
NVIDIA Nsight Systems 是一個綜合工具,用于跨 CPU 和 GPU 資源跟蹤應用程序性能。它可以幫助確保硬件得到有效使用,跟蹤 API 調用,并通過描述低級指標與應用程序性能的總和以及可以改進的地方,深入了解節點間網絡通信。
Nsight 系統可以擴展到集群大小的問題,比如 multi-node analysis,但當您剛剛開始優化之旅時,它也可以用于發現簡單的性能改進。例如,Nsight Systems 可以用來查看哪里的內存傳輸比預期的更昂貴。通過快速查看內存活動,可以發現并關聯性能損失,并建議如何解決這些損失。
在這篇深入的文章中,我來看看 GROMACS 2019 和 GROMACS 2020 之間的變化。我與 Nsight Systems 一步一步地尋找前一版本中的 GPU 和內存優化機會,并研究它們在新版本中是如何解決的。
GROMACS 2019
GROMACS 是一個通用且廣泛使用的軟件包,用于生物分子(如蛋白質、脂質和核酸)的分子動力學( MD )模擬。它可以幫助研究人員檢查疾病預防和治療的重要生物過程。
我在帶有 NVIDIA Volta GPU 的 Arm 服務器系統上使用 Nsight Systems 分析了 GROMACS 2019 。 Nsight Systems 包括一個用戶界面和一個 CLI ,稱為nsys.
運行以下命令 nsys 以收集沒有 CPU 采樣的 CUDA 和 NVTX 的跟蹤信息。它可以用于從目標 Arm 服務器收集性能數據,然后可以在 Nsight Systems 用戶界面中像往常一樣進行分析。更多關于 nsys 和配置文件選項的信息,請參閱 單條命令行示例。
nsys profile -t cuda,nvtx -s none gmx mdrun -dlb no -notunepme -noconfout -nsteps 3000 |
圖 1 顯示了執行該命令并打開報告文件。
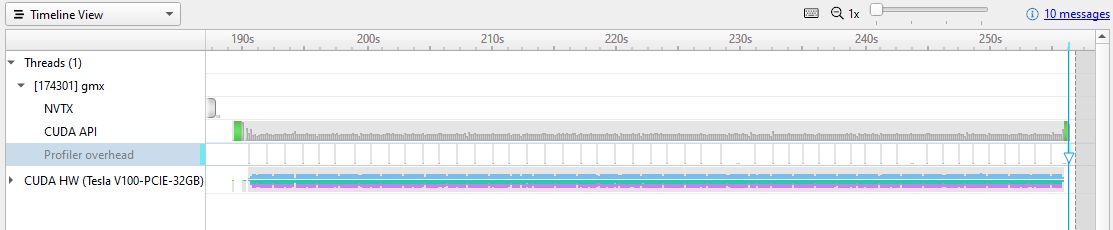
Nsight Systems 使用細節級別( LOD )縮放來顯示時間軸上每個像素下的 GPU 使用量。然而,在這種縮放級別上,數據過于密集,無法看到真實的圖案。放大顯示 Nsight Systems 捕獲的內容的粒度。
