGL 或 PyG 、 PyTorch 、 NVIDIA -RAPIDS 和一組經測試的依賴項。 NVIDIA 優化的 GNN 框架容器針對 NVIDIA GPU 進行了性能調整和測試。
這種方法消除了管理包和依賴項或從源代碼構建框架的需要。我們正在積極致力于提高這些頂級 GNN 框架的性能。我們添加了 GPU 對統一虛擬尋址( UVA )、 FP16 操作、鄰域采樣、小批量子圖操作和優化稀疏嵌入、稀疏 adam 優化器、圖形批處理、 CSR 到 COO 轉換等的支持。
本文首先討論了信用卡欺詐檢測中的獨特問題和最廣泛使用的檢測技術。它還強調了 GPU 加速的 GNN 如何以獨特的方式解決這些問題。我們將介紹一個端到端的工作流,該工作流展示了使用圖形神經網絡在金融欺詐數據集上檢測欺詐的預處理、培訓和部署的最佳實踐。最后,我們利用 NVIDIA 工程師在 DGL 中提供的優化,展示了兩個行業級數據集上的端到端工作流基準。
欺詐檢測概述
欺詐檢測是一套流程和分析,使公司能夠識別和防止未經授權的活動。它已成為大多數組織的主要挑戰之一,尤其是銀行、金融、零售和電子商務組織。
任何形式的欺詐都會對組織的底線和市場聲譽產生負面影響,并阻礙未來的前景和當前的客戶。鑒于這些脆弱組織的規模和影響范圍,防止欺詐行為的發生,甚至實時預測可疑行為對它們來說至關重要。
欺詐檢測給機器學習研究人員和工程師帶來了獨特的問題,下面詳細介紹了其中的一些問題。
復雜且不斷變化的欺詐模式
欺詐者更新他們的知識并開發復雜的技術來欺騙系統,通常涉及復雜的交易鏈以避免被發現。
傳統的基于規則的系統和表格機器學習( ML ),如 SVM 和 XGBoost ,通常只能考慮交易的直接邊緣(誰向誰發送了資金),往往會忽略具有更復雜背景的欺詐模式。隨著欺詐模式的改變和新漏洞的出現,基于規則的系統也需要隨著時間的推移進行手動調整。
標簽質量
可用的欺詐數據集通常既不平衡又沒有詳盡的標簽。在現實世界中,只有一小部分人打算實施欺詐。領域專家通常將交易分類為欺詐或非欺詐,但無法保證數據集中已捕獲所有欺詐。
這種類別不平衡和缺乏詳盡的標簽使得開發監督模型變得困難,因為根據我們現有的標簽訓練的模型可能會導致更高的誤報率,而不平衡的數據集也可能導致模型產生更多的誤報。因此,用替代目標培訓 GNN 并利用其下游潛在代表可以產生有益的效果。
模型可解釋性
預測交易是否欺詐,不足以滿足金融服務行業的透明度期望。還需要了解為什么某些交易被標記為欺詐。這一解釋對于理解欺詐是如何發生的,如何實施政策以減少欺詐,以及確保過程沒有偏見都很重要。因此,欺詐檢測模型必須是可解釋的,這限制了分析師可以使用的模型的選擇。
欺詐檢測的圖形方法
一系列事務可以精確地描述為一個圖形,用戶被表示為節點,它們之間的事務被表示為邊。雖然基于特征的算法(如 XGBoost )和基于深度特征的模型(如 DLRM )側重于單個節點或邊的特征,但基于圖的方法可以在預測中考慮本地圖上下文(例如,鄰居和鄰居的鄰居)的特征和結構。
在傳統(非 GNN )圖域中,有許多方法可以基于圖結構生成顯著預測。聚集相鄰節點或邊緣,甚至其鄰居的特征的統計方法,可用于向基于特征的表格算法(如 XGBoost )提供有關位置的信息。