同樣,也有關于 GPU 活動的信息,但詳細信息是在下拉列表下組織的。展開 GPU 行以顯示有關流和上下文的信息。
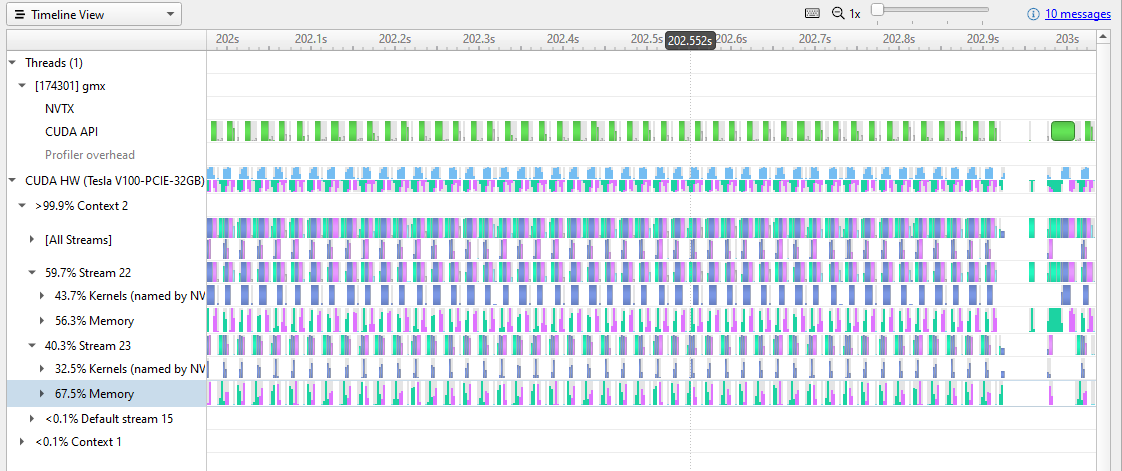
在圖 2 中,您可以開始看到 GPU 上內存傳輸和內核活動的重復模式。重復模式是正常的,但你也可以看到很多時間都花在了內存轉移上。 GPU 活動中存在差距,表明存在改進的機會。
圖 3 進一步放大到 0 . 1 秒的時鐘時間。
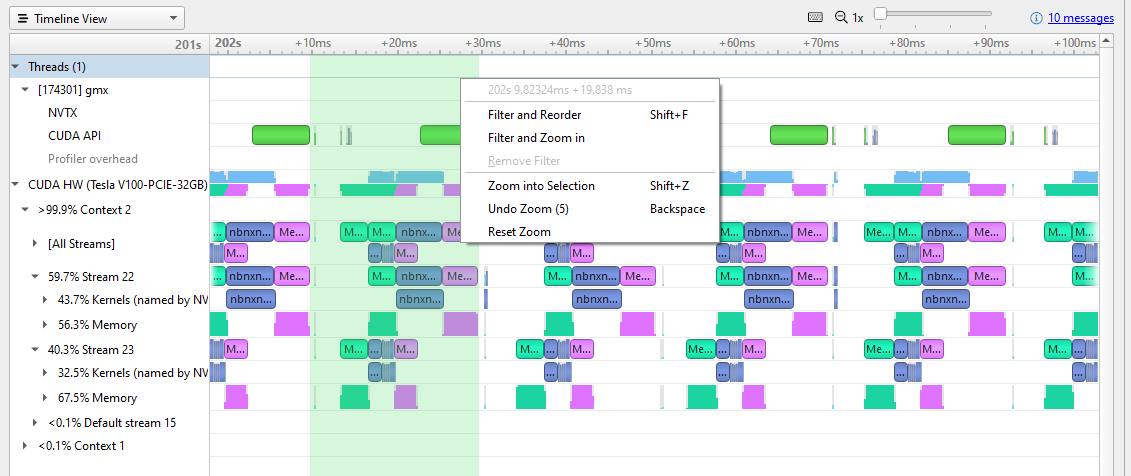
在這個分辨率下,您可以清楚地看到 GPU 上的活動模式。在每次重復中,都會有一個主機到設備的內存傳輸(綠色),一些內核工作(藍色),然后是一個內存傳輸回主機(品紅色)。您還可以看到每個內核運行后、新內存傳輸開始前的暫停。
圖 3 顯示了從上一次設備主機傳輸結束到本次迭代的設備主機傳輸(選擇標記為綠色)結束的單次迭代中的移位拖動。右鍵單擊此處將顯示菜單,您可以放大以隔離此迭代。