像 Louvain method 和 InfoMap 這樣的算法可以檢測圖形上的社區和更密集的用戶簇,然后可以使用這些算法檢測社區并生成將圖形結構表示為層次結構的特征。
雖然這些方法可以產生足夠的結果,但問題仍然是所使用的算法缺乏對圖形本身的表達能力,因為它們不考慮圖形的原生格式。
圖形神經網絡建立在模型中本地表示局部結構和特征上下文的概念之上。來自邊緣和節點特征的信息通過聚合和消息傳遞到相鄰節點來傳播。
當執行多層圖卷積時,這會導致節點的狀態包含來自多層以外節點的一些信息,從而有效地允許 GNN 具有節點或邊的“接受域”,這些節點或邊可以多次跳離所討論的節點或邊。
在欺詐檢測問題的背景下, GNN 的這個巨大的接受域可以解釋欺詐者可以用于混淆的更復雜或更長的交易鏈。此外,模式的變化可以通過模型的迭代再培訓來解釋。
圖形神經網絡還受益于在無監督或自我監督任務(如 Bootstrapped Graph Latents (BGRL) 或 link prediction with negative sampling )上進行訓練時,能夠對節點或邊的有意義表示進行編碼。這允許 GNN 用戶預先訓練一個沒有標簽的模型,并在管道中稍后在更稀疏的標簽上微調模型,或輸出圖形的強表示。表示輸出可以用于下游模型,如 XGBoost 、其他 GNN 或集群技術。
GNN 還有一套工具,可以解釋輸入圖形。某些 GNN 模型,如異構圖 transformer ( HGT )和圖形注意網絡( GAT ),可以在 GNN 的每一層上跨節點的相鄰邊緣啟用注意機制,允許用戶識別 GNN 用于導出其最終狀態的消息路徑。即使 GNN 模型沒有注意機制,也提出了多種方法來解釋整個子圖背景下的 GNN 輸出,包括 GNNExplainer 、 PGExplainer 和 GraphMask 。
下一節將介紹端到端信用卡欺詐檢測工作流。此工作流使用 TabFormer (卡片交易欺詐數據集),并針對鏈接預測任務的變化訓練 R-GCN (關系圖卷積網絡)模型,以生成豐富的節點嵌入。這些節點嵌入被傳遞給下游 XGBoost 模型,該模型經過培訓,隨后執行欺詐檢測。
然后可以輕松部署此 XGBoost 模型。訓練的嵌入可以隨后用于其他無監督技術,如集群,以識別未發現的使用模式,而無需標簽。最后,我們將利用 NVIDIA 工程師在 DGL 中提供的優化,在兩個行業級數據集上展示端到端工作流的基準。
使用 GNN 構建端到端欺詐檢測工作流
數據預處理
我們使用 IBM 提供的 Tabformer dataset 演示此工作流。 TabFormer 數據集是真實金融欺詐檢測數據集的合成近似值,包括:
- 2400 萬筆獨特交易
- 6000 家獨特商戶
- 100000 張獨特卡
- 30000 個欺詐樣本(占總交易量的 0.1% )
首先,使用預定義的工作流預處理數據集。該工作流利用 cuDF (一個 GPU DataFrame 庫)對原始數據集執行特征轉換,為圖形構建做好準備。 cuDF 是 pandas 的替代品,可以直接在 GPU 上預處理數據。
在這個數據集中,card_id被定義為一個用戶的一張卡。一個特定用戶可以有多張卡,對應于此圖的多個不同card_ids。merchant_id是特征“商家名稱”的分類編碼。對數據進行拆分,使培訓數據為 2018 年之前的所有交易,驗證數據為 2018 年間的所有交易以及測試數據為 2018 之后的所有交易。
# Read the dataset
data = cudf.read_csv(self.source_path)
data[“card_id”] = data[“user”].astype(“str”) + data[“card”].astype(“str”)
# Split the data based on the year
data["split"] = cudf.Series(np.zeros(data["year"].size), dtype=np.int8)
data.loc[data["year"] == 2018, "split"] = 1
data.loc[data["year"] > 2018, "split"] = 2
train_card_id = data.loc[data["split"] == 0, "card_id"]
train_merch_id = data.loc[data["split"] == 0, "merchant_id"]
從“ Amount ”中去掉“$”,將該值轉換為浮點值。僅當card_id和merchant_id包含在列車數據集中時,才將其保留在驗證和測試數據集中。
該圖由card_id和merchant_id之間的事務邊構成。
進一步預處理包括一個熱編碼 Use chip 功能,標簽編碼“ Is Fraud ?”特征,以及對商戶州、商戶城市、郵政編碼和 MCC 的分類表示進行編碼的目標。此外,“錯誤?”的可能值是一個熱編碼。
# Target encoding
high_card_cols = ["merchant_city", "merchant_state", "zip", "mcc"]
for col in high_card_cols:
tgt_encoder = TargetEncoder(smooth=0.001)
train_df[col] = tgt_encoder.fit_transform(
train_df[col], train_df["is_fraud"])
valtest_df[col] = tgt_encoder.transform(valtest_df[col])
# One hot encoding `use_chip`
oneh_enc_cols = ["use_chip"]
data = cudf.concat([data, cudf.get_dummies(data[oneh_enc_cols])], axis=1)
# Label encoding `is_fraud`
label_encoder = LabelEncoder()
train_df["is_fraud"] = label_encoder.fit_transform(train_df["is_fraud"])