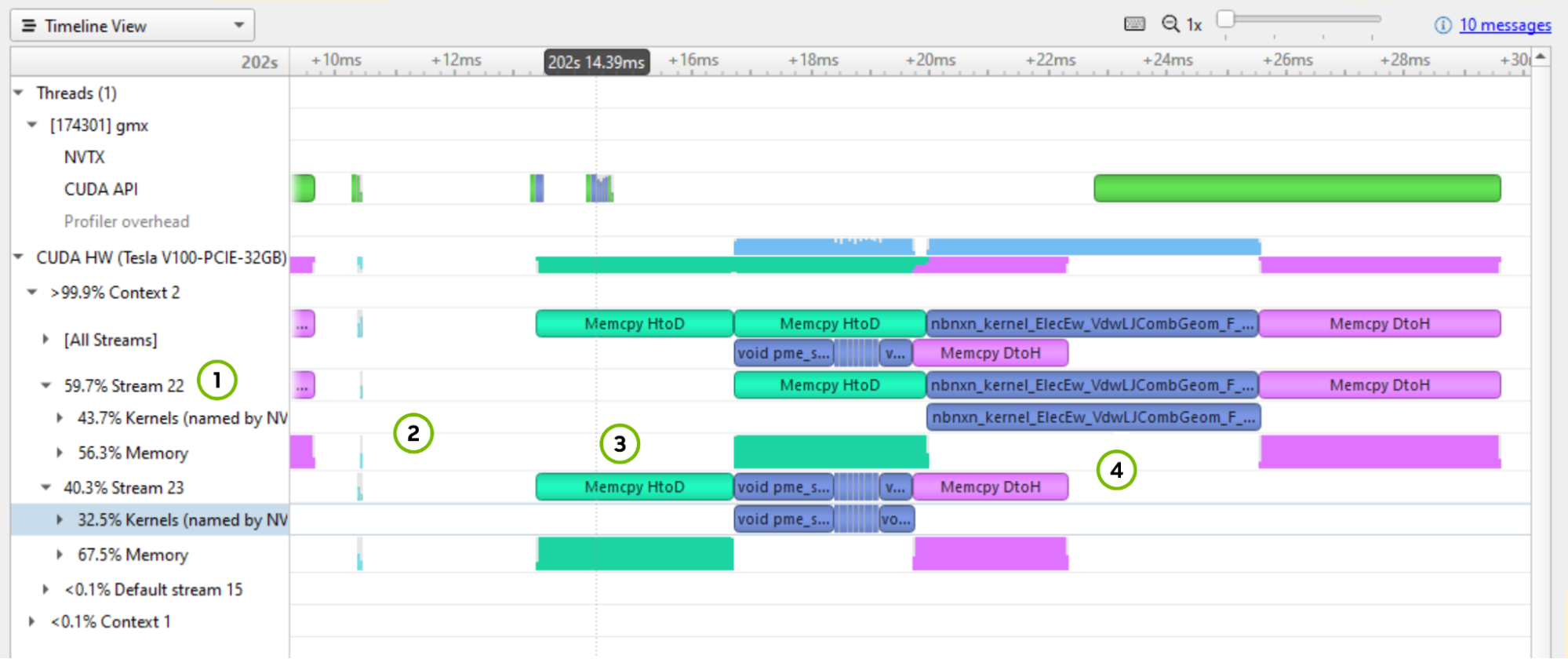
在圖 4 上標記的幾件事需要指出:
- 這個[All Streams]是流的匯合。關注細分,注意有一個活動上下文和兩個活動流(流 22 和 23 ),并且 Default 流是不活動的。每個流都將超過一半的時間用于內存傳輸。這個高百分比強烈表明您必須優化內存傳輸的大小,并考慮將其移動到默認流。
- 迭代大約需要 19 毫秒,但其中 3 毫秒的時間是在活動塊之間的空白間隙中。這意味著有大約 17% 的加速等待被捕獲。下一個好的步驟是運行 CPU 配置文件來檢查暫停的編程原因。
- 內存傳輸是序列化的。流 23 從主機獲取數據,而流 22 等待,在它能夠獲取數據之前不做任何工作。工作完成后也會發生同樣的事情。
- 最主要的工作內核是
nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda我建議在深入研究單個內核之前,先解決 CPU 和 GPU 時間線上的差距。