valtest_df["is_fraud"] = label_encoder.transform(valtest_df["is_fraud"])
# One hot encoding the errors
exploded = data["errors"].str.strip(",").str.split(",").explode()
raw_one_hot = cudf.get_dummies(exploded, columns=["errors"])
errs = raw_one_hot.groupby(raw_one_hot.index).sum()
數據集經過預處理后,將數據集的表格格式轉換為圖形。
將表格數據建模為圖形
將一個表(或多個表)轉換為圖形的中心是將現有表映射為兩個結構的邊、節點和特征。對于這個數據集,我們首先使用交易表在卡和商家之間創建邊緣。在當代 GNN 框架中,圖的邊緣在基本級別上由成對的節點 ID 表示。根據邊列表中包含的 ID ,節點是隱式的。
# Defining node type
for ntype in ["card", "merchant"]:
node_type = {MetadataKeys.NAME: ntype, MetadataKeys.FEAT: []}
self.node_types.append(node_type)
# Adding attributes of edge data
self.edge_data = dict()
self.edge_data["transaction"] = cudf.DataFrame({
MetadataKeys.SRC_ID: data["card_id"],
MetadataKeys.DST_ID: data["merchant_id"],})
# Defining features
features = []
for key in data.keys():
if key not in ["card_id", "merchant_id"]:
self.edge_data["transaction"][key] = data[key]
feat = {
MetadataKeys.NAME: key,
MetadataKeys.DTYPE: str(self.edge_data["transaction"][key].dtype),
MetadataKeys.SHAPE: self.edge_data["transaction"][key].shape,}
if key in ["is_fraud"]:
feat[MetadataKeys.LABEL] = True
features.append(feat)
創建基礎圖后,是時候將事務特性添加到圖的邊上了。請注意,在這種情況下,事務數據只是邊緣特定的,因此輸出圖沒有節點特征。
創建圖形并填充特征后,可以將模型應用于該圖形。
培訓 GNN 模型
考慮到數據集的標簽不平衡和標簽不完善,我們選擇使用無監督任務鏈接預測來訓練模型,以創建有意義的節點表示。鏈路預測的目的是預測兩個節點之間存在邊緣的概率。在金融服務業中,這被轉化為預測個人和商戶之間存在交易的可能性。
批處理中的一些目標節點是真實邊,即存在于圖形中的實際邊,而其他由負采樣器生成的節點是不真實存在的負邊。在這種情況下,負面邊緣是必要的,因為我們的訓練任務是區分真假。生成負邊的方法有多種,但簡單地對節點進行均勻采樣以獲得節點端點被廣泛采用,并取得了良好的效果。雖然使用這種方法可以對實際邊進行負采樣,但大多數圖形都足夠稀疏,因此這種可能性幾乎可以忽略不計。
由于大多數事務圖太大,無法在 GPU 內存中表示,因此我們需要使用子采樣技術,以便生成較小的位置供圖處理。 DGL 通常分兩個階段進行采樣。
首先,執行種子采樣,以識別 GNN 要預測的目標邊緣或節點。接下來,執行塊采樣,也稱為鄰域采樣,以生成種子周圍的子圖,用作 GNN 的輸入。
該圖包含可能從測試集中泄漏未來信息的邊和節點,因此我們必須為訓練、驗證和測試集創建單獨的數據加載器和采樣例程。序列數據加載器相當簡單,只利用訓練集中的邊進行種子采樣,利用序列集圖進行塊采樣。
對于驗證數據加載器,使用驗證邊進行種子采樣,但僅使用訓練集圖進行塊采樣,以防止信息泄漏。將同樣的思想應用于測試集,其中測試邊用于種子采樣,而圖則由塊采樣的訓練集和驗證集的聯合定義。
為了加速數據加載,使用一個名為 Universal Virtual Addressing ( UVA )的功能,它允許我們實例化圖形,以便所有 GPU 都可以直接訪問它,而不是通過主機。當圖形具有高度特色時, UVA 可以將模型吞吐量提高 5 倍。
定義數據加載器并構建圖形后,實例化 R-GCN 模型。眾所周知,圖卷積網絡對結構化鄰域的特征進行編碼,為連接到源節點的邊分配相同的權重。 R-GCN 在此基礎上構建,并提供依賴于邊的類型和方向的特定于關系的轉換。
邊緣的類型信息補充了為每個節點計算的消息。節點的特征和邊的類型作為輸入傳遞給 R-GCN 模型,并轉換為嵌入。 R-GCN 層可以通過消息傳遞和圖卷積提取高級節點表示。
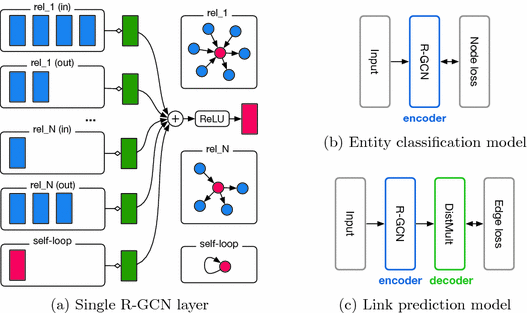
首先創建一個可學習的節點級嵌入,為每個節點存儲 64 個元素的表示張量。鑒于無法使用(負邊無特征),且圖形沒有節點特征,此處的節點嵌入將作為節點上的數字特征,而不僅僅是圖形的純結構。該嵌入表用作模型 R-GCN 的輸入,該模型使用標準化超參數定義。
指定的模型輸出寬度為 64 。請注意,該數字并不反映許多類:使用鏈接預測, R-GCN 模型應生成一個節點表示,下游操作可以使用該表示預測兩個節點之間的邊緣概率。有許多建議的方法可以做到這一點,包括多層感知器。本例使用兩個節點的余弦相似性,以生成節點實際通過邊連接的概率。因此,該模型被封裝在鏈接預測模塊中,以輸出給定輸入表示的概率。
接下來,定義優化器,每個優化器對應于模型本身和嵌入表。這兩個優化器設置在涉及嵌入表的其他上下文中很常見,在這里用于提高模型收斂性。
定義了組件后,現在是訓練模型的時候了。與其他域一樣,可以使用分布式數據并行( DDP )在單個節點上對模型進行訓練,以進一步加速多個 GPU 上的模型。
為下游任務使用 GNN 嵌入