要查找最昂貴的內核,請右鍵單擊所有流行并選擇在事件視圖中顯示(圖 5 )。
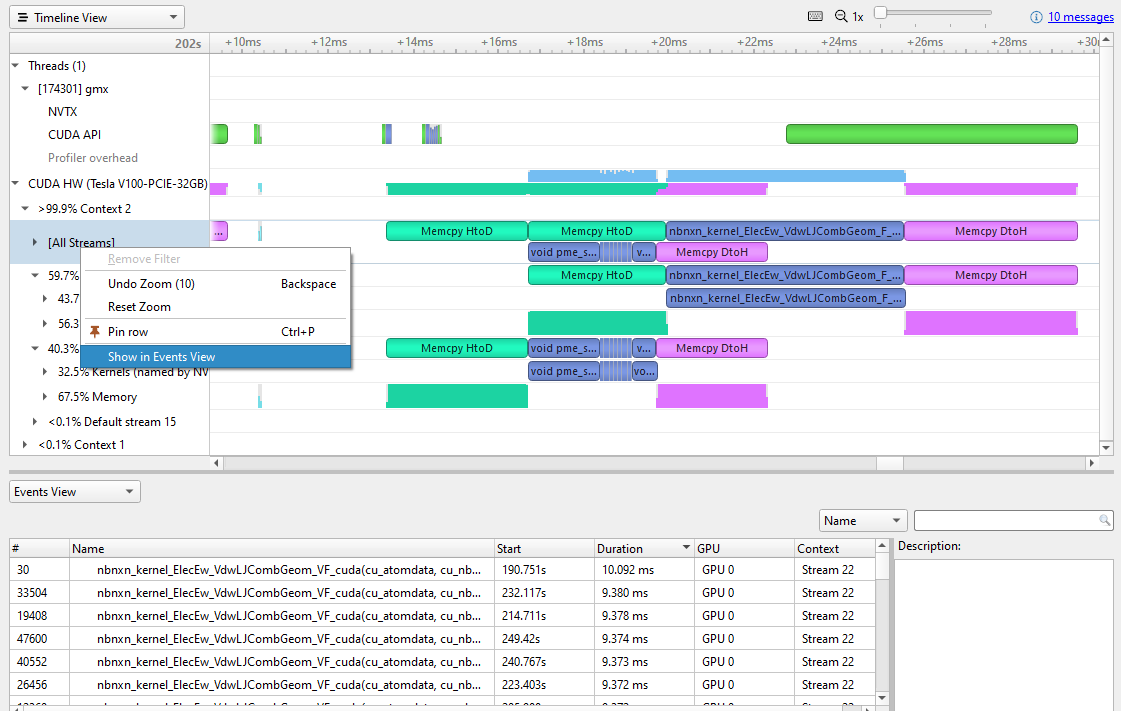
按持續時間對 Events 視圖進行排序會顯示最昂貴的內核。不同的實例略有不同,但目前最昂貴的是約 10 毫秒。單擊某個特定的內核實例會以青色高亮顯示時間線上與其相關的所有事件。
在圖 6 中,閉合行上的青色標記表示該行中的某些內容高亮顯示。時間線頂部或左側的箭頭表示高亮顯示的內容當前不在屏幕上。
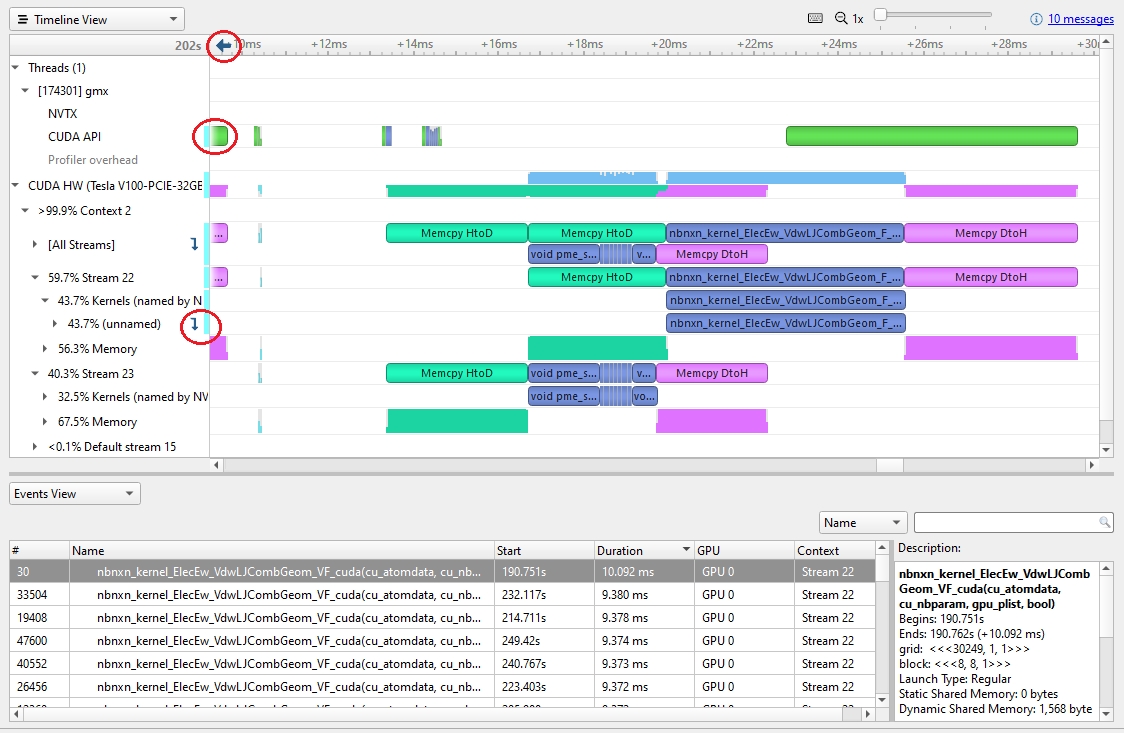
或者,您可以在事件表中單擊鼠標右鍵,然后選擇在日程表中顯示當前以將時間軸縮放到該內核。
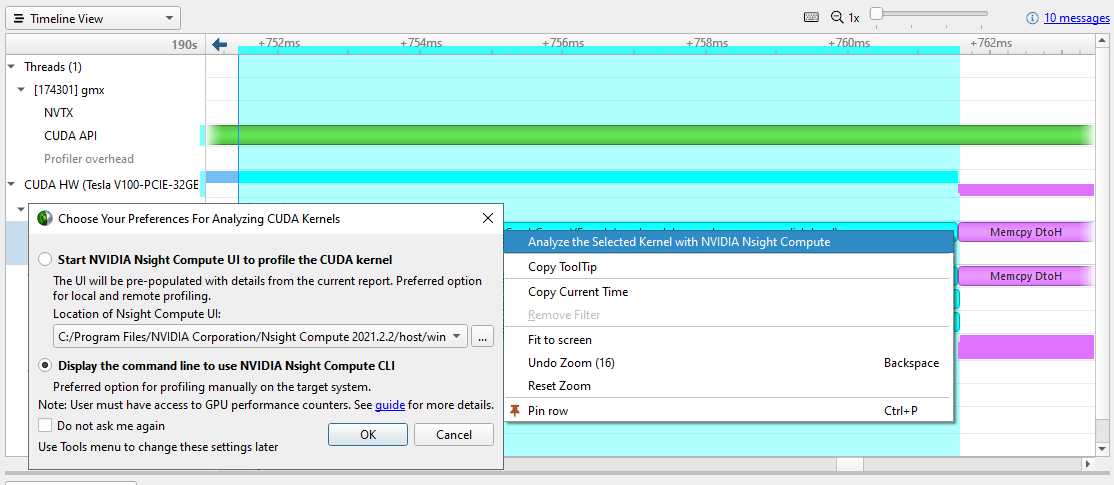
大多數時候,您會集中精力消除時間線間隙,并確保在深入到各個內核之前,工作已分配給所有 CPU 和 GPU 。屆時,或者如果內核性能與您的期望不符,您可以右鍵單擊感興趣的內核并選擇使用 NVIDIA Nsight Compute 分析所選內核.