R-GCN 模型經過訓練后,使用網絡生成健壯的節點嵌入。為此,對整個圖形的每個圖形層以一跳的比例執行圖形卷積,并使用模型生成的后期激活作為圖形節點的嵌入。
生成節點嵌入后,將嵌入連接到各自節點 ID 上的原始預處理數據集。接下來,將 XGBoost 模型擬合到邊緣特征數據集,并使用從上游 GNN 模型提取的嵌入值進行增強。
首先,通過連接到 LocalCUDACluster 創建一個 Dask client ,這是一個基于 Dask 的 CUDA 集群,能夠在多個 GPU 上執行 Python 進程。然后將邊緣特征數據集讀入 Dask 并進行采樣,以使最終訓練數據集(定義為通過嵌入值增強的邊緣特征)的大小不超過總 GPU 存儲的 40% 。這對于 Dask XGBoost 來說是必要的,因為完整的列車數據必須在 GPU 內存中,而創建 DMatrix 的過程會消耗剩余的內存。
接下來,讀取上游模型的嵌入內容,并將節點特征附加到相應的 ID 中。最后,對 XGBoost 模型進行訓練,以預測“是否欺詐?”并在測試集上輸出 AUPRC 分數 0.9 。為了證明 GNN 創建的節點嵌入的有效性,在沒有事務的情況下訓練的最佳 XGBoost 模型在測試集中的 AUCPR 得分為 0.79 。
模型檢查點可進一步用于在 NVIDIA Triton 推理服務器上部署此模型。
部署
XGBoost 模型經過訓練后,部署該模型并啟動一個推理服務器,使用 Python backend 處理嵌入查找,使用 Forest Inference Library ( FIL )后端執行 GPU 加速林庫推理。
部署管道由三部分組成:
- Python 后端模型,稱為嵌入模型。它讀取嵌入張量。此后端接受卡 ID 和商家 ID 作為輸入,并返回其嵌入內容。
- FIL 后端模型,稱為 XGBoost 模型。它從培訓中加載保存的 XGB 模型。此后端接受擴展數據(功能和嵌入),并返回每行的 XGB 預測。
- 另一個 Python 后端模型,我們稱之為下游模型。該模型統一了整個部署。此后端接受卡 ID 、商家 ID 和功能。首先,它使用業務邏輯腳本( BLS )調用嵌入模型來獲取嵌入。接下來,它連接特性和嵌入來創建擴展數據。然后,它再次使用 BLS 調用 XGB 模型,并返回其預測。
使用數據樣本查詢此服務,以獲取交易欺詐的可能性。然后,可以將此概率用于開發后續業務邏輯。
基準
我們分別對一個欺詐檢測和一個基準數據集 TabFormer 和 MAG240M 進行了廣泛測試。為了使我們的實驗具有可重復性,我們在所有基準測試運行中都使用了 DGX A100 ( 80 GB )。此服務器具有 64 核雙插槽 AMD EPYC 7742 CPU 處理器和八個 NVIDIA A100 ( 80 GB SXM4 ) GPU 處理器。
下一節介紹了通過優化 GPU 的端到端工作流實現的加速。
TabFormer 數據集
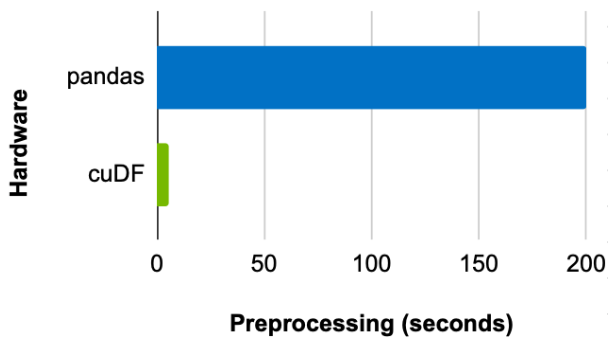
比較使用 CPU 上的 pandas 和 GPU 上的 cuDF 預處理數據集所需的時間,發現批次大小為 8192 時,使用 GPU 可以實現 39x 的加速(圖 2 )。