Nsight Compute 是一個強大的獨立工具,用于分析、調試和優化 CUDA 內核。如果它已安裝在您的機器上,您可以直接從 Nsight Systems 中有問題的內核啟動它的用戶界面或 CLI。
GROMACS 2020
NVIDIA 與斯德哥爾摩 GROMACS 開發團隊合作,對 GROMACS 進行了改進。有關詳細信息,請參閱 《將 Gromacs 帶入現代多 GPU 系統的新速度》。
您可能會注意到以下幾個變化:
- 這個
nbnxn_gpu_x_to_nbat_x_內核是一個函數的 GPU 實現,該函數將原子的坐標數據從“ XYZ ”轉換為一個結構,該結構中也有數據局部性的電荷: XYZQ 。在 GROMACS 2019 中,這是在 CPU 上完成的。 2020 版本調整了內存傳輸的大小,并將其移動到默認流。 - 長內核
nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda現在啟用兩個流之間的重疊內核執行。
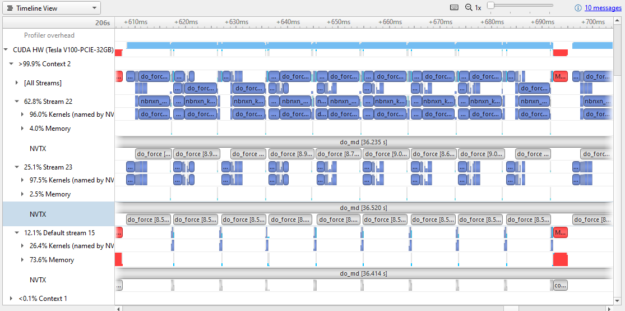
將圖 8 中的結果與圖 3 中的結果進行比較。兩者都顯示約 100 毫秒的掛鐘時間。如圖 8 所示, GPU 中有更多的時間實際上是在工作。 GPU 的使用顯然在不同版本之間進行了優化。
幾乎所有的內存傳輸工作都轉移到了默認流上,這意味著這兩個活動流在內存傳輸操作上花費的時間很少( 4% 和 2.5% ,而 GROMACS 2019 中超過 50% )。小的內存傳輸也被組合成更大的大小,仍然適合傳輸緩沖區。
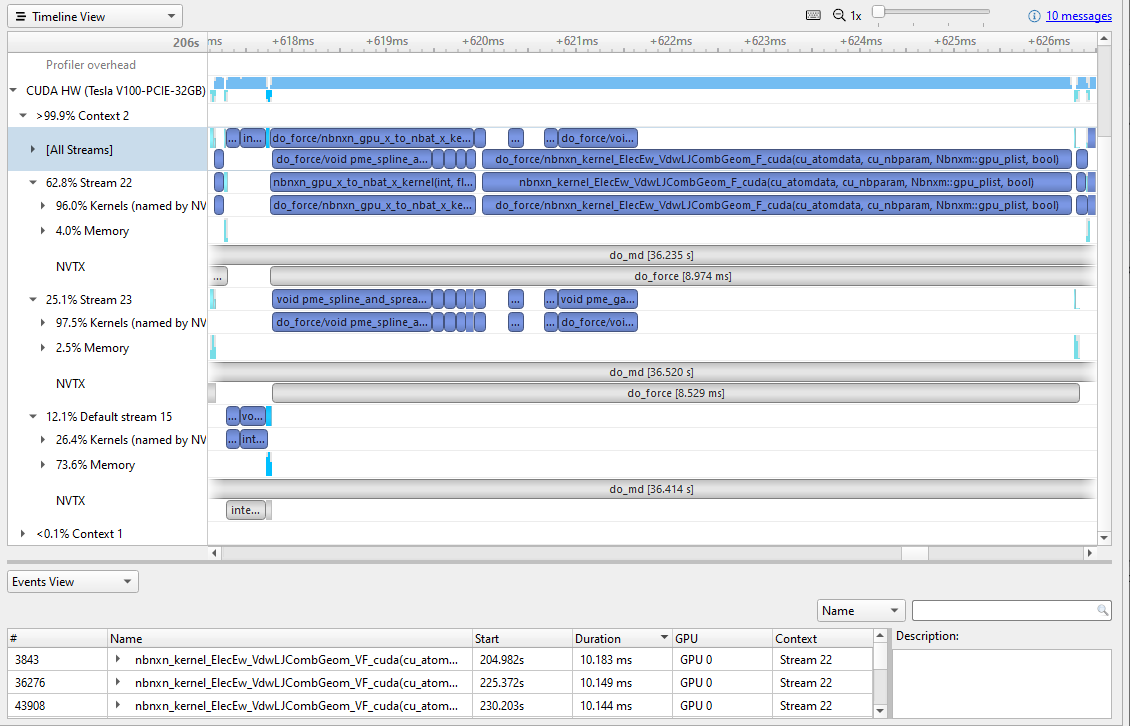
將圖 4 ( GROMACS 2019 的一個工作片段)與圖 9 ( GROMACS 2020 的一個作品片段)進行比較并不公平。正如我前面提到的,大部分內存傳輸都被打包并轉移到默認流。有幾件有趣的事情需要注意:
- 在這兩個流之間有更多的并行內核執行。
- 這個
nbnxn_gpu_x_to_nbat_x_在進行昂貴的計算之前,內核正在 GPU 上運行。將其移動到 GPU 而不是 CPU 不僅填充了一些間隙時間,而且還消除了一些存儲器傳輸開銷。 - 昂貴的內核,
nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda,并沒有變得更快。最長的實例仍然大約是 10 毫秒。然而,由于它在整個運行迭代中更有效地提供了數據,因此這項工作減少到了 10 毫秒,而不是 GROMACS 2019 中的 19 毫秒。
既然間隙被清除了,nbnxn_kernel_ElecEw_VdwLJCombGeom_VF_cuda在運行時占主導地位,這表明您的性能調優之旅接下來應該轉到該內核。
主要收獲
改進 CUDA 內核并不是優化 GPU 代碼時應該做的第一件事。提高內存利用率并確保 GPU 得到足夠的“饋送”,會產生最直接的影響。
當最初重構 GPU 或轉移到新一代的 GPU 硬件時,這一點尤其重要。如果 GPU 缺乏工作,您將永遠無法實現可用的性能提升。
準備好開始了嗎?
這只是 Nsight Systems 必須提供的所有系統性能信息的開始。
您可以從 NVIDIA CUDA ToolKit public download 中獲取 NVIDIA Nsight Systems。此外,您還可以在 NVIDIA CUDA 工具包中獲取最新的 Nsight Systems 增強和修復,請訪問 Nsight Systems 頁面。
想了解更多關于 GROMACS 的信息,請參閱 http://manual.gromacs.org/documentation/。
關于最近的其他帖子,請參閱以下內容:
有關文章、視頻和其他教程的完整列表,請參閱 Nsight Systems 文檔的Other Resources第節。
有任何問題嗎?請將其發布到 NVIDIA 論壇 NVIDIA Nsight Systems,或者將郵件發送至 nsight-systems-feedback@NVIDIA.com。或者,只需在應用程序中選擇 反饋,讓我們知道您所看到的以及您的想法。
?