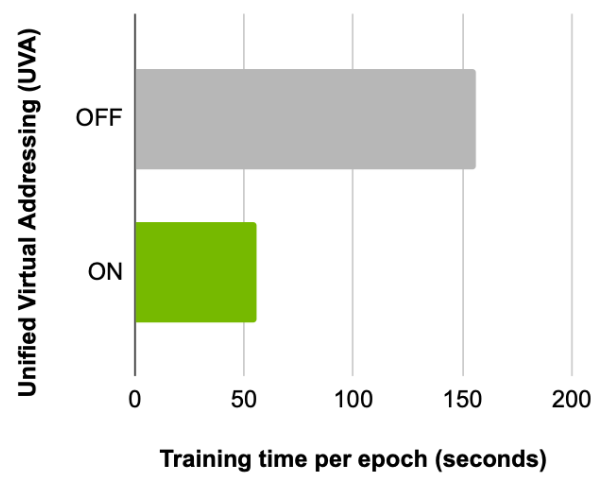
接下來,比較啟用此功能前后每個歷元的訓練時間,顯示使用 UVA 的優勢。使用相同的批量大小和[5 , 5]配置的扇出,單個 GPU 可以實現 2.8x 的加速(圖 3 )。
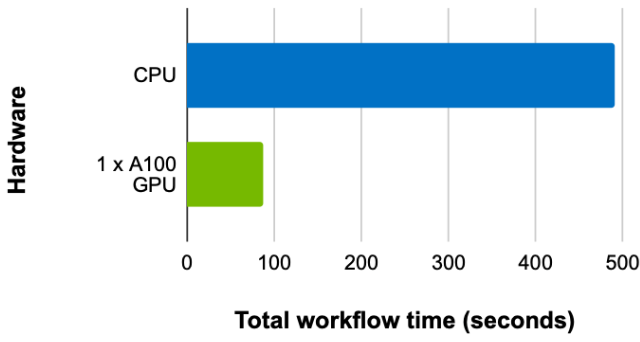
最后,比較具有相同批次大小和扇出配置的訓練時間,但在 CPU 和 GPU (啟用 UVA )上,單個 GPU 的加速比為 5.63 倍(圖 4 )。
MAG240M 數據集
MAG240M 數據集是 OGB Large Scale Challenge 的一部分。它是節點級任務的最大公共基準數據集,具有約 2.45 億個節點和約 17 億條邊。
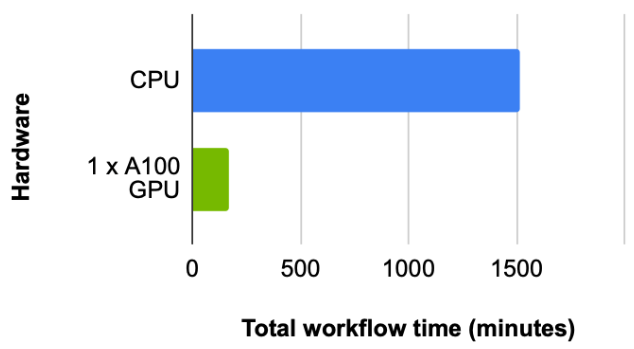
對于這個數據集,我們首先查看總工作流時間(預處理數據所需的時間)、加載、加上構造圖形和訓練 RGCN 模型。批次大小為 4096 ,扇出為[150100](用于在超參數搜索中獲得最佳結果),我們觀察到大約 9 倍的加速,其中 CPU 需要 1514 分鐘, 1x NVIDIA A100 GPU 需要 169 分鐘(圖 5 )。
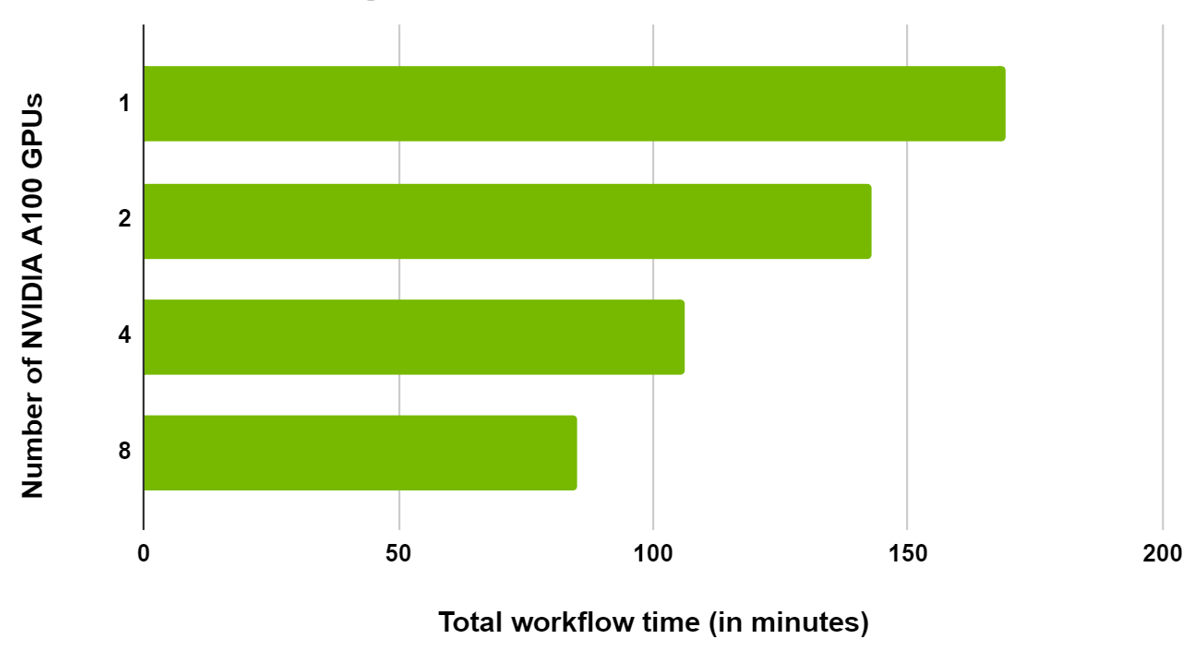
由于這是一個大型數據集,工作流已在同一節點中的多個 GPU 之間進行了擴展。我們觀察到,當從 1 縮放到 2 GPU 時,總時間減少了 20% ,從 1 縮放至 8 GPU 時減少了 50% (圖 6 )。
總結
NVIDIA 已與 DGL 和 PyG 合作,為 GPU 上的圖形操作添加支持,并優化預處理和培訓操作。了解更多有關 NVIDIA 如何積極促進這些頂級 GNN frameworks 的信息。
本文介紹了使用 GNN 進行欺詐檢測的端到端工作流,包括預處理、將表格數據建模為圖形、培訓 GNN 、將 GNN 嵌入用于下游任務以及部署。這種方法利用了 NVIDIA 優化的 DGL ,以及一組依賴項,如 RAPIDS cuDF 和 NVIDIA Triton 推斷服務器。我們在兩個數據集上進一步演示了基準測試,其中我們觀察到一個 NVIDIA A100 GPU 上的 MAG240M 數據集上的 RGCN 相對于 CPU 有 29x 的加速。
要了解更多信息,請與 AWS 高級應用科學家 Da Zheng 一起觀看 GTC 會議 Accelerate and Scale GNNs with Deep Graph Library and GPUs 。另請參閱由 NVIDIA 工程師主持的 Accelerating GNNs with Deep Graph Library and GPUs 和 Accelerating GNNs with PyTorch Geometric and GPUs 。
如果您有 DGL early access 或 PyG early access ,現在可以嘗試針對 NVIDIA GPU 進行性能優化和測試的容器。
?






